🎈🎈作者主页: 喔的嘛呀🎈🎈
🎈🎈所属专栏:python爬虫学习🎈🎈
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨
目录
一、爬取豆瓣电影Top250信息:
二、爬取Github上的Python项目信息(只有一部分)
三、爬取知乎上关于Python话题下的热门问题和对应的回答:
总结
嘿嘿,小伙伴们,今天为了激发大家的学习兴趣。俺特的找了几个爬虫的小案例,给大家展示一下。话不多说,正片开始。(大家在爬取数据的时候,一定要注意合法合规)
一、爬取豆瓣电影Top250信息:
就是这个豆瓣电影页面,接下来我们就要把前250名的电影的电影名称与评分爬取下来保存到
douban_top250.csv文件中

豆瓣网站的反爬虫机制限制了请求的频率或者数据量。所以我们可以尝试在每次请求之间加入更长的延迟,以降低请求频率。另外,我们也可以尝试分批次进行请求,每次请求部分数据,然后合并结果。以下是一个分批次请求的示例代码:
import requests
from bs4 import BeautifulSoup
import csv
import time
import randomdef scrape_douban_top250(url):# 设置请求头headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}# 发起请求response = requests.get(url, headers=headers)# 解析网页内容soup = BeautifulSoup(response.text, 'html.parser')# 获取电影列表movies = soup.find_all('div', class_='item')return moviesdef save_to_csv(movies, filename):# 将电影信息保存到CSV文件中with open(filename, 'a', newline='', encoding='utf-8') as csvfile:csvwriter = csv.writer(csvfile)for movie in movies:title = movie.find('span', class_='title').get_text()rating = movie.find('span', class_='rating_num').get_text()csvwriter.writerow([title, rating])url = '<https://movie.douban.com/top250>'
filename = 'douban_top250.csv'# 创建CSV文件并写入表头
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:csvwriter = csv.writer(csvfile)csvwriter.writerow(['电影名称', '评分'])start = 0
while start < 250:# 循环爬取每页的电影信息movies = scrape_douban_top250(f'{url}?start={start}')save_to_csv(movies, filename)start += 25# 添加随机延迟,避免频繁请求被封禁time.sleep(random.uniform(1, 3))print('保存成功')添加请求头信息: 有些网站需要在请求中包含用户代理(User-Agent)信息,模拟浏览器访问。你可以尝试添加请求头信息来解决问题:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)结果展示:

二、爬取Github上的Python项目信息(只有一部分)
import requests
import csvdef get_python_projects():# 设置请求URL和参数url = '<https://api.github.com/search/repositories>'params = {'q': 'language:python','sort': 'stars','order': 'desc'}# 设置请求头,包括用户代理信息headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}# 发起GET请求response = requests.get(url, params=params, headers=headers)# 解析JSON响应data = response.json()projects = data['items']return projectsif __name__ == '__main__':# 获取项目信息projects = get_python_projects()# 写入CSV文件with open('github_python_projects.csv', 'w', newline='', encoding='utf-8') as csvfile:csvwriter = csv.writer(csvfile)# 写入表头csvwriter.writerow(['项目名称', '星标数', '项目地址'])# 遍历项目列表,写入每个项目的信息for project in projects:name = project['name']stars = project['stargazers_count']url = project['html_url']csvwriter.writerow([name, stars, url])print('保存成功')请确保替换代码中的 'Your User Agent' 为合适的用户代理信息。这段代码会将项目名称、星标数和项目地址保存到名为**github_python_projects.csv**的CSV文件中,并在控制台输出“保存成功”消息。
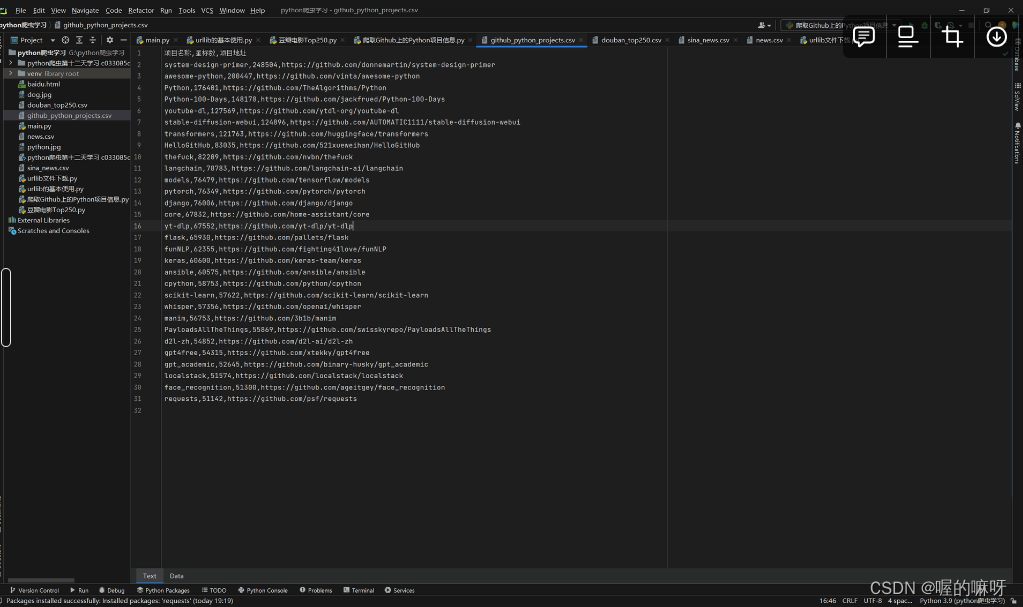
结果展示:
三、爬取知乎上关于Python话题下的热门问题和对应的回答:
import requests
from bs4 import BeautifulSoup
import csv
import textwrapurl = '<https://www.zhihu.com/topic/19552832/top-answers>'
headers = {'User-Agent': 'Your User Agent' # 替换为你的用户代理
}# 发送请求获取页面内容
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')# 解析页面获取问题和回答
questions = soup.select('.List-item')
data = []
for question in questions:title = question.select_one('.ContentItem-title').get_text()answer = question.select_one('.RichContent-inner').get_text()# 格式化回答文本,限制每行最大长度为80answer = '\\n'.join(textwrap.wrap(answer, width=80))data.append({'问题': title, '回答': answer})# 将结果保存到CSV文件中
with open('zhihu_python.csv', 'w', newline='', encoding='utf-8') as csvfile:fieldnames = ['问题', '回答']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader()for qa in data:writer.writerow(qa)print('保存成功')这段代码首先发送请求获取知乎Python话题下热门问题和回答的页面内容,然后使用BeautifulSoup解析页面,提取问题和回答信息。接着,使用textwrap模块对回答文本进行格式化,限制每行最大长度为80个字符。最后,将格式化后的结果保存到CSV文件中。
结果展示:

总结
当涉及Python爬虫学习时,案例对于激发兴趣和加深理解非常重要。在这个过程中,我们学习了如何使用Python中的requests和BeautifulSoup库来进行简单和复杂的网页数据抓取。
在这个过程中,我们从简单的示例开始,比如爬取百度首页的标题和链接,逐渐过渡到复杂的案例,比如爬取豆瓣电影Top250的详细信息和知乎上关于Python话题下的热门问题和回答。通过这些案例,我们学会了如何处理不同类型的网页内容,如何解析HTML,以及如何提取和保存感兴趣的数据。
在实际项目中,爬虫可以应用于许多领域,如数据采集、信息监控、搜索引擎优化等。掌握爬虫技术可以帮助我们更好地理解网络数据的结构和组织方式,并能够从中获取有用的信息。
总的来说,通过学习Python爬虫,我们不仅可以提升数据获取和处理的能力,还可以培养数据分析和挖掘的兴趣,为进一步深入学习和实践打下坚实的基础。
小伙伴们·,今天的展示就到这里了,希望可以在一定程度上可以激发你们学习的兴趣。温馨提示,不要乱爬取网站的敏感数据,一定要合法合规。








![【洛谷】P9236 [蓝桥杯 2023 省 A] 异或和之和](https://img-blog.csdnimg.cn/direct/0f0a394115bb46a683444993981ef117.png)