NL2SQL进阶系列(4):ConvAI、DIN-SQL等16个业界开源应用实践详解[Text2SQL]
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
NL2SQL基础系列(2):主流大模型与微调方法精选集,Text2SQL经典算法技术回顾七年发展脉络梳理
NL2SQL进阶系列(1):DB-GPT-Hub、SQLcoder、Text2SQL开源应用实践详解
NL2SQL进阶系列(2):DAIL-SQL、DB-GPT开源应用实践详解[Text2SQL]
NL2SQL任务的目标是将用户对某个数据库的自然语言问题转化为相应的SQL查询。随着LLM的发展,使用LLM进行NL2SQL已成为一种新的范式。在这一过程中,如何利用提示工程来发掘LLM的NL2SQL能力显得尤为重要。
1. MAC-SQL-2024.2.15
简介:最近的基于LLM的文本到SQL方法通常在“庞大”数据库和需要多步推理的复杂用户问题上表现出明显的性能下降。此外,大多数现有方法忽视了LLM利用外部工具和模型协作的重要意义。为了解决这些挑战,提出了一种新颖的基于LLM的多智能体协作框架MAC-SQL。的框架包括一个核心分解器智能体,用于生成文本到SQL并进行少量思维链推理,并伴随两个辅助智能体,它们利用外部工具或模型获取更小子数据库并精炼错误SQL查询。分解器智能体与辅助智能体协作,在需要时激活,并可扩展以适应新特性或工具,实现有效文本到SQL解析。
在的框架中,首先使用任务强大骨干LLM来确定框架上限。然后,通过利用Code Llama 7B微调开源指令跟随模型SQL-Llama来显示,在BIRD基准测试中,SQL-Llama达到43.94%执行准则为46.35% 的基线准确率相当接近 。撰写本文时, MAC-SQL+GPT-4 在holdout测试集上取得59.59% 的执行准确率, 创造了一个新水平(SOTA)。
文件链接:
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
代码链接:
github: MAC-SQL



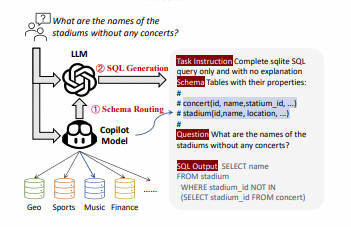
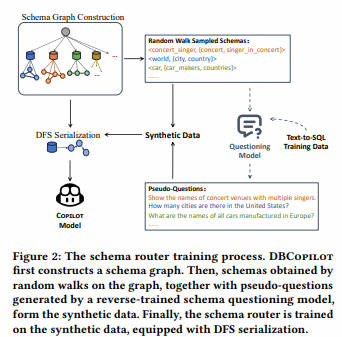
2. DBCopiLOT (☆)-2023.12.6
Text-to-SQL简化了数据库交互,让非专业人士将自然语言问题转换为SQL查询。尽管大型语言模型(LLMs)的近期进展改善了零样本Text-to-SQL范式,但现有方法在处理庞大、动态变化的数据库时仍面临可扩展性挑战。本文介绍了DBCopilot框架,它采用紧凑灵活的协同模型,实现跨大规模数据库的路由,解决了这些挑战。DBCopilot将Text-to-SQL过程解耦为模式路由和SQL生成,利用轻量级的基于序列到序列神经网络的路由器来制定数据库连接,并通过数据库和表导航自然语言问题。随后,将路由的模式和问题输入LLMs进行高效的SQL生成。此外,DBCopilot还引入了反向模式到问题生成范式,可以自动学习和适应大规模数据库中的路由器,无需人工干预。实验结果表明,DBCopilot是处理现实世界Text-to-SQL任务的可扩展和有效解决方案,为处理大规模模式提供了重大进展。
论文链接:
DBCᴏᴘɪʟᴏᴛ: Scaling Natural Language Querying to Massive Databases
代码链接:
github: DBCopilot
3.DAMO-ConvAI(☆)-2023.11.15
近年来,文本到SQL解析(即将自然语言问题转换为可执行的SQL语句)备受关注。特别是GPT-4和Claude-2在这一任务中取得了令人瞩目的成果。然而,当前主流基准测试(如Spider和WikiSQL)主要关注包含少量数据库值行的数据库模式,导致学术研究与实际应用之间存在差距。为弥补这一差距,提出BIRD——一个基于文本到SQL任务的大规模数据库基准测试,包含12,751个文本到SQL对和95个数据库,总大小达33.4GB,涵盖37个专业领域。强调数据库值的重要性,揭示了脏数据和噪声数据值、自然语言问题与数据库值之间的外部知识关联以及SQL效率(特别是在大型数据库背景下)等新挑战。为解决这些问题,文本到SQL模型除需具备语义解析能力外,还应具备数据库值理解能力。实验结果表明,在生成大型数据库准确文本到SQL语句时,数据库值至关重要。此外,即便是最有效的文本到SQL模型(如GPT-4),其执行准确率也仅为54.89%,远低于人类的92.96%,证明挑战依然存在。还提供了效率分析,为生成有益于行业的文本到高效SQL语句提供见解。相信,BIRD将有助于推动文本到SQL研究的实际应用发展。
论文链接:
Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs
代码链接:
github:bird-sql


4.DAIL-SQL(☆)- 2023.9.8-阿里
大型语言模型(LLMs)已成为文本到SQL任务的新范式。然而,缺乏系统的基准阻碍了设计有效、高效和经济实惠的基于LLM的文本到SQL解决方案的发展。为应对这一挑战,本文首先对现有的提示工程方法进行了系统和广泛的比较,包括问题表示、示例选择和示例组织,并基于这些实验结果详细阐述了它们的优缺点。基于这些发现,提出了一种新的集成解决方案,名为DAIL-SQL,它以86.6%的执行准确率刷新了Spider排行榜,并设定了新的标准。为探索开源LLM的潜力,在各种场景下对它们进行了研究,并通过监督微调进一步提升了它们的性能。的探索凸显了开源LLM在文本到SQL任务中的潜力,以及监督微调的优势和劣势。此外,为构建高效且经济的基于LLM的文本到SQL解决方案,强调了提示工程中的令牌效率,并在此指标下对先前的研究进行了比较。希望的工作能为基于LLM的文本到SQL任务提供更深入的理解。
论文链接:
Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation
代码链接:
github: DAIL-SQL




4.C3: Zero-shot Text-to-SQL with ChatGPT (☆)-2023.7.14 浙大
论文链接:https://arxiv.org/pdf/2307.07306.pdf
github地址:https://github.com/bigbigwatermalon/C3SQL
提出了一种基于ChatGPT的零样本Text-to-SQL方法C3,在Spider的holdout测试集上取得了82.3%的执行准确率,成为Spider Challenge上最先进的零样本Text-to-SQL方法。C3由三个关键组件组成:清晰提示(CP)、提示校准(CH)和一致性输出(CO),分别对应模型输入、模型偏差和模型输出。它为零样本Text-to-SQL提供了系统化的处理方法。



5. SeaD-2023.6.30
在文本到SQL(text-to-SQL)任务中,由于架构的限制,序列到序列(seq-to-seq)模型往往导致次优性能。本文提出了一种简单而有效的方法,将基于Transformer的seq-to-seq模型适配为健壮的文本到SQL生成器。并没有对解码器施加约束或将任务重新格式化为槽填充,而是提出了使用Schema感知去噪(Schema-aware Denoising,SeaD)来训练seq-to-seq模型。SeaD包含两个去噪目标,分别训练模型从两种新颖的去噪方法——侵蚀和洗牌中恢复输入或预测输出。这些去噪目标作为辅助任务,有助于更好地在序列到序列(S2S)生成中建模结构化数据。此外,改进并提出了一个子句敏感的执行引导(Execution Guided,EG)解码策略,以克服生成模型中EG解码的局限性。实验表明,所提出的方法在模式链接和语法正确性方面提高了seq-to-seq模型的性能,并在WikiSQL基准测试上建立了新的先进水平。这些结果表明,文本到SQL中基于Transformer的seq-to-seq架构的潜力可能被低估了。
论文链接:
SeaD: End-to-end Text-to-SQL Generation with Schema-aware Denoising
代码链接: 无

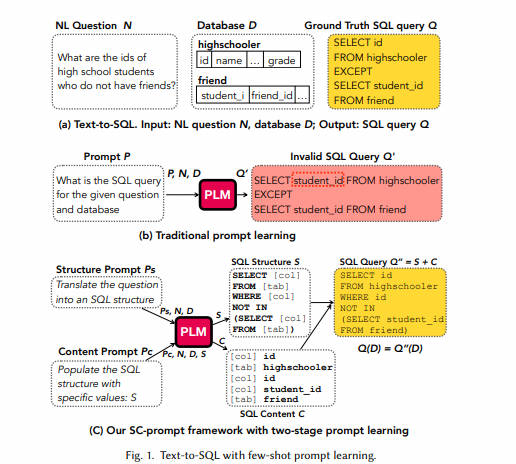
6. SC-prompt-2023.6
采用文本到SQL翻译(Text-to-SQL)在数据库系统中常见的一个问题是泛化能力较差。具体来说,当新数据集上的训练数据有限时,现有的少样本(few-shot)Text-to-SQL技术,即使在使用经过精心设计的文本提示对预训练语言模型(PLMs)进行引导时,也往往效果不佳。在本文中,提出了一种分而治之(divide-and-conquer)的框架,以更好地支持少样本Text-to-SQL翻译。该框架将Text-to-SQL翻译分为两个阶段(或子任务),使得每个子任务都更容易解决。
-
第一阶段,称之为结构阶段,它引导PLM生成一个带有占位符的SQL结构(包括SQL命令,如SELECT、FROM、WHERE,以及SQL运算符,如“<”、“>”)。这些占位符用于缺失的标识符。
-
第二阶段,称之为内容阶段,它指导PLM用具体的值(包括SQL标识符,如表名、列名和常量值)填充在生成的SQL结构中的占位符。
提出了一种混合提示策略,该策略结合了可学习的向量和固定向量(即文本提示的词嵌入),使得混合提示能够学习上下文信息,以更好地在两个阶段中引导PLM进行预测。
此外,还设计了关键词约束解码来确保生成的SQL结构的有效性,以及结构引导解码来确保模型填充正确的内容。通过与撰写本文时最新的十个Text-to-SQL解决方案进行广泛比较,实验结果表明,SC-Prompt在少样本场景下显著优于它们。特别是在广泛采用的Spider数据集上,给定少于500个标记的训练样本(官方训练集的5%),SC-Prompt在准确率上比之前的最佳方法高出约5%。
论文链接:
Few-shot Text-to-SQL Translation using Structure and Content Prompt Learning
代码链接:
github:SC-Prompt


7.T5-SR -2023.6.15
将自然语言查询转换为SQL语句的序列到序列(seq2seq)方法近年来备受关注。然而,与基于抽象语法树的SQL生成相比,seq2seq语义解析器面临着更多挑战,包括在模式信息预测方面的质量较差,以及自然语言查询与SQL语句之间的语义连贯性不足。本文分析了上述困难,并提出了一种面向seq2seq的解码策略,称为SR。该策略包括一个新的中间表示SSQL以及一个带有分数重估器的重排序方法,以分别解决上述障碍。实验结果表明,提出的技术是有效的,T5-SR-3b在Spider数据集上达到了新的最先进水平。
论文链接:
T5-SR: A UNIFIED SEQ-TO-SEQ DECODING STRATEGY FOR SEMANTIC PARSING
代码链接: 无


8.DIN-SQL(☆)-2023.4.27
研究了将复杂的文本到SQL任务分解为更小子任务的问题,以及这种分解如何显著提高大型语言模型(LLMs)在推理过程中的性能。目前,在诸如Spider等具有挑战性的文本到SQL数据集上,使用LLMs的微调模型与提示方法之间的性能存在显著差距。展示了可以将SQL查询的生成分解为子问题,并将这些子问题的解决方案输入到LLMs中,以显著提高其性能。对三个LLMs进行的实验表明,这种方法能够一致地将其简单的几次尝试性能提升约10%,使LLMs的准确率接近或超过当前最佳水平。在Spider的保留测试集上,以执行准确率为标准,当前最佳水平为79.9,而使用该方法实现的新最佳水平为85.3。的基于上下文学习的方法至少比许多经过大量微调的模型高出5%。
论文链接:
DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction
代码链接:
github DIN-SQL

9.RESDSQL-2023.4.10
近年来,预训练语言模型是文本到SQL转换的最佳尝试之一。由于SQL查询的结构特性,seq2seq模型负责解析模式项(即表和列)和骨架(即SQL关键字)。这种耦合的目标增加了正确解析SQL查询的难度,特别是在涉及多个模式项和逻辑运算符时。本文提出了一种基于排名增强的编码和骨架感知解码框架,以解耦模式链接和骨架解析。具体来说,对于seq2seq编码器-解码器模型,其编码器注入了最相关的模式项,而不是整个无序的模式项,这可以减轻SQL解析过程中的模式链接负担;其解码器首先生成骨架,然后生成实际的SQL查询,这可以隐式地约束SQL解析。在Spider及其三个鲁棒性变体(Spider-DK、Spider-Syn和Spider-Realistic)上评估了所提框架。实验结果表明,的框架表现出良好的性能和鲁棒性
论文链接:
RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL
代码链接:
github: RESDSQL


10.ChatGPT’s zero-shot Text-to-SQL-2023.3.12
本文首次对大型对话语言模型ChatGPT的文本到SQL能力进行了全面分析。鉴于ChatGPT在对话能力和代码生成方面的出色表现,旨在评估其在文本到SQL任务上的性能。在12个不同语言、设置或场景的基准数据集上进行了实验,结果表明ChatGPT具有强大的文本到SQL能力。尽管与当前最佳模型(SOTA)的性能相比仍有一定差距,但考虑到实验是在零样本场景下进行的,ChatGPT的表现仍然令人印象深刻。值得注意的是,在ADVETA(RPL)场景下,零样本的ChatGPT甚至超过了在Spider数据集上需要微调的SOTA模型,性能高出4.1%,展现了其在实际应用中的潜力。
论文链接:
A comprehensive evaluation of ChatGPT’s zero-shot Text-to-SQL capability
代码链接:
chatgpt-sql

11.Binder-2023.3.1
尽管端到端的神经方法最近在NLP任务中在性能和易用性方面占据主导地位,但它们缺乏可解释性和鲁棒性。提出了BINDER,一个无需训练的神经符号框架,它将任务输入映射到程序,从而实现以下功能:(1)将语言模型(LM)功能的统一API绑定到编程语言(如SQL、Python),从而扩展其语法覆盖范围,解决更多样化的问题;(2)将LM既用作程序解析器,又用作执行期间API调用的底层模型;(3)仅需要少量上下文示例注释。具体而言,采用GPT-3 Codex作为LM。在解析阶段,仅需少量上下文示例,Codex就能够识别任务输入中无法由原始编程语言回答的部分,正确生成API调用来提示Codex解决无法回答的部分,并在保持与原始语法兼容的同时确定API调用的位置。在执行阶段,Codex可以在API调用中提供适当的提示,执行多种功能(如常识问答、信息提取)。BINDER在WIKITABLEQUESTIONS和TABFACT数据集上实现了最先进的结果,并提供了明确的输出程序,有助于人类调试。请注意,之前的最佳系统都需要在数万个特定于任务的样本上进行微调,而BINDER仅使用几十个作为上下文示例的注释,无需任何训练。
论文链接:
BINDING LANGUAGE MODELS IN SYMBOLIC LANGUAGES
代码链接:
github: Binder

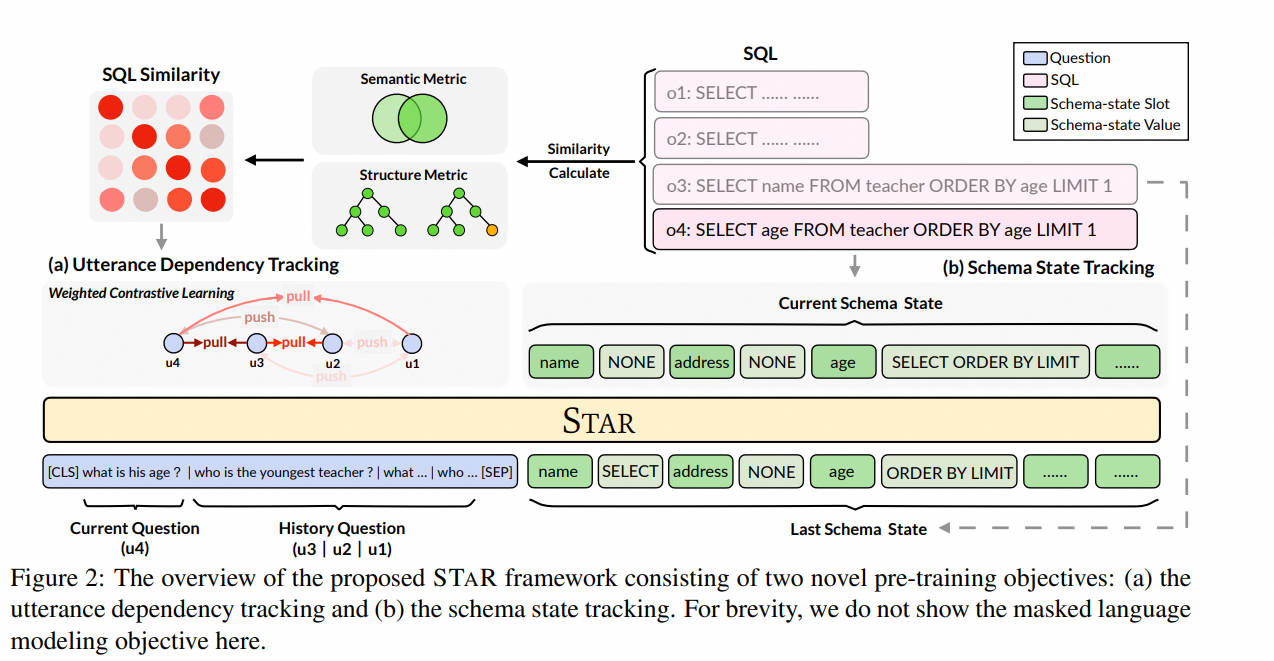
12.STAR-2022.10.28
在本文中,提出了一种新颖的SQL指导的预训练框架STAR,用于上下文依赖的文本到SQL解析。该框架利用上下文信息来丰富自然语言(NL)语句和表结构表示,从而改善文本到SQL的转换效果。具体来说,提出了两个新颖的预训练目标,它们分别探索每个文本到SQL对话中自然语言语句和SQL查询之间的上下文依赖交互:(i)模式状态追踪(SST)目标,通过预测和更新每个模式槽位的值来追踪和探索上下文依赖的SQL查询的模式状态;(ii)语句依赖追踪(UDT)目标,采用加权对比学习来拉近两个语义相似的自然语言语句的表示,同时推远每个对话中语义不相似的自然语言语句的表示。
此外,还构建了一个高质量的大规模上下文依赖的文本到SQL对话语料库,用于预训练STAR。大量实验表明,STAR在两个下游基准(SPARC和COSQL)上取得了新的最佳性能,显著优于先前的预训练方法,并在排行榜上名列第一。相信,所构建的语料库、代码库和预训练的STAR检查点的发布将推动该领域的研究发展。
论文链接:
STAR: SQL Guided Pre-Training for Context-dependent Text-to-SQL Parsing
代码链接:
https://github.com/alibabaresearch/damo-convai


13.CQR-SQL-2022.10.24
上下文依赖的文本到SQL的任务是将多轮问题翻译成与数据库相关的SQL查询。现有的方法通常侧重于充分利用历史上下文或先前预测的SQL进行当前的SQL解析,却忽视了显式理解模式和对话依赖性,如共指、省略和用户关注点的变化。在本文中,提出了CQR-SQL,它利用辅助性的对话问题重构(CQR)学习来显式地利用模式并解耦多轮SQL解析中的上下文依赖。具体来说,首先提出了一种模式增强的递归CQR方法,以生成与领域相关的、自包含的问题。其次,训练CQR-SQL模型,通过模式接地一致性任务和树结构SQL解析一致性任务,将多轮问题和辅助性的自包含问题的语义映射到相同的潜在空间,从而通过充分理解上下文来增强SQL解析的能力。在撰写本文时,的CQR-SQL在两个上下文依赖的文本到SQL基准测试SPARC和COSQL上取得了新的最先进结果。
论文链接:
CQR-SQL: Conversational Question Reformulation Enhanced Context-Dependent Text-to-SQL Parsers
代码链接: 无




14. RASAT-2022.10.9
关系结构,如模式链接和模式编码,已被验证为将自然语言定性转化为SQL查询的关键组件。然而,引入这些结构关系也存在一些代价:它们通常导致模型结构专业化,这在很大程度上限制了在文本到SQL任务中使用大型预训练模型。为了解决这个问题,提出了RASAT:一种增强了关系感知自注意力的Transformer序列到序列(seq2seq)架构。该架构能够利用多种关系结构,同时有效地继承T5模型的预训练参数。的模型可以整合文献中几乎所有类型的现有关系,此外,还提出了为多轮次场景引入共指关系。在三个广泛使用的文本到SQL数据集上的实验结果(涵盖单轮和多轮场景)表明,RASAT在所有三个基准测试中均取得了最先进的结果(Spider上的EX为75.5%,SParC上的IEX为52.6%,CoSQL上的IEX为37.4%)。
论文链接:
RASAT: Integrating Relational Structures into Pretrained Seq2Seq Model for Text-to-SQL
代码链接:
https://github.com/LUMIA-group/rasat
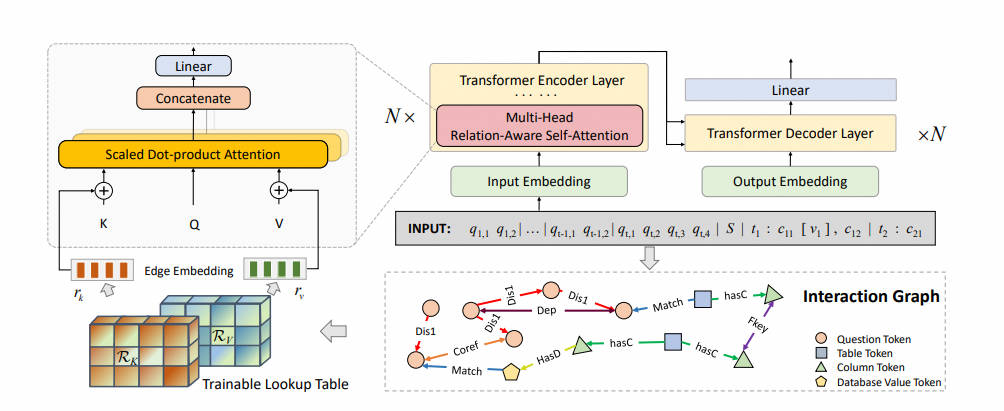
15.S2SQL-2022.5
将自然语言问题转换为可执行的SQL查询,即文本到SQL(Text-to-SQL),是语义解析的重要分支。虽然最先进的基于图的编码器已成功应用于此任务,但它对问题语法的建模并不理想。在本文中,提出了S²SQL,将语法注入到问题-模式图编码器中,用于Text-to-SQL解析器。这有效地利用了文本到SQL中问题的句法依赖信息来提高性能。还采用了解耦约束来诱导多样的关系边嵌入,这进一步提高了网络的性能。在Spider和健壮性设置Spider-Syn上的实验表明,当使用预训练模型时,所提出的方法优于所有现有方法,在Spider和Spider-Syn数据集上的性能分别提高了高达1.9%和2.2%。
论文链接:
Injecting Syntax to Question-Schema Interaction Graph Encoder for Text-to-SQL Parsers
代码链接: 无

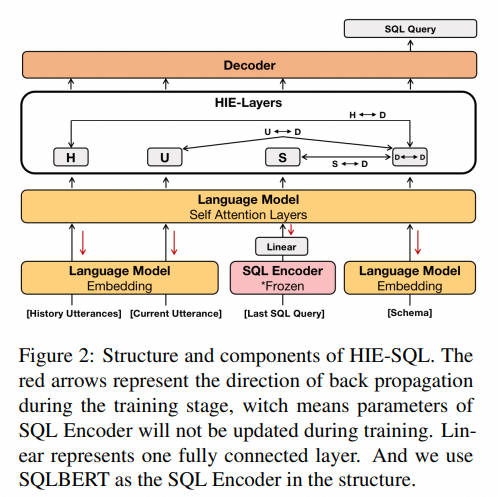
16. HIE-SQL-2022.4.2
近年来,上下文依赖的文本到SQL语义解析任务,即在交互过程中将自然语言翻译成SQL,引起了广泛关注。之前的工作要么从交互历史语句中,要么从先前预测的SQL查询中利用上下文依赖信息,但由于自然语言与逻辑形式的SQL之间的不匹配,它们无法同时利用两者。在这项工作中,提出了一个历史信息增强的文本到SQL模型(HIE-SQL),以同时从历史语句和最后预测的SQL查询中利用上下文依赖信息。鉴于这种不匹配,将自然语言和SQL视为两种模态,并提出一个双模态预训练模型来弥合它们之间的鸿沟。此外,设计了一个模式链接图,以增强从语句和SQL查询到数据库模式的连接。展示了历史信息增强方法显著提高了HIE-SQL的性能,在撰写本文时,它在两个上下文依赖的文本到SQL基准测试——SparC和CoSQL数据集上取得了新的最先进结果。
论文链接:
HIE-SQL: History Information Enhanced Network for Context-Dependent Text-to-SQL Semantic Parsing
代码链接:

更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。