文章目录
- 二叉搜索树的概念
- 二叉搜索树的操作
- 二叉搜索树的查找find
- 二叉搜索树的模拟实现
- 构造节点
- insert
- find
- erase(细节巨多,面试可能会考)
- a.叶子节点
- b.有一个孩子
- 左孩子
- 右孩子
- c.有两个孩子
- 注意:
- erase代码
- 中序遍历
- 二叉搜索树的应用
- k模型
- k模型模拟实现的总代码
- k-value模型
- k-value模型模拟实现的总代码
- 二叉搜索树的不足
- AVL树和红黑树的出现
- 总结
二叉搜索树的概念
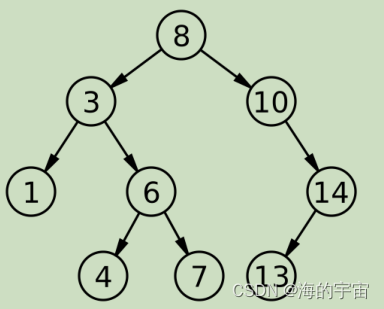
二叉搜索树,它的左子树的值比根的值小,右子树的值比根的值大
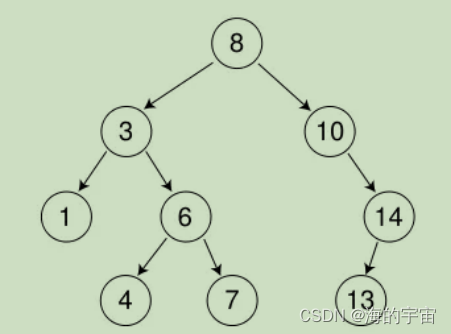
比如这一树,根节点的值8比左子树所有节点都大,比右子树的所有节点都小.
二叉搜索树的操作
二叉搜索树的查找find
因为二叉树有以上特性,所有使得它在搜索方面有极大的优势.
比如我们要找值为7的节点在不在
1.我们从根节点开始找,因为7<根节点的值8,所有根节点在左子树
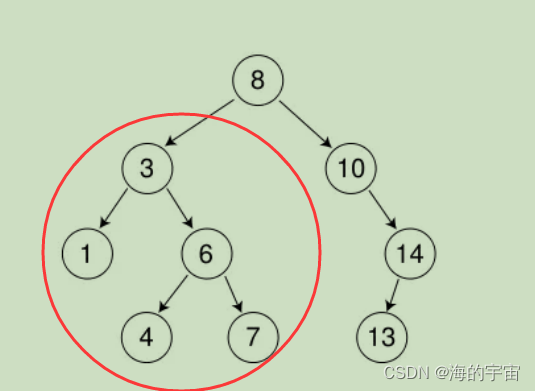
2.现在根节点的值为3<7,所有在3的右子树中
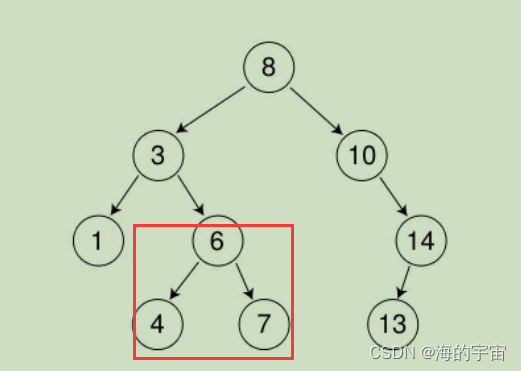
3.现在根节点的值为6<7,所有在6的右子树中,刚好右子树的节点为7.
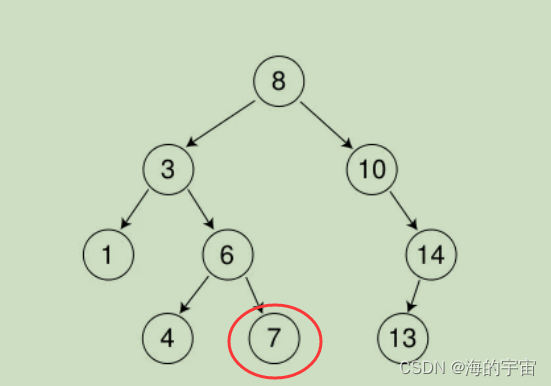
二叉搜索树最多寻找高度次,如果走到空还没有找到,说明这个值不存在
二叉搜索树的模拟实现
构造节点
template<class K>struct BSTreeNode{typedef BSTreeNode<K> Node;Node* _left;Node* _right;K _val;BSTreeNode(const K& val):_left(nullptr), _right(nullptr), _val(val){}};
_val里面存节点的值
insert
bool insert(const K& val)
{//a.树为空,直接构造新节点赋值给根节点if (_root == nullptr){_root = new Node(val);return true;}Node* parent = nullptr;Node* cur = _root;//找到空的节点进行插入while (cur){if (cur->_val < val){parent = cur;cur = cur->_right;}else if (cur->_val > val){parent = cur;cur = cur->_left;}// 二叉搜索树默认不允许重复else{return false;}}cur = new Node(val);if (parent->_val < val){parent->_right = cur;}else{parent->_left = cur;}return true;
}
插入有两种情况
a.树为空,直接构造新节点赋值给根节点
b.树不为空,按照二叉树的性质找到应该插入的空位置插入.
注意:
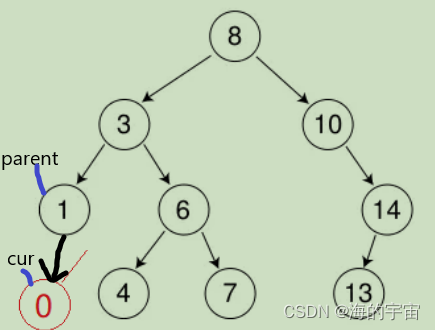
在b情况下,要找到新节点的位置,也要找到该节点的父亲节点,这样才能进行链接
假设要插入0节点,不光要找到0节点应该放的位置,还要找到0节点的父亲1,将他们链接起来
find
bool find(const K& val)
{Node* cur = _root;while (cur){if (cur->_val < val){cur = cur->_right;}else if (cur->_val > val){cur = cur->_left;}else{return true;}}return false;
}
按照二叉搜索树的概念,比根大的往右走,比根小的往左走.
找到返回true,找不到返回false
erase(细节巨多,面试可能会考)
erase里面的细节很多,要细品.
删除的节点有多种可能
a.叶子节点
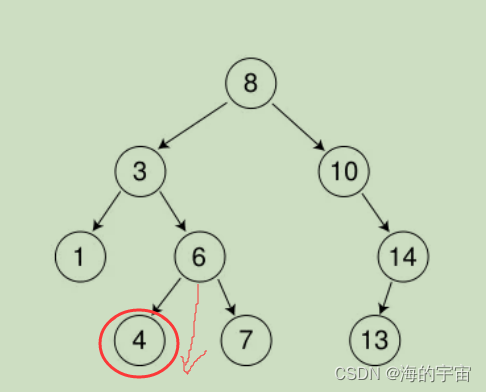
比如这棵树我们要删除4节点,就只需要找到4节点和它的父亲节点6,让父亲节点6指向空,再删除4节点.
b.有一个孩子
特殊情况
要删除的是根节点,此时要更新新的根节点10.
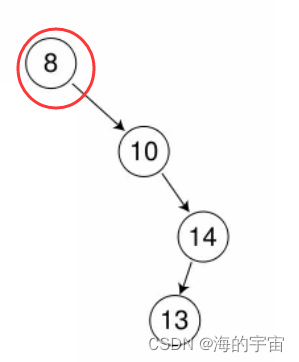
if (_root == cur)
{_root = cur->_right;delete cur;
}
左孩子
右为空,父亲指向我的左
有一个左孩子,说明右子树为空.
此时要让父亲指向3的左边,此时不清楚是父亲的左边还是父亲的右边指向1节点
父亲的左指向我的左
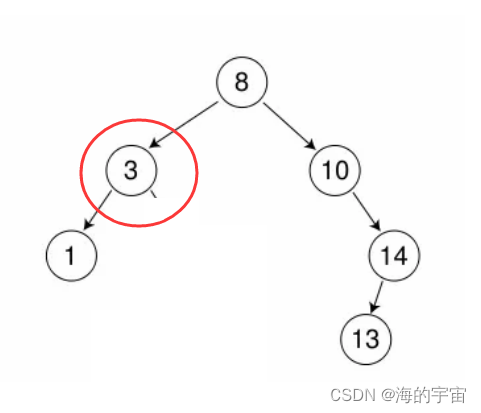
父亲的右指向我的左
代码实现
if (cur->_right == nullptr)
{//删除头节点if (_root == cur){_root = cur->_left;delete cur;}else{if (parent->_right == cur)parent->_right = cur->_left;elseparent->_left = cur->_left;delete cur;}
}
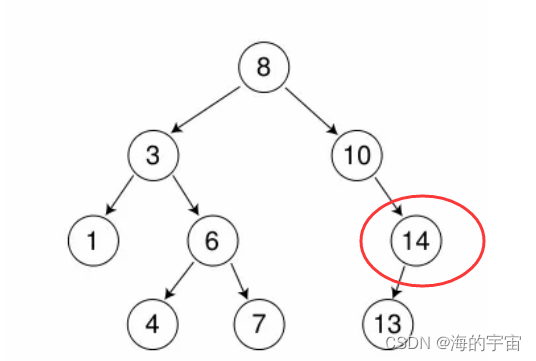
右孩子
左为空, 父亲指向我的右
//左为空, 父亲指向我的右
else if (cur->_left == nullptr)
{//删除头节点if (_root == cur){_root = cur->_right;delete cur;}else{if (parent->_right == cur)parent->_right = cur->_right;elseparent->_left = cur->_right;delete cur;}
}
右孩子的判断和左孩子类似,方向反过来而已.
c.有两个孩子
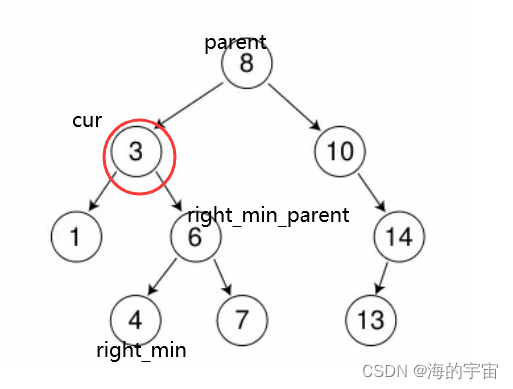
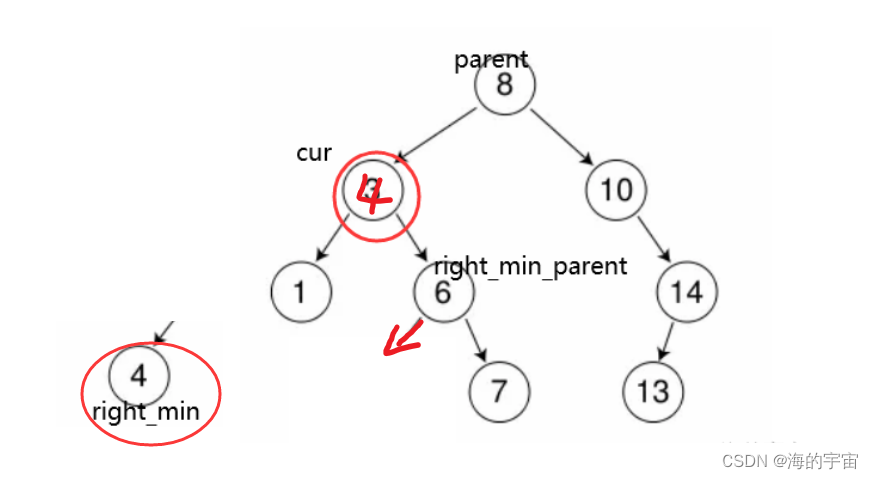
找到左边的最大值或者右边的最小值,与目标值进行替换.
这里以右边的最小值为例.
我们寻找右边的最小值时,同时要找它的父亲节点,因为要对它的父亲节点进行修改.
找到右边的最小值为4,将4覆盖到cur上面,再删除right_min这个节点.
注意:
因为是寻找右子树的最小值,所以这个最小值理论上应该没有左子树.
如果有左子树,说明有更小的值.但是可能会有右子树.
所有要让right_min_parent左节点指向right_min的右节点.
这只是理论上,实际里面还有一个大坑
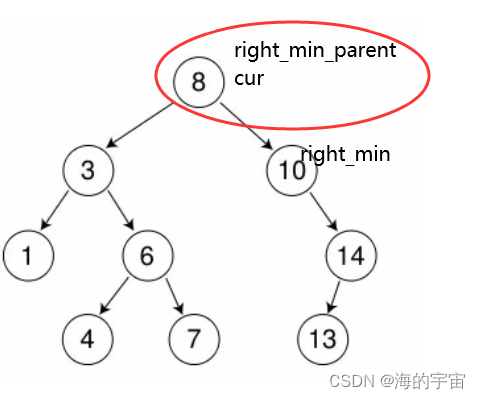
如果我们要删除的节点:cur和right_min_parent 指向同一个地方时,此时应该让right_min_parent 的右节点指向right_min的右节点.
//有两个孩子:找到左边的最大值或者右边的最小值,与目标值进行替换//让这个右最小节点的父亲的左边指向右最小的右边,因为它此时最多只有右孩子
else
{Node* right_min_parent = cur;Node* right_min = cur->_right;while (right_min->_left){right_min_parent = right_min;right_min = right_min->_left;}cur->_val = right_min->_val;//右最小节点,有坑,是连续存放的有序值if (cur->_right == right_min)right_min_parent->_right = right_min->_right;elseright_min_parent->_left = right_min->_right;delete right_min;
}erase代码
bool erase(const K& val){Node* parent = _root;Node* cur = _root;//找到要删除的目标值while (cur){if (cur->_val < val){parent = cur;cur = cur->_right;}else if (cur->_val > val){parent = cur;cur = cur->_left;}else{//只有一个孩子/叶子节点:让父亲节点指向子节点的右(nullptr)//右为空,父亲指向我的左if (cur->_right == nullptr){//删除头节点if (_root == cur){_root = cur->_left;delete cur;}else{if (parent->_right == cur)parent->_right = cur->_left;elseparent->_left = cur->_left;delete cur;}}//左为空, 父亲指向我的右else if (cur->_left == nullptr){//删除头节点if (_root == cur){_root = cur->_right;delete cur;}else{if (parent->_right == cur)parent->_right = cur->_right;elseparent->_left = cur->_right;delete cur;}}//有两个孩子:找到左边的最大值或者右边的最小值,与目标值进行替换//让这个右最小节点的父亲的左边指向右最小的右边,因为它此时最多只有右孩子else{Node* right_min_parent = cur;Node* right_min = cur->_right;while (right_min->_left){right_min_parent = right_min;right_min = right_min->_left;}cur->_val = right_min->_val;//右最小节点,有坑,是连续存放的有序值if (cur->_right == right_min)right_min_parent->_right = right_min->_right;elseright_min_parent->_left = right_min->_right;delete right_min;}return true;}}return false;}
中序遍历
void MidOrder(){_MidOrder(_root);cout << endl;}private:void _MidOrder(const Node* root){if (root == nullptr){return;}_MidOrder(root->_left);std::cout << root->_val << " ";_MidOrder(root->_right);}
首先,中序的搜索方式是左子树 根 右子树.按照这个顺序就能有序的取出搜索二叉树里面的值了
为什么会有两个函数?
因为函数的形参没有this指针,没法调用_root根节点,我们需要另外一个函数来传_root根节点
二叉搜索树的应用
k模型
k模型跟我们上面实现的一样,只存储一个值
比如:我们可以用这个功能查找到我们英文作文里面的拼写错误的单词.
我们可以把词库里面所有的英语单词丢进这个二叉搜索树,再遍历整个作文,检查每个单词是否存在,不存在就报错.
k模型模拟实现的总代码
namespace shh1
{template<class K>struct BSTreeNode{typedef BSTreeNode<K> Node;Node* _left;Node* _right;K _val;BSTreeNode(const K& val):_left(nullptr), _right(nullptr), _val(val){}};//k模型template<class K>class BSTree{typedef BSTreeNode<K> Node;public:bool insert(const K& val){if (_root == nullptr){_root = new Node(val);return true;}Node* parent = nullptr;Node* cur = _root;//找到空的节点进行插入while (cur){if (cur->_val < val){parent = cur;cur = cur->_right;}else if (cur->_val > val){parent = cur;cur = cur->_left;}// 二叉搜索树默认不允许重复else{return false;}}cur = new Node(val);if (parent->_val < val){parent->_right = cur;}else{parent->_left = cur;}return true;}bool erase(const K& val){Node* parent = _root;Node* cur = _root;//找到要删除的目标值while (cur){if (cur->_val < val){parent = cur;cur = cur->_right;}else if (cur->_val > val){parent = cur;cur = cur->_left;}else{//只有一个孩子/叶子节点:让父亲节点指向子节点的右(nullptr)//右为空,父亲指向我的左if (cur->_right == nullptr){//删除头节点if (_root == cur){_root = cur->_left;delete cur;}else{if (parent->_right == cur)parent->_right = cur->_left;elseparent->_left = cur->_left;delete cur;}}//左为空, 父亲指向我的右else if (cur->_left == nullptr){//删除头节点if (_root == cur){_root = cur->_right;delete cur;}else{if (parent->_right == cur)parent->_right = cur->_right;elseparent->_left = cur->_right;delete cur;}}//有两个孩子:找到左边的最大值或者右边的最小值,与目标值进行替换//让这个右最小节点的父亲的左边指向右最小的右边,因为它此时最多只有右孩子else{Node* right_min_parent = cur;Node* right_min = cur->_right;while (right_min->_left){right_min_parent = right_min;right_min = right_min->_left;}cur->_val = right_min->_val;//右最小节点,有坑,是连续存放的有序值if (cur->_right == right_min)right_min_parent->_right = right_min->_right;elseright_min_parent->_left = right_min->_right;delete right_min;}return true;}}return false;}bool find(const K& val){Node* cur = _root;while (cur){if (cur->_val < val){cur = cur->_right;}else if (cur->_val > val){cur = cur->_left;}else{return true;}}return false;}void MidOrder(){_MidOrder(_root);cout << endl;}private:void _MidOrder(const Node* root){if (root == nullptr){return;}_MidOrder(root->_left);std::cout << root->_val << " ";_MidOrder(root->_right);}private:Node* _root = nullptr;};void BST_Test1(){int a[] = { 6,5,1,4,7,2,3,8,9,11,55,68,-1 };BSTree<int> t;for (auto e : a){t.insert(e);}t.MidOrder();}void BST_Test2(){int a[] = { 8 };BSTree<int> t;for (auto e : a){t.insert(e);}t.MidOrder();for (auto e : a){t.erase(e);t.MidOrder();}}
}
k-value模型
每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。
这个在我们日常生活很常见,比如词典的翻译,我们在key里面存英语单词,value里面存相对应的中文翻译.
我们就可以通过输入英文单词得到其对应的中文翻译.
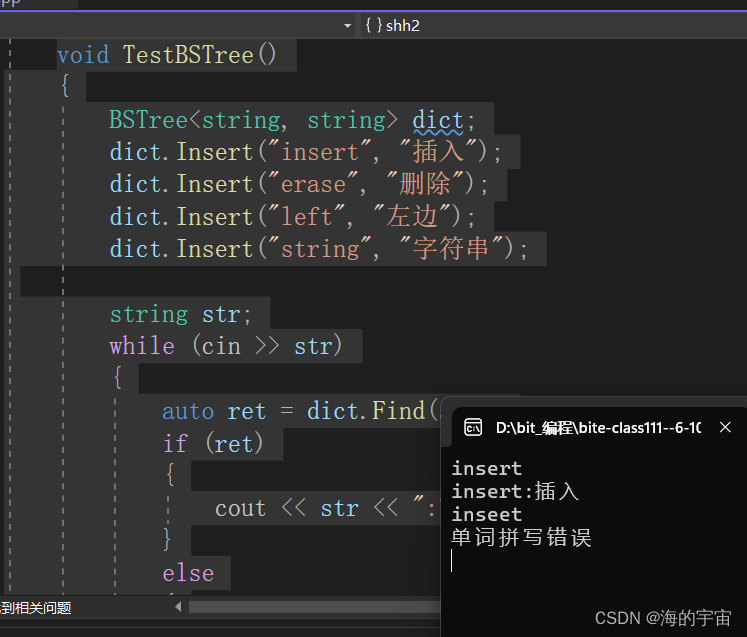
下面稍作演示:
void TestBSTree(){BSTree<string, string> dict;dict.Insert("insert", "插入");dict.Insert("erase", "删除");dict.Insert("left", "左边");dict.Insert("string", "字符串");string str;while (cin >> str){auto ret = dict.Find(str);if (ret){cout << str << ":" << ret->_val << endl;}else{cout << "单词拼写错误" << endl;}}}
k-value模型模拟实现的总代码
k-value模型的代码和上面的key模型类似,我们只需要要添加新节点的时候再加一个值就行.
namespace shh2
{template<class K, class V>struct BSTreeNode{typedef BSTreeNode<K, V> Node;Node* _left;Node* _right;K _key;V _val;BSTreeNode(const K& key, const V& val):_left(nullptr), _right(nullptr), _key(key), _val(val){}};template<class K, class V>class BSTree{typedef BSTreeNode<K, V> Node;Node* _root = nullptr;public:bool Insert(const K& key, const V& val){//头节点if (_root == nullptr){_root = new Node(key, val);return true;}Node* parent = _root;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{//已经插入过的return false;}}cur = new Node(key, val);if (parent->_key < key)parent->_right = cur;elseparent->_left = cur;return true;}Node* Find(const K& key){Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->_right;}else if (cur->_key > key){cur = cur->_left;}else{return cur;}}return nullptr;}bool Erase(const K& key){Node* parent = _root;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{//叶子节点和只有一个孩子的一起处理//左为空,父亲的左/右指向我的右if (cur->_left == nullptr){// 如果为根节点if (cur == _root){_root = cur->_right;delete cur;}else{if (cur == parent->_left){parent->_left = cur->_right;}else{parent->_right = cur->_right;}delete cur;}}//右为空,父亲的左/右指向我的左else if (cur->_right == nullptr){// 如果为根节点if (cur == _root){_root = cur->_left;delete cur;}else{if (cur == parent->_left){parent->_left = cur->_left;}else{parent->_right = cur->_left;}delete cur;}}//两个孩子 找到cur左子树的最大值替换else{Node* left_max_parent = cur;Node* left_max = cur->_left;while (left_max->_right){left_max_parent = left_max;left_max = left_max->_right;}swap(cur->_key, left_max->_key);if (left_max_parent->_left = left_max)left_max_parent->_left = left_max->_left;elseleft_max_parent->_right = left_max->_left;delete left_max;}return true;}}}void _InOrder(Node* root){if (root == nullptr){return;}_InOrder(root->_left);cout << root->_key << ":" << root->_val << endl;_InOrder(root->_right);}void InOrder(){_InOrder(_root);}};void TestBSTree(){BSTree<string, string> dict;dict.Insert("insert", "插入");dict.Insert("erase", "删除");dict.Insert("left", "左边");dict.Insert("string", "字符串");string str;while (cin >> str){auto ret = dict.Find(str);if (ret){cout << str << ":" << ret->_val << endl;}else{cout << "单词拼写错误" << endl;}}}
};
二叉搜索树的不足
当二叉搜索树有序存入了一段值
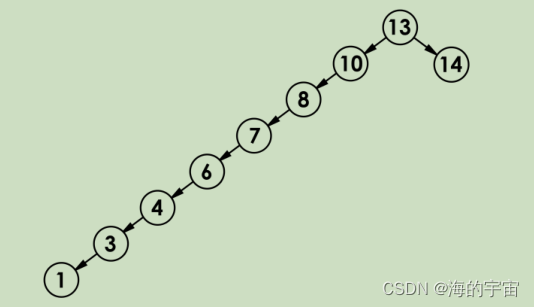
这棵树会退化成单叉树,因为插入,查找和删除的时间复杂度都是高度次,
所以在这种情况下插入,查找和删除的时间复杂度会接近于N.搜索二叉树也就失去了它的优势.
AVL树和红黑树的出现
怎么解决这个问题呢,就要用到AVL和红黑树了.
在插入的时候,AVL树会查看树的高度是否平衡,
左子树和右子树的高度差不超过1.超过1会让树的几个节点之间发生旋转,最终这棵树会变成这样.
我们平时调用的容器map和set底层就是用AVL树和红黑树生成的.
总结
二叉搜索树的插入和查找不难,但是它的删除细节很多,分类很细,一不留神容易掉坑里面,面试也经常会考.大家如果不懂的话,要多看几遍.