文章目录
一、数据集
二、网络结构
三、完整文件目录介绍
四、测试分析
一、数据集
1、数据格式:图像数据(JPG格式),采用labelme标注后的图像(XML格式),训练需要的TXT格式
2、数据来源:公共火灾数据库或特定行业机构收集的火灾图像数据
3、数据获取方式:通过API接口或数据下载平台获取数据
4、数据特点:包含火灾和非火灾图像样本,标记了火灾区域的相关信息
5、数据规模:2059张火灾图像样本
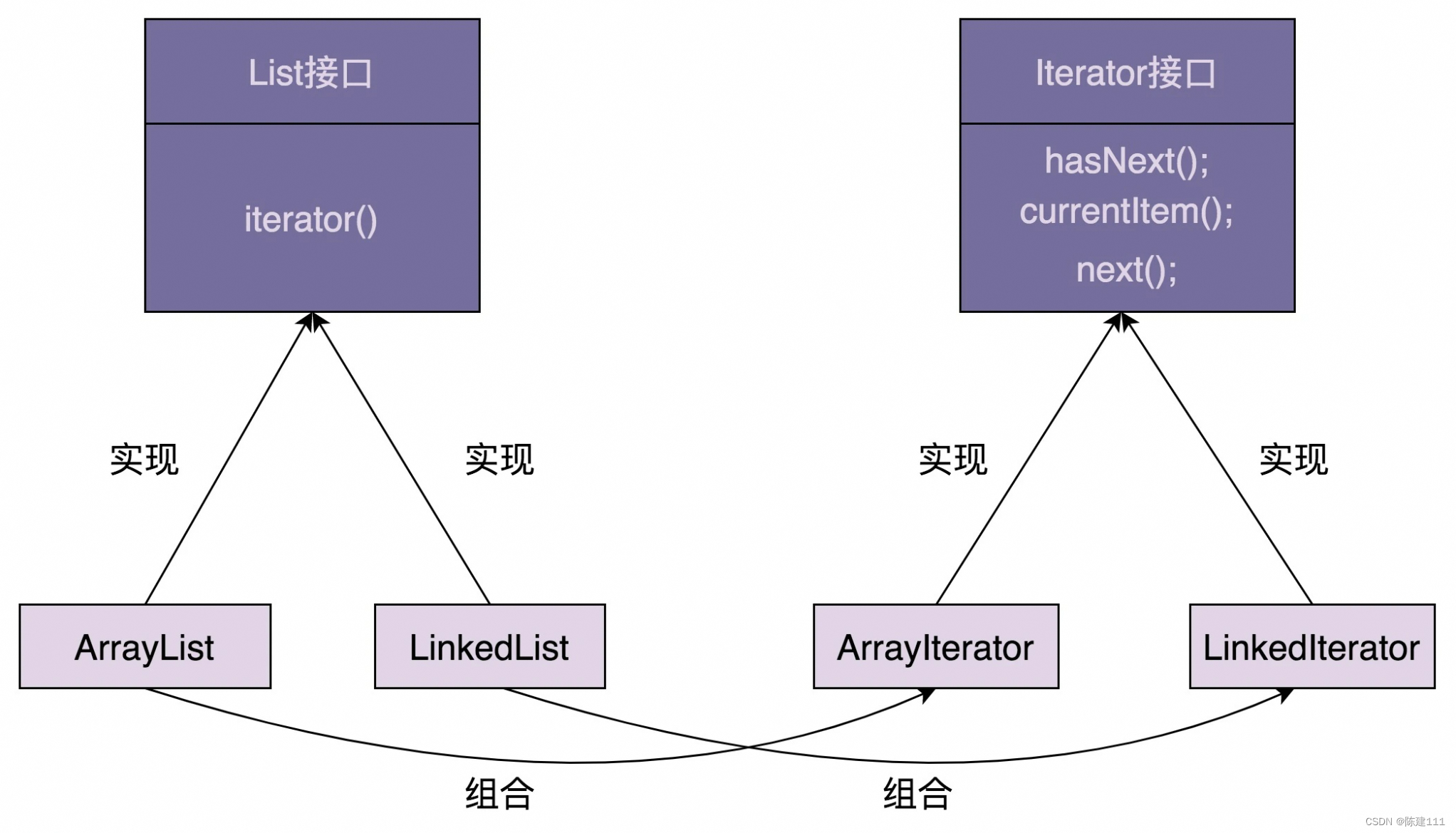
二、网络结构



在图像输入时对图像进行了 Mosaic 数据增强操作并且在进行推理时采用了自适应缩放操作,该方法可根据输入图像尺寸大小的不同进行自适应填充,提升了 37%的推理速度。其次,还设计了位于网络最前端的 Focus 结构,该结构最主要的内容是对输入数据进行切片操作,可有效提升图片特征提取的质量。YOLOv5 设计了两种与 YOLOv4 结构中使用的相同的 CSP 网络结构,并且将其用于 Backbone 层和 Neck 层。Neck 层采用了 FPN+PAN(Perceptual Adversarial Network)结合的方式,不同的是 YOLOv4 中使用的都是普通卷积操作而 YOLOv5使用了新设计的 CSP 结构,这也增强了网络对特征的融合能力。在输出端,YOLOv5 使用的是GIOU_Loss 做为 Bounding box 的损失函数并且在进行非最大值抑制时使用了加权非最大值抑制,这在不增加计算资源的情况下对检测图像中一些有重叠的目标检测效果较好。最重要的是,YOLOv5 的四种版本的切换不需要修改大量的代码,仅需要更换不同的 yaml 文件即可,YOLOv5 将模型的深度和广度做到了仅用两个参数 depth_multiple 和 width_multiple 来控制,四种模型的 yaml 文件只有这两个参数不同,但是最终训练的模型却差异非常大。表面上只有这两个参数不同,但其实后面各层之间的模块数量、卷积核大小和数量等也都产生了变化,YOLOv5l 与 YOLOv5s 相比较起来训练参数的大小成倍数增长,其模型的深度和宽度也会大很多,这就使得 YOLOv5l 的学习能力要比 YOLOv5s好很多,因此在最终推理时的模型也会比 YOLOv5s 大、推理速度慢,但是检测精度高。所以 YOLOv5 提供了不同的选择,如果想要追求推理速度可选用较小一些的模型如 YOLOv5s、YOLOv5m,如果想要追求精度更高对推理速度要求不高的可以选择其他两个稍大的模型。
三、完整文件目录介绍
Yolov5官方模型改进,主要选择yolov5x,效果较好
AttentionModule.py—注意力机制模块(在 YOLOv5 中添加注意力机制可以帮助模型更好地学习到关键特征,提高目标检测的性能和精度。
1. 提高关注度:注意力机制可以使模型更加关注重要的特征,减少不必要的背景干扰,从而提高目标检测的准确性。
2. 增强特征表征:通过引入注意力机制,模型可以学习到更具有代表性的特征表示,有助于更好地区分火灾目标与其他物体。
3. 增强泛化能力:注意力机制有助于模型对不同尺度、姿态和光照条件下的火灾目标进行更好的检测,提高模型的泛化能力。
4. 改善鲁棒性:引入注意力机制可以帮助模型更好地适应不同环境下的输入图像变化,提升系统的鲁棒性,降低误报率。)
Tongji.py—统计xml文件中的标签数量
Detect_qt5—改进后的预测函数(在detect函数中,官方对于视频、摄像头检测是从每秒的视频中抽取30帧,对每帧进行检测。同理,先试着使用pyqt显示视频、摄像头在界面上。显示视频原理为:使用QFileDialog.getOpenFileName函数打开一个视频文件,得到视频文件的地址,使用self.cap_video=cv2.VideoCapture()打开视频,使用flag, self.image = self.cap_video.read(),获取视频的每一帧,然后把每一帧显示(和图片显示基本一样)在label控件上面,不过注意的是要使用到定时器,self.timer_camera1 = QtCore.QTimer()。显示实时摄像头原理为:self.cap = cv2.VideoCapture(),参数为空时候打开摄像头。flag, self.image = self.cap.read(),获取摄像头的每一帧,然后把每一帧显示。(也需要用到定时器把每一帧的检测图片传给detect函数,进行检测,并把返回值图像绘制在label控件上面。准备工作做好,你执行detect.py文件,会自动检测 data/images目录下的图片,并且在runs/detect/exp下面生成标注好的图片。可以在点击检测时候,把之前获取到的待检测图片复制一份到data/images目录下,然后执行detect.py,在runs/detect/exp里面获取标注好的图片,并且显示在界面上。可以把detect.py的主函数封装为一个子函数,在这个里面直接调用封装好的子函数,把模型加载部分单独拿出来,在第一次界面打开时候加载,之后就不需要加载。在detect.py文件中,detect函数里面找到加载模型的部分,拿出来写成一个子函数,然后在执行detect函数时候,把model作为参数传入进去。)GridSearchCV.py--在训练阶段应用超参数搜索算法来优化模型的性能。在目标检测系统中,通常会在训练阶段使用超参数搜索来调整模型的参数,以获得更好的检测准确性和泛化能力。在训练阶段应用超参数搜索有助于找到最佳的超参数组合,从而改善模型的性能。一旦通过超参数搜索得到了最佳的超参数配置,就可以使用这些参数进行模型训练,以便在实际应用中获得更好的检测效果。
detect_image.py在预测过程中将detect中对图片处理的部分拿出来单独进行预测
detect_video.py在预测过程中对视频提取帧单独进行预测
fire文件夹 存放数据集及单独的fire_model.yaml 和fire_parameter.yaml 意为fire的参数配置和模型,修改其训练集的标签种类
四、测试分析
1、目标检测性能指标
| 检测精度 | 检测速度 |
| Precision,Recall,F1 score | 前传耗时 |
| IoU(Intersection over Union) | 每秒帧数 FPS(Frames Per Sencond) |
| P-R curve | 浮点运算量(FLOPS) |
| AP、mAP |
表1 目标检测性能指标
2、 验证集的实际标签和预测标签对比


3、结果显示模型性能
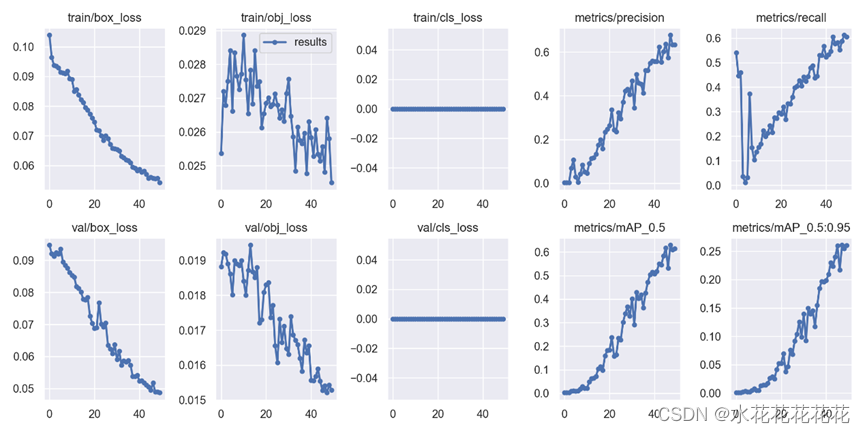
观察各损失函数的数值变化,由定位可得可知本模型是较为准确的预测结果。从图9中可以看到各损失函数的变化不是很大,说明训练结果较好。
Precision:精度(找对的正类/所有找到的正类);
Recall:真实为positive的准确率,即正样本有多少被找出来了(召回了多少)。Recall从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。
mAP是用Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值,@0.5:0.95表示阈值取0.5:0.05:0.95后取均值。
mAP@.5:.95(mAP@[.5:.95])表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
mAP@.5:表示阈值大于0.5的平均mAP
一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好),此模型的结果可视化可观察到训练结果是较为准确的。
4、查准率和召回率的调和平均数曲线
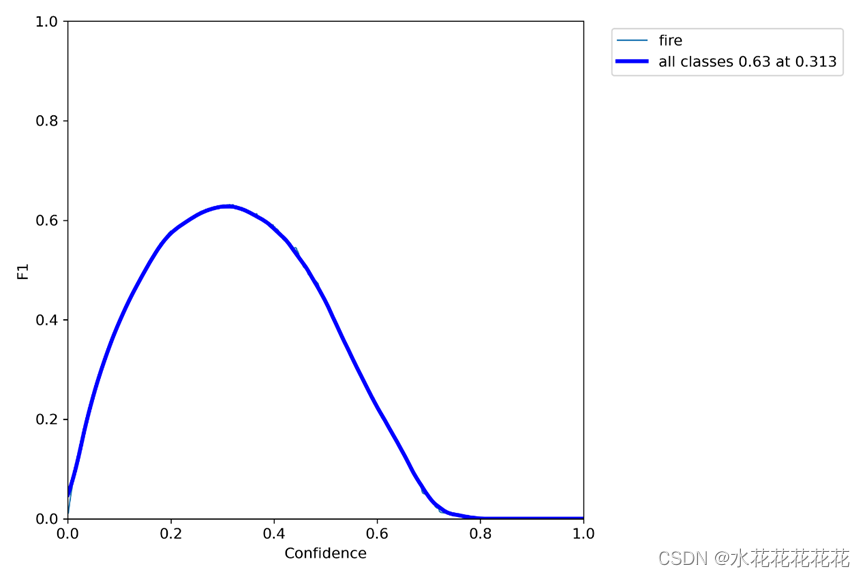
图10是训练得到的F1_curve,说明在置信度为0.2-0.6区间内得到比较好的F1分数,置信度阈值(该样本被判定为某一类的概率阈值)较低的时候,很多置信度低的样本被认为是真,召回率高,精确率低;置信度阈值较高的时候,置信度高的样本才能被认为是真,类别检测的越准确,即精准率较大(只有confidence很大,才被判断是某一类别),所以前后两头的F1分数比较少。
计算公式:

5、标签图labels.jpg
第一个图是训练集的数据量,每个类别有多少个
第二个图是框的尺寸和数量
第三个图是中心点相对于整幅图的位置
第四个图是图中目标相对于整幅图的高宽比例
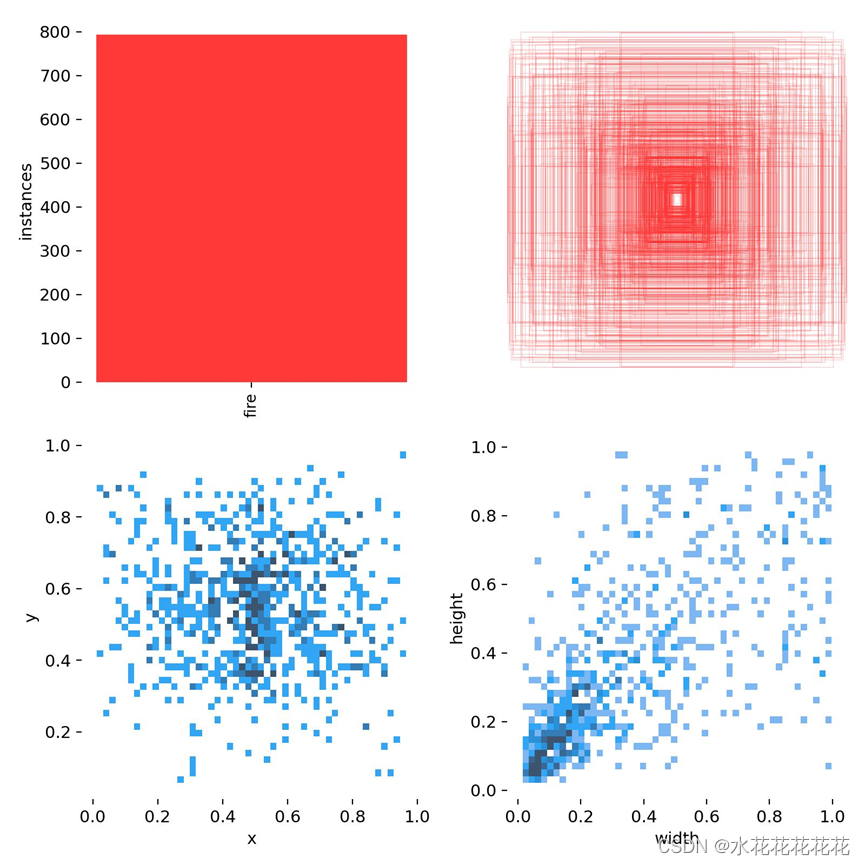
6、labels_correlogram体现中心点横纵坐标以及框的高宽间的关系
表示中心点坐标x和y,以及框的高宽间的关系。
每一行的最后一幅图代表的是x,y,宽和高的分布情况:
最上面的图(0,0)表明中心点横坐标x的分布情况,可以看到大部分集中在整幅图的中心位置;
(1,1)图表明中心点纵坐标y的分布情况,可以看到大部分集中在整幅图的中心位置
(2,2)图表明框的宽的分布情况,可以看到大部分框的宽的大小大概是整幅图的宽的一半
(3,3)图表明框的宽的分布情况,可以看到大部分框的高的大小超过整幅图的高的一半
而其他的图即是寻找这4个变量间的关系

7、P_curve单一类准确率
准确率precision和置信度confidence的关系图,即置信度阈值 - 准确率曲线图
当判定概率超过置信度阈值时,各个类别识别的准确率。当置信度越大时,类别检测越准确,但是这样就有可能漏掉一些判定概率较低的真实样本。
意思就是,当我设置置信度为某一数值的时候,各个类别识别的准确率。可以看到,当置信度越大的时候,类别检测的越准确。这也很好理解,只有confidence很大,才被判断是某一类别。但也很好想到,这样的话,会漏检一些置信度低的类别。
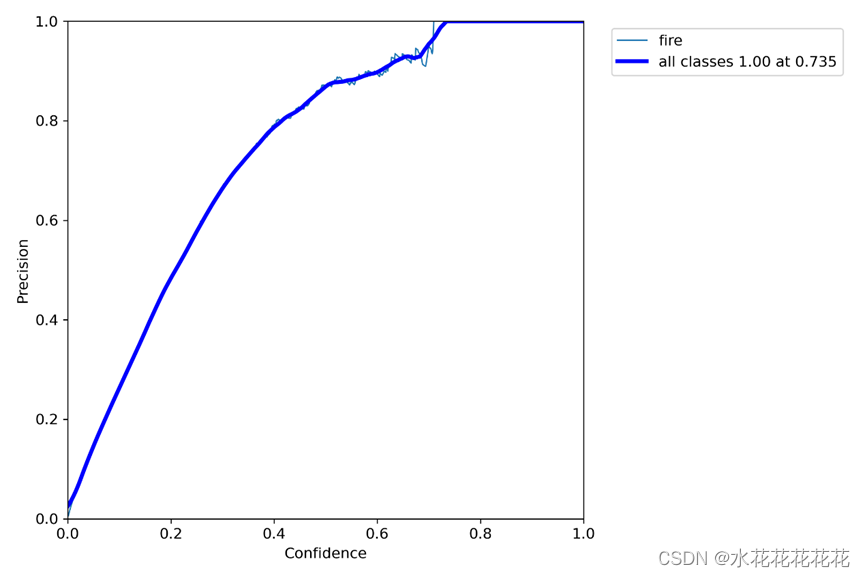
8、PR_curve精确率和召回率的关系
PR曲线体现精确率和召回率的关系。mAP 是 Mean Average Precision 的缩写,即 均值平均精度。可以看到:精度越高,召回率越低。
因此我们希望:在准确率很高的前提下,尽可能的检测到全部的类别。因此希望我们的曲线接近(1,1),即希望mAP曲线的面积尽可能接近1。在图15中我们观察到面积是接近1的,说明模型的均值平均精度是很高的。

PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。PR曲线下围成的面积即AP,所有类别AP平均值即Map.
如果PR图的其中的一个曲线A完全包住另一个学习器的曲线B,则可断言A的性能优于B,当A和B发生交叉时,可以根据曲线下方的面积大小来进行比较。一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)
Precision和Recall往往是一对矛盾的性能度量指标;及一个的值越高另一个就低一点;
提高Precision < == > 提高二分类器预测正例门槛 < == > 使得二分类器预测的正例尽可能是真实正例;
提高Recall < == > 降低二分类器预测正例门槛 < == >使得二分类器尽可能将真实的正例挑选
9、R_curve单一类找回率
召回率recall和置信度confidence之间的关系,recall(真实为positive的准确率),即正样本有多少被找出来了(召回了多少)。
从图16可以看到随着confidence的降低,召回率是更高的,说明类别检测的全面。
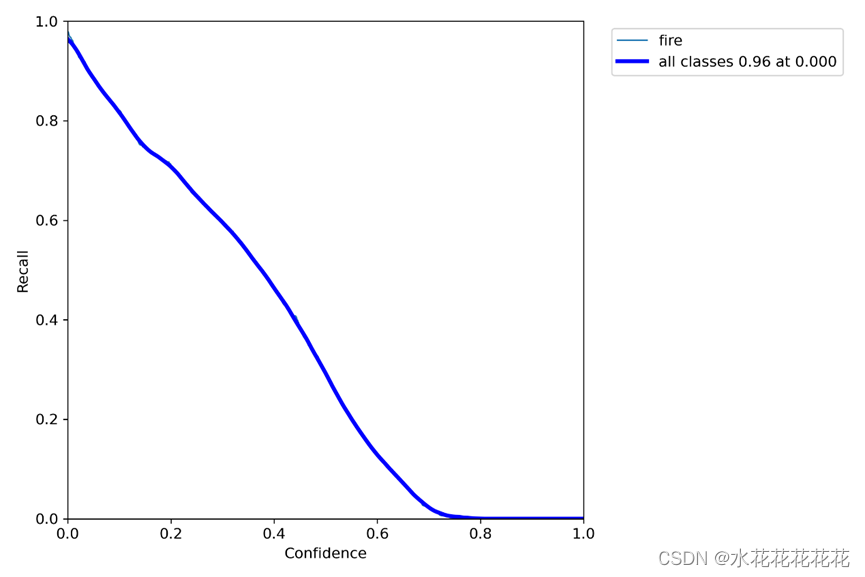
即置信度阈值 - 召回率曲线图
当置信度越小的时候,类别检测的越全面(不容易被漏掉,但容易误判)。
10、confusion_matrix _normalized混淆矩阵
混淆矩阵是对分类问题预测结果的总结。使用计数值汇总正确和不正确预测的数量,并按每个类进行细分,显示了分类模型进行预测时会对哪一部分产生混淆。通过这个矩阵可以方便地看出机器是否将两个不同的类混淆了,把一个类错认成了另一个。
从图17中可以看出正类预测和负类预测的真实和预测值都相同,说明模型的预测准确性很高。
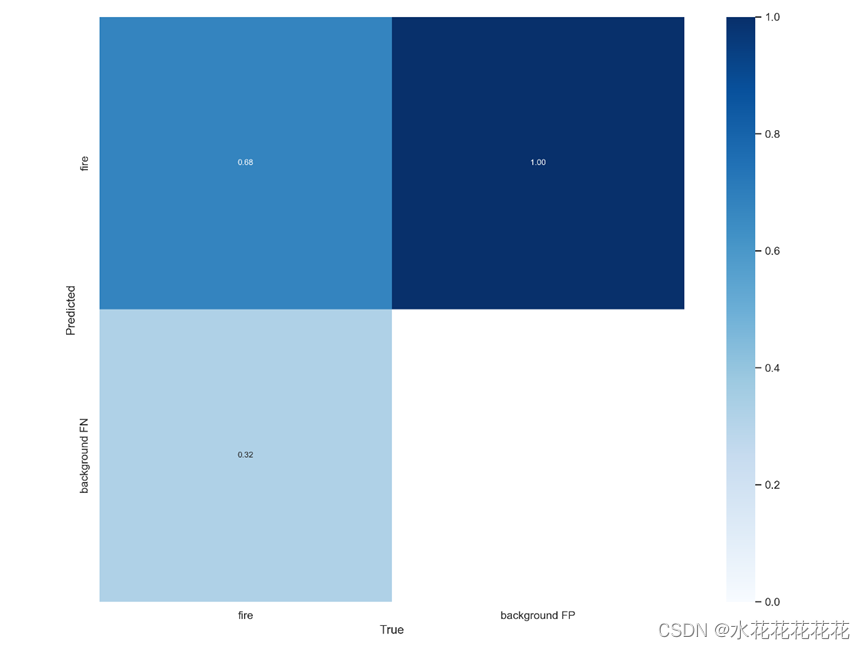
行是预测类别(y轴),列是真实类别(x轴)
混淆矩阵以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。其中矩阵的行表示真实值,矩阵的列表示预测值。
TP(True Positive): 将正类预测为正类数 即正确预测,真实为0,预测也为0
FN (False Negative):将正类预测为负类 即错误预测,真实为0,预测为1
FP(False Positive):将负类预测为正类数 即错误预测, 真实为1,预测为0
TN (True Negative):将负类预测为负类数,即正确预测,真实为1,预测也为1
精确率和召回率的计算方法
精确率Precision=TP / (TP+FP), 在预测是Positive所有结果中,预测正确的比重
召回率recall=TP / (TP+FN), 在真实值为Positive的所有结果中,预测正确的比重