关于YOLOv8的主干网络在YOLOv8网络结构介绍-CSDN博客介绍了,为了更好地学习本章内容,建议先去看预测流程的原理分析YOLOv8原理解析[目标检测理论篇]-CSDN博客,再次把YOLOv8网络结构图放在这里,方便随时查看。

1.前言
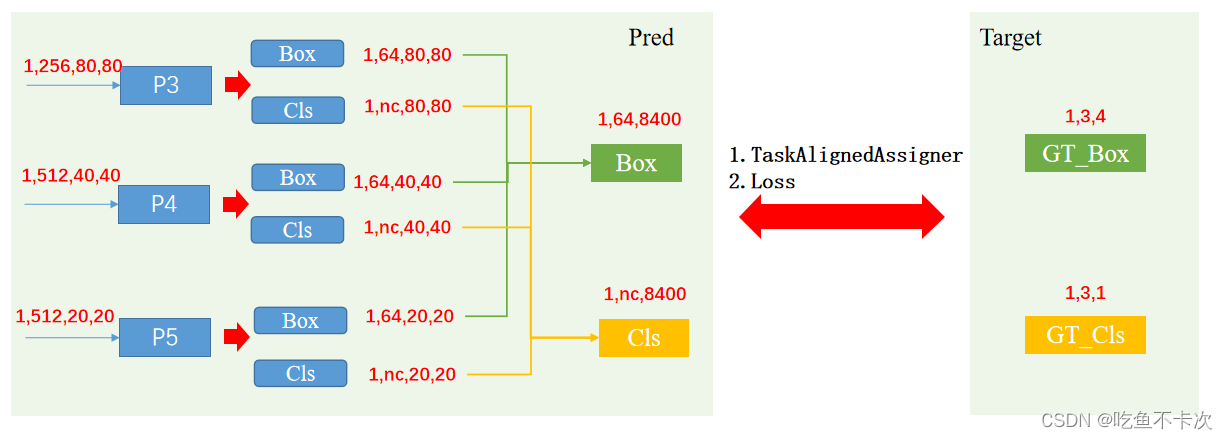
YOLOv8训练流程这一块内容还是比较复杂的,所以先来谈一下训练流程的思路,一共就两步:第一步就是从网络预测的结果中找到正样本,并且确定正样本要预测的对象;第二步就是计算预测结果和标签之间的损失,分别计算预测框的损失以及预测类别的损失。
如下图所示,假设一张图片中只有3个标签,那么需要从8400个Grid cell中找到这3个标签对应的正样本,然后通过计算正样本的预测值和标签值之间的损失,最后通过损失的反向传播更新模型的权值和偏差。
为了更好地理解YOLOv8或者说是YOLO系列网络,需要对Grid cell建立概念,如下所示:
首先可以看到通过网络输出的三个特征图的分辨率分别为:80*80,40*40,20*20,本文所说的Grid cell即为图中的红点、蓝点以及黄点,从图中可以得到以下信息:第一,红点代表的Grid cell是80*80分辨率中每个像素的中心点,因为红色Grid cell比较密集并且可以x8将红点映射回原图,所以80*80分辨率的特征图Grid cell是用来训练小目标的,蓝色和黄色Grid cell同理;第二,如果8400个Grid cell全部当成正样本的话是不实际的,所以必须从这8400个Grid cell中选出一些正样本;第三,由于YOLOv8是Anchor Free的模型,所以会将这三个尺度的特征图展开变成长度为8400的一维向量。

2. Task Aligned Assigner
Task Aligned Assigner中文翻译为任务对齐分配器,是一种正负样本分配策略,也就是找正样本的方法,也就是训练流程中的第一步。
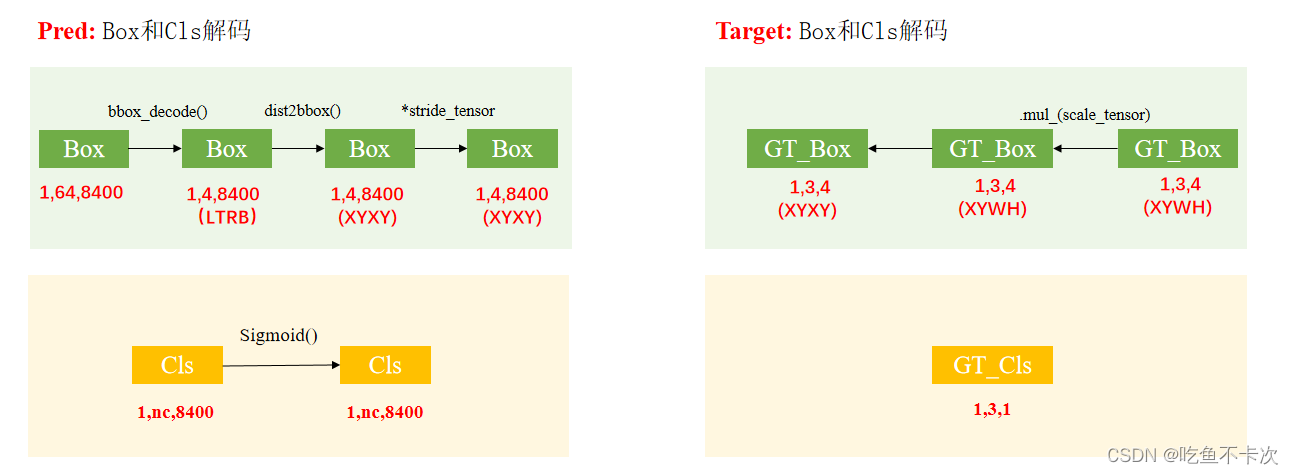
在正式开始找正样本之前,需要先把网络预测值Box和Cls解码,同时也需要把标签的Box和Cls解码,过程如下图所示:首先是网络预测结果Pred的Box需要解码成4维,用来预测LTRB的(解码过程在预测原理第三章有提到YOLOv8预测流程-原理解析[目标检测理论篇]-CSDN博客),另外还需要转换为XYXY格式且预测的坐标值是相对于网络输入尺寸的(即640*640);Cls只需要使用Sigmoid()解码就行。其次是标签Target的解码,其实只有Box需要解码,为了和Pred的解码格式保持一致,需要将XYWH格式转换为XYXY,并且标签值对应的坐标是相对于网络输入尺寸(即640*640)。
然后正式开始找正样本了,假设一张图片上只有一个GT Box,使用红色框作为标记。由于已经将三个特征图下的grid cell都转换到640*640坐标系了,结合GT框的位置和大小,找到合适的中心点作为训练的正样本,这就是TaskAlignedAssigner的任务,一共分成三步,即初步筛选,精细筛选,剔除多余三个步骤。
(1)初步筛选:即select_candidates_in_gts,转换之后的Grid Cell落在GT Box内部,作为初步筛选的正样本,如图中所示红色点为初步筛选的Grid Cell,而落在GT Box外部的点或者落在GT Box角上或者边上的都需要过滤掉,如蓝色点所示;经过初步筛选,图2中9个红色的点作为初筛后留下的正样本点。
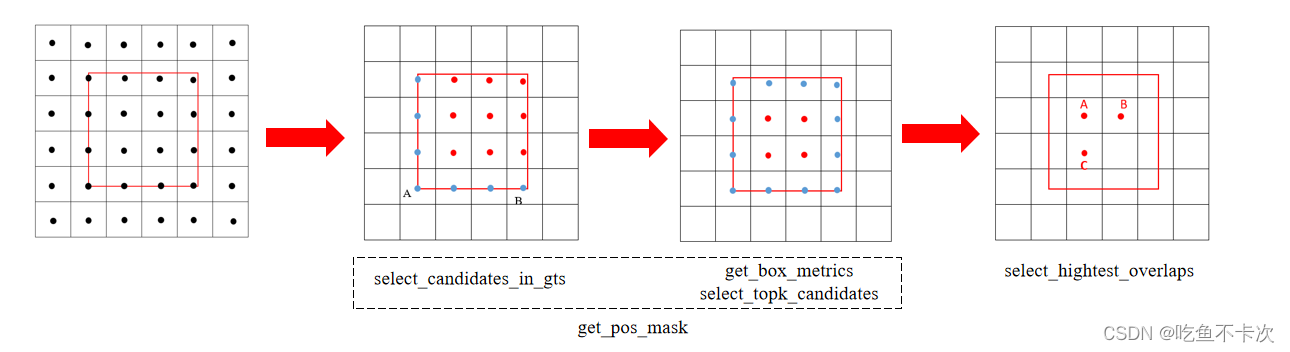
(2)精细筛选:即get_box_metrics,select_topk_candidates,通过公式align_metric=s^α∗u^β(s和u分别表示分类得分和CIoU得分, a和b是权重系数,默认值分别0.5和6.0),计算出每个预测框的得分,然后把得分低的预测框给过滤掉,一般会取得分最高的top10个gird cell。
其中分类得分,取的在是GT Box内对应的类别的预测值,比如该GT的类别下标为1,那么落在GT box内的点所预测的类别下标为1时的置信度。另外计算IoU使用的是CIoU,计算公式和计算过程如下所示,如何理解CIoU呢,IoU并无法充分表示预测框和标注框之间的关系,需要引入中心点距离,以及最小矩形框斜边距离,通过这两者的比值来表示预测框和标注框的相似度。所以会在IoU的基础上减去该比值,再减去由预测框宽高和标注框宽高组成的式子。

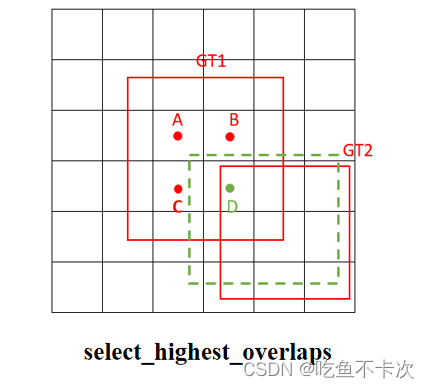
(3)剔除多余:保证一个Grid Cell只预测一个GT框,如果一个Grid Cell同时匹配到两个GT Box,那么将从这两个GT中,选出与他CIoU值最大的一个作为他要预测的GT Box。如图所示,Grid Cell A、B、C负责预测GT1,包括预测GT1的类别和Box,而Grid Cell D负责预测GT2,也是预测类别和Box。
3.Loss
YOLOv8的Loss由三部分组成:Loss_box,Loss_cls,Loss_DFL分别表示回归框损失,类比损失和DFL损失(其实也是回归框的损失),下面会详细介绍这三种损失。

还是先来简单了解下Loss计算的思路,如下图所示:左边Target表示标签值,右边Pred表示预测值,均需要借助上一章找到的正样本,然后通过对比同一个Grid cell正样本的预测值和标签值,计算对应的Loss。
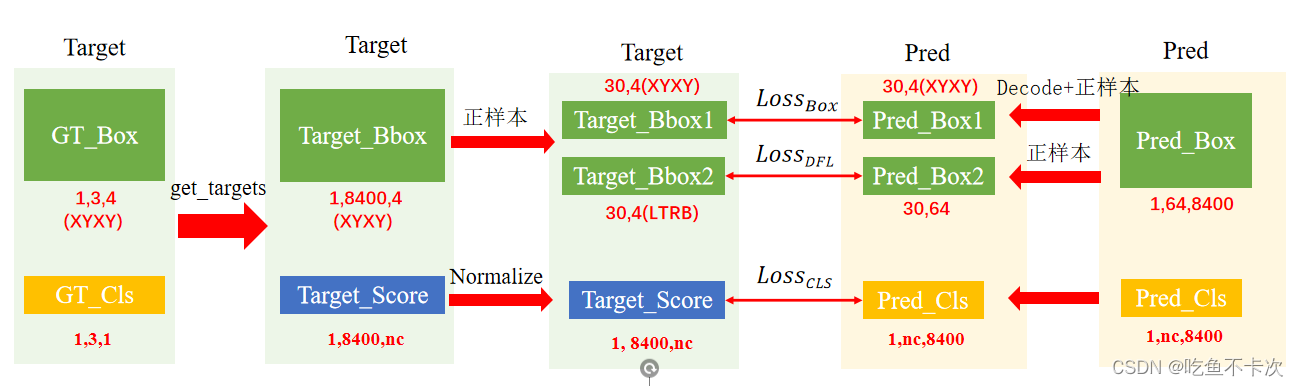
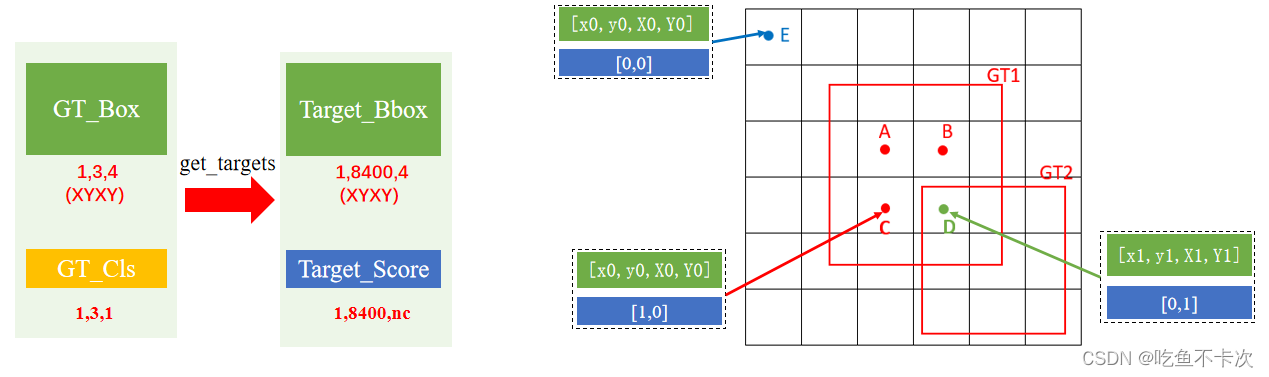
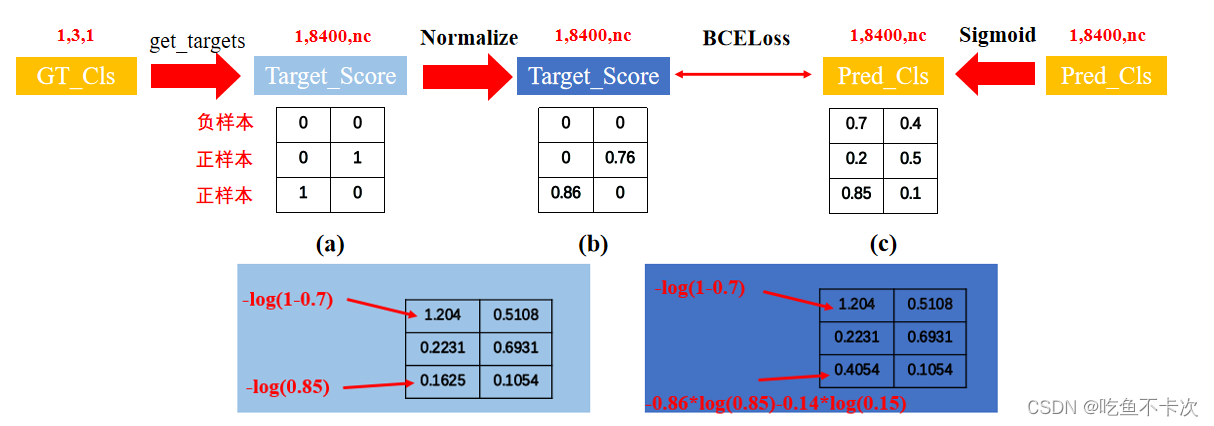
先来看一下get_targets函数做了哪些处理,GT_Box是经过预处理的,(1,3,4)表示XYXY且相对于640*640尺度的坐标。GT_Cls没有经过处理,表示GT_Box1、 GT_Box2、 GT_Box3的类别。
假设GT1的box是(x0,y0,X0,Y0),cls是0; GT2的box是(x1,y1,X1,Y1),cls是1;根据找到的正样本和负样本来举个例子,其中负样本为E,正样本为A/B/C/D.由图可以看到Target_Score在这一步已经区分了正负样本了,其中负样本使用[0,0]来表示。而Target_Bbox并没有区分正负样本,负样本统统会选择第1个GT的Box作为其Target_Bbox,换句话说,Target_Bbox值为[x0,y0,X0,Y0]的Grid cell可能为正样本也可能为负样本。
3.1Loss_cls
下面是YOLOv8中计算Loss_cls的代码:
target_scores_sum = max(target_scores.sum(), 1)loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
而主要的部分是Loss_cls采用了BCELoss损失函数,损失计算公式如下(注意:YOLOv8中的Cls使用的是BCEWithLogitsLoss,传入的预测值是不需要自己进行Sigmoid,损失内部会自动进行sigmoid,但我这里演示使用的是BCELoss):

假设当前只有两个类别,取出其中三个Grid cell的值,其中(0,0)表示负样本,(0,1)和(1,0)表示正样本,经过Normalize后得到带有权重的真实标签,这里正负样本均计算Loss.
3.2Loss_box
下面是YOLOv8中计算Loss_box的代码:
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
而主要的部分是Loss_box采用了CIoULoss损失函数,损失计算公式如下:

由前面可知,经过get_targets后的Target_Bbox并没有区分正负样本,因此下一步将利用fg_mask来区分正负样本,从而得到30个正样本。对Box会求两个损失,所以有Target_Bbox1和Target_Bbox2,都需要还原到各自的特征图的比例进行计算(可能这样数字比较小计算比较方便),并且分别采用XYXY格式和LTRB格式表示。
另一方面,Pred_Box1需要通过网络预测的结果(1,64,8400)解码成(1,4,8400)并采用XYXY坐标的格式表示,并且找到对应的30个正样本和Target_Bbox1计算CIoU损失;Pred_Box2则是直接把网络预测的结果(1,64,8400)取出来,然后找到对应的30个正样本,和Target_Bbox1计算DFL损失。
这里再说一下为什么会是30个正样本,因为有3个GT,每个GT取top10个得分最高的grid cell,并且这30个中没有因重复而被过滤掉的Grid cell。

3.3Loss_DFL
下面是YOLOv8中计算Loss_DFL的代码:
loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weightloss_dfl = loss_dfl.sum() / target_scores_sum
而主要的部分是Loss_DFL,损失计算公式如下:
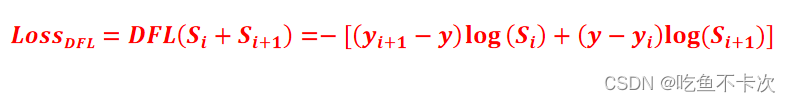
下面演示一个Grid cell正样本LTRB的计算过程:
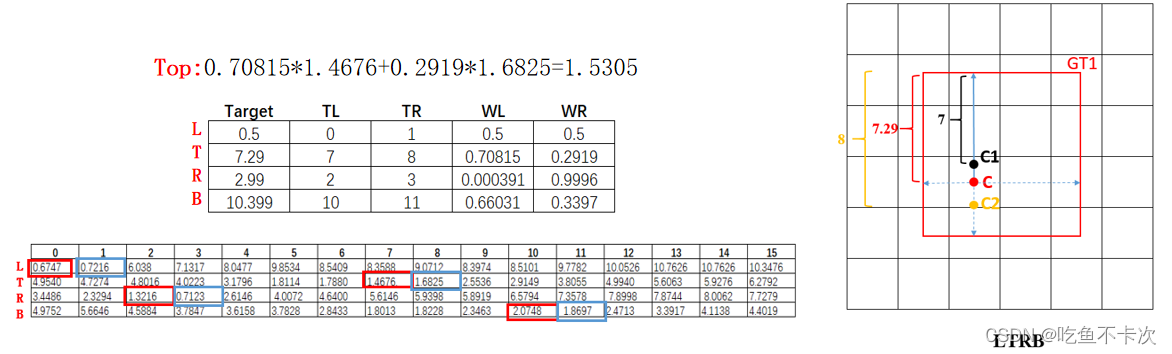
首先,Pred_Box2即Pred_dist,是一个(120,16)的矩阵,可以理解为(30*4,16),即共有30个正样本,每个正样本需要预测LTRB四个数值,并且这四个数又分别通过0~15来表示。其次,Target_Bbox2即Target,是一个(120,1)的向量,分别对应着30个样本中每个样本的LTRB真实值。最后,由于Target一般不会是整数值,所以需要计算相邻的两个真实值对应的损失。损失函数使用Cross_entropy损失.

前面提到了由于Target一般不会是整数值,所以需要计算相邻的两个真实值对应的损失,那么如何选择呢?这两个损失之间的权重又是怎么样的呢?为了加深理解,又单独举例演示该Grid cell中的Top_loss是怎么计算的:
该正样本需要对GT对应的LTRB中的T为例,该正样本的中心点距离上边框是7.29像素,因为网络预测只能是0~15的整数,那么只能选择7和8这两个相邻的值作为标签值,即yi=7和yi+1=8。接下来是选择这两个损失的权重,遵循一个原则:离得越近权重越大,所以当计算标签为7的时候,选择权重0.71,即yi+1-y;而计算标签为8的时候,选择权重0.21,即y-yi+1。
前面也提到了损失函数使用Cross_entropy损失,和BCE损失有两点区别,第一是把网络预测的每个正样本的LTRB值都需要进行SoftMax(),使得∑value=1,这和预测的时候是一样的;第二是只选取标签值对应的值作为损失,比如在该正样本预测Top的损失计算中,有7和8两个标签值,那么7对应的损失值为1.4676,即-Log(Si),8对应的损失值为1.6825,即-log(Si+1)。最后该正样本的Loss_Top为1.53,该正样本的总损失为(Loss_Left+ Loss_Top+ Loss_Right+ Loss_Bottom)/4.
 训练过程的原理会稍微复杂,先整理成这样子,后面我再优化下表达,争取每个人都可以看得懂。
训练过程的原理会稍微复杂,先整理成这样子,后面我再优化下表达,争取每个人都可以看得懂。