编译原理概述
编译原理:是计算机科学的一个分支,研究如何将 高级程序语言 转换为 计算机可执行的目标代码 的技术和理论。
- 高级程序语言:Python、Java、JavaScript、TypeScript、C、C++、Go 等。
- 计算机可执行的目标代码:机器码、汇编语言、字节码、目标代码等。
编译器 (Compiler):是一种将高级编程语言 源代码 转换为计算机可执行代码 目标代码 的软件工具。它是将源代码翻译成机器语言的程序。以下是编译器的基本工作流程:
词法分析[Lexical Analysis]:将源代码分解为一个个的 词法单元(tokens),比如关键字、标识符、运算符等。语法分析[Syntax Analysis]:根据语法规则,将 词法单元(tokens) 组织成 语法树(Parse Tree) 或 抽象语法树(Abstract Syntax Tree,即 AST )。语义分析[Semantic Analysis]:检查语法正确性和语义正确性,进行类型检查、符号表管理等,确保源代码的语义正确。生成中间代码[Intermediate Code Generation]:将抽象语法树转换为中间表示形式,如三地址码、字节码、中间表示语言等。优化[Optimization]:对中间代码进行优化,改善程序性能、减少资源消耗等。生成目标代码[Code Generation]:将优化后的中间代码转换为目标机器代码,可以是机器语言、汇编语言或其它形式的可执行代码。
为什么要有编译器?
进行应用程序编译的几个重要原因:
执行效率和优化:编译过程可以进行代码优化,改善应用程序的执行效率。编译器可以对源代码进行静态分析,并应用各种优化技术,如常量折叠、循环展开、死代码消除等,以生成更高效的目标代码。平台独立性:通过编译,可以将应用程序从一种高级语言转换为与特定平台无关的中间表示形式(如字节码)。这使得应用程序可以在不同的操作系统和硬件平台上运行,而无需进行源代码修改。代码隐藏和保护:编译后的目标代码通常不包含源代码的明文形式,从而隐藏了实现细节和商业逻辑。这有助于保护知识产权和应用程序的安全性,防止未经授权的访问和修改。加速加载和部署:编译后的应用程序可以更快地加载和执行,因为它们已经被转换为计算机能够直接执行的形式。此外,编译过程还可以将应用程序及其依赖项打包成更小、更紧凑的形式,以便更快地部署和传输到用户设备。错误检查和类型安全:编译器可以在编译过程中检查代码中的错误和潜在问题。例如,它可以检查类型错误、语法错误和常见的编码错误,提供更早的反馈和警告。这有助于提高代码质量、减少运行时错误和调试时间。
Angular Compiler
Angular 编译器有两大方面的内容:
- HTML Template 编译
- 基于 TS 基础之上的编译
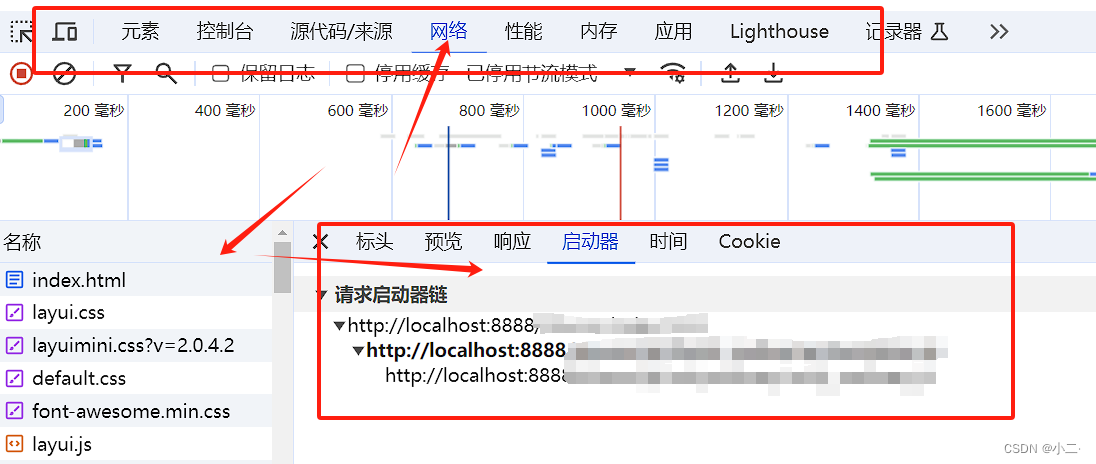
本文重点要介绍的是 HTML Template 编译,了解 Angular 应用程序在运行时编译模板的底层实现,同时了解抽象语法树在整个编译过程中的作用。核心代码来源:@angular/compiler/src。

在了解 HTML Template 编译的底层实现之前,我们先来看个小示例。
html 模板,比如下面这个,大家应该都不陌生:

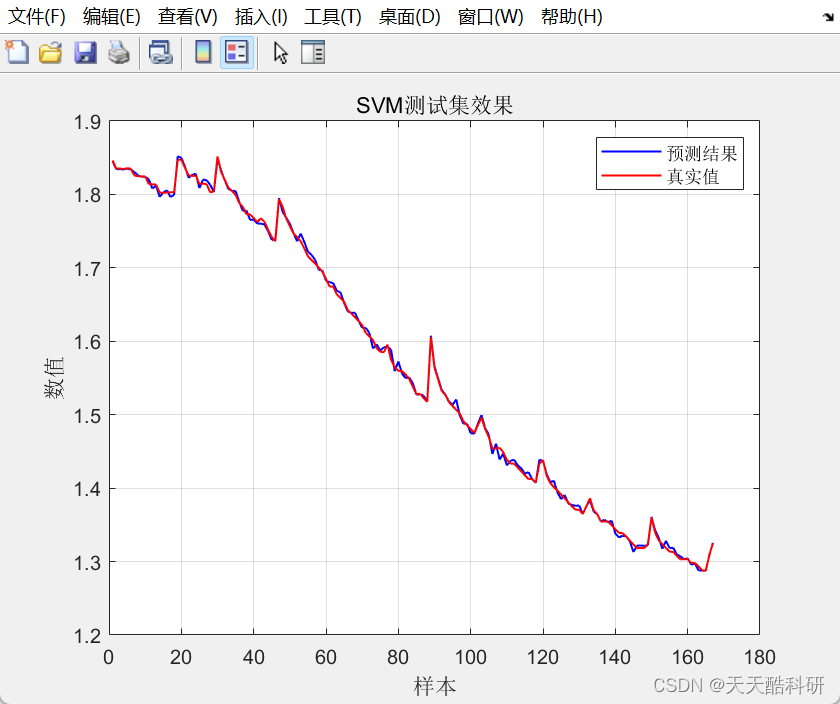
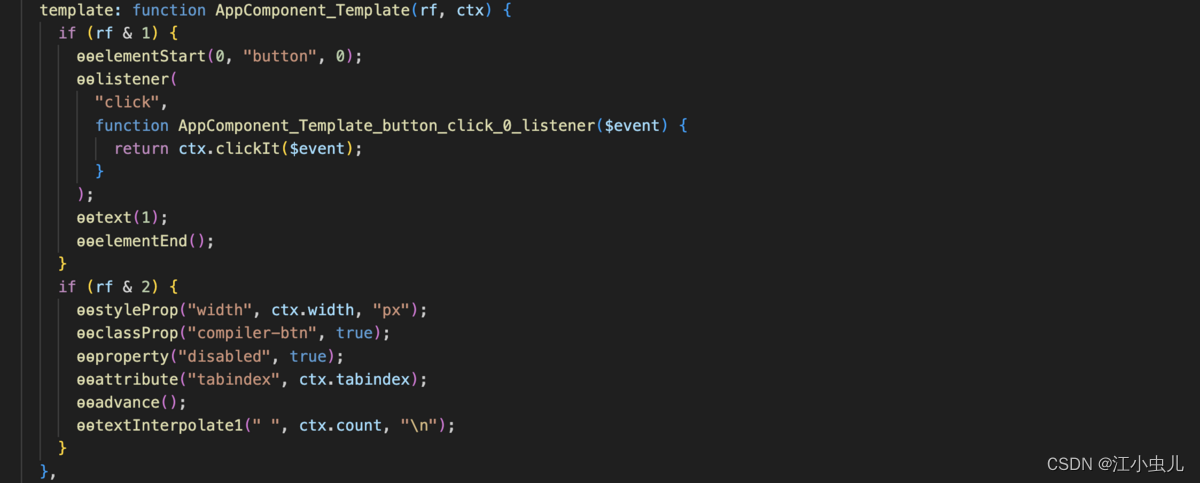
那 Angular 最终运行时会把 HTML Template 编译解析成什么了呢? 经过编译器的编译,应用程序的源代码会被编译成浏览器可识别、可执行的 JavaScript 代码,其中模板的编译结果:
下面来了解底层实现过程。
html 模板的编译过程 parseTemplate 的实现,用到了两个解析器:
- 解析标签,通过 HtmlParser (lexer、parser、ast) 实现。
- 解析属性绑定,通过 BindingParser + ExpressionParser (lexer、parser、ast) 实现。
html 解析器
html 模板的解析是如何实现的? 实现一个词法分析器 lexer,对源代码进行分词。实现一个解析器 parser,对分词的结果做进一步分析和处理,生成语法树。整个解析的过程会记录和报告遇到的错误。
lexer(词法分析器)
词法分析的目的是将源代码分解为一个个的 词法单元(tokens),如关键字、标识符、运算符等。
词法分析的过程是对要解析的模板字符串,进行一个字符一个字符的识别和处理,然后生成不同类型的 token 的过程。
字符:(我们平时会用到的字符有这些:特殊字符、标点、数字、字母等)
文件结束符EOF 退格符BSPACE 制表符TAB 换行符LF 垂直制表符VTAB 换页符FF 回车符CR 空格SPACE 无间断空格NBSP ! " # $ % & ' ( ) * + , - . / : ; < = > ? 0 7 9 A E F X Z [ \ ] ^ _ a b e f n r t u v x z { } | BAR | PIPE ~ @。
Token类型:
TAG_OPEN_START, // 0 开始标签的开始TAG_OPEN_END, // 1 开始标签的结束TAG_OPEN_END_VOID, // 2 自闭合标签的结束TAG_CLOSE, // 3 标签的关闭INCOMPLETE_TAG_OPEN, // 4 不完整的标签的开始TEXT, // 5 文本ESCAPABLE_RAW_TEXT, // 6 可转义的原始文本,比如:textarea, titleRAW_TEXT, // 7 原始文本,比如:script, styleINTERPOLATION, // 8 插值ENCODED_ENTITY, // 9 编码实体COMMENT_START, // 10 注释的开始COMMENT_END, // 11 注释的结束CDATA_START, // 12 CDATA的开始CDATA_END, // 13 CDATA的结束ATTR_NAME, // 14 属性名ATTR_QUOTE, // 15 属性引用(引号)ATTR_VALUE_TEXT, // 16 属性值的文本ATTR_VALUE_INTERPOLATION, // 17 属性值的插值DOC_TYPE, // 18 文档类型EXPANSION_FORM_START, // 19 扩展表单的开始EXPANSION_CASE_VALUE, // 20 扩展的值EXPANSION_CASE_EXP_START, // 21 扩展的表达式的开始EXPANSION_CASE_EXP_END, // 22 扩展的表达式的结束EXPANSION_FORM_END, // 23 扩展表单的结束BLOCK_OPEN_START, // 24 BLOCK的开始BLOCK_OPEN_END, // 25 BLOCK的结束BLOCK_CLOSE, // 26 BLOCK的关闭BLOCK_PARAMETER, // 27 BLOCK的参数INCOMPLETE_BLOCK_OPEN, // 28 不完整的BLOCK的开始EOF, // 29 文件结束符
上面我们了解了html模板中词法分析的一些基本概念。接下来用两个简单的例子,展示一下模板源代码执行分词处理之后生成 tokens 的结果。
对于下面这段代码

它解析出来的 tokens 的结果如下:
TokenizeResult {// 这里可以看出 <div></div> 解析出来5个token,并指出了每个token的类型tokens: [{ type: 0, parts: [Array], sourceSpan: [ParseSourceSpan] },{ type: 1, parts: [], sourceSpan: [ParseSourceSpan] },{ type: 3, parts: [Array], sourceSpan: [ParseSourceSpan] },{ type: 5, parts: [Array], sourceSpan: [ParseSourceSpan] },{ type: 29, parts: [], sourceSpan: [ParseSourceSpan] }],errors: [],nonNormalizedIcuExpressions: []
}//展开查看每个token的细节
TokenizeResult {tokens: [{ // 第一个token: <div 开始标签的开始type: 0, parts: [ '', 'div' ], // parts 不会记录 <sourceSpan: ParseSourceSpan {start: ParseLocation {file: [ParseSourceFile],offset: 0,line: 0,col: 0},end: ParseLocation {file: [ParseSourceFile],offset: 4,line: 0,col: 4},fullStart: ParseLocation {file: [ParseSourceFile],offset: 0,line: 0,col: 0},details: null},{ // 第二个token:> ,开始标签的结束type: 1,parts: [], // parts 不记录 >sourceSpan: ParseSourceSpan {start: ParseLocation {file: [ParseSourceFile],offset: 4,line: 0,col: 4},end: ParseLocation {file: [ParseSourceFile],offset: 5,line: 0,col: 5},fullStart: ParseLocation {file: [ParseSourceFile],offset: 4,line: 0,col: 4},details: null}},{ // 第三个token:</div> ,标签的关闭type: 3,parts: [ '', 'div' ],sourceSpan: ParseSourceSpan {start: ParseLocation {file: [ParseSourceFile],offset: 5,line: 0,col: 5},end: ParseLocation {file: [ParseSourceFile],offset: 11,line: 0,col: 11},fullStart: ParseLocation {file: [ParseSourceFile],offset: 5,line: 0,col: 5},details: null}},{ // 第四个token: \n ,文本type: 5,parts: [ '\n' ],sourceSpan: ParseSourceSpan {start: ParseLocation {file: [ParseSourceFile],offset: 11,line: 0,col: 11},end: ParseLocation {file: [ParseSourceFile],offset: 12,line: 1,col: 0},fullStart: ParseLocation {file: [ParseSourceFile],offset: 11,line: 0,col: 11},details: null}},{ // 最后一个token: EOF ,文件结束符。type: 29,parts: [],sourceSpan: ParseSourceSpan {start: ParseLocation {file: [ParseSourceFile],offset: 12,line: 1,col: 0},end: ParseLocation {file: [ParseSourceFile],offset: 12,line: 1,col: 0},fullStart: ParseLocation {file: [ParseSourceFile],offset: 12,line: 1,col: 0},details: null}}],errors: [],nonNormalizedIcuExpressions: []
}
所以上述示例中源代码被切割成了 <div > </div> \n EOF 五个token。 为什么开始标签要分割成 <div > 两个token,而闭合标签当一个 </div> 使?看下面那个示例就知道了。
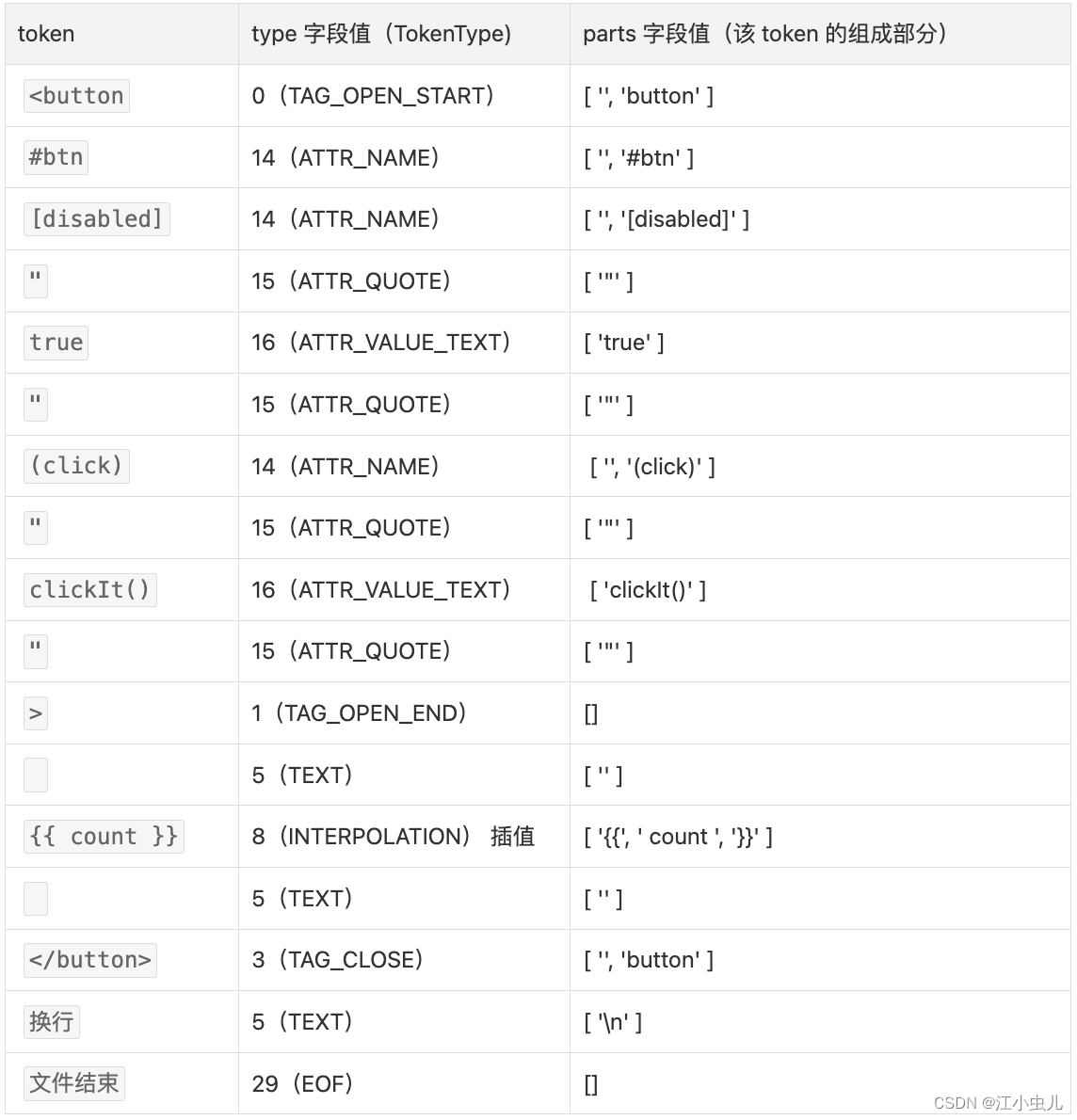
对于下面这段代码中,开始标签上绑定几个属性,开始标签和结束标签之间有插值。

这个示例中,
- 开始标签包括:标签的开始,属性绑定区,标签的结束。
- 开始标签和结束标签之间有插值。
- 结束标签。
它解析出来的 tokens 结果如下:
到此,对于 tokens 的概念我们也有了一定的了解,它是词法分析的产物。那词法分析的实现过程是怎么样的呢?过程概述如下:
export function tokenize( source, url, tagDefinition) {// 实例化一个分词器,接收源代码、源代码所在文件的路径、标签定义、配置信息const tokenizer = new _Tokenizer(new ParseSourceFile(source, url), tagDefinition, options);// 分词处理tokenizer.tokenize();// 得到词法分析结果 tokens 和分析过程中遇到的错误 errorsreturn new TokenizeResult(mergeTextTokens(tokenizer.tokens), tokenizer.errors, tokenizer.nonNormalizedIcuExpressions);
}具体实现:分词器(Tokenizer.tokenize) + 字符光标(CharacterCursor) 。
分词器是如何识别并生成 token 的?下面拿开始标签和结束标签(以 < 开头) 的 token 识别过程说明一下。
- 注释标签:
<!-- 注释 --> - CDATA 区块标签:
<![CDATA[......]]> - 文件类型声明标签:
<!DOCTYPE html> - 普通标签:
<div>......</div>
分词器中维护了一个光标对象,光标从左往右移动对源代码片段中的字符进行解析。
光标对象中会记录当前解析的字符所在位置的 line(行)、column(列)、peek(指向当前字符)。
class _Tokenizer {tokenize(): void {while (this._cursor.peek() !== chars.$EOF) { // peek 获得当前解析的字符,当前字符不是结束符时,则光标继续前进const start = this._cursor.clone();// 分词处理,识别不同类型的标签,合法的标签就外面常见的几种,如果不是,按错误处理try {// 如果当前字符是 < (开始标签的第一个字符),将光标前进一个字符,cursor 更新为前进之后的这个字符的信息(如果是换行符,则行号加1,列号置0;否则列号加1。如果光标的偏移量+1之后会大于目标分析片段的结束位置,在当前字符更新为EOF,否则记录当前字符。)if (this._attemptCharCode(chars.$LT)) {if (this._attemptCharCode(chars.$BANG)) {// ==========================================// <!if (this._attemptCharCode(chars.$LBRACKET)) {// <![ (说明:CDATA 区块,用于包含不需要被解析的文本数据,通常用于在 XML 或 XHTML 中嵌入代码块,如 JavaScript 代码或样式表。CDATA 区块以 <![CDATA[ 开头,以 ]]> 结尾。)this._consumeCdata(start);} else if (this._attemptCharCode(chars.$MINUS)) {// <!- (说明:注释:HTML 注释以 <!-- 开头,以 --> 结尾。)this._consumeComment(start);} else {// <!DOCTYPE (说明:文件类型声明,比如完整的html5的文件类型声明是 <!DOCTYPE html> )this._consumeDocType(start);}} else if (this._attemptCharCode(chars.$SLASH)) {// ==========================================// </ (说明:结束标签)this._consumeTagClose(start); } else {// ==========================================// < (说明:都是上述特殊情况,按普通的开始标签处理)this._consumeTagOpen(start); }// 后面是除了开始标签、结束标签之外的其它情况的token解析} else if (this._tokenizeBlocks && this._attemptCharCode(chars.$AT)) {// 含有 @ 字符的块this._consumeBlockStart(start);} else if (this._tokenizeBlocks && !this._inInterpolation && !this._isInExpansionCase() &&!this._isInExpansionForm() && this._attemptCharCode(chars.$RBRACE)) {this._consumeBlockEnd(start);} else if (!(this._tokenizeIcu && this._tokenizeExpansionForm())) {this._consumeWithInterpolation(TokenType.TEXT, TokenType.INTERPOLATION, () => this._isTextEnd(),() => this._isTagStart());}} catch (e) {this.handleError(e);}}}
以上是模板的词法分析的核心内容(词法分析的结果也在开头以示例的形式给大家介绍了)。目的是将模板源代码切割成一个个的词法单元(token),每个词法单元里记录了该单元在源代码中的位置信息、组成成分、类型。它会作为下一步解析过程的基础。
扩展:在移动光标进行字符解析和分词处理的过程中,有运用到 创建型设计模式中的原型模式 去创建光标 cursor 实例。
原型模式特点:光标对象中提供了 clone 方法,在需要的时候,开发者可以直接调用 cursor.clone() 快速生成一个新的光标实例。
原型模式的优点:当创建对象的过程比较复杂、耗时或者需要频繁创建对象时,可以使用原型模式。通过复制已有对象来创建新的对象,避免了重复的初始化过程,提高了性能。
parser(解析器)
词法分析的下一步,是进行语法分析。语法分析,根据语法规则将上一步生成的词法单元构建成语法树。对于模板的解析,Angular Compiler 有专门解析器(parser)。解析过程概述:
export class Parser {constructor(public getTagDefinition: (tagName: string) => TagDefinition) {}// 接收模板的源代码 template content,parse(source: string, url: string, options?: TokenizeOptions) {// 词法分析拿到 tokensconst tokenizeResult = lexer.tokenize(source, url, this.getTagDefinition, options); // 根据语法规则,组合 tokens ,构建成语法树(parser.rootNodes)const parser = new _TreeBuilder(tokenizeResult.tokens, this.getTagDefinition);parser.build();// 得到解析结果 treeNodes、parseErrorsreturn new ParseTreeResult(parser.rootNodes,(tokenizeResult.errors as ParseError[]).concat(parser.errors),);}
}
解析器具体是如何将 tokens 组装成语法树的?
实现过程在 TreeBuilder(树构造器)的 build 方法里。树的构造过程中的操作对象(原材料)是 tokens ,在遍历 tokens 时,用 peek 指针指向当前正在操作的 token。
class _TreeBuilder {constructor(private tokens: Token[], private getTagDefinition: (tagName: string) => TagDefinition) {this._advance();}build(): void {// _peek:当前处理的token。遍历tokens数组,通过 _index++,this._peek = this.tokens[this._index] 实现遍历,直到遇到文件结束符(TokenType=EOF)时结束// 遍历 tokens,根据token类型的不同,生成不同的节点。while (this._peek.type !== TokenType.EOF) {if (this._peek.type === TokenType.TAG_OPEN_START ||this._peek.type === TokenType.INCOMPLETE_TAG_OPEN) {/*** 如果当前 token 是 TokenType.TAG_OPEN_START 类型的,形如 <button,它会以该token作为Element结点的起点,接着解析下一个token,* 如果接着遇到的 token 是 TokenType.ATTR_NAME 类型的,则往下识别出完整的属性并记录Element结点的attrs中。* 如果接着遇到的 token 是 TokenType.TAG_OPEN_END 类型的,表示开始标签要关闭了,一个Element结点构建完成。* (如果该节点有父,将其加入到父结点的children中。否则,将其加入到rootNodes中作为根节点之一。)*/this._consumeStartTag(this._advance());} else if (this._peek.type === TokenType.TAG_CLOSE) {/*** 如果当前 token 是 TokenType.TAG_CLOSE 类型的,形如 </button>,* 会做一些错误处理:* a. 判断开始标签是不是一个自闭合标签,如果是自闭合标签(input、img、br、hr、link等),生成一个error:该tag不需要闭合标签。* b. 判断该标签是否和最近的开始标签匹配,如果不匹配,生成一个error:该闭合标签不匹配。*/this._consumeEndTag(this._advance());} else if (this._peek.type === TokenType.CDATA_START) {/*** 如果当前 token 是 TokenType.CDATA_START 类型的,形如 <![CDATA[, (CDATA 区块以 <![CDATA[ 开头,以 ]]> 结尾。)* 结束上一个元素节点的解析。* 以当前token作为CDATA结点的起点,接着解析下一个token,直到遇到TokenType.CDATA_END类型的token,表示CDATA区块结束,生成一个CDATA区块节点。*/this._closeVoidElement();this._consumeCdata(this._advance());} else if (this._peek.type === TokenType.COMMENT_START) {// 如果当前 token 是 TokenType.COMMENT_START 类型的,形如 <!--,接着解析下一个token,识别注释的内容TokenType.RAW_TEXT 和 注释的关闭TokenType.COMMENT_END,生成一个Comment节点,挂到树上。this._closeVoidElement();this._consumeComment(this._advance());} else if (this._peek.type === TokenType.TEXT || this._peek.type === TokenType.RAW_TEXT ||this._peek.type === TokenType.ESCAPABLE_RAW_TEXT) {// 如果当前token是 文本类型、原生文本类型或转义后的原生文本类型,解析并生成一个Text节点,并挂到树上this._closeVoidElement();this._consumeText(this._advance());} else if (this._peek.type === TokenType.EXPANSION_FORM_START) {// 生成Expansion节点,挂到树上this._consumeExpansion(this._advance());} else if (this._peek.type === TokenType.BLOCK_OPEN_START) {/*** 如果当前元素是块级元素的开始标签,* 接着解析下一个token,识别出块级元素的参数,记录在Block结点的 parameters 中,* 直到识别到块级元素开始标签的结束标志,生成一个Block结点,挂到树上。*/this._closeVoidElement();this._consumeBlockOpen(this._advance());} else if (this._peek.type === TokenType.BLOCK_CLOSE) {/*** 如果当前token是 TokenType.BLOCK_CLOSE ,会判断是否有与之对应的开始标签,* 如果没有匹配的开始标签,则生成并记录一个error:该block可能已提前关闭。 如果您想编写 } 字符,则应使用 “}” HTML实体代替。*/this._closeVoidElement();this._consumeBlockClose(this._advance());} else if (this._peek.type === TokenType.INCOMPLETE_BLOCK_OPEN) {/*** 如果当前token是 TokenType.INCOMPLETE_BLOCK_OPEN “不完整的block的打开”类型,* 接着往下解析,识别出块级元素的参数,记录在Block结点的 parameters 中,* 同时记录一个error:这是一个不完整的块 “block名称”。 如果您想编写 @ 字符,则应使用 “@” HTML实体代替。*/this._closeVoidElement();this._consumeIncompleteBlock(this._advance());} else {// 如果当前token不是上述提到的token类型,跳过该token,继续处理下一个tokenthis._advance();}......}}
}
解析的语法树结果的示例:
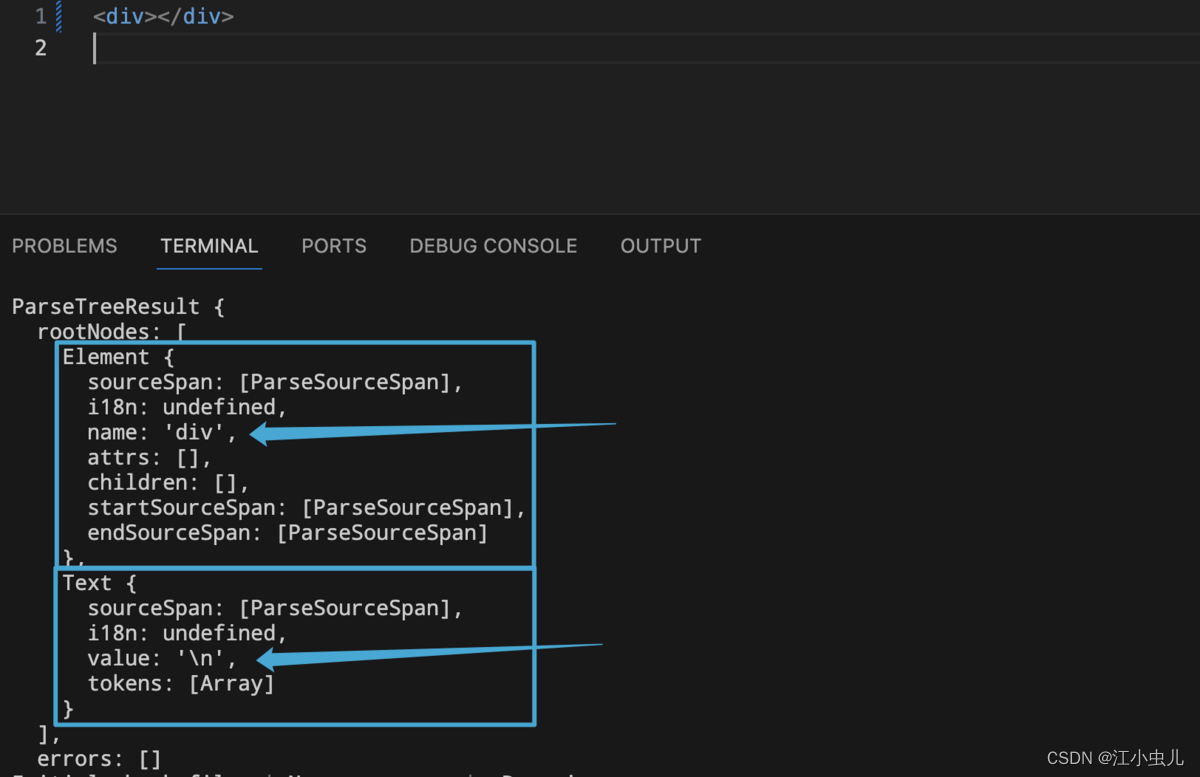
示例1: 下面这个示例结构比较简单,没有涉及到结构嵌套,也没有绑定属性。 共有两个根节点,分别是Element节点 <div></div> 和Text节点 \n 。
示例2:这个示例中有属性绑定和插值。
<button #btn [disabled]="true" (click)="clickIt()">{{ count }}</button>解析结果:一个元素节点和一个文本节点。元素节点里有元素的名称叫 button ,元素的属性有3个属性 #btn [disabled] (click) ,还记录了一些其它信息,具体如下:
ParseTreeResult {rootNodes: [Element { // Element 类型的节点sourceSpan: ParseSourceSpan {start: ParseLocation {file: [ParseSourceFile],offset: 0,line: 0,col: 0},end: ParseLocation {file: [ParseSourceFile],offset: 51,line: 0,col: 51},fullStart: ParseLocation {file: [ParseSourceFile],offset: 0,line: 0,col: 0},details: null}i18n: undefined,name: 'button', // 元素名称attrs: [ // 属性数组Attribute {sourceSpan: [ParseSourceSpan],i18n: undefined,name: '#btn', value: '',keySpan: [ParseSourceSpan],valueSpan: undefined,valueTokens: undefined},Attribute {sourceSpan: [ParseSourceSpan],i18n: undefined,name: '[disabled]', value: 'true',keySpan: [ParseSourceSpan],valueSpan: [ParseSourceSpan],valueTokens: [Array]},Attribute {sourceSpan: [ParseSourceSpan],i18n: undefined,name: '(click)', value: 'clickIt()',keySpan: [ParseSourceSpan],valueSpan: [ParseSourceSpan],valueTokens: [Array]}],children: [],startSourceSpan: [ParseSourceSpan],endSourceSpan: [ParseSourceSpan]},Text { // 文本类型的节点sourceSpan: [ParseSourceSpan],i18n: undefined,value: '\n', // 内容是一个换行tokens: [Array]}],errors: []
}
到这里,html 模板的抽象语法树就构造好了。整个流程下来经历了:
源代码 → 词法分析(字符→tokens) → 语法分析,生成语法树(tokens→nodes→tree)。
ast(抽象语法树)
html 模板解析中的抽象语法树,提供了以下这些定义和方法。
节点类型:Attribute | Comment | Element | Expansion | ExpansionCase | Text | Block | BlockParameter。
节点结构(节点信息):
每个节点里都记录了sourceSpan 信息,并提供了访问该节点的方法。
interface BaseNode {sourceSpan: ParseSourceSpan;visit(visitor: Visitor, context: any): any;
}
节点的跨度信息 ParseSourceSpan。(span 解释为:节点的跨度)
- start:开始位置
- end:结束位置
- fullStart:token 的开始位置
- details:其它相关的信息,比如标识符名称等
其中,start、end、fullStart 字段里都记录了 file.url、file.content、offset、line、col)。可借助 工具 查看抽象语法树结构。
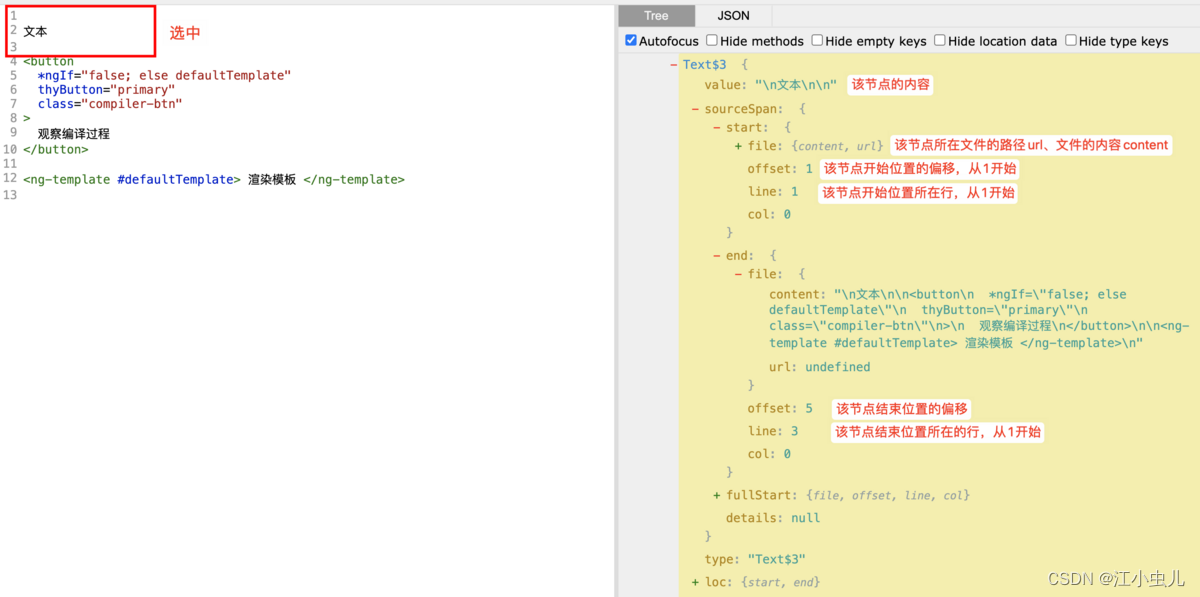
提供了访问语法树的接口、方法:
访问器 Visitor 接口:定义了节点访问器应该具备的方法规范,使得不同的类可以通过实现相同的接口来实现代码的模块化、解耦合和扩展。RecursiveVisitor、HtmlAstToIvyAst、WhitespaceVisitor、NonBindableVisitor、_Expander 这些访问器都实现了 Visitor 接口。
export interface Visitor {visit?(node: Node, context: any): any;visitElement(element: Element, context: any): any;visitAttribute(attribute: Attribute, context: any): any;visitText(text: Text, context: any): any;visitComment(comment: Comment, context: any): any;visitExpansion(expansion: Expansion, context: any): any;visitExpansionCase(expansionCase: ExpansionCase, context: any): any;visitBlock(block: Block, context: any): any;visitBlockParameter(parameter: BlockParameter, context: any): any;
}
节点访问:每个类型的节点都有自己的 visit 方法。由于上述接口约定了访问器的规范,所以,访问者 visitor 在访问节点时,不需要关心访问器里的具体实现,只需要根据节点的类型调访问器里对应的方法即可。
export class Comment implements BaseNode {constructor(public value: string|null, public sourceSpan: ParseSourceSpan) {}visit(visitor: Visitor, context: any): any {return visitor.visitComment(this, context);}
}export class BlockParameter implements BaseNode {constructor(public expression: string, public sourceSpan: ParseSourceSpan) {}visit(visitor: Visitor, context: any): any {return visitor.visitBlockParameter(this, context);}
}......
访问节点 visitAll:对于同一层级的节点 Node[] 进行遍历,如果访问器实例提供的统一的所有节点的visit方法,则会使用 visitor.visit,否则会调用节点自己的 ast.visit 方法,返回最终访问的结果。
export function visitAll(visitor: Visitor, nodes: Node[], context: any = null): any[] {const result: any[] = [];const visit = visitor.visit ?(ast: Node) => visitor.visit!(ast, context) || ast.visit(visitor, context) :(ast: Node) => ast.visit(visitor, context);nodes.forEach(ast => {const astResult = visit(ast);if (astResult) {result.push(astResult);}});return result;
}
递归访问节点 RecursiveVisitor:除了访问当前节点本身,还会访问当前节点的子节点 visitChildren。
export class RecursiveVisitor implements Visitor {constructor() {}visitElement(ast: Element, context: any): any {this.visitChildren(context, visit => {visit(ast.attrs);visit(ast.children);});}......
}
总的来说,html 模板解析里的抽象语法树,定义了模板中节点的类型和数据结构,提供了遍历节点数组和递归访问抽象语法树的方法。
错误处理
从词法分析阶段得到 TokenizeResult 和语法分析阶段得到 ParseTreeResult 的具体实现过程可以看出,整个过程中每一步的解析都有在做错误处理并记录 errors 信息。
词法解析的分词器 Tokenizer 中维护了一个 errors: TokenError ,分词处理过程中遇到的错误,会记录在内,并在最终返回token化结果时一并返回。
return new TokenizeResult(mergeTextTokens(tokenizer.tokens), tokenizer.errors, tokenizer.nonNormalizedIcuExpressions);
html 解析的树构造器 TreeBuilder 中也维护了一个 errors: TreeError[] ,构造语法树的过程中遇到的错误会记录在内,在最终返回解析结果时会把 tokenize 和 parse 的错误合并返回。
这些错误处理的作用之一:在程序运行时(解析模板的过程中)提示开发者错误的位置和错误类型。
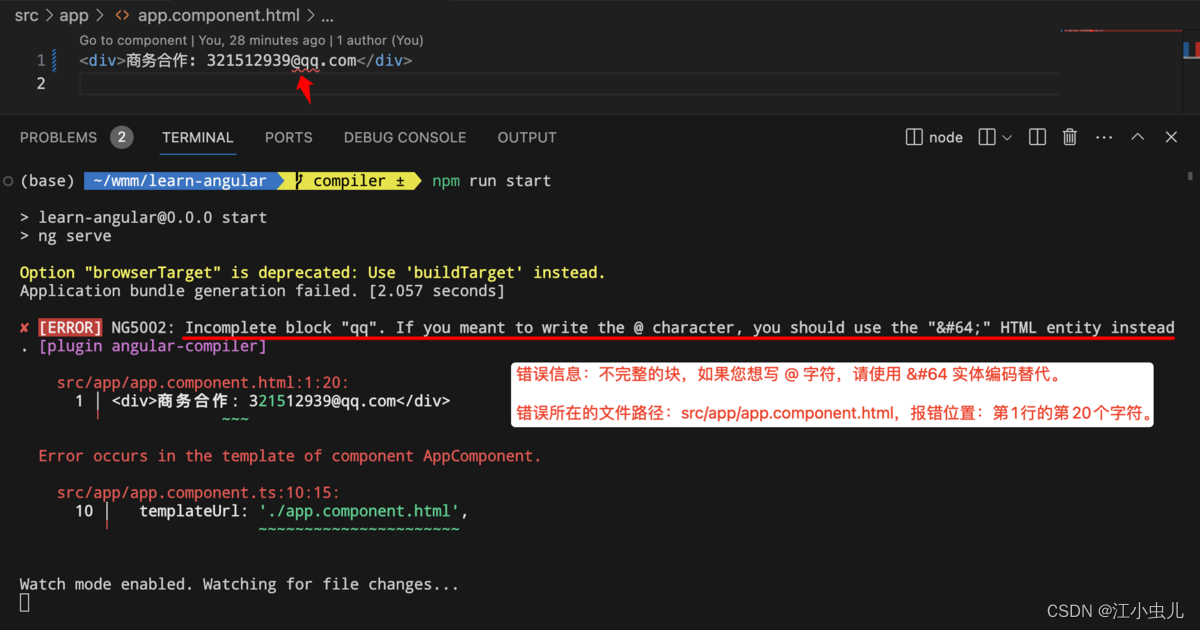
比如:在语法分析阶段 TreeBuilder.build 过程中,对于 TokenType.INCOMPLETE_BLOCK_OPEN token是不完整的块的打开类型的处理,会记录一个错误:

在程序运行时,将错误信息提示给开发者:
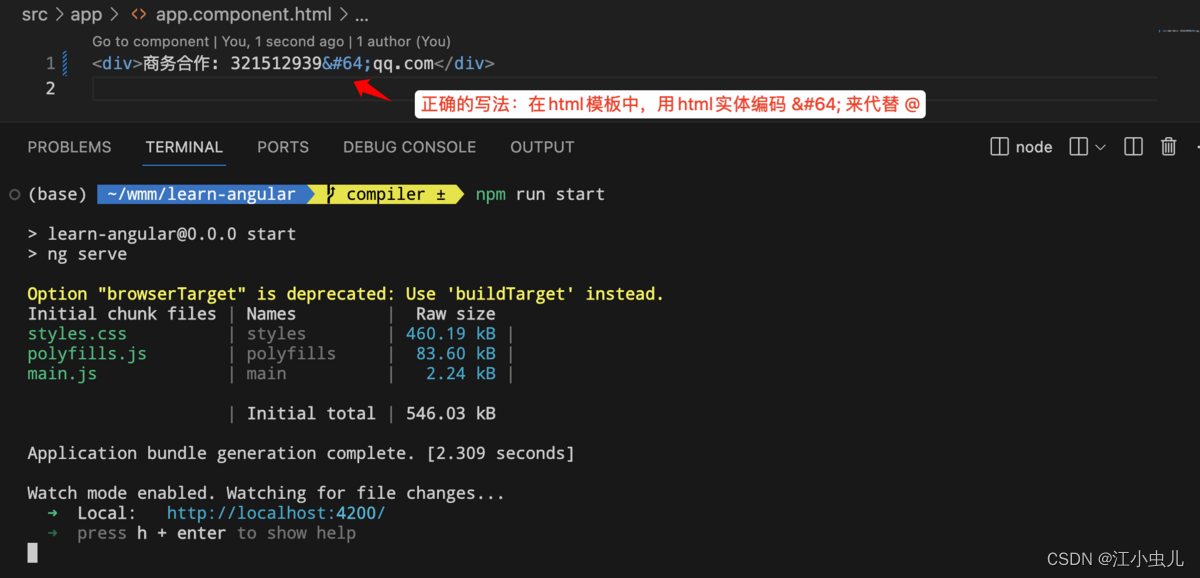
开发者根据错误提示,修改代码,得到正确的代码:
总的来说,解析器(Parser)是将输入数据按照语法规则进行解析和分析的工具,它可以将输入数据转换成易于理解和处理的形式,为后续的处理、分析或转换提供基础。
到此,我们已经了解了 html 解析器的工作内容,它主要用于对视图模板中的标签元素以及标签元素上绑定的属性情况进行解析和错误处理。
binding 解析器
针对标签元素上绑定的属性,Angular compiler 提供了单独解析器 BinddingParser,属性的值往往是一个表达式,针对表达式,Angular compiler 提供了解析器 ExpressionParser。
BindingParser 解析器解析的场景有以下这些:
- 解析 插值
- 解析 内联模板绑定
- 解析 属性的绑定
- 解析 事件,包括动画事件和常规事件
- …
我们在 html 模板中常用到的绑定有以下这些:
- Property:对属性的常规绑定。 例如:
[属性]=“表达式” - Attribute:对元素属性的绑定。 例如:
[attr.name]=“表达式” - Class:对 CSS 类的绑定。 例如:
[class.name]=“条件表达式” - Style:对样式规则的绑定。 例如:
[style.rule]=“表达式” - Animation:对动画引用的绑定。 例如:
[animate.key]=“表达式” - TwoWay:双向绑定的属性。 例如:
[(属性)]=“表达式” - …

BindingParser 对于不同场景的绑定有不同的解析过程。其中一种场景(插值解析)的解析过程: 调用 ExpressionParser 解析表达式,同时报告解析过程中遇到的错误。
parseXXX(value: string, sourceSpan: ParseSourceSpan,interpolatedTokens: InterpolatedAttributeToken[]|InterpolatedTextToken[]|null): ASTWithSource {const sourceInfo = sourceSpan.start.toString();const absoluteOffset = sourceSpan.fullStart.offset;try {// 调用 ExpressionParser 解析表达式const ast = this._exprParser.parseXXX(value, sourceInfo, absoluteOffset, interpolatedTokens, this._interpolationConfig)!;// 错误处理if (ast) this._reportExpressionParserErrors(ast.errors, sourceSpan);return ast;} catch (e) {// 错误处理this._reportError(`${e}`, sourceSpan);return this._exprParser.wrapLiteralPrimitive('ERROR', sourceInfo, absoluteOffset);}
}下面我会展开介绍 bingding 解析过程中使用到的 ExpressionParser。
Angular 在编译模板的过程中,把属性绑定的值统称为表达式(expression)。
什么是表达式? 在编程中,表达式(Expression)是由操作数(Operands)和运算符(Operators)组成的序列,用来计算并得到一个结果。表达式可以是简单的值,也可以是包含函数调用、运算符、变量引用等的复杂组合。表达式的计算结果通常是一个值,这个值可以是数字、字符串、布尔值等。
表达式的类型可以分为以下几种: - Unary:一元操作表达式,形如: -2 、 +5 - Binary:二进制表达式,形如: 1+1 - Conditional:条件表达式,形如: canDo ? true : true - Call:回调,形如: clickIt($event) - ......
对于表达式的解析,Angular Compiler 提供了一个单独的解析模块 expression_parser,下面我们来学习一下它的解析过程:表达式源代码片段 → 词法分析 → 语法分析(解析树) → …。
lexer(词法分析器)
ExpressionParser.lexer
表达式解析的第一步:词法分析。
它的工作内容是:将表达式源代码片段进行切割分词,生成 tokens 数组。
核心的概念有三个:TokenType、Lexer(分词器)、Scanner(扫描器)。
Token 类型:
- Character 0 字符
- Identifier 1 标识符
- PrivateIdentifier 2 私有标识符
- Keyword 3 关键字 (var、let、as、null、undefined、true、false、if、else、this)
- String 4 字符串
- Operator 5 操作符
- Number 6 数字
- Error 7 错误
分词器 Lexer:分词器的逻辑比较简单和清晰。
export class Lexer {// 原材料:接收一个表达式源代码片段 texttokenize(text: string): Token[] {// 实例化一个扫描器,并将要扫描的文本传给这个扫描器const scanner = new _Scanner(text);const tokens: Token[] = [];// 通过扫描器,逐个扫描源代码片段中的字符,切割并生成一个一个的 tokenlet token = scanner.scanToken();while (token != null) {tokens.push(token);token = scanner.scanToken();}// 产出物:tokensreturn tokens;}}
扫描器 Scanner: 用于对表达式源码片段进行从左到右逐个字符扫描,根据字符特征识别并生成 token。
// 主要看 scanToken 方法中,每种 token 类型的解析和生成过程。
class _Scanner {// input 是即将要被扫描的表达式源代码字符串constructor(public input: string) {this.length = input.length;this.advance();}length: number;// peek:记录当前被扫描到的字符(UTF-16 字符码)peek: number = 0;index: number = -1;// 通过字符下标的递增 ++index 从左往右扫描advance() {this.peek = ++this.index >= this.length ? chars.$EOF : this.input.charCodeAt(this.index);}scanToken(): Token|null {let peek = this.peek, index = this.index;// 如果当前字符是字母,则继续往右扫描直到匹配到一个 identifier token 并返回if (isIdentifierStart(peek)) return this.scanIdentifier();// 如果当前字符是数字,则继续往右扫描直到匹配到一个 number token 并返回if (chars.isDigit(peek)) return this.scanNumber(index);const start: number = index;switch (peek) {// 如果当前扫描到的是单点符,继续向右扫描,当遇到数字时,继续往右扫描直到匹配到一个 number token 并返回,否则当做一个 character token 返回case chars.$PERIOD: // .this.advance();return chars.isDigit(this.peek) ? this.scanNumber(start) :newCharacterToken(start, this.index, chars.$PERIOD);// 如果扫描的是下面这些字符,则直接生成一个 character token case chars.$LPAREN: // (case chars.$RPAREN: // )case chars.$LBRACE: // {case chars.$RBRACE: // }case chars.$LBRACKET: // [case chars.$RBRACKET: // ]case chars.$COMMA: // ,case chars.$COLON: // :case chars.$SEMICOLON: // ;return this.scanCharacter(start, peek);// 如果扫描到的是单引号或双引号,则继续往右扫描直到匹配到一个 string token 并返回case chars.$SQ: // 'case chars.$DQ: // "return this.scanString();// 如果扫描到的的是 #,则继续往右扫描直到匹配到一个 private identifier token 并返回case chars.$HASH: // #return this.scanPrivateIdentifier();// 如果扫描到的是以下这些字符,直接生成一个 operator tokencase chars.$PLUS: // +case chars.$MINUS: // -case chars.$STAR: // *case chars.$SLASH: // /case chars.$PERCENT: // %case chars.$CARET: // ^return this.scanOperator(start, String.fromCharCode(peek));// 如果扫描到的是 ?,会继续往右扫描匹配 `a ?? b` 或 'a?.b' 这两种情况之一,然后生成一个 operator tokencase chars.$QUESTION:return this.scanQuestion(start);// 如果扫描到的是 <、>,会继续往右扫描匹配 <、<= 或 >、>= 这两种情况之一,然后生成一个 operator tokencase chars.$LT: // <、<= 小于,小于等于case chars.$GT: // >、<= 大于,大于等于return this.scanComplexOperator(start, String.fromCharCode(peek), chars.$EQ, '=');// 如果扫描到的是 !、=,会继续往右扫描匹配 !、!=、!== 或 =、==、=== 这两种情况之一,然后生成一个 operator token,返回的是能匹配到的最大长度的case chars.$BANG: // !case chars.$EQ: // =return this.scanComplexOperator(start, String.fromCharCode(peek), chars.$EQ, '=', chars.$EQ, '=');// 如果扫描到的是 &,继续往右扫描匹配 & 或 &&,然后生成一个 operator token,返回的是能匹配到的最大长度的case chars.$AMPERSAND: // &return this.scanComplexOperator(start, '&', chars.$AMPERSAND, '&');// 如果扫描到的是 |,继续往右扫描匹配 | 或 ||,然后生成一个 operator token,返回的是能匹配到的最大长度的case chars.$BAR: // |return this.scanComplexOperator(start, '|', chars.$BAR, '|');// 如果扫描到的是无间断空格,跳过空格,继续往前扫描case chars.$NBSP: // 无间断空格while (chars.isWhitespace(this.peek)) this.advance();return this.scanToken();}this.advance();return this.error(`Unexpected character [${String.fromCharCode(peek)}]`, 0);}
}解析示例1:

对于其中的表达式 a + b 的解析,生成的 tokens 信息如下:
tokens: [Token { index: 1, end: 2, type: 1, numValue: 0, strValue: 'a' }, // IdentifierToken { index: 3, end: 4, type: 5, numValue: 0, strValue: '+' }, // OperatorToken { index: 5, end: 6, type: 1, numValue: 0, strValue: 'b' } // Identifier
]
解析示例2:

对其中的表达式 !(1 > 2) ? true : false 的解析,生成的 tokens 信息如下:
tokens: [Token { index: 0, end: 1, type: 5, numValue: 0, strValue: '!' }, // OperatorToken { index: 1, end: 2, type: 0, numValue: 40, strValue: '(' }, // CharacterToken { index: 2, end: 3, type: 6, numValue: 1, strValue: '' }, // Number 1Token { index: 4, end: 5, type: 5, numValue: 0, strValue: '>' }, // OperatorToken { index: 6, end: 7, type: 6, numValue: 2, strValue: '' }, // Number 2Token { index: 7, end: 8, type: 0, numValue: 41, strValue: ')' }, // 字符Token { index: 9, end: 10, type: 5, numValue: 0, strValue: '?' }, // OperatorToken { index: 11, end: 15, type: 3, numValue: 0, strValue: 'true' },// KeywordToken { index: 16, end: 17, type: 0, numValue: 58, strValue: ':' },// CharacterToken { index: 18, end: 23, type: 3, numValue: 0, strValue: 'false' }// Keyword
]
parser(解析器)
ExpressionParser.parser
表达式解析的第二步:语法分析。
拿到上一步词法分析的输出结果 tokens,解析成语法树同时处理和记录解析过程中发现的错误。下面这段“伪代码” 反映了其解析的过程。
ExpressionParser {parseXXX() {// 拿到上一步(词法分析)的输出结果 tokensconst tokens = this._lexer.tokenize(sourceToLex);// 进行下一步(语法分析):解析生成语法树、错误处理const ast =new _ParseAST(input, location, absoluteOffset, tokens, ParseFlags.Action, errors, 0);// 返回解析结果return new ASTWithSource(ast, input, location, absoluteOffset, this.errors);}
}
表达式解析器,以 表达式 为解析目标,针对不同绑定场景,解析的过程和结果会有不同。
绑定场景主要有:
- 属性绑定上的表达式
- 事件绑定(普通事件/双向绑定事件)上的表达式
- 插值表达式
- 微语法表达式
场景一:属性绑定上的表达式(parseBinding)

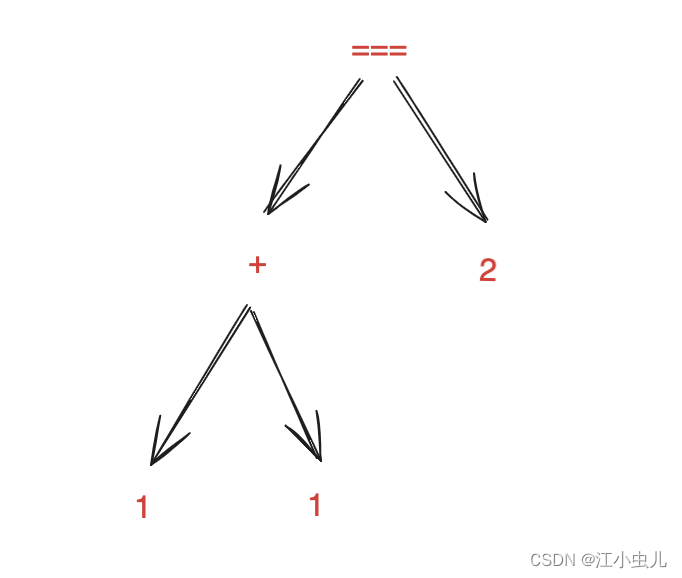
解析目标: 1 + 1 ===2
解析结果:
// parseBinding Result
Binary {span: ParseSpan { start: 0, end: 11 },sourceSpan: AbsoluteSourceSpan { start: 75, end: 86 },operation: '===', // 树根:===left: Binary { // 左子树:1+1span: ParseSpan { start: 0, end: 5 },sourceSpan: AbsoluteSourceSpan { start: 75, end: 80 },operation: '+',left: LiteralPrimitive {span: [ParseSpan],sourceSpan: [AbsoluteSourceSpan],value: 1},right: LiteralPrimitive {span: [ParseSpan],sourceSpan: [AbsoluteSourceSpan],value: 1}},right: LiteralPrimitive { // 右子树:2span: ParseSpan { start: 10, end: 11 },sourceSpan: AbsoluteSourceSpan { start: 85, end: 86 },value: 2}
]语法树结果的示例图:
场景二:事件绑定上的表达式(parseAction)

这个示例中,表达式解析的目标是 clickIt($event) ,解析的结果:生成一个 Call 回调节点,回调的接收者 receiver 是一个只读属性,名为 clickIt,它的参数也是一个只读属性,名为 $event,其它信息。
Call {span: ParseSpan { start: 0, end: 15 },sourceSpan: AbsoluteSourceSpan { start: 84, end: 99 },receiver: PropertyRead {span: ParseSpan { start: 0, end: 7 },sourceSpan: AbsoluteSourceSpan { start: 84, end: 91 },nameSpan: AbsoluteSourceSpan { start: 84, end: 91 },receiver: ImplicitReceiver {span: [ParseSpan],sourceSpan: [AbsoluteSourceSpan]},name: 'clickIt'},args: [PropertyRead {span: [ParseSpan],sourceSpan: [AbsoluteSourceSpan],nameSpan: [AbsoluteSourceSpan],receiver: [ImplicitReceiver],name: '$event'}],argumentSpan: AbsoluteSourceSpan { start: 92, end: 98 }
}
下面这个示例中,表达式解析的目标是 !!canDo ? clickIt($event) : null:

解析的结果:生成一个 Conditional 条件节点,节点里记录了 condition、trueExp、falseExp 等信息。
Conditional {span: ParseSpan { start: 0, end: 32 },sourceSpan: AbsoluteSourceSpan { start: 17, end: 49 },condition: PrefixNot {span: ParseSpan { start: 0, end: 7 },sourceSpan: AbsoluteSourceSpan { start: 17, end: 24 },expression: PrefixNot {span: [ParseSpan],sourceSpan: [AbsoluteSourceSpan],expression: [PropertyRead]}},trueExp: Call {span: ParseSpan { start: 10, end: 25 },sourceSpan: AbsoluteSourceSpan { start: 27, end: 42 },receiver: PropertyRead {span: [ParseSpan],sourceSpan: [AbsoluteSourceSpan],nameSpan: [AbsoluteSourceSpan],receiver: [ImplicitReceiver],name: 'clickIt'},args: [ [PropertyRead] ],argumentSpan: AbsoluteSourceSpan { start: 35, end: 41 }},falseExp: LiteralPrimitive {span: ParseSpan { start: 28, end: 32 },sourceSpan: AbsoluteSourceSpan { start: 45, end: 49 },value: null}
}
场景三:插值表达式(parseInterpolation)

在这个示例中,解析的对象是 -count ,解析的结果:生成一个 Unary 一元操作节点。
expressionNodes:[Unary {span: ParseSpan { start: 3, end: 9 },sourceSpan: AbsoluteSourceSpan { start: 8, end: 14 },operation: null,left: null,right: null,operator: '-', // 操作符expr: PropertyRead { // 表达式,是一个只读属性,countspan: [ParseSpan],sourceSpan: [AbsoluteSourceSpan],nameSpan: [AbsoluteSourceSpan],receiver: [ImplicitReceiver],name: 'count'}}
]

这个示例中,文本里包含了两个插值,针对这段源代码解析并生成了两个表达式节点。
expressionNodes:[PropertyRead {span: ParseSpan { start: 14, end: 18 },sourceSpan: AbsoluteSourceSpan { start: 52, end: 56 },nameSpan: AbsoluteSourceSpan { start: 52, end: 56 },receiver: ImplicitReceiver {span: [ParseSpan],sourceSpan: [AbsoluteSourceSpan]},name: 'name'},PropertyRead {span: ParseSpan { start: 30, end: 33 },sourceSpan: AbsoluteSourceSpan { start: 68, end: 71 },nameSpan: AbsoluteSourceSpan { start: 68, end: 71 },receiver: ImplicitReceiver {span: [ParseSpan],sourceSpan: [AbsoluteSourceSpan]},name: 'age'}
场景四:微语法表达式 *ngIf *ngFor (parseTemplateBindings)
模板绑定 TemplateBinding:在微语法表达式绑定这块,绑定的类型分为 VariableBinding(变量绑定) 和 ExpressionBinding(表达式绑定) 两种,解析的结果以 key-value 键值对的形式记录。
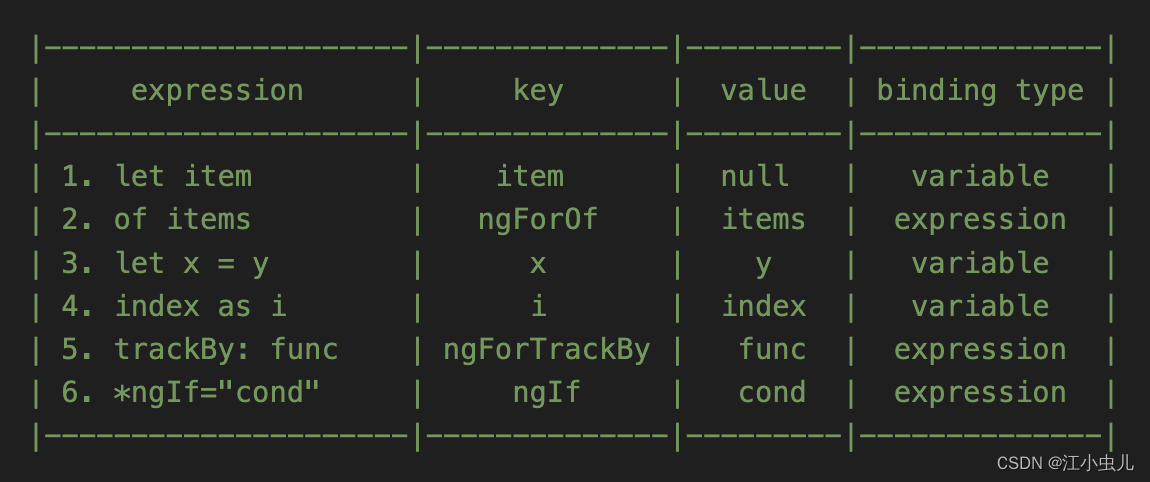
示例:

TemplateBindingParseResult {templateBindings: [ExpressionBinding { // *ngForsourceSpan: [AbsoluteSourceSpan],key: { source: 'ngFor', span: [AbsoluteSourceSpan] },value: null},VariableBinding { // let itemsourceSpan: [AbsoluteSourceSpan],key: { source: 'item', span: AbsoluteSourceSpan { start: 185, end: 189 } },value: null},ExpressionBinding { // of itemssourceSpan: [AbsoluteSourceSpan],key: { source: 'ngForOf', span: [AbsoluteSourceSpan] },value: ASTWithSource {span: [ParseSpan],sourceSpan: [AbsoluteSourceSpan],ast: [PropertyRead],source: 'items',location: '/Users/wumeimin/wmm/learn-angular/src/app/app.component.html@6:5',errors: []}},VariableBinding { // let index = indexsourceSpan: [AbsoluteSourceSpan],key: {source: 'index',span: AbsoluteSourceSpan { start: 204, end: 209 }},value: {source: 'index',span: AbsoluteSourceSpan { start: 212, end: 217 }}}],warnings: [],errors: []
}

TemplateBindingParseResult {templateBindings: [ExpressionBinding {sourceSpan: [AbsoluteSourceSpan],key: { source: 'ngIf', span: [AbsoluteSourceSpan] },value: ASTWithSource {span: [ParseSpan],sourceSpan: [AbsoluteSourceSpan],ast: [Conditional],source: '2 + 3 > 5 ? false : true',location: '/Users/wumeimin/wmm/learn-angular/src/app/app.component.html@0:5',errors: []}}],warnings: [],errors: []
}
ast(抽象语法树)
binding 中表达式解析器的抽象语法树,定义了以下基础能力: 节点的类型、节点的结构(存哪些信息)、提供访问语法树中节点的访问器、提供从一种语法树转换成另一种语法树的转换器。
节点的结构:
// 表达式语法树节点的抽象类
export abstract class AST {constructor(// 节点的跨度信息:start:number end:numberpublic span: ParseSpan,// 表达式在源代码文件中的绝对位置:start:number end:numberpublic sourceSpan: AbsoluteSourceSpan) {}// 访问该类型的节点的方法 visitabstract visit(visitor: AstVisitor, context?: any): any;toString(): string {return 'AST';}
}
访问节点的接口 AstVisitor:定义了节点访问器应该具备的方法规范,使得不同的类可以通过实现相同的接口来实现代码的模块化、解耦合和扩展。RecursiveAstVisitor、AstTransformer 都实现了这个接口。
export interface AstVisitor {visit?(ast: AST, context?: any): any;visitUnary?(ast: Unary, context: any): any;visitBinary(ast: Binary, context: any): any;visitChain(ast: Chain, context: any): any;visitConditional(ast: Conditional, context: any): any;visitThisReceiver?(ast: ThisReceiver, context: any): any;visitImplicitReceiver(ast: ImplicitReceiver, context: any): any;visitInterpolation(ast: Interpolation, context: any): any;visitKeyedRead(ast: KeyedRead, context: any): any;visitKeyedWrite(ast: KeyedWrite, context: any): any;visitLiteralArray(ast: LiteralArray, context: any): any;visitLiteralMap(ast: LiteralMap, context: any): any;visitLiteralPrimitive(ast: LiteralPrimitive, context: any): any;visitPipe(ast: BindingPipe, context: any): any;visitPrefixNot(ast: PrefixNot, context: any): any;visitNonNullAssert(ast: NonNullAssert, context: any): any;visitPropertyRead(ast: PropertyRead, context: any): any;visitPropertyWrite(ast: PropertyWrite, context: any): any;visitSafePropertyRead(ast: SafePropertyRead, context: any): any;visitSafeKeyedRead(ast: SafeKeyedRead, context: any): any;visitCall(ast: Call, context: any): any;visitSafeCall(ast: SafeCall, context: any): any;visitASTWithSource?(ast: ASTWithSource, context: any): any;
}
递归访问器 RecursiveAstVisitor:提供递归访问整棵语法树的能力。
export class RecursiveAstVisitor implements AstVisitor {visit(ast: AST, context?: any): any {ast.visit(this, context);}// 访问所有节点visitAll(asts: AST[], context: any): any {for (const ast of asts) {this.visit(ast, context);}}// 递归访问 插值 节点visitInterpolation(ast: Interpolation, context: any): any {this.visitAll(ast.expressions, context);}// 递归访问 回调 节点visitCall(ast: Call, context: any): any {this.visit(ast.receiver, context);this.visitAll(ast.args, context);}visitXXX(ast: any, context: any): any {......}// ......
}
到此,我们对 bingding 解析器的工作内容和实现过程有了一定的了解,它主要用于对模板中的元素上的属性绑定、事件绑定以及绑定的表达式进行解析,记录并报告解析过程中的错误。
扩展:不管是在 html 解析器还是在 bingding 解析器中,对于抽象语法树中节点的访问和操作,都采用了 行为型设计模式中的访问者模式 。访问者模式,用于将 对象结构 和 操作(算法) 分离。
优点:
- 分离数据结构和操作:访问者模式将数据结构和对数据结构的操作分离开来,使得新增操作更加容易,不会影响到数据结构本身。这样做提高了代码的可维护性和扩展性。
- 符合 ”对修改封闭,对扩展开放“ 原则:对于已有的数据结构和操作,不需要修改,只需要新增访问者类即可扩展功能。
- 增加新操作更容易:由于访问者模式将操作封装在访问者对象中,因此要增加新的操作只需要添加新的访问者类即可,而不需要修改已有的数据结构类。可以看一下 htmlAstToRender3Ast 的实现。
htmlAstToRender3Ast ,是模板解析过程中的一个 AstTransformer(语法树转换器),它将 html 抽象语法树转换成 Render3 抽象语法树的一个实现,它在不改变抽象语法树结构的情况下,对节点信息做了除了和转换。
export function htmlAstToRender3Ast() {// 对于已有的数据结构,要增加新的操作只需要添加新的访问者类(transformer)即可const transformer = new HtmlAstToIvyAst(bindingParser, options);// 在不破坏原有语法树结构(htmlAst)的情况下,操作(visitAll)得到一种新的结构(ivyNodes)const ivyNodes = htmlAst.visitAll(transformer, htmlNodes, htmlNodes);
}
class HtmlAstToIvyAst implements htmlAst.Visitor {visitElement() {// ...... 新的操作// return 新的结果}visitXXX() {// ......}
}
到此,模板解析中用到的两个解析器的实现就介绍完了。下面我们将 parseTemplate 的整体流程串起来。
parseTemplate
模板解析过程的概括:
export function parseTemplate(template: string, templateUrl: string, options: ParseTemplateOptions = {}) {// HtmlParser 👈🏻👈🏻👈🏻 解析html标签const htmlParser = new HtmlParser();const parseResult = htmlParser.parse(template, templateUrl, options);let rootNodes: html.Node[] = parseResult.rootNodes;// BindingParser 👈🏻👈🏻👈🏻 解析属性绑定 && ExpressionParser 👈🏻👈🏻👈🏻解析绑定的表达式const bindingParser = new BindingParser(new ExpressionParser(new Lexer()), interpolationConfig, elementRegistry, []);// htmlAstToRender3Ast 👈🏻👈🏻👈🏻// 第一个参数是:上述 HtmlParser 解析得到的语法树 rootNodes// 第二个参数是:绑定解析器 BindingParserconst {treeNodes, errors, styleUrls, styles, ngContentSelectors, commentNodes} = htmlAstToRender3Ast(rootNodes, bindingParser, collectCommentNodes);// 得到解析好的模板const parsedTemplate: ParsedTemplate = {interpolationConfig,preserveWhitespaces,errors: errors.length > 0 ? errors : null,nodes: treeNodes,styleUrls,styles,ngContentSelectors};return parsedTemplate;}
解析示例:
<buttonstyle="width: 100px"[disabled]="true"[attr.tabindex]="tabindex"[class.compiler-btn]="true"[style.width.px]="width"(click)="clickIt($event)"
>{{ count }}
</button>经过模板解析之后得到的语法树结构:
treeNodes: [Element$1 { // 元素节点 buttonname: 'button',attributes: [ // attributesTextAttribute {name: 'style',value: 'width: 100px',sourceSpan: [ParseSourceSpan],keySpan: [ParseSourceSpan],valueSpan: [ParseSourceSpan],i18n: undefined}],inputs: [ // inputsBoundAttribute {name: 'disabled',type: 0,securityContext: 0,value: [ASTWithSource],unit: null,sourceSpan: [ParseSourceSpan],keySpan: [ParseSourceSpan],valueSpan: [ParseSourceSpan],i18n: undefined},BoundAttribute {name: 'tabindex',type: 1,securityContext: 0,value: [ASTWithSource],unit: null,sourceSpan: [ParseSourceSpan],keySpan: [ParseSourceSpan],valueSpan: [ParseSourceSpan],i18n: undefined},BoundAttribute {name: 'compiler-btn',type: 2,securityContext: 0,value: [ASTWithSource],unit: null,sourceSpan: [ParseSourceSpan],keySpan: [ParseSourceSpan],valueSpan: [ParseSourceSpan],i18n: undefined},BoundAttribute {name: 'width',type: 3,securityContext: 2,value: [ASTWithSource],unit: 'px',sourceSpan: [ParseSourceSpan],keySpan: [ParseSourceSpan],valueSpan: [ParseSourceSpan],i18n: undefined}],outputs: [ // outputsBoundEvent { // 绑定的事件name: 'click',type: 0,handler: [ASTWithSource],target: null,phase: null,sourceSpan: [ParseSourceSpan],handlerSpan: [ParseSourceSpan],keySpan: [ParseSourceSpan]}],children: [ // 子节点BoundText { // 绑定的文本value: [{span: ParseSpan { start: 0, end: 15 },sourceSpan: AbsoluteSourceSpan { start: 166, end: 181 },ast: Interpolation$1 { // 插值类型的astspan: [ParseSpan],sourceSpan: [AbsoluteSourceSpan],strings: [Array],expressions: [Array]},source: '\n {{ count }}\n', location: '/Users/wmm/compiler/src/app/app.component.html@7:1',errors: []}],sourceSpan: [ParseSourceSpan],i18n: undefined}],references: [],sourceSpan: [ParseSourceSpan],startSourceSpan: [ParseSourceSpan],endSourceSpan: [ParseSourceSpan],i18n: undefined},Text$3 { // 文本节点value: '\n', sourceSpan: [ParseSourceSpan] }]
拿到上面解析好的模板之后,这个解析好的模板结果(parsedTemplate),会流向整个编译过程的下一个环节,再经过复杂的处理,形成下面我们所看到的 javascript 代码。
总结和运用
本文以 Angular 运行时编译模板 (parseTemplate) 为分享载体,了解其底层的实现过程。从中我们可以得到哪些收获和启发?
思想层面上的认识:
- 模板解析的过程,做了哪些事情 = 解析html、解析绑定(解析表达式)、错误处理。
- 认识编译的底层实现:lexer(词法分析器)、parser(模板和绑定解析器)的实现原理。
- 了解了我们平时在本地开发中运行程序时的一些模板相关的错误提示,是在编译模板阶段分析出来并提示开发者的。
- 认识了从源代码到构造一棵抽象语法树的过程: character → token → Node → Tree。
应用层面上的启发:
从 Angular 模板编译的过程可以看出,它的一个处理过程是这样的:先将源代码构造和映射成一棵抽象语法树,然后再通过深度递归访问树,来对源代码的结构进行分析和转换。我们日常的一些需求的开发,其实也可以运用抽象语法树,去实现一些需求,以达到提高开发效率的目的。