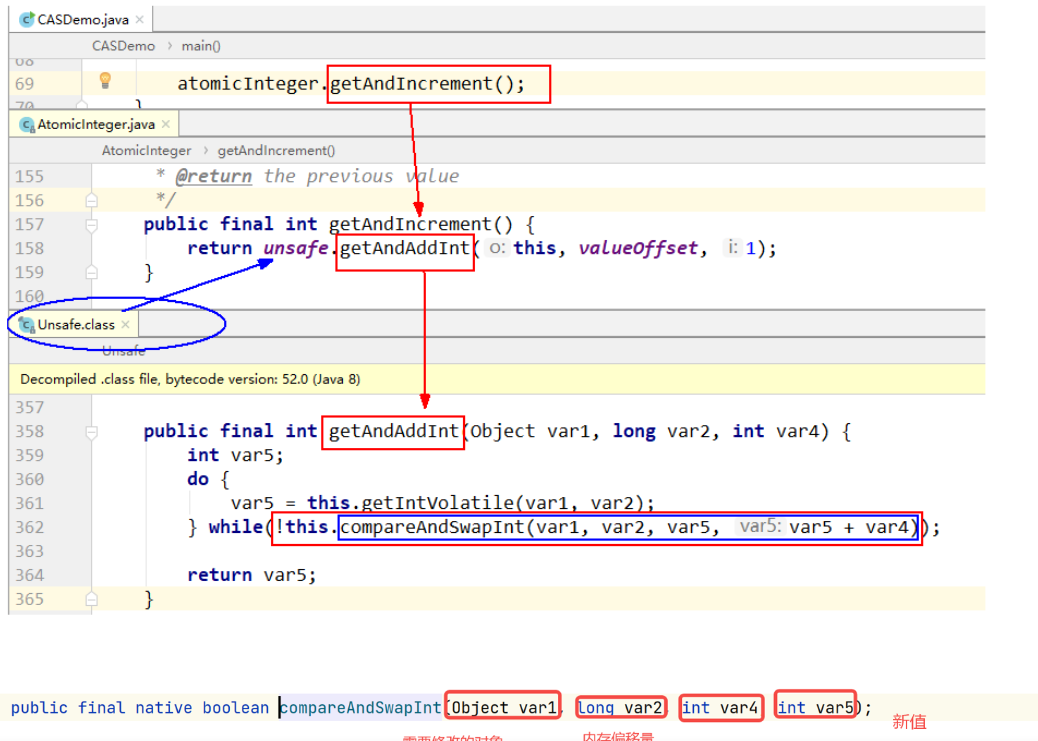
Dataframe是一种二维数据结构,数据以表格形式(与Excel类似)存储,有对应的行和列,如图3-3所示。它的每列可以是不同的值类型(不像 ndarray 只能有一个 dtype)。基本上可以把 DataFrame 看成是共享同一个 index 的 Series 的集合。
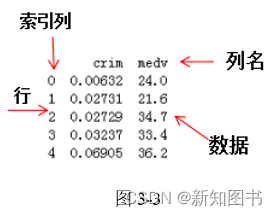
DataFrame 的构造方法与 Series 类似,只不过可以同时接受多条一维数据源,每一条都会成为单独的一列,演示代码如下。DataFrame创建方法比较丰富,可以通过字典、列表、ndarrays、Series对象创建而来。
import pandas as pd
data1 = [['Google',10],['Runoob',12],['Wiki',13]]
df1 = pd.DataFrame(data1,columns=['Site','Age'])
print(df1)
data2 = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df2 = pd.DataFrame(data2)
print (df2)
data3 = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df3 = pd.DataFrame(data3)
print (df3)
运行结果如图3-4所示。
如下面的代码所示,Pandas可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为0,第二行索引为1,以此类推。它也可以返回多行数据,使用[[ ... ]]格式,...为各行的索引,以逗号隔开。
import pandas as pd
data = {"calories": [420, 380, 390],"duration": [50, 40, 45]
}
#数据载入DataFrame对象
df = pd.DataFrame(data)
#返回第一行
print(df.loc[0])
#返回第二行和第三行
print(df.loc[[1, 2]])
运行结果如图3-5所示。

另外,也可以只获取 dataframe 中的几列,比如当处理数据的时候series较多,我们可以只关注其中一些特定的列,代码如下,假设只关注apple和banana数据列。
import pandas as pd
data2 = {"mango": [420, 380, 390],"apple": [50, 40, 45],"pear": [1, 2, 3],"banana": [23, 45,56]
}
df = pd.DataFrame(data2)
print(df[["apple","banana"]])
运行结果如图3-6所示。

本文节选自《PyTorch深度学习与企业级项目实战》,获出版社和作者授权发布。