本文来自2024 OceanBase开发者大会,OceanBase CTO 杨传辉的演讲实录—《携手开发者打造一体化数据库》。完整视频回看,请点击这里>>

各位 OceanBase 的开发者,大家上午好!今天非常高兴能够在上海与大家再次相聚,这是 OceanBase 的第二届开发者大会,上次是在北京的望京,这次在上海。

首先,简单对 OceanBase 的架构做一个回顾。2010 年 OceanBase 开始研发,到今天已经有接近 14 年的时间,我们总共经历了两次重大的技术架构升级,以及一次重大的产品升级。
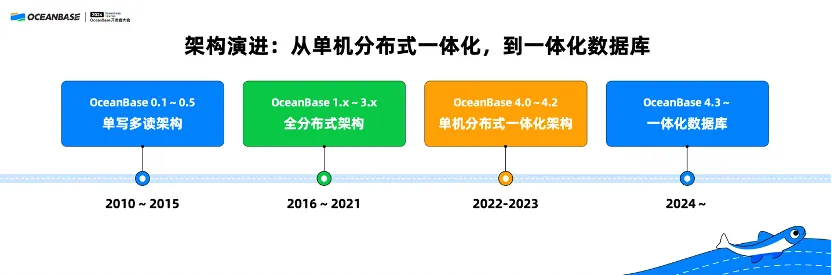
第一次技术架构升级是 2016 年,当时我们发布了 OceanBase 1.0 版,把原先OceanBase 0.5 版本的单写多读架构升级为全分布式架构。2022 年发布了 OceanBase 4.0 版,提出单机分布式一体化架构,使 OceanBase 不仅仅能够应用在大型企业,也可以应用在中小企业乃至创业公司。
去年下半年,我们又提出了一体化数据库,基于之前的单机分布式一体化架构,构建对 OLTP、OLAP、KV、多模乃至未来对 AI 的融合能力,支持各种各样不同的工作负载。
一、回顾开源
大家都知道,OceanBase 是 2021 年 6 月 1 号儿童节那一天正式开源的。其实 OceanBase 开源的时候,业界乃至中国也有一款非常流行的原生分布式数据库,为什么开源社区还需要另外一个原生分布式数据库?
回想当初,我们的想法挺简单的,我们认为作为一款在蚂蚁集团已经应用了十多年,支撑了每年“双 11”所有核心业务场景的产品,OceanBase 的稳定性非常好、性能非常好、性价比也非常高。
当我们把这样的产品开源出去,我们相信用户跟开发者一定会非常喜欢,这就是我们最早开源的初心。当时我们在面向公司内部、面向外部经常说一句话:开源,OceanBase 是认真的。还有一句话:OceanBase 是真开源。直到今天,我对“真开源”这几个字才有了深刻理解,OceanBase 是不是真开源?我们说了不算,只有用户跟开发者说了才算。
比较幸运的是,OceanBase 这两年开源了,我们发展得非常迅速,到今天为止,OceanBase 仅仅是社区版部署的集群数已经超过了一万。而且我们在 OceanBase 4.0 版本发布之后,看到使用 OceanBase 的用户、使用 OceanBase 的集群,增速进入了新台阶。
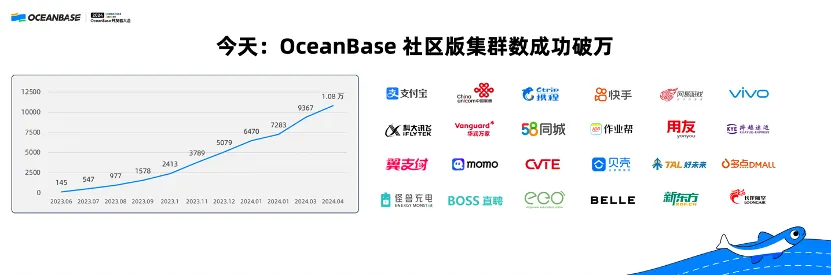
今天,业界主流的互联网公司,包括携程、快手、知乎、vivo、网易等等,他们都在各种各样的场景使用了 OceanBase 社区版。在开源社区,很多开发者已经形成了共识,就是最好的开源分布式数据库,产品技术特性能力最强的一定是 OceanBase。
今天,OceanBase 的客户数量已经突破了 1000 家,并且得到了各种各样的更多认可。在 IDC 去年的中国分布式关系型数据库厂商评估报告里,OceanBase 位列领导者象限,并且在产品能力上处于领先地位;在 Gartner 去年全球云数据库管理系统魔力象限里,OceanBase 也获得了荣誉提及;在“墨天轮中国数据库流行度排行”里,OceanBase 连续 14 个月获得了第一。

(一)用户将 OceanBase 社区版应用在分布式 OLTP 场景
OceanBase 一开始设计之初,主要是用来处理交易、支付这样的 mission-critical 核心业务场景。所以,最早的开源用户还是把 OceanBase 应用在核心业务场景的。
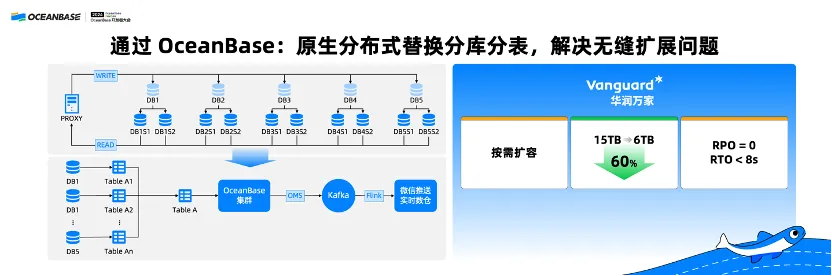
华润万家原先使用 MySQL 分库分表,但我们都知道 MySQL 分库分表没有办法做扩展。通过 OceanBase 原生分布式替换 MySQL 分库分表实现了按需扩容,并且存储容量由原来的 15TB 减少为 6TB,降低了 60%,并且实现 RPO 等于零。
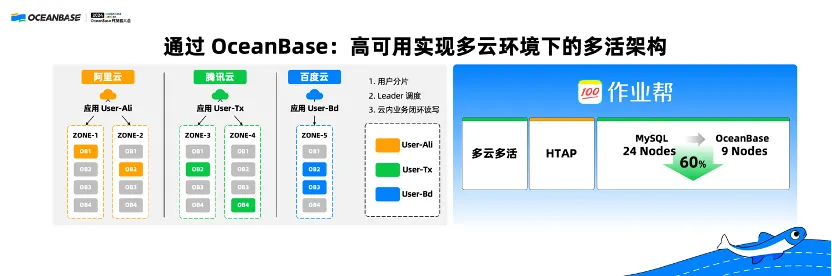
作业帮的基础设施(包括数据库)构建在百度云、阿里云、腾讯云三朵云上,通过 OceanBase 的高可用和容灾能力,实现了多基础设施环境下的多活架构,最终一套系统同时处理 TP 和 AP 混合负载。并且把原来 24 台 MySQL 服务器降低为只有 9 台 OceanBase,节省了 60%。
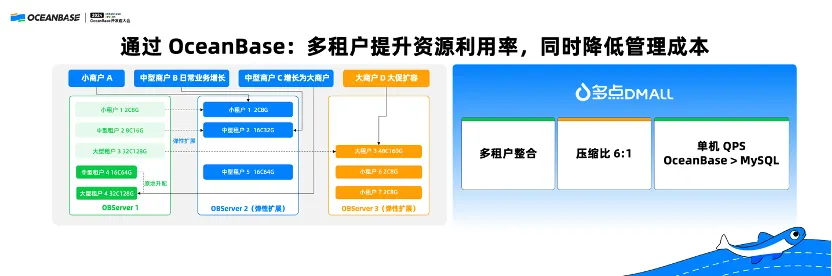
大家应该都去过物美超市,多点 DMALL 服务了包括物美超市在内的很多大大小小的超市。原先多点 DMALL 使用了很多分散的 MySQL 服务器,但是大量的MySQL没有办法做扩展,并且运维成本比较高。通过 OceanBase 的多租户能力实现了数据库的整合,大大降低了运维成本,同时压缩比做到了 6:1。并且在如此高压缩比的前提下,单机的OceanBase性能仍然高于 MySQL。
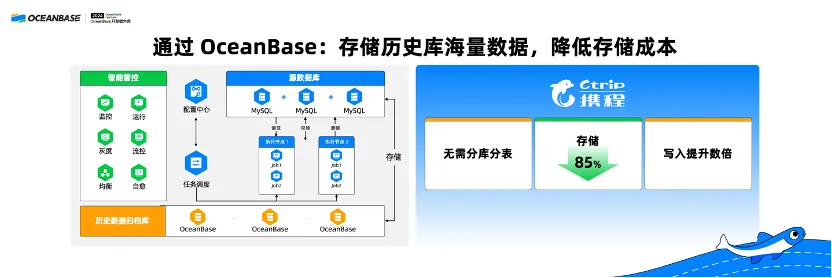
携程是 OceanBase 社区版最早的一批用户之一,他们有一个历史库场景。原先的历史库也是使用的 MySQL 分库分表,但是历史库的数据量增长非常快,MySQL 分库分表无法很方便地做在线动态扩容,通过 OceanBase 原生分布式数据库避免了分库分表,并且存储容量降低了 85%,写入性能提升了数倍。
(二)用户也将 OceanBase 社区版应用在实时 AP、多模场景
虽然 OceanBase 一开始设计是用来处理 mission-critical 核心业务场景,但是我们的开发者也把 OceanBase 应用在实时 AP 和多模的场景。
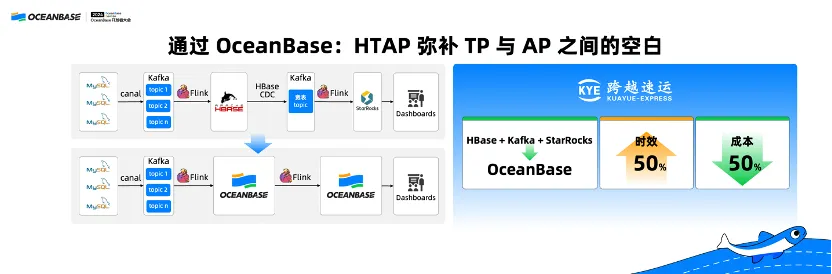
跨越速运在一个偏分析类的场景,原先使用“HBase+Kafka+StarRocks”,并且他们自研了一套系统叫 HBase CDC,把数据从 HBase 拉取到 Kafka 再同步到 StarRocks。这个方案链路非常复杂,而且自研成本很高,因为链路复杂也导致数据处理的时间很长。通过 OceanBase 实现了一套系统解决原来多套系统的问题,硬件成本降低了 50%,同时数据处理的时效提升了 50%。
贝壳有一个字典服务原先使用了 HBase,大家应该很清楚 HBase 有两个特别大的问题:
○ HBase 的部署依赖于 Hadoop 体系,部署起来组件特别多、特别复杂;
○ HBase 无法支持二级索引。
通过 OceanBase 多模的 KV 能力替换 HBase,贝壳最终降低了系统复杂度,查询性能是原来的 2-5 倍,写入性能是原来的 5 倍。

(三)开发者驱动 OceanBase 打造一体化数据库
我有时候就在想,作为一个一开始用来处理 mission-critical 核心业务场景的分布式数据库,为什么我们的开发者会把这样的产品天然应用在实时 AP、应用在多模的场景,把它当成一个一体化数据库来使用?我觉得这和 OceanBase 最早的两个设计有关。
○ 分布式。因为有了分布式所以可以处理海量数据,可以自动扩缩容;
○ LSM-Tree。可以实现高压缩,以一种很低成本的方式处理海量数据。
因为有这样的能力,使得 OceanBase 特别适合海量数据的场景,不仅仅是海量数据的 TP 场景,也包括海量数据的 AP 以及多模场景。因为所有的 AP 和多模,天然就是海量数据的场景。
所以也可以认为,今天其实是开发者和用户的需求,驱动 OceanBase 慢慢成长为一个 All-in-one 的一体化数据库。由原来最早的分布式 TP、到分布式 AP,再到未来的多模以及对于 AI 等各种各样能力的处理,通过一体化的方式可以降低IT成本,让 OceanBase 用户来说变得更加简单。
一体化数据库的背后是一体化架构,既包括内核的一体化存储引擎、一体化事务引擎、一体化 SQL 引擎;也包括构建在一体化架构之上多模的引擎,以及我们对多种基础设施的适配。
OceanBase 也是多云原生的一体化数据库,既能支持公有云也能支持专有云,包括很多国内不同架构的云环境,华为云、腾讯云、阿里云,以及国外的 AWS、GCP 和 Azure,OceanBase 都可以在一套系统里面原生支持。这就意味着,开发者可以通过一样的体验使用 OceanBase 在不同云上的服务。
二、一体化对开发者意味着什么
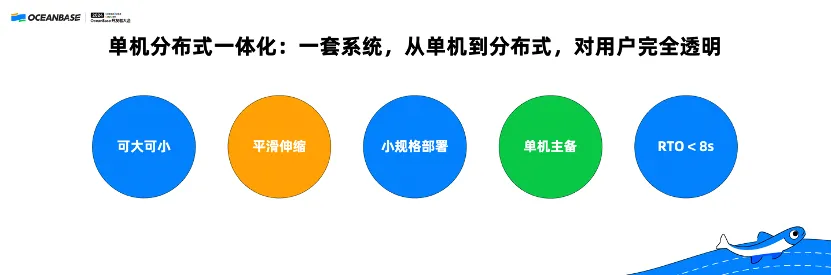
(一)单机分布式一体化:一套系统,从单机到分布式,对用户完全透明
首先,单机分布式一体化,通过一套系统做到从单机到分布式,对用户完全透明。今天,我们在数据库选型的时候,很多开发者首先会有第一个问题:到底选集中式还是分布式?
我想告诉大家,有了 OceanBase 一体化架构以后,我们可以选单机分布式一体化的OceanBase,避免了集中式与分布式的烦恼,一套系统可大可小、平滑伸缩、按需使用,既能支持三副本的 Paxos,也能支持主备同步,RPO = 0,RTO<8秒,并且 OceanBase 也已经支持了小规格的部署,可以应用在大企业,也可以应用在中小企业甚至是创业公司。
(二)多模融合:增加一种查询接口,而不是增加一款数据库
SQL 与 NoSQL 的融合实现多模融合。我认为多模融合不仅仅是提供了一种新的数据模型,更重要的一点在于能够实现多种数据模型之间的融合以及优势互补。
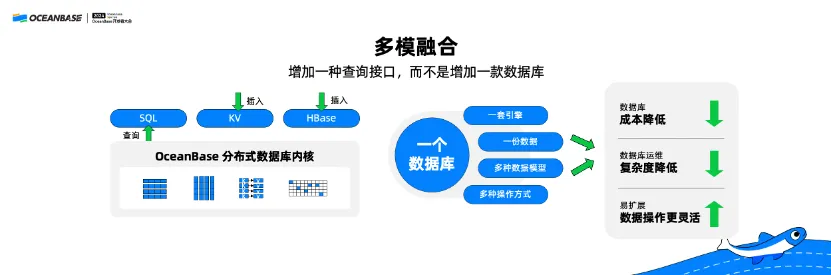
举个例子,很多开发者应该都使用过HBase,HBase的写入接口对于开发者来讲是比较简单、高效、易用的,但是 HBase 因为不支持 SQL,所以它的查询接口使用起来功能不够丰富,比较麻烦。当我们用了多模融合的 OceanBase 之后,可以使用 HBase 兼容的方式把数据写入到 OceanBase,并且采用标准 SQL 的方式查询 OceanBase,这种方式可以非常好地发挥 SQL 与 NoSQL 的双重技术优势。
(三)HTAP = OLTP Plus
TP 与 AP 的融合,我们都在讲一个概念叫 HTAP,我在很多场合里面一直强调一个观点:HTAP 也不是万能的。
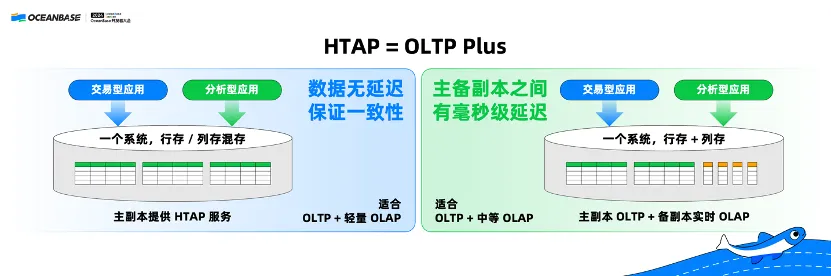
我们认为的 HTAP,简单来讲就是 OLTP Plus,在 OLTP 的基础上支持支撑 OLAP 的能力。有两种主要的部署和应用场景:
第一种,OceanBase 本身是一个多副本的分布式架构,所有的副本都采用相同的行存或者行列混合式存储,由主副本直接提供服务。这种方式的好处在于,数据完全没有延迟,保证一致性。但是问题在于,对 AP 能力的支持相对来说偏弱一些,因为没有列存,比较适合“OLTP+轻量的 OLAP”的场景。
第二种,主副本仍然采用行存或者行列混合式存储,但是其中某一个或者多个备副本可以有列存。这种方式主备之间有延迟,但可以支持更好的 OLAP 的能力,比较适合“OLTP 加中等 OLAP”的场景。
在这里还要特别强调,我认为即使有这两种灵活的部署模式,HTAP 也不是万能的,HTAP 比较适合数据量在几百个 GB-几百个 TB 的场景。如果数据量再大,很多大公司往往会把 TP 和 AP 两套系统分开来。
给大家举一个 HTAP 的案例,海底捞大家应该都去过。原先的 OLTP 使用了 PolarDB 和 PolarDB-X,OLAP 使用了 ADB,并且通过 DTS 实现 PolarDB 到 ADB 之间的数据同步。

海底捞经常要做节假日的促销,并且需要实时根据用户的口味习惯做推荐。通过 OceanBase 的 HTAP 能力,实现了一份数据两份收益,TCO 降低了 35%,同时 AP 性能相比之前提升了 30%。
三、TP & AP 一体化的另一层含义:把分布式 TP 核心能力融入到 AP
前面,我们讲到传统意义上的 HTAP 并不是万能的。现在,我要在这里抛出一个新的概念,TP&AP 一体化的另外一层含义:把分布式TP的核心能力融入到AP。
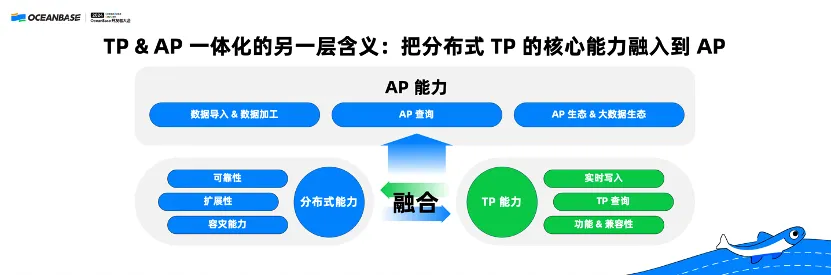
什么意思?它不一定是把 TP 和 AP 放到一个系统,也可以把我们的分布式TP能力直接融合到 AP 系统里面,做出一个更好、更加实时、对开发者更加易用的新型实时分析数据库。
我们都知道传统的 OLAP 系统往往大查询能力很强,AP 生态适配很强,但是无法做实时的写入,因为不支持行存,往往没有办法做实时的点查、实时的 Serving。并且,AP 系统语法的兼容性和功能相对来讲,比 TP 系统还是有一定的差距。而且坦白来讲,今天的 AP 系统比较多样,很多的 AP 系统其实没有应用在核心业务场景,没有核心业务场景打磨的经验,可靠性和稳定性有一定欠缺。
OceanBase 一方面具备很好的分布式能力,是很可靠的,是高可用的,可以保证 RPO 等于零;也有很好的TP能力,能够做实时写入,能够做点查二级索引的回表,来实现 AP 场景里面动态的 Serving;也可以兼容 MySQL,并且 OceanBase 还有一个很好的运维白屏化的管控工具叫 OCP。
当我们把这样的能力与传统的 AP 能力结合在一起,我们就会得到一个新一代的实时 AP 系统。这样的实时 AP 系统,它的实时性变得更强,可以直接在一套系统里面既做大查询又做 Serving;它兼容 MySQL,对用户来讲特别容易使用;它可以直接用 OceanBase 的管控工具做一体化的管控。
四、OceanBase 4.3 正式发布
今天,在这里正式发布 OceanBase 4.3 版本,4.3 版本主要发布三个最重要的核心技术升级:
○ 推出列式存储引擎;
○ 进一步强化 TP&AP 一体化;
○ 打造近 PB 级实时分析数据库 [1TB, 1PB)
下面,对 OceanBase 4.3 版本的核心能力做进一步的展开。
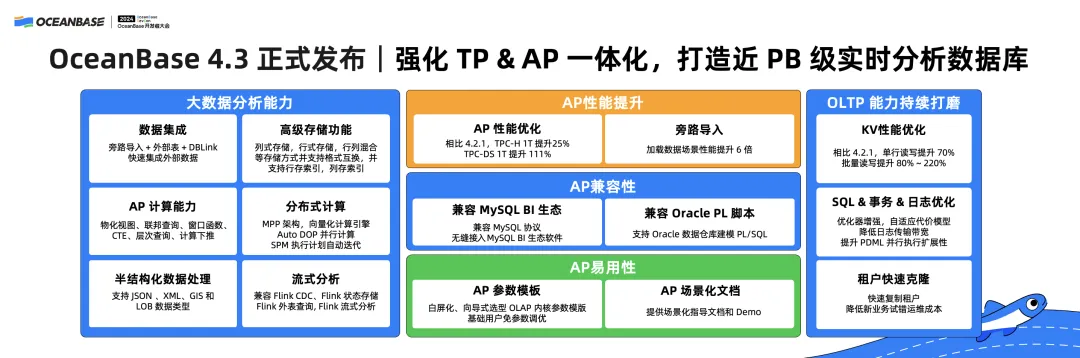
首先,进一步强化TP&AP一体化,持续打磨 OLTP 的能力。在 KV 场景,OceanBase 4.3 版本相比 4.2.1 版本有了大幅度提升,单行读写能力提升了70%,批量读写能力提升了 80%-220%,同时,对于 SQL、事务、日志都做了很多的优化工作。
我们还发布了一个功能——租户快速克隆,开发者应该会非常喜欢这个功能。当我们需要进行一些危险操作的时候,可以首先通过租户克隆操作,克隆出一份快照,万一这个操作出现了问题,破坏了数据,后面也可以很快恢复回来。
第二,4.3 版本进一步增强了 OceanBase 的实时 AP 能力。我们支持旁路导入、外部表,支持列式存储,同时也支持行式存储与列式存储之间的动态转换。
我们支持很多在 OLAP 场景里面非常有用的功能,比如说物化视图、联邦查询、窗口函数、CTE、层次查询、计算下压等等。
我们的分布式计算引擎的能力也得到了大幅度提升,有了更好的 MPP 架构,并且支持了向量化执行引擎,也支持 Auto DOP。同时,4.3版本也增强了对 JSON、GIS 等半结构化数据的支持。OceanBase 4.3 版本也与业界最主流的流式数据库,比如说 Kafka、Flink 做了很好的兼容适配。
第三,在 OLAP 的性能方面。OceanBase 4.3 版本相比 4.2.1 有了大幅度提升,TPC-H 1TB 提升 25%、TPC-DS 1TB 提升 111%,旁路导入性能提升了 6 倍。我们的 TPC-H 性能虽然只提升了 25%,但是大家要知道 OceanBase 的 TPC-H 曾经拿过世界第一,所以是在一个很高的水准上继续提升 25%。
第四,我们也进一步提升了 AP 兼容性。第五,我们通过 AP 参数模板、AP 场景化文档,增强了 OceanBase 4.3 版本的易用性。相信通过我们的场景化文档,开发者可以非常简单地直接体验 OceanBase 4.3 版本。
虽然今天是正式发布 OceanBase 4.3 版本,但是网上已经有了一些 OceanBase 4.3 版本使用的文章。欢迎各位开发者到展区以及官网体验 4.3。
(一)OceanBase 分析型负载跑分测试:PK 业内一流的列式大宽表数据库
大家应该都知道 OceanBase 发布会的特点,尤其是我这个环节最喜欢干的一件事情——跑分。所以,这次我们还是一起现场见证 OceanBase 分析型负载的跑分测试。
其实我们在会前,把 OceanBase 与业界主流的实时分析数据库都做了一个跑分对比,但是考虑到实时分析场景业界的 benchmark 的标杆是 ClickBench(ClickBench 由 ClickHouse 提出,而且现在 ClickHouse 也是排名第一),所以这次在现场,我们将用 OceanBase 直接跟 ClickHouse 进行 ClickBench 性能测试跑分。
去年的时候,我们已经对 OceanBase 4.3 的内测版本,以 ClickHouse 23.11 做了第一次跑分测试;后来,4.3 的内测版本进一步产品化,到今天成为了 4.3.0。同时,我们也发现,不仅仅国产数据库很卷,ClickHouse 也很卷,他们在今年 4 月份又发布了 ClickHouse 24.4,而且性能比原来的 23.11 更好。不过幸好,我们比他们更卷,我们有一个 4.3.x 的内测版。
所以,今天,我们会有四个系统同时做跑分测试:4.3.0、23.11、4.3.x 内测版、24.4,分别代表 OceanBase 和 ClickHouse 最新两代的产品。
我们的跑分测试已经开始,ClickBench 大家应该都很熟悉,它总共有 43 条Query,从 Q0 到 Q42。每一次 ClickBench 跑分,它会对每一条 Query 都总共跑 3 次,选取其中跑得最快、用时最短的一次作为这条 Query 最终的结果。
正在跑分测试的屏幕里面有两种颜色,一种是绿色,一种是红色。绿色表示这个系统跑得更快、时间更短,红色表示跑得更慢。可以看到,所有四个系统都已经完成了跑分——OceanBase 4.3.0 跑 ClickBench 用了 14.5 秒,ClickHouse 23.11 用了 14.8 秒,OceanBase 4.3.x 内测版本用了 12.85 秒,ClickHouse 24.4版本用了 14.26 秒。整体性能,OceanBase 4.3.0 好于 ClickHouse 23.11,但是又弱于ClickHouse 24.4,我们的最新内测版又好于 ClickHouse 24.4,基本上处于非常焦灼的状态。
经过跑分测试,我们可以得出一个结论,同等硬件条件之下,OceanBase 在 4.3 的大宽表查询性能已经达到了 ClickHouse 的同一水平,ClickHouse 也代表实时分析数据库大宽表场景的业界最高水平。

(二)OceanBase AP 致力于打造 PB 以下实时分析数据库的最强六边形战士
前面我们讲了很多 OceanBase 一体化数据库能做 TP、AP 还能做多模、KV、AI,看起来什么都能做。那么到底 OceanBase 真正适合的场景有哪些?这里,我提炼成五类:
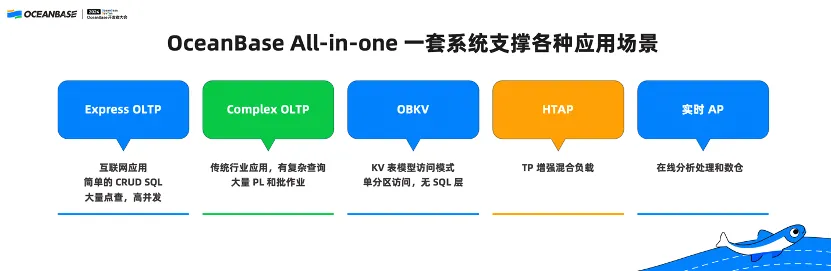
第一,Express OLTP。是我们在互联网行业里面,MySQL 比较适用的场景,是一些简单的读写,并发量很高。
第二,Complex OLTP。是我们传统行业以 Oracle 为代表的商业数据库适用的场景,除了有简单的读写操作也会有一些复杂查询,有跑批的操作,有一些存储过程。
第三,OBKV。是 HBase、Redis 等系统适用的场景。
第四,HTAP。是在一套系统里面既能做 OLTP 又能做实时的 AP,我认为 HTAP 比较适合的场景是几百 GB-几百 TB 的场景。
第五,如果数据量更大,就需要我们今天推出的实时 AP 场景。实时 AP 场景和 HTAP 的区别在于,HTAP 数据源都是一套系统,实时 AP 数据源不仅仅是从 OceanBase 的 TP 系统,也可能是从一些其他的数据库或者是 Kafka、Flink,或者是一些文件、存储系统等等。实时 AP 系统会进一步扩展 OceanBase AP 能力的支持。
实时 AP 适合的数据量是一个 TB 到一个 PB 之间,如果数据量再大,比如超过一个 PB,我认为这往往都是一些大企业的应用场景。像阿里、腾讯这么大的企业一定会有针对自己企业自建的数据湖或者大数据分析系统,这些系统到今天为止,还不是 OceanBase 最适合的范畴。
我们可以基于 OceanBase 的实时 AP 直接构建一个轻量级的实时分析数据库,这样的实时分析数据库数据源比较多样,可以是实时写入也可以是批量写入,也可以是做一些 Update 批量更新。数据到了 OceanBase 之后会分层处理,首先进入到ODS层,再到 DWD、DWS、ADS。
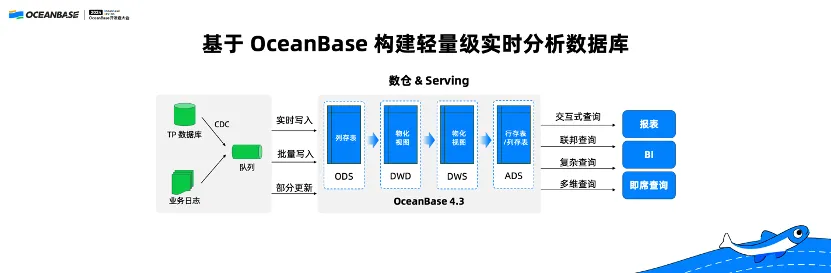
ODS 层存储原始数据,在实时数仓里面往往都是用列存表;DWD 跟 DWS 会对原始数据做两层处理,往往是物化视图;再到最后的 ADS 做 Serving,它有两种可能:有的时候我们的 Serving 都是一些简单的点查或者是索引回表,这个时候是用行存;还有一些时候我们做 Serving,它每次查询的数据量也是比较大的,这个时候会用列存。
通过 OceanBase 4.3 版本,我们可以在一套系统里面既实现数仓的大查询又实现 Serving,并且给用户提供更好的实时能力,兼容 MySQL,让开发者的使用更加简单。
OceanBase 的实时 AP 有一个定位,我们致力于打造 PB 以下实时分析数据库的最强六边形战士。
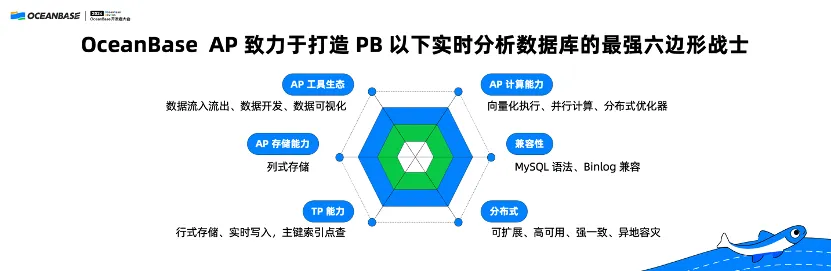
首先,它适合的场景是 1TB-1PB 之间的场景,希望的用户是有实时的需求,不完全是一个离线分析,因为离线分析可选的 AP 系统很多。OceanBase 有很强的 TP 能力,支持实时写入,通过点查直接提供 AP 的 Serving;也有很好的 MySQL 兼容性、很好的分布式能力可以提供高可用的能力;并且 OceanBase 的稳定性也非常好,基本上没有 BUG。
第二,OceanBase 有很好的实时 AP 能力,实现了列式存储和向量化,而且 OceanBase 的 ClickBench 也已经达到了世界一流水平,再加上 TPC-H 也拿到了世界第一。我相信这两种能力结合在一起,一定会让 OceanBase 成为近 PB 级实时分析数据库里面特别好的选择。
(三)What’s Next
接下来我们还要做很多的事情。Q1,也就是这次的开发者大会最主要发布 4.3 版本,主要增强对列式存储、向量化执行引擎的能力;Q2、Q3、Q4 我们会继续沿着一体化数据库的方向,提升 OceanBase 对多模、搜索、AI能力的整合和支持。

我们在 Q2 会支持全文索引、JSON 多值索引,在数据库里面加强对搜索能力的支持;在 Q3 会进一步支持 Vector 向量数据库,通过组件的方式来实现。向量数据库支持以后,开发者可以直接基于 OceanBase 开发自己的大模型应用;在 Q4 会实现基于 S3 的存算分离能力。
OceanBase 在公有云上其实已经有很多用户,大家都知道只要在公有云上肯定都是存储计算分离的,只不过今天 OceanBase 的存储计算分离是构建在公有云的云盘基础上。云盘很贵,有了基于 S3 的对象存储能力之后,我们可以大幅度提升 OceanBase 的性价比,给各位开发者省钱。
五、提升易用性
关于 OceanBase 的易用性,其实很多开发者都跟我讲 OceanBase 有两点做得比较好:
第一,.OceanBase 的产品技术能力很强,每一次开发布会OceanBase最喜欢的就是打榜,一会儿打 TPC-C、一会儿打 TPC-H、一会儿打 ClickBench、一会儿打 ClickHouse。这就有点感觉像是你有一个孩子,你一会儿让他考清华、一会儿让他考北大,还喜欢到邻居家门口嘚瑟,这就是 OceanBase 的核心技术能力。
第二,OceanBase 做得比较好的,是当一个开发者、一个 DBA 熟练掌握 OceanBase 之后,他的使用和运维效率特别高,支付宝一个 DBA 就能运维几千台服务器。功能特别强大,但前提是你首先要成为 OceanBase 的专家,所以大家可以把 OceanBase 想象为一个慢热型选手。
所以,我们花了大量精力,让 OceanBase 变得更加主动,成为一个不是那么慢热型的选手,来提升它的易用性。
接下来,让我们一起来看一段来自我们的用户和开发者,关于 OceanBase 易用性的视频。
非常感谢春雷、光明和白鳝三位开发者,既有表扬,也有批评,还有鼓励,同时三位开发者都对 OceanBase 提出了很高的期待。
其实只要谈到易用性,我脑海里经常想到以前学技术看到的书籍,比如,《从入门到精通》、《七天学会 xxx》、《21 天学会一门编程语言》等,开发者看得比较多的技术书籍都有类似的名字。所以这页 PPT 也起了个名字《OceanBase 从入门到精通》
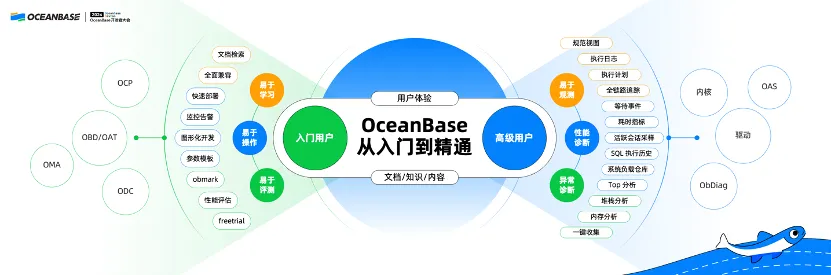
易用性主要针对两类人群:
第一类人群偏入门的用户,入门用户主要关心怎样能够快速把 OceanBase 安装部署起来,有一个很简单图形界面或者黑屏界面能够很快进行一些 benchmark 测试和基础demo等等,有文档可以查找。
另外一类用户相对比较资深一点,已经使用 OceanBase 一段时间,这类用户的所有需求可以概括为一句话——出了问题怎么办。问题很简单,但是回答这个问题很难。这里面的问题既有普通异常,比如服务器故障、网络故障、磁盘故障;也有更加深层次的问题,比如我们经常遇到卡住、抖动,但是并不知道卡住、抖动什么原因引起的。所以,有很多资深用户是比较习惯于看 OceanBase debug 日志,看看这个系统到底发生了什么。
前面三位开发者视频里面,大家可以看到 OceanBase 一些最基础的白屏化功能,OCP 其实是业界做得比较好的。光明同学还说 OCP 是从业以来用过最好用的生态工具,让我倍受鼓舞,回去可以给 OCP 团队加鸡腿。
也有一些做得不好的点——快速入门。很多新同学刚接触 OceanBase 的时候,不知道哪里找文档,安装部署起来也会遇到一些挑战。再加上一些特别深层次问题的诊断,尤其是抖动、卡住这样一些性能问题的诊断,缺少一些有效的工具,整体的 debug 日志相对 Oracle 来讲易用性、可观测性偏弱。
其实我们去年花了大量精力去做改进,当然可能还不一定能完全满足今天开发者的预期。
(一)易学习:降低上手门槛
首先,我们花了大量的精力去降低上手门槛。

第一件事情,安装部署。
前面春雷在视频里提到安装部署,去年,我们已经实现通过 OBD 两分钟安装部署。而 OBD 这个工具本身的功能比较弱,OCP 这个工具本身的功能很强,但是 OCP 的安装有一些假设,它假设一定要在特定的硬件之上。所以使得这两个工具,每一个工具都没法百分之百满足开发者需求。
于是我们把 OBD 和 OCP 两个工具融合在一起,通过 OBD 做安装,安装以后能够直接把 OCP 运行起来,利用 OCP 的丰富管控能力,最终解决春雷提到安装部署的问题。
第二件事情,性能测评。
众所周知,OceanBase 的性能非常好。但是很多开发者告诉我,性能确实很好,但前提是你要先成为一个 OceanBase 专家。
所以,这次我们对 OceanBase 支持的很多场景,它涉及到的一些参数做了模板化,通过这些参数模板,能够让每一个开发者跑出一个相对来讲比较高水平的 OceanBase benchmark 性能。
第三件事情,文档。
OceanBase 文档涉及工作量比较大,我们去年干了很多苦活,2.x 版本只有 1900 多篇文档,3.x 版本 2900 多篇,4.x 版本 3900 多篇,基本上每个产品迭代至少都会新增 1000 多篇文档。
虽然我们已经做得很辛苦了,但是我们文档的改进空间还很大。未来,我也期待像白鳝老师以及其他各位开发者能够在文档方面,包括其他易用性方面给OceanBase 提更多建议。
大家都知道,OceanBase 定位——全球流行的数据库,而不是全球流行的分布式数据库。对于这样定位,怎么做好文档达到世界水准,是我们产研团队的必经之路。
除了文档之外,还有两个对于开发者特别有用功能。
一是,在线体验。我们看文档的时候除了理论学习,其实还希望有一个地方直接操作。在线体验启动一个环境,让文档里面涉及到的 OceanBase 知识进行在线体验。大会现场的展台设有文档专区,每个操作可以直接拷贝,直接在云环境里面看效果。
二是,知识库。OceanBase去年增强了知识库,有超过1000条经验总结,这些经验总结是OceanBase以及蚂蚁集团的DBA多年在客户场景里挖掘、解决问题的思路沉淀。期望对开发者有更大的用处。
(二)易诊断:提升诊断能力
其次,我们进一步提升诊断能力。

OceanBase 对于简单异常诊断能力比较好,这部分在 OCP 里面得到体现。比如,一些简单的网络故障、磁盘故障或者简单的一些合并有问题等等,OCP 都能非常好的解决。OCP 能看到,到底哪个比较慢?到底发生了什么?但是对于最深层次依赖于开发者了解原理的问题,OceanBase 还有待提升。
第一件事情——ASH:数据库性能 Perf
大家如果写过 Linux 代码,一定用过 Linux 的 perf 工具。出现问题怎么办?不知道怎么办的时候,就打开 perf 看一下到底卡在哪里。
我们去年做一个功能 ASH,ASH 可以想象为 OceanBase 数据库的性能 perf 工具,当出现任何问题都能够通过 ASH 看到底卡在哪里。这个事情看起来也没什么,但是 ASH 对于我们来讲做起来非常有挑战。
我们为了做好 ASH 这么一件事情,内部专门成立了一个性能诊断的团队,这里面有很多非常资深的 OceanBase 内核研发人员,他们花一年多时间仅仅干一件事,那就是把我们后台所有任务、锁、等待事件、进队列、出队列等时间做准确。仅仅是把这个时间模型做准确,就花了一个团队一年多时间。
第二件事情——OAS:根因分析
ASH 定位住问题出在哪里之后,我们还有一个工具叫 OAS,根据蚂蚁集团和 OceanBase 服务客户多年经验沉淀了一些规则。它根据这个问题在哪里以及这些规则,去判断出来到底什么原因引起的。所以,它是一个根因分析工具。
第三件事情——alert.log:常见系统事件
OceanBase 一个老大难问题,那就是 OceanBase 的 debug 日志,前面提到了 OceanBase debug 日志内容很多,而且有一些内容对于开发者来讲是比较冗余的。
今年,我们在开发者建议之下,提炼出来一个 alert.log,里面包含整个 OceanBase 运行过程中常见系统事件。基本上一个开发者遇到问题,80% 的情况下只需要看 alert.log 就能解决,不需要看更大的 observer.log。
(三)Serverless 按需使用,1 个月免费 Free Trial
现在只要谈到云原生就一定想到 Serverless,它相比原来的普通实例,用更细更灵活的扩展方式,可以完完全全按需使用,帮助开发者省钱。
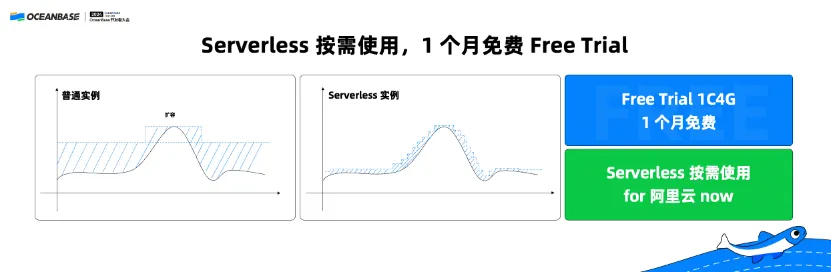
OceanBase 的 Serverless 已经在阿里云上发布,同时,我们也在阿里云、华为云提供了一个月 1C4G 的免费试用。大会现场的展区有免费试用 demo,据说免费试用太火,已经被申请完,我们现在正在申请新的额度。
六、更开放的技术生态
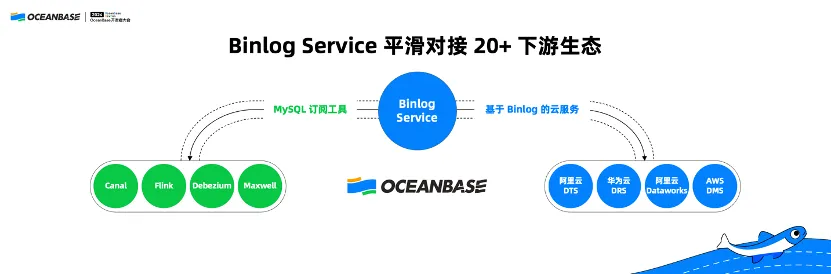
(一)Binlog Service 平滑对接 20+ 下游生态
我们去年还做了一个非常有用的功能,MySQL 兼容的 Binlog Server,成功对接超过 20 多个下游生态,包括一些 MySQL 订阅工具以及基于 Binlog 云服务。
这里也想给大家分享一个事情。我们 OceanBase 产研团队每年底都会颁发一个“产研突破大奖”,这是我们产研团队的最高奖项。去年“产研突破大奖”PK到最后只剩下两个项目,一个叫列式存储,另外一个项目叫 Binlog。
最后,大家能猜到是 Binlog 得奖了。我也非常欣慰,看到我们核心产研 leader 把票投给对开发者易用性更相关的 Binlog,而没有投给核心能力提升的列式存储。这也说明我们产研团队已经深刻体会到,也许某些点的易用性问题,比仅仅提升一点性能,对开发者更加重要。
(二)OceanBase Landscape:从基础生态适配,到开放技术生态
这张图是 OceanBase 生态工具的 Landscape。
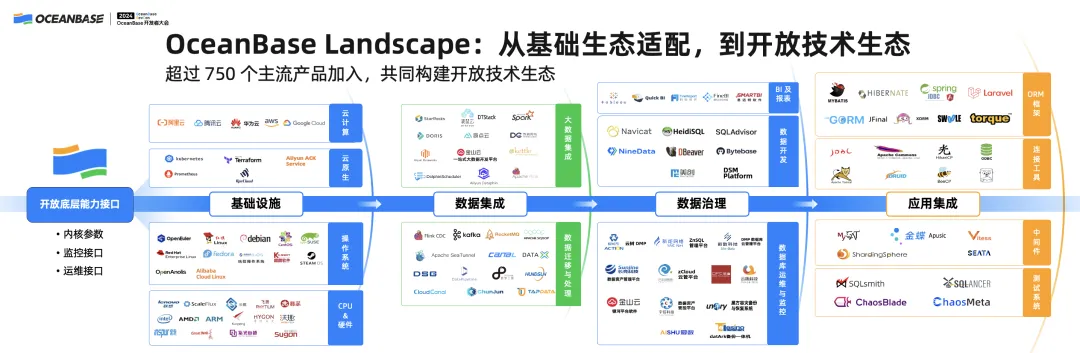
OceanBase 的生态工具主要经历了两个阶段。
第一阶段还是生态适配,既包括基于 OceanBase 内核本身周边工具生态适配,也包括OceanBase作为数据库生态跟其他一些比如 K8s 生态、大数据生态等等适配。
第二个阶段是通过开放 API 方式进行生态共建。现在已经有超过 750 个主流产品加入 OceanBase 生态,多个产品进入第二个阶段与 OceanBase 进行生态共建。
(三)基于开源持续降低开发者参与门槛
最后,简单给大家谈谈 OceanBase 的开源社区。

OceanBase 开源社区最早有一个口号,及时响应的社区,今天从及时响应升级到社区互动。
我一直有一个观点,做开源不仅仅是把一些开源的产品或者技术开放源代码或者分享出去让大家使用。更高级的一点,在于大家能够在开源社区里面基于这个产品连接你我,成为很好的朋友,这是我去年最大的体会。
去年,非常开心一点,我们用户组织 OUG 终于上了轨道。我们办了大量 OUG“城市行”活动,以及“企业行”活动,非常感谢 58、知乎、vivo 等多家企业和我们一起在开源社区里面合办“企业行”活动。
很多开发者在开源社区里面做分享,有超过 118 位开发者开通博客,超过 1000 篇技术文章。也有很多一些开源共建案例,有 6 个仓库是 OceanBase 与其他公司、其他开发者共建完成设计代码超过 5 万行。
七、致敬开发者,用有趣的尝试,连接你我
这里,特别感谢 108 位社区月度之星,因为你们的参与,社区共建使得 OceanBase 学习更加容易;特别感谢携手同行的应用开发者,因为你们的参与,生态共建让 OceanBase 更加好用;特别感谢 315 位 OceanBase contributors,因为你们的参与,使得 OceanBase 开源做得更好。

最后,再给大家分享一个来自 OceanBase 社区的小案例,也是一个开发者的尝试——构建 OceanBase 向量引擎插件,实现 SQL + AI 一体化。
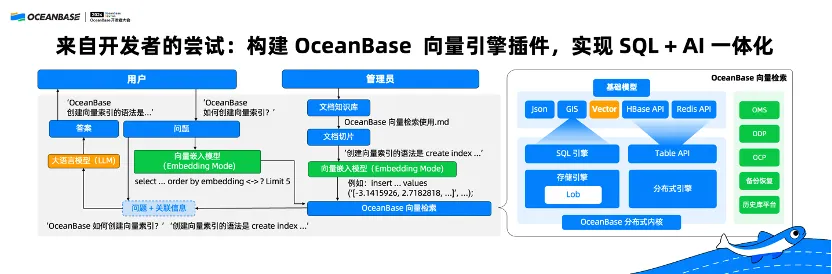
大家都知道,OceanBase 虽然目前还不支持向量数据库。但在我们社区有一个开发者,他大概花了几个月时间,干了一件事情。基于 OceanBase 的开源代码自己写了一个向量引擎插件,并且基于他自己写的向量引擎插件构建个人知识库,这个知识库支持自然语言检索。
这个案例特别好,我也特别喜欢这样有创意的案例,希望未来 OceanBase 社区有越来越多像这样有趣的尝试。我们的开源社区不仅仅是冷冰冰的产品,更是一个连接你我,让大家交朋友,好玩的地方。
以上就是我今天的分享,我们 2024 年年度发布会见。