文章目录
- 前言
- Apache Iceberg
- 存储
- 索引
- metadata
- Format V2
- 小文件
- Delta Lake
- Apache Hudi
- 存储
- 索引
- COW
- MOR
- 元数据表
- Apache Paimon
- LSM
- Tag
- consumer
- Changelog
- Partial Update
前言
对比读写性能和对流批一体的支持情况,建议选择Apache Paimon
截止2024年1月12日数据湖四大开源项目特性如下:

Apache Iceberg
存储
文件组织形式如下:
Snapshot:用户的每次 commit 会产生一个新的 snapshot。由于 Iceberg 基于 MVCC(多版本并发控制) 的设计理念,每次 Commit 都会生成一个 Snapshot, 该 Snapshot 是当时表的全局快照,即选定某个快照读取时,读到的是全量数据。Snapshot 文件记录了历史的 Manifest 文件和本次 Commit 新增的 Manifest,当我们增量读取时,只需要读取指定快照的新增的 Manifest 就可以实现读取新增的数据。
Manifest List:维护当前 snapshot 中所有的 manifest
Manifest:维护当前 Manifest 下所有的 data files 和 delete files,记录了本次事务中写入的文件和分区的对应关系,并且记录了文件中字段的一些统计信息(如最大值、最小值)以便于快速查找。
Data File:存储数据的文件,如 Parquet、Avro 等格式文件。
Delete File:存储「删除的数据」的文件
在上面的文件组织基础上,Iceberg 实现 update 的大致逻辑是:
先将要删除的数据写入 Delete File;
然后将「Data File」 JOIN 「Delete File」进行数据比对,实现数据更新。
索引
Iceberg 提供的 min-max,可以算是一种文件级别的索引。文件级别的索引就是根据 filter 条件过滤掉不符合条件的 data file。文件级别的索引可适用于多种文件类型,但这种粒度比较粗,只要 data file 中有一条数据符合条件,该 data file 中的数据就会全部读取出来参与计算,从而影响 SQL 的查询性能。
Iceberg 使用两个级别的元数据来跟踪快照中的文件。
Manifest List存储数据文件列表,以及每个数据文件的分区数据和列级统计信息
Manifest List存储快照的清单列表,以及每个分区字段的值范围
为了快速规划扫描,Iceberg 首先使用Manifest List中的分区值范围过滤清单。然后,它读取每个清单以获取数据文件。使用此方案,Manifest List充当Manifest文件的索引,从而可以在不读取所有清单的情况下进行规划。
除了分区值范围外,Manifest List还存储Manifest中添加或删除的文件数,以加快快照过期等操作。
Manifest文件包括分区数据的元组和每个数据文件的列级统计信息。
metadata
对象存储的 list 文件非常慢,使用 Iceberg 的元数据管理,可以避免 list 文件带来的性能瓶颈。iceberg 通过一个metadata 文件记录分区结构和文件列表,每次 commit 时重新生成一个 metadata 文件记录最新分区结构和文件列表。换言之,一个 Table 的数据是由 metadata 所维护的信息决定的,而不是由文件系统目录树决定的。经过这个抽象,对象存储的很多原生的问题就被避开了,兼顾性能和成本。
Format V2
Format V2 的格式中,在 V1 的基础上增加了如何通过这些类型的表实现行级别的更新与删除功能。其最主要的改变是引入了 delete file 记录需要删除的行数据,这样可以在不重写原有(数据)文件的前提下,实现行数据的更新与删除。
小文件
Iceberg表每次commit都会生成一个parquet数据文件,有可能一张Iceberg表对应的数据文件非常多。
Iceberg 跟踪表中的每个数据文件。数据文件越多,Manifest文件中存储的元数据就越多,而数据文件越小,文件打开成本就越高,元数据量越大,查询效率越低。
Iceberg 可以使用 Spark 和 action 并行压缩数据文件。这会将小文件合并为较大的文件,以减少元数据开销和运行时文件打开成本。
而hudi则通过File Group文件组织天然解决小文件问题。
Delta Lake
对Flink支持较差。
Apache Hudi
存储
Hudi 表的文件组织形式:在每个分区(Partition)内,数据文件被切分组织成一个个文件组(FileGroup),每个文件组都已 FileID 进行唯一标识。
Hudi 使用类 LSM 模式进行数据写入与合并,不过有区别于 LSM 的 SSTable,合并过程全读全写,即使只变更了其中一条数据,也需要整个文件进行读取合并,这就造成 compact 过程需要比较大的内存。尤其当存在热点数据时,任务需要从一开始便保留足够的资源来应对突增的大流量数据,从而造成一定的内存资源浪费。
索引
SimpleIndex:
通过在每个分区内进行 left outer join的方式判断输入纪录是否已经存储在当前分区内;GlobalSimpleIndex和SimpleIndex类似,只不过left outer join该表内所有已存在数据而不是当前分区已存在数据。
BloomIndex:
在纪录可能存在的文件中依次使用每个文件对应的bloomfilter,由于bloomfilter的误判特性,需要将这些纪录在文件中进行精准匹配查找以得到实际需要更新的纪录及其对应的location.GLOBAL_BLOOM索引是一种全局索引。GLOBAL_BLOOM索引可以加速全局查询,但会增加索引的存储开销。
Bucket Index和一致性哈希索引:
0.13.0引入了 Consistent Hashing Index 作为使用 Hudi 写入的另一种索引选项。这是对 0.11.0 版本中添加的 Bucket Index 的增强。使用桶索引,每个分区的桶/文件组是静态分配的,而使用一致性哈希索引,桶可以动态增长,因此用户无需担心数据倾斜。桶将根据每个分区的负载因子扩展和收缩。
如果采用基于表主键的 bucket 索引,因为湖仓做到了近实时,所以带来了更多的点查场景,Hudi 利用分区和主键下推到查询引擎后能够剪枝掉大量的分区和文件,不过单 bucket 内仍然需要 scan 整个文件来定位到具体的主键数据,点查性能略显吃力。
COW
每次的 update 数据都会与 main 文件 compaction 形成新的 main 文件。这种更新方案的优势是对分析非常友好,可以达到最好的分析性能,缺点是写放大严重。在 DB 数据入湖场景,对于千万级别以下的小表,这种方案简单明了,对资源也比较友好。
对于 Insert 新数据的处理上,Hudi 与 Iceberg 以及 Delta Lake 的 Copy On write 方案有很大的不同,Hudi 将数据文件布局成 File Group 的形式, 除了将 update 数据与 key 所在数据 base 文件合并外,还会尝试将 insert 数据继续写入到小的 File Group 文件(默认阈值为 120MB,小于此大小的被视为小文件),进一步优化文件大小从而提升查询性能。而 Delta Lake 和 Iceberg 需要后期的 compaction 任务来完成类似的操作。
MOR
写入延时较cow表低,但直到0.13.x版本mor表仍有丢失数据的bug,故mor表虽然较cow表写入延时低且写放大低,但在生产环境有丢数据风险。
元数据表
在0.11版本默认开启了类似iceberg metadata的元数据表,但元数据表也是以mor表组织的,会生成大量小文件且有元数据mor表丢数据风险。
Apache Paimon
LSM
Iceberg、Hudi、Delta一旦需要涉及到合并就是增量数据和全量数据的一次超大合并。如果全量10 TB,增量哪怕1 GB也可能会涉及到所有文件的合并,这10个TB的数据要全部重写一次,然后合并才算完成,合并的代价非常大。
Paimon采用面向更新的技术LSM,这种格式在实时领域已经被大量的各种数据库应用起来,包括 RocksDB、Clickhouse、Doris、StarRocks 等等。LSM带来的变化是每次合并都可能是局部的。每次合并只用按照一定的策略来merge数据即可,这种格式能真正在成本、新鲜度和查询延时的三角trade-off中可以做到更强,而且在三角当中可以根据不同的参数做不一样的trade-off的选择。
Hudi MOR是纯Append,虽然后台有compaction,但是不等Compaction完全结束就会有查询。所以在测试中Hudi的Compaction只做了一点点,读取的时候性能特别差。对于CopyOnWrite,测试合并性能,测试CopyOnWrite情况下的 compaction 性能。测试的结果是发现不管是2分钟、1分钟还是30秒,Paimon性能都是大幅领先的,是12倍的性能差距。在30秒的时候,Hudi跑不出来,Paimon还是能比较正常地跑出来。
高性能更新:LSM 的 Minor Compaction,保障写入的性能和稳定性
高性能合并:LSM 的有序合并效率非常高。
高性能查询:LSM 的 基本有序性,保障查询可以基于主键做文件的 Skipping
得益于 LSM 这种原生异步的 Minor Compaction,它可以通过异步 Compaction 落到最下层,也可以在上层就发生一些 Minor 的 Compaction 和 Minor 的合并,这样压缩之后它可以保持 LSM 不会有太多的 level。保证了读取 merge read 的性能,且不会带来很大的写放大。
另外,Flink Sink 会自动清理过期的快照和文件,还可以配置分区的清理策略。所以整个 Paimon 提供了吞吐大的 Append 写,消耗低的局部 Compaction,全自动的清理以及有序的合并。所以它的写吞吐很大,merge read 不会太慢。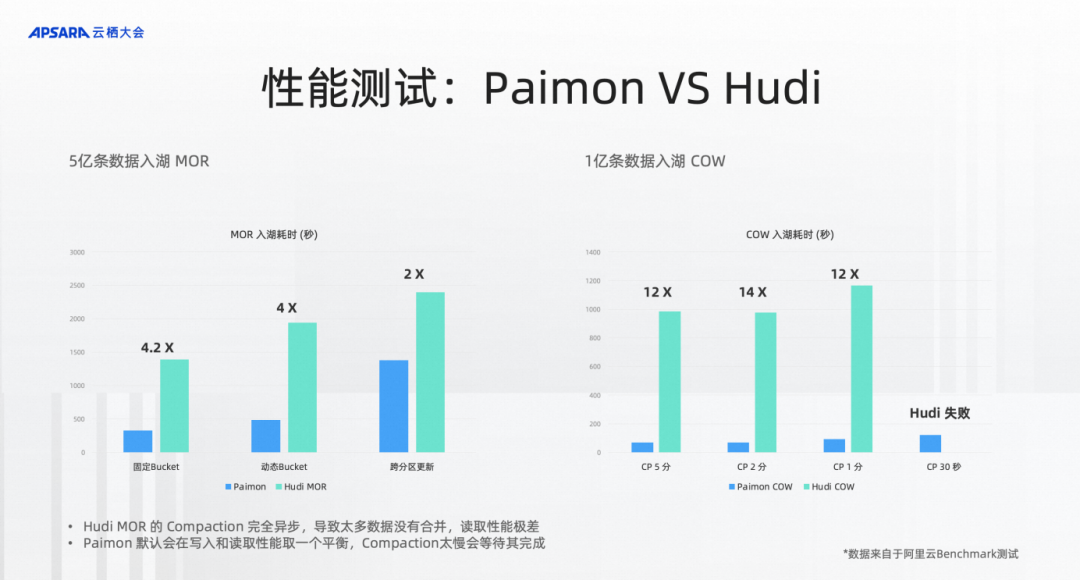
Tag
Flink+Paimon的流式CDC更新,只要定义Paimon的主键表,不分区。它的定义就非常像MySQL表的定义。
每天的离线视图可以通过 CREATE TAG 创建,Tag 是一个 snapshot 的引用。Flink、Spark可以通过Time Travel的语法访问到Tag的数据。类似hudi的savepoint。存储成本通过Paimon的文件复用机制,打十天的Tag其实存储成本只有一两天的全量成本,保留100天的分区,最后存储成本可以达到50倍的节省。
增量视图可以通过 INCREMTENTAL 视图获取到 (比如支持查询两个 TAG 的 DIFF)。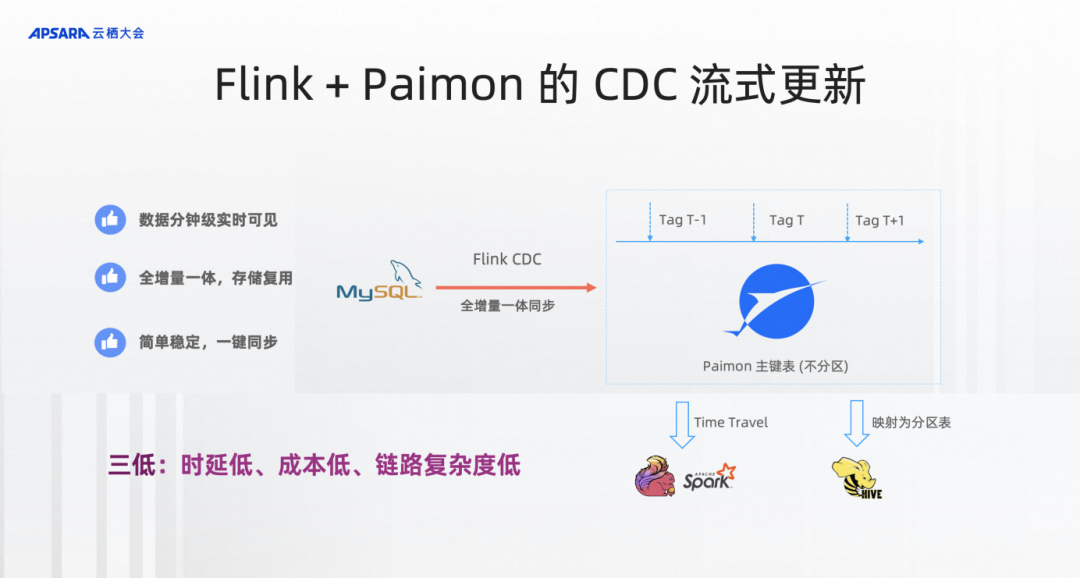
consumer
正在流读的Snapshot如果被Snapshot Expiration给删了,会出现FileNotFoundException。consumer机制就是在Paimon里用了这个机制之后,会在文件系统中记一个进度,当我再读这个Snapshot,Expiration就不会删这个Snapshot,它能保证这个流读的安全,也能做到像类似 kafka group id 流读进度的保存。重启一个作业无状态恢复还是这个进度。所以consumer机制可以说是流读的基本机制。
Changelog
通过changelog-producer参数设置相应的增量数据产生机制,Paimon可以为任意输入数据流产生完整的增量数据(所有的update_after数据都有对应的update_before数据)。
设置changelog-producer为none(默认值)后,此时,对于同一个primary key,下游的Paimon源表只能看到数据的最新情况。但这些最新情况无法让下游消费者方便地了解完整的增量数据,从而进行正确的计算。因为它只能确定对应数据是否被删除了,或最新数据是什么,无法得知更改之前的数据是什么。例如,假设下游消费者需要计算某一列的总和,如果消费者只看到了最新数据5,它无法断定该如何更新总和。因为如果之前的数据是4,它应该将总和增加1;如果之前的数据是6,它应该将总和减去1。此类消费者对update_before较为敏感,建议不要将增量数据产生机制配置为None,但是其他增量数据产生机制会带来性能损耗。如果下游是数据库之类的对update_before数据不敏感的消费者,则可以将增量数据产生机制配置为None。
设置changelog-producer为input后,Paimon结果表会将输入数据流双写至增量数据文件中,作为增量数据。因此,只有当输入数据流本身是完整的增量数据时(例如CDC数据),才能使用这一增量数据产生机制。
设置changelog-producer为lookup后,Paimon结果表会通过一种类似于维表的点查机制,在每次commit snapshot之前产生本次snapshot对应的完整增量数据。无论输入数据是否为完整的增量数据,这一增量数据产生机制均能产生完整的增量数据。与下文的Full Compaction机制相比,Lookup机制产生增量数据的时效性更好,但总体来看耗费的资源更多。推荐在对增量数据的新鲜度有较高要求(例如分钟级)的情况下使用。
设置changelog-producer为full-compaction后,Paimon结果表会在每一次full compaction时产生完整的增量数据。无论输入数据是否为完整的增量数据,这一增量数据产生机制均能产生完整的增量数据。Full compaction的时间间隔由full-compaction.delta-commits参数指定。与上文的Lookup机制相比,Full Compaction机制产生增量数据的时效性更差,但它利用了数据的full compaction过程,不产生额外计算,因此总体来看耗费的资源更少。推荐在对增量数据的新鲜度要求不高(例如小时级)的情况下使用。
Partial Update
数据打宽的三种方式:
第一种是 Flink 双流 join 的方式,需要维护两边比较大的 state,这也是成本比较高的原因之一。
第二种是通过 Flink lookup join 的方式 lookup 到 Paimon 的数据,缺点是维表的更新不能更新到已经 join 的数据上。
第三种是通过paimin的Partial Update 的方式, 可以根据相同的主键实时合并多条流,形成 Paimon 的一张大宽表。而且,借助LSM 树的延迟 Compaction 机制,我们可以用较低的成本完成合并,从而提高了数据处理的效率。