在工作中遇到异构数据库同步的问题,从Oracle数据库同步数据到Postgres,其中的很多数据库表超过百万,并且包含空间字段。经过筛选,选择了开源的DataX+DataX Web作为基础框架。DataX 是阿里云的开源产品,大厂的产品值得信赖,而且,DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久,每天完成同步8w多道作业,每日传输数据量超过300TB,经过了时间、实践的检验。这里顺便分析一下源码,看看大厂的程序员是怎么实现数据库的快速全表查询、写入操作,怎么进行多线程管理的。
部分内容参见:
GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。
DataX/introduction.md at master · alibaba/DataX · GitHub
DataX/dataxPluginDev.md at master · alibaba/DataX · GitHub
一、DataX介绍
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
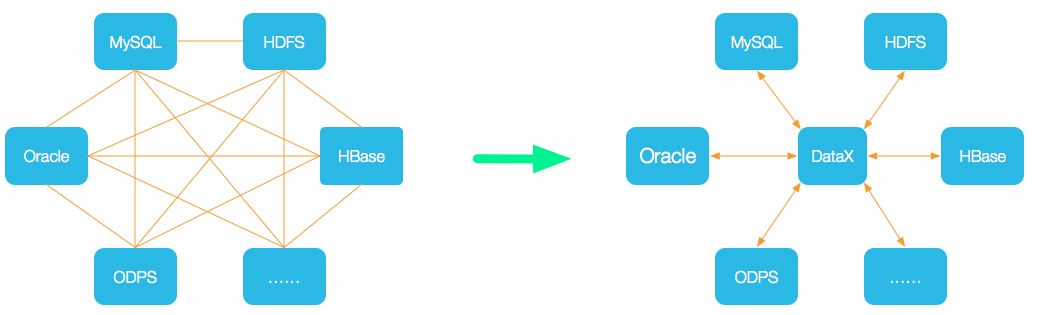
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
二、源码解析(基于DataX v202309版本)

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
2.1 Reader 源码解析(基于OracleReader插件)
以oraclereader插件为例,看一下Reader的代码。
oraclereader插件包括Constant.java、OracleReader.java和OracleReaderErrorCode.java三个Java类。先关注一下OracleReader,OracleReader继承Reader基类,在其中,通过内部类Task实现读取数据库操作,将读取的数据交由框架处理。具体为CommonRdbmsReader.Task来实现。在代码中包含了commonRdbmsReaderTask的初始化及读取数据操作等内容。核心为this.commonRdbmsReaderTask.startRead。
public static class Task extends Reader.Task {private Configuration readerSliceConfig;private CommonRdbmsReader.Task commonRdbmsReaderTask;@Overridepublic void init() {this.readerSliceConfig = super.getPluginJobConf();this.commonRdbmsReaderTask = new CommonRdbmsReader.Task(DATABASE_TYPE ,super.getTaskGroupId(), super.getTaskId());this.commonRdbmsReaderTask.init(this.readerSliceConfig);}@Overridepublic void startRead(RecordSender recordSender) {int fetchSize = this.readerSliceConfig.getInt(com.alibaba.datax.plugin.rdbms.reader.Constant.FETCH_SIZE);this.commonRdbmsReaderTask.startRead(this.readerSliceConfig,recordSender, super.getTaskPluginCollector(), fetchSize);}@Overridepublic void post() {this.commonRdbmsReaderTask.post(this.readerSliceConfig);}@Overridepublic void destroy() {this.commonRdbmsReaderTask.destroy(this.readerSliceConfig);}}CommonRdbmsReader.Task的startRead方法如下:
public void startRead(Configuration readerSliceConfig,RecordSender recordSender,TaskPluginCollector taskPluginCollector, int fetchSize) {String querySql = readerSliceConfig.getString(Key.QUERY_SQL);String table = readerSliceConfig.getString(Key.TABLE);PerfTrace.getInstance().addTaskDetails(taskId, table + "," + basicMsg);LOG.info("Begin to read record by Sql: [{}\n] {}.",querySql, basicMsg);PerfRecord queryPerfRecord = new PerfRecord(taskGroupId,taskId, PerfRecord.PHASE.SQL_QUERY);queryPerfRecord.start();Connection conn = DBUtil.getConnection(this.dataBaseType, jdbcUrl,username, password);// session config .etc relatedDBUtil.dealWithSessionConfig(conn, readerSliceConfig,this.dataBaseType, basicMsg);int columnNumber = 0;ResultSet rs = null;try {rs = DBUtil.query(conn, querySql, fetchSize);queryPerfRecord.end();ResultSetMetaData metaData = rs.getMetaData();columnNumber = metaData.getColumnCount();//这个统计干净的result_Next时间PerfRecord allResultPerfRecord = new PerfRecord(taskGroupId, taskId, PerfRecord.PHASE.RESULT_NEXT_ALL);allResultPerfRecord.start();long rsNextUsedTime = 0;long lastTime = System.nanoTime();while (rs.next()) {rsNextUsedTime += (System.nanoTime() - lastTime);this.transportOneRecord(recordSender, rs,metaData, columnNumber, mandatoryEncoding, taskPluginCollector);lastTime = System.nanoTime();}allResultPerfRecord.end(rsNextUsedTime);//目前大盘是依赖这个打印,而之前这个Finish read record是包含了sql查询和result next的全部时间LOG.info("Finished read record by Sql: [{}\n] {}.",querySql, basicMsg);}catch (Exception e) {throw RdbmsException.asQueryException(this.dataBaseType, e, querySql, table, username);} finally {DBUtil.closeDBResources(null, conn);}
}上述代码可见查询数据库的常规步骤,数据库操作通过原生JDBC实现。熟悉的味道,熟悉的配方。详细说明如下。
1.建立数据库链接
Connection conn = DBUtil.getConnection(this.dataBaseType, jdbcUrl,username, password);DBUtil内部通过原生Jdbc实现。代码如下:
private static synchronized Connection connect(DataBaseType dataBaseType,String url, Properties prop) {try {Class.forName(dataBaseType.getDriverClassName());DriverManager.setLoginTimeout(Constant.TIMEOUT_SECONDS);return DriverManager.getConnection(url, prop);} catch (Exception e) {throw RdbmsException.asConnException(dataBaseType, e, prop.getProperty("user"), null);}
}2.执行查询操作,返回ResultSet
ResultSet rs = null;
try {rs = DBUtil.query(conn, querySql, fetchSize);// 其他代码此处省略
}catch (Exception e) {throw RdbmsException.asQueryException(this.dataBaseType, e, querySql, table, username);
} finally {DBUtil.closeDBResources(null, conn);
} DBUtil内部查询实现代码如下。
/*** a wrapped method to execute select-like sql statement .** @param conn Database connection .* @param sql sql statement to be executed* @return a {@link ResultSet}* @throws SQLException if occurs SQLException.*/
public static ResultSet query(Connection conn, String sql, int fetchSize)throws SQLException {// 默认3600 s 的query Timeoutreturn query(conn, sql, fetchSize, Constant.SOCKET_TIMEOUT_INSECOND);
}/*** a wrapped method to execute select-like sql statement .** @param conn Database connection .* @param sql sql statement to be executed* @param fetchSize* @param queryTimeout unit:second* @return* @throws SQLException*/
public static ResultSet query(Connection conn, String sql, int fetchSize, int queryTimeout)throws SQLException {// make sure autocommit is offconn.setAutoCommit(false);Statement stmt = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY,ResultSet.CONCUR_READ_ONLY);stmt.setFetchSize(fetchSize);stmt.setQueryTimeout(queryTimeout);return query(stmt, sql);
}3.获取数据元数据信息
ResultSetMetaData metaData = rs.getMetaData();4.遍历数据,对数据进行转换并传递给框架
while (rs.next()) {rsNextUsedTime += (System.nanoTime() - lastTime);this.transportOneRecord(recordSender, rs,metaData, columnNumber, mandatoryEncoding, taskPluginCollector);lastTime = System.nanoTime();
}5.在finally块中关闭数据链接
finally {DBUtil.closeDBResources(null, conn);
} DBUtil内部关闭链接代码如下。很明显上述代码调用时只传入了connection,会造成只关闭链接,未关闭ResultSet和Statement,有瑕疵。
public static void closeDBResources(ResultSet rs, Statement stmt,Connection conn) {if (null != rs) {try {rs.close();} catch (SQLException unused) {}}if (null != stmt) {try {stmt.close();} catch (SQLException unused) {}}if (null != conn) {try {conn.close();} catch (SQLException unused) {}}
}public static void closeDBResources(Statement stmt, Connection conn) {closeDBResources(null, stmt, conn);
}在第2步DBUtil内部的查询代码部分,指定了fetchSize参数。
stmt.setFetchSize(fetchSize);fetchSize是实现读取数据源表的关键点之一。简单理解,fetchSize定义了本地缓存大小,例如,fetchSize=1000即可简单理解为本地缓存区大小为1000条数据大小,当执行ResultSet.next取数据时,如果本地缓存中没有数据,会从数据库中取出1000条(剩余数据大于1000时为1000,小于1000时为剩余数据)数据放到缓存中,接下来的rs.next操作就是从本地缓存中读取数据,直至缓存区为空才再次请求数据库。通过减少与数据库的交互次数,提升性能。
如果 fetchsize 设置的太小,会导致程序频繁地访问数据库,影响性能;如果 fetchsize 设置的太大,则可能会导致内存不足。在oraclereader插件的代码Constant.java中定义了fetchSize的默认值。
package com.alibaba.datax.plugin.reader.oraclereader;public class Constant {public static final int DEFAULT_FETCH_SIZE = 1024;}接下来我们看一下transportOneRecord的代码,该代码将一条数据进行转换后传递给Writer。
protected Record transportOneRecord(RecordSender recordSender, ResultSet rs, ResultSetMetaData metaData, int columnNumber, String mandatoryEncoding, TaskPluginCollector taskPluginCollector) {Record record = buildRecord(recordSender,rs,metaData,columnNumber,mandatoryEncoding,taskPluginCollector); recordSender.sendToWriter(record);return record;
}buildRecord方法将一条数据的各个字段按照类型转换为标准数据,方便后续各类数据库写入插件使用实现数据插入。如果数据中包含了不支持的其他字段类型,需要在SQL中通过转换函数进行转换,否则对于不支持的其他字段类型,或在转换过程中出现其他错误,这条数据将被作为脏数据扔掉。当然,也可以修改buildRecord方法代码,让DataX支持更多数据类型的查询和写入。代码如下:
protected Record buildRecord(RecordSender recordSender,ResultSet rs, ResultSetMetaData metaData, int columnNumber, String mandatoryEncoding,TaskPluginCollector taskPluginCollector) {Record record = recordSender.createRecord();try {for (int i = 1; i <= columnNumber; i++) {switch (metaData.getColumnType(i)) {case Types.CHAR:case Types.NCHAR:case Types.VARCHAR:case Types.LONGVARCHAR:case Types.NVARCHAR:case Types.LONGNVARCHAR:String rawData;if(StringUtils.isBlank(mandatoryEncoding)){rawData = rs.getString(i);}else{rawData = new String((rs.getBytes(i) == null ? EMPTY_CHAR_ARRAY : rs.getBytes(i)), mandatoryEncoding);}record.addColumn(new StringColumn(rawData));break;case Types.CLOB:case Types.NCLOB:record.addColumn(new StringColumn(rs.getString(i)));break;case Types.SMALLINT:case Types.TINYINT:case Types.INTEGER:case Types.BIGINT:record.addColumn(new LongColumn(rs.getString(i)));break;case Types.NUMERIC:case Types.DECIMAL:record.addColumn(new DoubleColumn(rs.getString(i)));break;case Types.FLOAT:case Types.REAL:case Types.DOUBLE:record.addColumn(new DoubleColumn(rs.getString(i)));break;case Types.TIME:record.addColumn(new DateColumn(rs.getTime(i)));break;// for mysql bug, see http://bugs.mysql.com/bug.php?id=35115case Types.DATE:if (metaData.getColumnTypeName(i).equalsIgnoreCase("year")) {record.addColumn(new LongColumn(rs.getInt(i)));} else {record.addColumn(new DateColumn(rs.getDate(i)));}break;case Types.TIMESTAMP:record.addColumn(new DateColumn(rs.getTimestamp(i)));break;case Types.BINARY:case Types.VARBINARY:case Types.BLOB:case Types.LONGVARBINARY:record.addColumn(new BytesColumn(rs.getBytes(i)));break;// warn: bit(1) -> Types.BIT 可使用BoolColumn// warn: bit(>1) -> Types.VARBINARY 可使用BytesColumncase Types.BOOLEAN:case Types.BIT:record.addColumn(new BoolColumn(rs.getBoolean(i)));break;case Types.NULL:String stringData = null;if(rs.getObject(i) != null) {stringData = rs.getObject(i).toString();}record.addColumn(new StringColumn(stringData));break;default:throw DataXException.asDataXException(DBUtilErrorCode.UNSUPPORTED_TYPE,String.format("您的配置文件中的列配置信息有误. 因为DataX 不支持数据库读取这种字段类型. 字段名:[%s], 字段名称:[%s], 字段Java类型:[%s]. 请尝试使用数据库函数将其转换datax支持的类型 或者不同步该字段 .",metaData.getColumnName(i),metaData.getColumnType(i),metaData.getColumnClassName(i)));}}} catch (Exception e) {if (IS_DEBUG) {LOG.debug("read data " + record.toString()+ " occur exception:", e);}//TODO 这里识别为脏数据靠谱吗?taskPluginCollector.collectDirtyRecord(record, e);if (e instanceof DataXException) {throw (DataXException) e;}}return record;
}2.2 关于扩展DataX数据库同步支持字段类型的思考
第一种方式:2.1中已提到过,如果要同步的数据源包含了DataX不支持的类型,可以通过数据库转换函数将字段转换为String等DataX支持的类型。例如对于Oracle Spatial字段可以通过Oracle Spatial函数SDO_UTIL.TO_WKTGEOMETRY将字段值转换为WKT文本空间数据格式。
第二种方式:如果数据库没有对应的转换函数,可以修改CommonRdbmsReader.Task类的buildRecord方法代码。同样的对于Oracle Spatial字段,是Types.STRUCT类型,可以根据其结构在buildRecord中自行将其转换为WKT文本空间数据格式。
第三种方式:对于某些类型的数据库特有的类型,也可以通过第二种方式进行扩展,但是会造成多余的依赖,例如还是Oracle Spatial的字段,如果通过oracle.sql.STRUCT进行解析,这样就会造成CommonRdbmsReader依赖Oracle驱动,进而造成所有涉及关系型数据库的同步都需要依赖oracle驱动,即使可能只是从MySQL同步数据到MySQL。这样更好的方式是在对应的reader或writer中扩展对应的数据类型处理逻辑。在oraclereader中使用CommonRdbmsReader.Task的子类,在子类中重写buildRecord方法。以下为OracleReader.Task类的init方法,在初始化commonRdbmsReaderTask 时,使用内部子类,子类重写buildRecord方法增加特定类型的转换逻辑。在switch块,default分支处理前。
@Override
public void init() {this.readerSliceConfig = super.getPluginJobConf();this.commonRdbmsReaderTask = new CommonRdbmsReader.Task(DATABASE_TYPE ,super.getTaskGroupId(), super.getTaskId()){@Overrideprotected Record buildRecord(RecordSender recordSender,ResultSet rs, ResultSetMetaData metaData, int columnNumber, String mandatoryEncoding,TaskPluginCollector taskPluginCollector) {Record record = recordSender.createRecord();try {for (int i = 1; i <= columnNumber; i++) {switch (metaData.getColumnType(i)) {case Types.CHAR:case Types.NCHAR:case Types.VARCHAR:case Types.LONGVARCHAR:case Types.NVARCHAR:case Types.LONGNVARCHAR:String rawData;if(StringUtils.isBlank(mandatoryEncoding)){rawData = rs.getString(i);}else{rawData = new String((rs.getBytes(i) == null ? EMPTY_CHAR_ARRAY : rs.getBytes(i)), mandatoryEncoding);}record.addColumn(new StringColumn(rawData));break;case Types.CLOB:case Types.NCLOB:record.addColumn(new StringColumn(rs.getString(i)));break;case Types.SMALLINT:case Types.TINYINT:case Types.INTEGER:case Types.BIGINT:record.addColumn(new LongColumn(rs.getString(i)));break;case Types.NUMERIC:case Types.DECIMAL:record.addColumn(new DoubleColumn(rs.getString(i)));break;case Types.FLOAT:case Types.REAL:case Types.DOUBLE:record.addColumn(new DoubleColumn(rs.getString(i)));break;case Types.TIME:record.addColumn(new DateColumn(rs.getTime(i)));break;// for mysql bug, see http://bugs.mysql.com/bug.php?id=35115case Types.DATE:if (metaData.getColumnTypeName(i).equalsIgnoreCase("year")) {record.addColumn(new LongColumn(rs.getInt(i)));} else {record.addColumn(new DateColumn(rs.getDate(i)));}break;case Types.TIMESTAMP:record.addColumn(new DateColumn(rs.getTimestamp(i)));break;case Types.BINARY:case Types.VARBINARY:case Types.BLOB:case Types.LONGVARBINARY:record.addColumn(new BytesColumn(rs.getBytes(i)));break;// warn: bit(1) -> Types.BIT 可使用BoolColumn// warn: bit(>1) -> Types.VARBINARY 可使用BytesColumncase Types.BOOLEAN:case Types.BIT:record.addColumn(new BoolColumn(rs.getBoolean(i)));break;case Types.NULL:String stringData = null;if(rs.getObject(i) != null) {stringData = rs.getObject(i).toString();}record.addColumn(new StringColumn(stringData));break;// 在此处增加对oracle特定类型的处理逻辑default:throw DataXException.asDataXException(DBUtilErrorCode.UNSUPPORTED_TYPE,String.format("您的配置文件中的列配置信息有误. 因为DataX 不支持数据库读取这种字段类型. 字段名:[%s], 字段名称:[%s], 字段Java类型:[%s]. 请尝试使用数据库函数将其转换datax支持的类型 或者不同步该字段 .",metaData.getColumnName(i),metaData.getColumnType(i),metaData.getColumnClassName(i)));}}} catch (Exception e) {if (IS_DEBUG) {LOG.debug("read data " + record.toString()+ " occur exception:", e);}//TODO 这里识别为脏数据靠谱吗?taskPluginCollector.collectDirtyRecord(record, e);if (e instanceof DataXException) {throw (DataXException) e;}}return record;}};this.commonRdbmsReaderTask.init(this.readerSliceConfig);
}上面的方式会产生很多重复代码。为了进一步优化,我们可以为CommonRdbmsReader.Task增加一个扩展点。
protected Record buildRecord(RecordSender recordSender,ResultSet rs, ResultSetMetaData metaData, int columnNumber, String mandatoryEncoding,TaskPluginCollector taskPluginCollector) {Record record = recordSender.createRecord();try {for (int i = 1; i <= columnNumber; i++) {switch (metaData.getColumnType(i)) {case Types.CHAR:case Types.NCHAR:case Types.VARCHAR:case Types.LONGVARCHAR:case Types.NVARCHAR:case Types.LONGNVARCHAR:String rawData;if(StringUtils.isBlank(mandatoryEncoding)){rawData = rs.getString(i);}else{rawData = new String((rs.getBytes(i) == null ? EMPTY_CHAR_ARRAY : rs.getBytes(i)), mandatoryEncoding);}record.addColumn(new StringColumn(rawData));break;case Types.CLOB:case Types.NCLOB:record.addColumn(new StringColumn(rs.getString(i)));break;case Types.SMALLINT:case Types.TINYINT:case Types.INTEGER:case Types.BIGINT:record.addColumn(new LongColumn(rs.getString(i)));break;case Types.NUMERIC:case Types.DECIMAL:record.addColumn(new DoubleColumn(rs.getString(i)));break;case Types.FLOAT:case Types.REAL:case Types.DOUBLE:record.addColumn(new DoubleColumn(rs.getString(i)));break;case Types.TIME:record.addColumn(new DateColumn(rs.getTime(i)));break;// for mysql bug, see http://bugs.mysql.com/bug.php?id=35115case Types.DATE:if (metaData.getColumnTypeName(i).equalsIgnoreCase("year")) {record.addColumn(new LongColumn(rs.getInt(i)));} else {record.addColumn(new DateColumn(rs.getDate(i)));}break;case Types.TIMESTAMP:record.addColumn(new DateColumn(rs.getTimestamp(i)));break;case Types.BINARY:case Types.VARBINARY:case Types.BLOB:case Types.LONGVARBINARY:record.addColumn(new BytesColumn(rs.getBytes(i)));break;// warn: bit(1) -> Types.BIT 可使用BoolColumn// warn: bit(>1) -> Types.VARBINARY 可使用BytesColumncase Types.BOOLEAN:case Types.BIT:record.addColumn(new BoolColumn(rs.getBoolean(i)));break;case Types.NULL:String stringData = null;if(rs.getObject(i) != null) {stringData = rs.getObject(i).toString();}record.addColumn(new StringColumn(stringData));break;default:buildColumn(record, i, rs, metaData, mandatoryEncoding); }}} catch (Exception e) {if (IS_DEBUG) {LOG.debug("read data " + record.toString()+ " occur exception:", e);}//TODO 这里识别为脏数据靠谱吗?taskPluginCollector.collectDirtyRecord(record, e);if (e instanceof DataXException) {throw (DataXException) e;}}return record;
}
// 新增的扩展点,可以在子类中处理特殊的字段类型
protected Record buildColumn(Record record, int columnIndex, ResultSet rs, ResultSetMetaData metaData, String mandatoryEncoding){throw DataXException.asDataXException(DBUtilErrorCode.UNSUPPORTED_TYPE,String.format("您的配置文件中的列配置信息有误. 因为DataX 不支持数据库读取这种字段类型. 字段名:[%s], 字段名称:[%s], 字段Java类型:[%s]. 请尝试使用数据库函数将其转换datax支持的类型 或者不同步该字段 .",metaData.getColumnName(i),metaData.getColumnType(i),metaData.getColumnClassName(i)));
}这样,我们在oraclereader中,创建CommonRdbmsReader.Task的子类用于处理特殊字段类型时,只需要重写buildColumn方法即可。这样代码就简洁多了。
@Override
public void init() {this.readerSliceConfig = super.getPluginJobConf();this.commonRdbmsReaderTask = new CommonRdbmsReader.Task(DATABASE_TYPE ,super.getTaskGroupId(), super.getTaskId()){@Overridevoid buildColumn(Record record, int columnIndex, ResultSet rs, ResultSetMetaData metaData, String mandatoryEncoding) {switch (metaData.getColumnType(columnIndex)) {// 在此处增加对oracle特定类型的处理逻辑// 解析完成后将数据通过record.addColumn加入到record中default:// 不进行处理的其他类型字段可以继续抛出异常super.buildColumn(record, columnIndex, rs, metaData, mandatoryEncoding);}}};this.commonRdbmsReaderTask.init(this.readerSliceConfig);
}2.3 Writer代码解析(基于postgresqlwriter插件)
PostgresqlWriter类继承Writer基类。操作数据库的部分封装在其static类型内部类Task中。
public static class Task extends Writer.Task {private Configuration writerSliceConfig;private CommonRdbmsWriter.Task commonRdbmsWriterSlave;@Overridepublic void init() {this.writerSliceConfig = super.getPluginJobConf();this.commonRdbmsWriterSlave = new CommonRdbmsWriter.Task(DATABASE_TYPE){@Overridepublic String calcValueHolder(String columnType){if("serial".equalsIgnoreCase(columnType)){return "?::int";}else if("bigserial".equalsIgnoreCase(columnType)){return "?::int8";}else if("bit".equalsIgnoreCase(columnType)){return "?::bit varying";}return "?::" + columnType;}};this.commonRdbmsWriterSlave.init(this.writerSliceConfig);}@Overridepublic void prepare() {this.commonRdbmsWriterSlave.prepare(this.writerSliceConfig);}public void startWrite(RecordReceiver recordReceiver) {this.commonRdbmsWriterSlave.startWrite(recordReceiver, this.writerSliceConfig, super.getTaskPluginCollector());}@Overridepublic void post() {this.commonRdbmsWriterSlave.post(this.writerSliceConfig);}@Overridepublic void destroy() {this.commonRdbmsWriterSlave.destroy(this.writerSliceConfig);}}1. 建立数据库链接
this.commonRdbmsWriterSlave.startWrite 通过DBUtil建立了数据库链接。
// TODO 改用连接池,确保每次获取的连接都是可用的(注意:连接可能需要每次都初始化其 session)
public void startWrite(RecordReceiver recordReceiver,Configuration writerSliceConfig,TaskPluginCollector taskPluginCollector) {Connection connection = DBUtil.getConnection(this.dataBaseType,this.jdbcUrl, username, password);DBUtil.dealWithSessionConfig(connection, writerSliceConfig,this.dataBaseType, BASIC_MESSAGE);startWriteWithConnection(recordReceiver, taskPluginCollector, connection);
}接下来开始操作数据。
public void startWriteWithConnection(RecordReceiver recordReceiver, TaskPluginCollector taskPluginCollector, Connection connection) {this.taskPluginCollector = taskPluginCollector;// 用于写入数据的时候的类型根据目的表字段类型转换this.resultSetMetaData = DBUtil.getColumnMetaData(connection,this.table, StringUtils.join(this.columns, ","));// 写数据库的SQL语句calcWriteRecordSql();List<Record> writeBuffer = new ArrayList<Record>(this.batchSize);int bufferBytes = 0;try {Record record;while ((record = recordReceiver.getFromReader()) != null) {if (record.getColumnNumber() != this.columnNumber) {// 源头读取字段列数与目的表字段写入列数不相等,直接报错throw DataXException.asDataXException(DBUtilErrorCode.CONF_ERROR,String.format("列配置信息有错误. 因为您配置的任务中,源头读取字段数:%s 与 目的表要写入的字段数:%s 不相等. 请检查您的配置并作出修改.",record.getColumnNumber(),this.columnNumber));}writeBuffer.add(record);bufferBytes += record.getMemorySize();if (writeBuffer.size() >= batchSize || bufferBytes >= batchByteSize) {doBatchInsert(connection, writeBuffer);writeBuffer.clear();bufferBytes = 0;}}if (!writeBuffer.isEmpty()) {doBatchInsert(connection, writeBuffer);writeBuffer.clear();bufferBytes = 0;}} catch (Exception e) {throw DataXException.asDataXException(DBUtilErrorCode.WRITE_DATA_ERROR, e);} finally {writeBuffer.clear();bufferBytes = 0;DBUtil.closeDBResources(null, null, connection);}
}2. 获取目标表元数据信息
DataX 的Writer通过PreparedStatement预编译语句实现数据库写入操作。需要提前基于数据库链接、数据库表、字段信息获取各字段的类型,以便后续根据字段类型进行合理赋值。
// 用于写入数据的时候的类型根据目的表字段类型转换
this.resultSetMetaData = DBUtil.getColumnMetaData(connection,this.table, StringUtils.join(this.columns, ","));具体通过构建一条查询语句获取表字段元数据信息。因为只需要获取元数据,而不需要查询具体数据,queryColumnSql 的条件被设置为where 1=2。在获取完元数据信息之后会将Statement、ResultSet关闭,需要将元数据转存,此处转存到columnMetaData中。注意,finally块中不能关闭connection。
/*** @return Left:ColumnName Middle:ColumnType Right:ColumnTypeName*/
public static Triple<List<String>, List<Integer>, List<String>> getColumnMetaData(Connection conn, String tableName, String column) {Statement statement = null;ResultSet rs = null;Triple<List<String>, List<Integer>, List<String>> columnMetaData = new ImmutableTriple<List<String>, List<Integer>, List<String>>(new ArrayList<String>(), new ArrayList<Integer>(),new ArrayList<String>());try {statement = conn.createStatement();String queryColumnSql = "select " + column + " from " + tableName+ " where 1=2";rs = statement.executeQuery(queryColumnSql);ResultSetMetaData rsMetaData = rs.getMetaData();for (int i = 0, len = rsMetaData.getColumnCount(); i < len; i++) {columnMetaData.getLeft().add(rsMetaData.getColumnName(i + 1));columnMetaData.getMiddle().add(rsMetaData.getColumnType(i + 1));columnMetaData.getRight().add(rsMetaData.getColumnTypeName(i + 1));}return columnMetaData;} catch (SQLException e) {throw DataXException.asDataXException(DBUtilErrorCode.GET_COLUMN_INFO_FAILED,String.format("获取表:%s 的字段的元信息时失败. 请联系 DBA 核查该库、表信息.", tableName), e);} finally {DBUtil.closeDBResources(rs, statement, null);}
}3. 根据表名、列信息构建写入语句
接下来需要构建带占位符的写入语句。写入语句大概长这样:insert into table_name(column_name) values(?)
// 写数据库的SQL语句
calcWriteRecordSql();具体组装代码有好几处。
例如:OriginalConfPretreatmentUtil类的dealWriteMode方法。
public static void dealWriteMode(Configuration originalConfig, DataBaseType dataBaseType) {List<String> columns = originalConfig.getList(Key.COLUMN, String.class);String jdbcUrl = originalConfig.getString(String.format("%s[0].%s",Constant.CONN_MARK, Key.JDBC_URL, String.class));// 默认为:insert 方式String writeMode = originalConfig.getString(Key.WRITE_MODE, "INSERT");List<String> valueHolders = new ArrayList<String>(columns.size());for (int i = 0; i < columns.size(); i++) {valueHolders.add("?");}boolean forceUseUpdate = false;//ob10的处理if (dataBaseType == DataBaseType.MySql && isOB10(jdbcUrl)) {forceUseUpdate = true;}String writeDataSqlTemplate = WriterUtil.getWriteTemplate(columns, valueHolders, writeMode,dataBaseType, forceUseUpdate);LOG.info("Write data [\n{}\n], which jdbcUrl like:[{}]", writeDataSqlTemplate, jdbcUrl);originalConfig.set(Constant.INSERT_OR_REPLACE_TEMPLATE_MARK, writeDataSqlTemplate);
}4. 执行批量写入
循环获取record,通过witeBuffer.size() 和 数据量的大小控制每次执行批量写入操作的数据量。具体批量写入数据库操作代码见doBatchInsert方法。
Record record;
while ((record = recordReceiver.getFromReader()) != null) {if (record.getColumnNumber() != this.columnNumber) {// 源头读取字段列数与目的表字段写入列数不相等,直接报错throw DataXException.asDataXException(DBUtilErrorCode.CONF_ERROR,String.format("列配置信息有错误. 因为您配置的任务中,源头读取字段数:%s 与 目的表要写入的字段数:%s 不相等. 请检查您的配置并作出修改.",record.getColumnNumber(),this.columnNumber));}writeBuffer.add(record);bufferBytes += record.getMemorySize();if (writeBuffer.size() >= batchSize || bufferBytes >= batchByteSize) {doBatchInsert(connection, writeBuffer);writeBuffer.clear();bufferBytes = 0;}
}
if (!writeBuffer.isEmpty()) {doBatchInsert(connection, writeBuffer);writeBuffer.clear();bufferBytes = 0;
}protected void doBatchInsert(Connection connection, List<Record> buffer)throws SQLException {PreparedStatement preparedStatement = null;try {// 设置手动提交事务connection.setAutoCommit(false);// 构建预编译语句preparedStatement = connection.prepareStatement(this.writeRecordSql);// 循环添加for (Record record : buffer) {// 添加实际字段参数preparedStatement = fillPreparedStatement(preparedStatement, record);preparedStatement.addBatch();}// 提交事务preparedStatement.executeBatch();connection.commit();} catch (SQLException e) {LOG.warn("回滚此次写入, 采用每次写入一行方式提交. 因为:" + e.getMessage());connection.rollback();doOneInsert(connection, buffer);} catch (Exception e) {throw DataXException.asDataXException(DBUtilErrorCode.WRITE_DATA_ERROR, e);} finally {// 关闭preparedStatement,注意此处不会关闭connectionDBUtil.closeDBResources(preparedStatement, null);}
}fillPreparedStatement及之后的fillPreparedStatementColumnType决定了写入操作支持的通用数据类型。如果字段包含不支持的数据类型,会抛出异常。
// 直接使用了两个类变量:columnNumber,resultSetMetaData
protected PreparedStatement fillPreparedStatement(PreparedStatement preparedStatement, Record record)throws SQLException {for (int i = 0; i < this.columnNumber; i++) {int columnSqltype = this.resultSetMetaData.getMiddle().get(i);String typeName = this.resultSetMetaData.getRight().get(i);preparedStatement = fillPreparedStatementColumnType(preparedStatement, i, columnSqltype, typeName, record.getColumn(i));}return preparedStatement;
}protected PreparedStatement fillPreparedStatementColumnType(PreparedStatement preparedStatement, int columnIndex,int columnSqltype, String typeName, Column column) throws SQLException {java.util.Date utilDate;switch (columnSqltype) {case Types.CHAR:case Types.NCHAR:case Types.CLOB:case Types.NCLOB:case Types.VARCHAR:case Types.LONGVARCHAR:case Types.NVARCHAR:case Types.LONGNVARCHAR:preparedStatement.setString(columnIndex + 1, column.asString());break;case Types.SMALLINT:case Types.INTEGER:case Types.BIGINT:case Types.NUMERIC:case Types.DECIMAL:case Types.FLOAT:case Types.REAL:case Types.DOUBLE:String strValue = column.asString();if (emptyAsNull && "".equals(strValue)) {preparedStatement.setString(columnIndex + 1, null);} else {preparedStatement.setString(columnIndex + 1, strValue);}break;//tinyint is a little special in some database like mysql {boolean->tinyint(1)}case Types.TINYINT:Long longValue = column.asLong();if (null == longValue) {preparedStatement.setString(columnIndex + 1, null);} else {preparedStatement.setString(columnIndex + 1, longValue.toString());}break;// for mysql bug, see http://bugs.mysql.com/bug.php?id=35115case Types.DATE:if (typeName == null) {typeName = this.resultSetMetaData.getRight().get(columnIndex);}if (typeName.equalsIgnoreCase("year")) {if (column.asBigInteger() == null) {preparedStatement.setString(columnIndex + 1, null);} else {preparedStatement.setInt(columnIndex + 1, column.asBigInteger().intValue());}} else {java.sql.Date sqlDate = null;try {utilDate = column.asDate();} catch (DataXException e) {throw new SQLException(String.format("Date 类型转换错误:[%s]", column));}if (null != utilDate) {sqlDate = new java.sql.Date(utilDate.getTime());}preparedStatement.setDate(columnIndex + 1, sqlDate);}break;case Types.TIME:java.sql.Time sqlTime = null;try {utilDate = column.asDate();} catch (DataXException e) {throw new SQLException(String.format("TIME 类型转换错误:[%s]", column));}if (null != utilDate) {sqlTime = new java.sql.Time(utilDate.getTime());}preparedStatement.setTime(columnIndex + 1, sqlTime);break;case Types.TIMESTAMP:java.sql.Timestamp sqlTimestamp = null;try {utilDate = column.asDate();} catch (DataXException e) {throw new SQLException(String.format("TIMESTAMP 类型转换错误:[%s]", column));}if (null != utilDate) {sqlTimestamp = new java.sql.Timestamp(utilDate.getTime());}preparedStatement.setTimestamp(columnIndex + 1, sqlTimestamp);break;case Types.BINARY:case Types.VARBINARY:case Types.BLOB:case Types.LONGVARBINARY:preparedStatement.setBytes(columnIndex + 1, column.asBytes());break;case Types.BOOLEAN:preparedStatement.setBoolean(columnIndex + 1, column.asBoolean());break;// warn: bit(1) -> Types.BIT 可使用setBoolean// warn: bit(>1) -> Types.VARBINARY 可使用setBytescase Types.BIT:if (this.dataBaseType == DataBaseType.MySql) {preparedStatement.setBoolean(columnIndex + 1, column.asBoolean());} else {preparedStatement.setString(columnIndex + 1, column.asString());}break;default:throw DataXException.asDataXException(DBUtilErrorCode.UNSUPPORTED_TYPE,String.format("您的配置文件中的列配置信息有误. 因为DataX 不支持数据库写入这种字段类型. 字段名:[%s], 字段类型:[%d], 字段Java类型:[%s]. 请修改表中该字段的类型或者不同步该字段.",this.resultSetMetaData.getLeft().get(columnIndex),this.resultSetMetaData.getMiddle().get(columnIndex),this.resultSetMetaData.getRight().get(columnIndex)));}return preparedStatement;
}
对于Writer增加支持的字段类型,可以参见2.2。修改上面的方法,将将default内容替换为扩展点函数。在应用时于具体的Write子类中创建CommonRdbmsWriter.Task的子类,扩展支持的字段类型。
5. 关闭数据源
数据同步完毕,在finally块中清空标记变量、关闭数据源。
finally {writeBuffer.clear();bufferBytes = 0;DBUtil.closeDBResources(null, null, connection);
}
![【洛谷】P9236 [蓝桥杯 2023 省 A] 异或和之和](https://img-blog.csdnimg.cn/direct/0f0a394115bb46a683444993981ef117.png)