0、前言:
- 本文意在记录自己在做毕业Flask项目开发时遇到的一些问题,并将问题解决方案记录下来,可做日后查询
- 本文也会记录自己做FLask项目时实现的一些功能,作为开发工作的进程记录
- 注意:用Flask开发的前提是已经设计好前端页面和后端数据库表的情况下,通过Flask进行前后端联合调试
1、项目路径问题:
- 问题描述:在之前写好的html模板中调用了一些css样式,之前css和html在一个文件夹中直接调用就好了,但是在flask中,需要重新放在不同文件夹中,就需要用相对路径来调用了,项目开发最好都是写相对路径,方便别人在跑你代码的时候,不论别人把你项目放在哪个地方,都可以顺畅跑起路来。如下图,在“系统首页”代码中要访问“全局样式”,就需要写路径,方式有绝对路径和相对路径两种。

- 绝对路径:C:\Users\11252\Desktop\个性化交互式在线学习系统\App\static\css\全局样式.css
- 相对路径:…/…/…/static/css/全局样式.css
- 总结:相对路径中,一层 “ …/ ” 就意味着往外面走一层,直到走到包含你要引用的文件那一层,再写路径往下找。
2、css样式失效:
- 解决方法:通过内联样式修改html代码,如下所示就是内联样式的写法。
<!-- 使用内联样式定义一个带有背景色和边框的div -->
<div style="background-color: lightblue; border: 1px solid black; padding: 10px;"> 这是一个使用内联样式定义的div,它有背景色、边框和内边距。
</div>
3、登陆页面登陆验证:
- 实现逻辑:如果视图函数收到的是从服务器向前端请求数据的request请求,也就是GET请求,那么就通过rend_template返回网页模板,如果视图函数再次收到网页发送数据的request请求,也就是POST请求,那么就可以通过request拿到网页提交过来的表单数据(这里要注意,网页提交数据的请求是通过form表单中action属性连接到视图函数的,其中method属性要设置为post,autocompete属性设置为off就避免了自动填充内容)。通过request拿到前端页面提交的数据之后,再通过数据表查询的filter_by方法去用户表中核对账号和密码即可,核对上就表示登录成功,借助response变量重定向到首页,然后把cookie保存到response中,再返回即可。
- 视图函数
# 登录页面
@blue.route('/user/login/', methods=['GET','POST'])
def user_login():if request.method == 'GET':return render_template('/user_0/登录页面.html')elif request.method == 'POST':user_account = request.form.get('user_account')user_password = request.form.get('user_password')# print(user_account,user_password)user = User.query.filter_by(user_account=user_account, user_password=user_password).first()if user:# 登录成功,将cookie保存到要返回给前端页面的响因中response = redirect('/user/index/')response.set_cookie('user_id', str(user.user_id), max_age=3*24*3600) # 设置cookie名,cookie值,cookie的有效期(秒作为单位)print(f'登录用户账号;{user.user_account}')return responseelse:return '输入户账号或密码错误!'else:return 'login failed'
- 前端代码
<form action="/user/login/" method="post" autocomplete="off"><div><img src="../../../static/img/账户.png" alt=""><input name="user_account" type="text" class="in" placeholder="请输入账号"></div><div><img src="../../../static/img/密码.png" alt=""><input name="user_password" type="password" class="in" placeholder="请输入密码"></div><div class="b1"><button type="submit">登录</button></div><div class="b2"><a href="" style="width:300px; height: 50px;font-size: 18px; color: #fff; border: none;">注册</a></div></form>
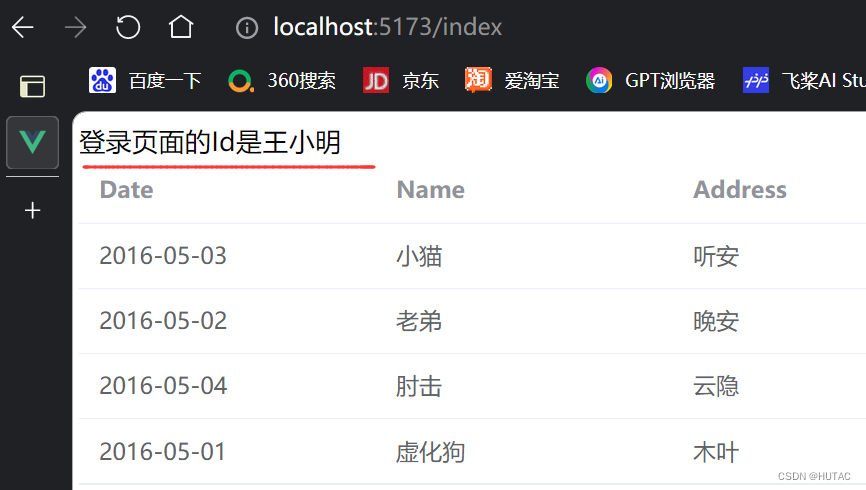
- 效果图

- 总结:如果项目中登陆其他页面需要做登录验证,那么在开发这个项目的时候,应该先做登录功能,然后在登录成功后保存登录对象的cookie,然后再做退出登录功能删除cookie,然后其他页面需要登录验证的时候,只需要获取cookie即可,如果拿到cookie就说明该用户登录成功过,但是要注意cookie的值设置时必须是用户数据表的唯一字段,后续在做完登录验证后,在视图函数中还可以通过cookie去查询对应用户在用户数据表中的信息;从逻辑上来讲,系统启动后默认路径进入的应该是登陆页面。
4、在项目编辑过程中如何发现数据库缺少字段处理方式:
- 1、在对应models文件中给对应数据表添加字段
- 2、在终端该项目路径下执行:flask db migrate;flask db upgrade
- 说明:这种修改方式会保存数据表中原有的数据的同时,给数据表添加字段
5、数据库外键查询报错问题
- 我的理解:在models文件中只要把数据库外键和外键关联关系写对,如下所示:
# models文件中的内容# 课程表
class Course(db.Model):# 表名__tablename__ = 'tb_course'# 字段course_id = db.Column(db.Integer, primary_key=True, autoincrement=True)course_name = db.Column(db.String(20), default='课程名')course_introduction = db.Column(db.Text(), default='课程介绍')# 与外键反向关联course_resources = db.relationship('Course_resources', backref='course', lazy='dynamic')# 课程资源表
class Course_resources(db.Model):# 表名__tablename__ = 'db_c_resources'# 字段video_id = db.Column(db.Integer, primary_key=True, autoincrement=True)video_name = db.Column(db.String(30), default='视频名称')show_url = db.Column(db.String(100), default='封面链接')# 外键course_id = db.Column(db.Integer, db.ForeignKey(Course.course_id))
然后在视图函数中调用即可,如下面代码中,我想通过 课程表 去查与他关联的 课程资源表 ,结果就会出现报错,
# views文件中的内容# 系统首页面
@blue.route('/user/index/')
def user_index():# 获取cookie,得到登录的用户user_id = request.cookies.get('user_id', None)if user_id:# 登陆过,查询用户信息,返回user = User.query.get(user_id)# 在课程表中查询信息course = Course.query.all()# 在资源表中查询信息(出错的地方!)print(f'{course[0].course_resources.show_url}')return render_template('/user_0/系统首页.html',user = user,hot_course = hot_course,recommend_course = recommend_course)else:return redirect('/user/login/')
报错信息如下:

通过查询后得知:course_resources是数据表中的一个关系属性,它返回的是一个AppenderQuery对象,在SQLAIchemy中,当访问一个模型关系属性时,得到的是一个查询对象而不是结果集,需要进一步从查询对象当中执行查询来获取实际的资源对象,因此可以在course[0].course_resources后面使用 .all() 或 .first() 方法来获取所有资源或第一个资源。
6、在网页通过链接跳转传参
- 本质上讲该问题就是在网页实现调用视图函数并传递参数给视图函数

7、在jinja2模板语言中如何调用一个自增长的变量
- 在jinja2的for循环当中有一个属性就是index,它会随着循环每次都增加1。

8、如何导出一个项目的python环境,方便他人复现你的项目
-
1、在项目中导出第三方库:pip freeze > requirements.txt ,通过这个代码就能生成一个requirements.txt文件。
-
2、最后把requirements文件分享给别人,别人通过pip install -r requirements.txt 可以快速安装项目环境。
9、★★★★★如何将训练好的机器学习或者深度学习模型嵌入Flask项目中实现调用。
9.1、模型部分调试记录
- 1、首先把模型跑通,该模型是一个二分类模型,主要用于通过32个用户行为特征来预测用户学习风格属于二分类当中的哪一个。
# 1、构造模型
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.callbacks import LearningRateSchedulermodel = Sequential([Embedding(input_dim=900, output_dim=64, input_length=32),LSTM(units=128, return_sequences=True),LSTM(units=64),Dense(units=2, activation='softmax')
])def lr_schedule(epoch):initial_lr = 0.001 # 初始学习率decay_factor = 0.5 # 学习率衰减因子decay_epochs = 5 # 学习率衰减的周期数new_lr = initial_lr * (decay_factor ** (epoch // decay_epochs))return new_lr# 定义学习率回调
lr_scheduler = LearningRateScheduler(lr_schedule)
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 打印模型概况
model.summary()

-
2、通过数据预处理,把需要训练的数据第1类和第2类都划分为7:1.5:1.5,其中7成是训练数据,1.5成分别是测试数据和验证数据,然后再将这两部分7成部分打乱,1.5部分打乱,然后拼接在一起。最终保证总体训练集占比为7成,总体测试集和验证集占比分别是1.5成。

-
3、导入预处好的数据,划分好训练集、预测集、验证集
train_data = data.iloc[0:631,1:34]
val_data = data.iloc[631:768,1:34]
test_data = data.iloc[768:900,1:34]# 划分数据集
X_train = train_data.iloc[:,0:32]
y_train = train_data.iloc[:,32]-1 # 后面进行one-hot
X_val = val_data.iloc[:,0:32]
y_val= val_data.iloc[:,32]-1 # 后面进行one-hot
X_test = test_data.iloc[:,0:32]
y_test = test_data.iloc[:,32]-1 # 后面进行one-hot
- 4、数据训练
# 假设你已经准备好了 train_data 和 train_labels 数据# 进行标签的 one-hot 编码
from tensorflow.keras.utils import to_categorical
y_train_encoded = to_categorical(y_train, num_classes=2)
y_val_encoded = to_categorical(y_val, num_classes=2)
# 训练模型
batch_size = 12
epochs = 100history = model.fit(X_train, y_train_encoded, batch_size=batch_size, epochs=epochs, validation_data=(X_val, y_val_encoded), callbacks=[lr_scheduler])
# history = model.fit(train_data, y_train_encoded, batch_size=batch_size, epochs=epochs, callbacks=[lr_scheduler])
# 注意:代码中的 history 中会保存训练过程的数据,后面要生成准确率变化图,损失率变化图,都得通过 history 获取。
- 5、生成分类报告:查看模型分类能力如何
# 生成分类报告
from sklearn.metrics import classification_reporty_test_one_hot = to_categorical(y_test, num_classes=2)
# 在测试数据上进行预测
y_pred = model.predict(X_test)# 将模型的预测结果转换为类别标签
y_pred_labels = tf.argmax(y_pred, axis=1)
y_test_labels = tf.argmax(y_test_one_hot, axis=1) # tf.argmax 来计算 y_pred 中每行的最大值所在的列索引# 生成分类报告
report = classification_report(y_test_labels, y_pred_labels)
print(report)

- 6、保存模型:在这里遇到过保存路径直接写相对路径,就会报错的问题,最后通过导入os模块,解决了这个问题。
# 保存模型
import os# 定义保存路径,确保路径存在
save_dir = './save_model'
if not os.path.exists(save_dir):os.makedirs(save_dir)# 使用绝对路径,保存为 .keras 文件
model_save_path = os.path.abspath(os.path.join(save_dir, 'shijian_model.keras'))# 保存模型
model.save(model_save_path)
- 7、★加载模型
# 加载模型
loaded_model = tf.keras.models.load_model(model_save_path)
# 生成满足模型要求的数据(一组32列的二维数据,数据内容是从0-899随机的整数)
new_data = np.random.randint(900, size=[1,32])
# 用加载模型测试
result = loaded_model.predict(new_data)
print(result) # [[0.15184742 0.8481526 ]]
# 判断并生成最终结果
# 判断最后的值
if result[0][0] > result[0][1]:print('类型1')
else:print('类型2')
# 类型2
- 补充:最后得到的模型可以用来做预测、可以用带标签的数据来评估模型、还可以继续输入训练数据来训练模型,训练好之后,还可以保存模型进入下一个迭代循环周期。
# 1、进行预测的代码示例
predictions = loaded_model.predict(new_data)# 2、进行评估的代码示例
# 示例测试数据和标签
test_data = np.random.randint(900, size=(20, 32)) # 20个测试样本,每个样本长度为32
test_labels = np.random.randint(2, size=(20, 2)) # 20个测试样本对应的标签,假设是one-hot编码
# 评估模型
loss, accuracy = loaded_model.evaluate(test_data, test_labels)
# 打印评估结果
print(f'Loss: {loss}, Accuracy: {accuracy}')# 3、用保存的代码继续训练的方法
import tensorflow as tf
import numpy as np
# 假设你有训练数据和标签
train_data = np.random.random((100, 32)) # 示例训练数据,假设形状为 (100, 32)
train_labels = np.random.randint(2, size=(100, 2)) # 示例训练标签,假设形状为 (100, 2)
# 加载已保存的模型
loaded_model = tf.keras.models.load_model('my_model.h5')
# 编译模型(如果需要)
loaded_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 继续训练模型
loaded_model.fit(train_data, train_labels, epochs=5)
9.2、项目中导入模型部分调试记录
- 1、首先项目当中要调用模型的话,环境配置当中要有tensorflow库,而且一定要注意,通过下面代码查看下你训练模型时用到的tensorflow版本
import tensorflow as tf
print(tf.__version__)
我刚开始没有注意到这一点,就直接通过pycharm终端通过:pip install tensorflow ,给项目安装了一个tensorflow,结果,我安装的这个tensorflow是2.16.1的版本,然后,在视图函数中调用模型的时候,老是报错,我检查了我写的路径没有问题,折磨了我一下午,查看了我训练模型的tensorflow版本是2.14.0的,当我通过:pip uninstall tensorflow 从项目中卸载了2.16.1的版本,然后通过:pip install tensorflow==2.14.0 下载了与训练模型一致的版本后,问题迎刃而解。
- 2、以下是对应的视图函数:
# 学习风格分类任务(写在这里可以作为参考,这个视图函数并不会被调用,这个功能写在了用户页面视图函数当中)
@blue.route('/user/classify/<int:user_id>')
def classify_model(user_id):print(tf.__version__)# 通过id获取到用户行为列表user = User.query.get(user_id)user_action = User_action.query.get(user_id)# 将用户行为列表转换为列表,作为学习风格分类模型的输入user_ac_list = []for i in range(32):ac = str(f'act{i+1}')# 如果直接写user_action.ac,程序不能把ac识别为上面的ac,因此要用到getattr函数,它可以基于字符串变量访问对象属性ac_value = getattr(user_action, ac)user_ac_list.append(ac_value)# print(user_ac_list)# 将输入数据格式调整为可以被模型识别的二维数据ac_array = np.array(user_ac_list)ac_array = ac_array.reshape((1,32))# 获取当前文件所在的目录base_dir = os.path.dirname(os.path.abspath(__file__))# 拼接模型文件的相对路径shijianmodel_save_path = os.path.join(base_dir, 'static', 'project_model', 'shijian_model.keras')jihuamodel_save_path = os.path.join(base_dir, 'static', 'project_model', 'jihua_model.keras')luojimodel_save_path = os.path.join(base_dir, 'static', 'project_model', 'luoji_model.keras')ganguanmodel_save_path = os.path.join(base_dir, 'static', 'project_model', 'ganguan_model.keras')# 加载保存的模型shijian_model = load_model(shijianmodel_save_path)jihua_model = load_model(jihuamodel_save_path)luoji_model = load_model(luojimodel_save_path)ganguan_model = load_model(ganguanmodel_save_path)# 通过模型结果判断学习风格shijian_result = shijian_model.predict(ac_array)jihua_result = jihua_model.predict(ac_array)luoji_result = luoji_model.predict(ac_array)ganguan_result = ganguan_model.predict(ac_array)print(shijian_result)user_style = ""if shijian_result[0][0] > shijian_result[0][1]:user_style += 'I' # 主动型else:user_style += 'R' # 反应型 if jihua_result[0][0] > jihua_result[0][1]:user_style += 'D' # 细节型else:user_style += 'O' # 全局型if luoji_result[0][0] > luoji_result[0][1]:user_style += 'R' # 理性型else:user_style += 'P' # 感性型if ganguan_result[0][0] > ganguan_result[0][1]:user_style += 'V' # 视觉型else:user_style += 'H' # 听觉型# 将结果存放到用户数据表user.user_style = user_styletry:db.session.commit()except Exception as e:print(e)db.session.rollback()return redirect('/user/home/')
把模型嵌入到项目中的思路就是,在静态文件夹中新建一个project_model来存放训练好保存起来的模型,然后下载模型对应的第三方库,之后,按照正确路径加载模型,构建符合模型输入要求的输入数据,然后通过模型预测结果即可,从上面视图函数中看出,最后我还把模型预测结果通过修改数据表的方式,存放到了用户数据表当中。