基础篇:Transformer
- 引言
- 模型基础架构
- 原论文架构图
- Embedding
- Postional Encoding
- Multi-Head Attention
- LayerNorm
- Encoder
- Decoder
- 其他
引言
此文作者本身对transformer有一些基础的了解,此处主要用于记录一些关于transformer模型的细节部分用于进一步理解其具体的实现机制,输入输出细节,以及一些理解.此文会不定期更新用于记录新学习到的知识.
模型基础架构
原论文架构图
首先给出的是原论文 Attention is all you need中的架构图,我们会在这个篇章部分分列模型pipeline中的各个部件。在最后给出关于这个模型图中没有的细节补充。

Embedding
其使用的是nn.embedding来进行初始化,根据词表里的数量和设置的隐层维度来初始化,可训练。(**TODO:**这里会存在词表的初始化问题,即分词方法,在后续介绍)
Postional Encoding
两种编码方式,learned PE是绝对位置编码,即直接随机初始化一个可训练的参数;Sinusoidal PE为相对位置的三角编码,首先根据位置pos和隐层维度位置i得到embedding值
f ( p o s , i ) = s i n ( p o s 1000 0 i N ) i f i 为奇数 e l s e c o s f(pos,i)=sin(\frac{pos}{10000^{\frac{i}{N}}}) \ \ \ \ if\ \ i为奇数\ \ else\ \ cos f(pos,i)=sin(10000Nipos) if i为奇数 else cos
Multi-Head Attention
单头attention 的 Q/K/V 的shape和多头attention 的每个头的Qi/Ki/Vi的大小是不一样的,假如单头attention 的 Q/K/V的参数矩阵WQ/WK/WV的shape分别是[512, 512] (此处假设encoder的输入和输出是一样的shape),那么多头attention (假设8个头)的每个头的Qi/Ki/Vi的参数矩阵WQi/WKi/WVi大小是[512, 512/8].
LayerNorm
BatchNorm本质是对同一个批次中,每一个数据样本的不同通道求均值方差,通道之间不进行交互,并通过滑动动量平均的方式将批次的均值方差记录下来用于推理。BN相对更适合在数据批次上具有统计意义的问题,其会抹平特征之间的差异,保留样本之间的大小关系。而在NLP任务当中,每个句子内部的特征大小关系才是需要保留的,不同句子之间关联不大,因此抹平样本之间的大小关系更为合适。
Encoder
Encoder一般包含两部分,self-attention和feed-forward。每一层Encoder都有独立的一组权重参数。最后一层Encoder得到的Wk,Wv用于计算Decoder的cross-attention。
Decoder
Decoder一般包含三个部分,self-attention, encoder-decoder-attention和feed-forward。在这里和这里有一些关于Decoder实际部署时的运行细节。
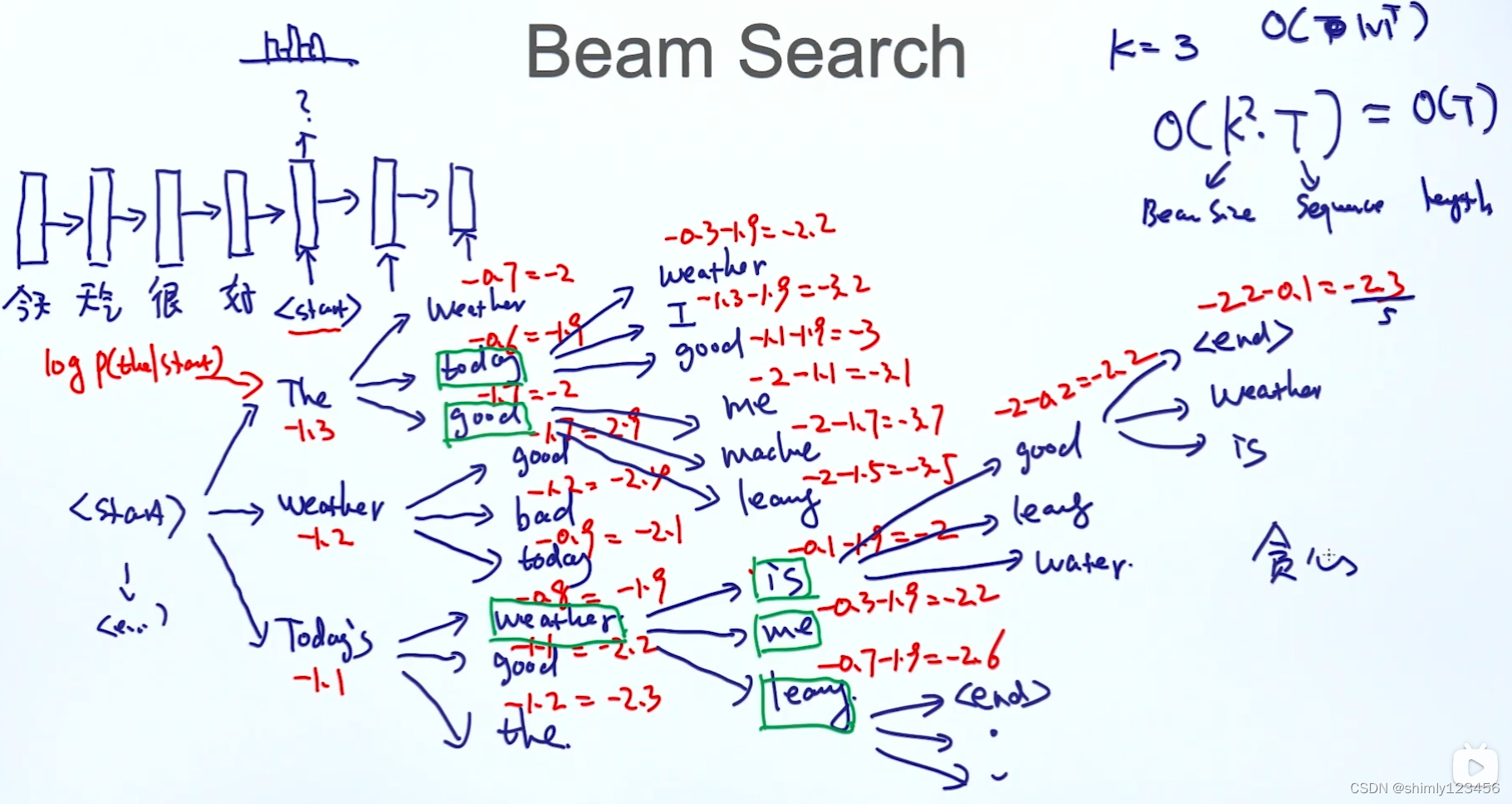
在训练的时候,Decoder通过mask得到ground truth的shift-right的下三角矩阵,对于位置t,其拥有前t-1个时刻的所有信息,之后计算矩阵得到该位置的output,该output和同位置的ground truth计算损失(即teach forcing的方法)。在推理时,通过padding一个一个输入,但只取最后一个时刻的output作为全局的预测结果,因此可能存在非对应位置最优解(即beam search)。
其他
- 编码层解码层堆栈:事实上encoder和decoder是可以进行stack的,原论文图中只展示了一层,其实际实现逻辑是下图。

- transformer只能够处理定长输入和定长输出,对于长度不定的数据,通过padding -INF等方法来进行补全,由于softmax的存在这些会约等于0。