1删除二叉搜索树中的节点
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
一般来说,删除节点可分为两个步骤:
- 首先找到需要删除的节点;
- 如果找到了,删除它。
示例 1:
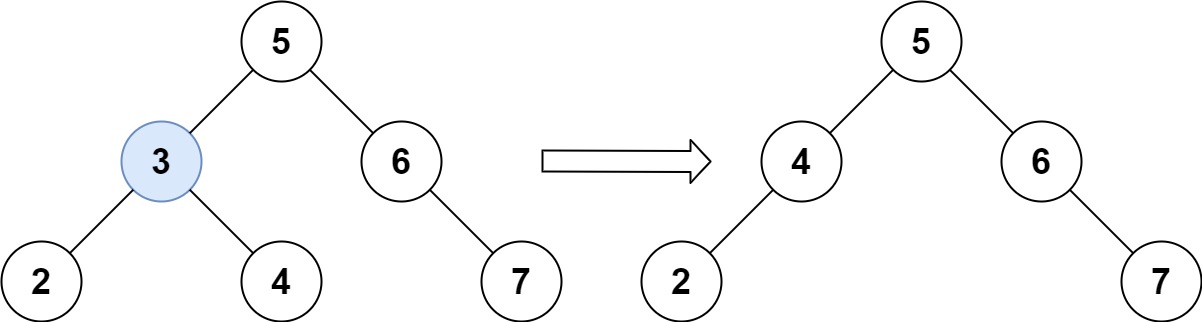
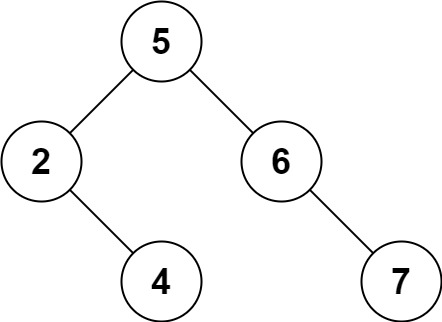
输入:root = [5,3,6,2,4,null,7], key = 3 输出:[5,4,6,2,null,null,7] 解释:给定需要删除的节点值是 3,所以我们首先找到 3 这个节点,然后删除它。 一个正确的答案是 [5,4,6,2,null,null,7], 如下图所示。 另一个正确答案是 [5,2,6,null,4,null,7]。
示例 2:
输入: root = [5,3,6,2,4,null,7], key = 0 输出: [5,3,6,2,4,null,7] 解释: 二叉树不包含值为 0 的节点
示例 3:
输入: root = [], key = 0 输出: []
提示:
- 节点数的范围
[0, 104]. -105 <= Node.val <= 105- 节点值唯一
root是合法的二叉搜索树-105 <= key <= 105
思路:
二叉搜索树中删除节点遇到的情况:
- 第一种情况:没找到删除的节点,遍历到空节点直接返回了
- 找到删除的节点
- 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
- 第三种情况:删除节点的左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点
- 第四种情况:删除节点的右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
- 第五种情况:左右孩子节点都不为空,则将删除节点的左子树头结点(左孩子)放到删除节点的右子树的最左面节点的左孩子上,返回删除节点右孩子为新的根节点。
-
确定递归函数及其参数:
- 递归函数
deleteNode接受两个参数:二叉搜索树的根节点root和要删除的节点值key。它返回删除节点后的二叉搜索树的根节点。
- 递归函数
-
定义递归终止条件:
- 如果当前节点为空,说明已经搜索到叶子节点或树为空,直接返回空指针。
- 如果当前节点的值等于要删除的值,则根据节点的情况进行删除操作,并返回相应的节点。
-
拆分问题并递归求解:
- 如果要删除的值小于当前节点的值,则在左子树中递归删除。
- 如果要删除的值大于当前节点的值,则在右子树中递归删除。
-
合并子问题的结果:
- 如果删除的是叶子节点,则直接删除并返回空指针。
- 如果删除的节点只有一个子节点,则将子节点提升为父节点。
- 如果删除的节点有两个子节点,则找到右子树中最小的节点,将其替换当前节点,并在右子树中删除这个最小节点。
-
清理和整理数据:
- 在删除节点后,需要释放被删除节点的内存空间,确保程序的正确性和内存管理。
代码:
class Solution {
public:// 定义删除节点函数,返回删除节点后的根节点TreeNode* deleteNode(TreeNode* root, int key) {// 如果根节点为空,直接返回空指针if (root == nullptr) return root;// 如果当前节点的值等于要删除的值if (root->val == key) {// 情况1:当前节点没有左右子节点,直接删除当前节点并返回空指针if (root->left == nullptr && root->right == nullptr) {delete root;return nullptr;}// 情况2:当前节点没有右子节点,将左子节点提升为新的根节点else if (root->right == nullptr) {auto retNode = root->left;delete root;return retNode;}// 情况3:当前节点没有左子节点,将右子节点提升为新的根节点else if (root->left == nullptr) {auto retNode = root->right;delete root;return retNode;}// 情况4:当前节点既有左子节点又有右子节点else {// 找到右子树中最小的节点作为替代节点TreeNode* cur = root->right;while (cur->left != nullptr) {cur = cur->left;}// 将替代节点的左子树连接到当前节点的左子树cur->left = root->left;TreeNode* temp = root;// 将当前节点替换为右子树的根节点root = root->right;delete temp; // 释放当前节点的内存return root;}}// 如果要删除的值小于当前节点的值,在左子树中继续删除if (root->val > key) root->left = deleteNode(root->left, key);// 如果要删除的值大于当前节点的值,在右子树中继续删除if (root->val < key) root->right = deleteNode(root->right, key);// 返回删除节点后的根节点return root;}
};2把二叉搜索树转换为累加树
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
- 节点的左子树仅包含键 小于 节点键的节点。
- 节点的右子树仅包含键 大于 节点键的节点。
- 左右子树也必须是二叉搜索树。
注意:本题和 1038: . - 力扣(LeetCode) 相同
示例 1:
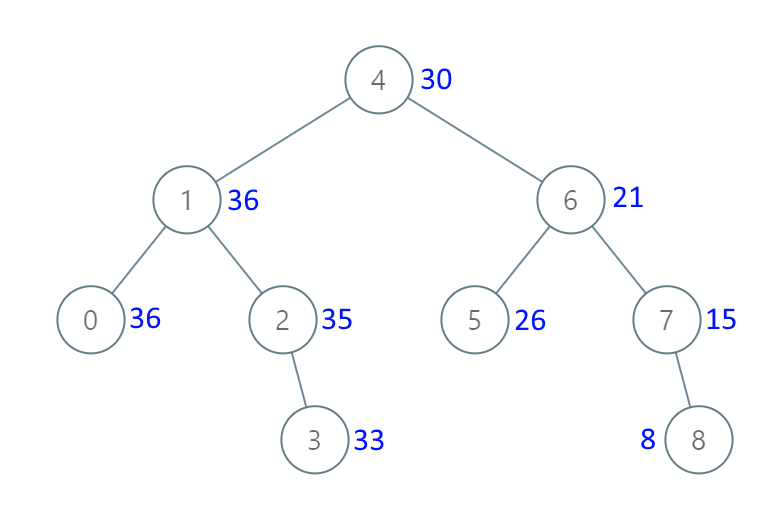
输入:[4,1,6,0,2,5,7,null,null,null,3,null,null,null,8] 输出:[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
示例 2:
输入:root = [0,null,1] 输出:[1,null,1]
示例 3:
输入:root = [1,0,2] 输出:[3,3,2]
示例 4:
输入:root = [3,2,4,1] 输出:[7,9,4,10]
提示:
- 树中的节点数介于
0和104之间。 - 每个节点的值介于
-104和104之间。 - 树中的所有值 互不相同 。
- 给定的树为二叉搜索树。
一棵二叉搜索树,二叉搜索树啊,这是有序的啊。
那么有序的元素如何求累加呢?
其实这就是一棵树,大家可能看起来有点别扭,换一个角度来看,这就是一个有序数组[2, 5, 13],求从后到前的累加数组,也就是[20, 18, 13],是不是感觉这就简单了。
为什么变成数组就是感觉简单了呢?
因为数组大家都知道怎么遍历啊,从后向前,挨个累加就完事了,这换成了二叉搜索树,看起来就别扭了一些是不是。
那么知道如何遍历这个二叉树,也就迎刃而解了,从树中可以看出累加的顺序是右中左,所以我们需要反中序遍历这个二叉树,然后顺序累加就可以了。
利用了中序遍历BST的特性,从大到小遍历节点,并将每个节点的值更新为当前节点值加上其右子树所有节点的值之和,即将每个节点的值替换为原始BST中比它大的所有节点值之和。
解题思路如下:
-
确定递归函数及其参数:
- 递归函数
convertBST接受一个参数:二叉搜索树的根节点root,并返回转换后的根节点。
- 递归函数
-
定义递归终止条件:
- 如果当前节点为空,直接返回。
- 递归函数中没有其他终止条件,因为需要遍历整棵树。
-
拆分问题并递归求解:
- 采用右-中-左的顺序递归遍历BST。首先遍历右子树,然后更新当前节点的值,最后遍历左子树。
-
合并子问题的结果:
- 在遍历过程中,每次更新当前节点的值为当前节点值加上前一个节点的值(即右子树节点的值之和)。
- 由于采用了中序遍历,因此在更新节点值时,已经确保了比当前节点大的所有节点的值已经被加到了当前节点。
-
清理和整理数据:
- 递归过程中不需要进行额外的数据清理或整理。
代码:
class Solution {
private:// 前一个节点的值,初始为0int pre = 0;// 定义中序遍历函数void traversal(TreeNode* cur) {// 如果当前节点为空,直接返回if (cur == nullptr) return;// 先遍历右子树traversal(cur->right);// 更新当前节点的值为当前节点值加上前一个节点的值cur->val += pre;// 更新前一个节点的值为当前节点值pre = cur->val;// 遍历左子树traversal(cur->left);}public:// 定义转换BST函数,返回转换后的根节点TreeNode* convertBST(TreeNode* root) {// 重置前一个节点值为0pre = 0;// 执行中序遍历traversal(root);// 返回根节点return root;}
};3将有序数组转换为二叉搜索树
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵
平衡
二叉搜索树。
示例 1:
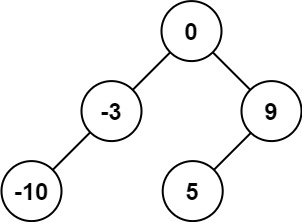
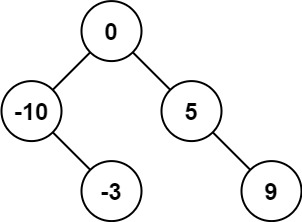
输入:nums = [-10,-3,0,5,9] 输出:[0,-3,9,-10,null,5] 解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:
示例 2:
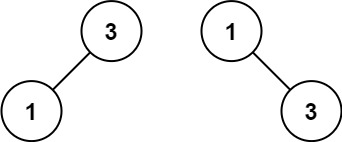
输入:nums = [1,3] 输出:[3,1] 解释:[1,null,3] 和 [3,1] 都是高度平衡二叉搜索树。
提示:
1 <= nums.length <= 104-104 <= nums[i] <= 104nums按 严格递增 顺序排列
递归思路:
-
确定递归函数及其参数: 首先确定递归函数,本例中为
traversal函数,参数包括传入的有序数组nums,以及当前子数组的左右边界left和right。 -
定义递归终止条件: 在递归函数内部,需要首先检查递归终止的条件。在这个例子中,终止条件是当左边界
left大于右边界right时,说明当前子数组为空,此时返回空指针。 -
拆分问题并递归求解: 在递归函数内部,首先确定当前子数组的中间位置
mid,然后以该位置的元素构建当前子树的根节点。接着,分别对左右子数组进行递归调用,我们递归地构建左子树和右子树,分别传入左半部分和右半部分的数组,并更新左右子节点。最终返回根节
代码:
class Solution {
private:// 定义私有函数,用于递归构建平衡二叉搜索树TreeNode* traversal(vector<int>& nums, int left, int right) {// 如果左边界大于右边界,返回空指针if (left > right) return nullptr;// 计算中间位置int mid = (left + right) / 2;// 创建根节点TreeNode* root = new TreeNode(nums[mid]);// 递归构建左子树root->left = traversal(nums, left, mid - 1);// 递归构建右子树root->right = traversal(nums, mid + 1, right);// 返回根节点return root;}public:// 定义公有函数,将有序数组转换为平衡二叉搜索树TreeNode* sortedArrayToBST(vector<int>& nums) {// 调用递归函数构建平衡二叉搜索树TreeNode* root = traversal(nums, 0, nums.size() - 1);// 返回根节点return root;}
};4银行账户概要 II
表: Users
+--------------+---------+ | Column Name | Type | +--------------+---------+ | account | int | | name | varchar | +--------------+---------+ account 是该表的主键(具有唯一值的列)。 该表的每一行都包含银行中每个用户的帐号。 表中不会有两个用户具有相同的名称。
表: Transactions
+---------------+---------+ | Column Name | Type | +---------------+---------+ | trans_id | int | | account | int | | amount | int | | transacted_on | date | +---------------+---------+ trans_id 是该表主键(具有唯一值的列)。 该表的每一行包含了所有账户的交易改变情况。 如果用户收到了钱, 那么金额是正的; 如果用户转了钱, 那么金额是负的。 所有账户的起始余额为 0。
编写解决方案, 报告余额高于 10000 的所有用户的名字和余额. 账户的余额等于包含该账户的所有交易的总和。
返回结果表单 无顺序要求 。
查询结果格式如下例所示。
示例 1:
输入: Userstable: +------------+--------------+ | account | name | +------------+--------------+ | 900001 | Alice | | 900002 | Bob | | 900003 | Charlie | +------------+--------------+Transactionstable: +------------+------------+------------+---------------+ | trans_id | account | amount | transacted_on | +------------+------------+------------+---------------+ | 1 | 900001 | 7000 | 2020-08-01 | | 2 | 900001 | 7000 | 2020-09-01 | | 3 | 900001 | -3000 | 2020-09-02 | | 4 | 900002 | 1000 | 2020-09-12 | | 5 | 900003 | 6000 | 2020-08-07 | | 6 | 900003 | 6000 | 2020-09-07 | | 7 | 900003 | -4000 | 2020-09-11 | +------------+------------+------------+---------------+ 输出: +------------+------------+ |name|balance| +------------+------------+ | Alice | 11000 | +------------+------------+ 解释: Alice 的余额为(7000 + 7000 - 3000) = 11000. Bob 的余额为1000. Charlie 的余额为(6000 + 6000 - 4000) = 8000.
代码:
select name,sum(Transactions.amount)as balancefrom Users left join Transactions on Users.account=Transactions.accountgroup by Transactions.account having sum(Transactions.amount)>10000