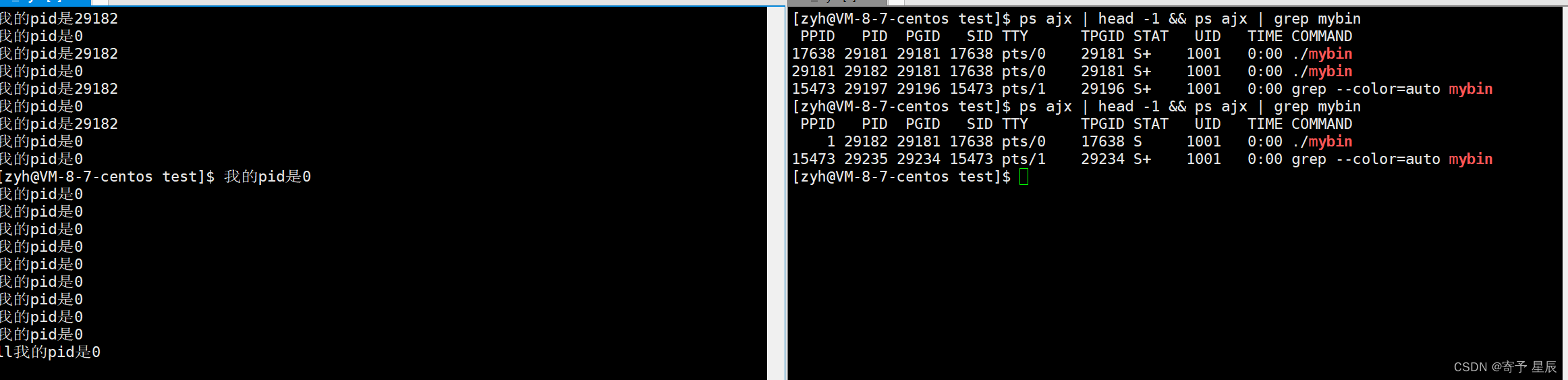
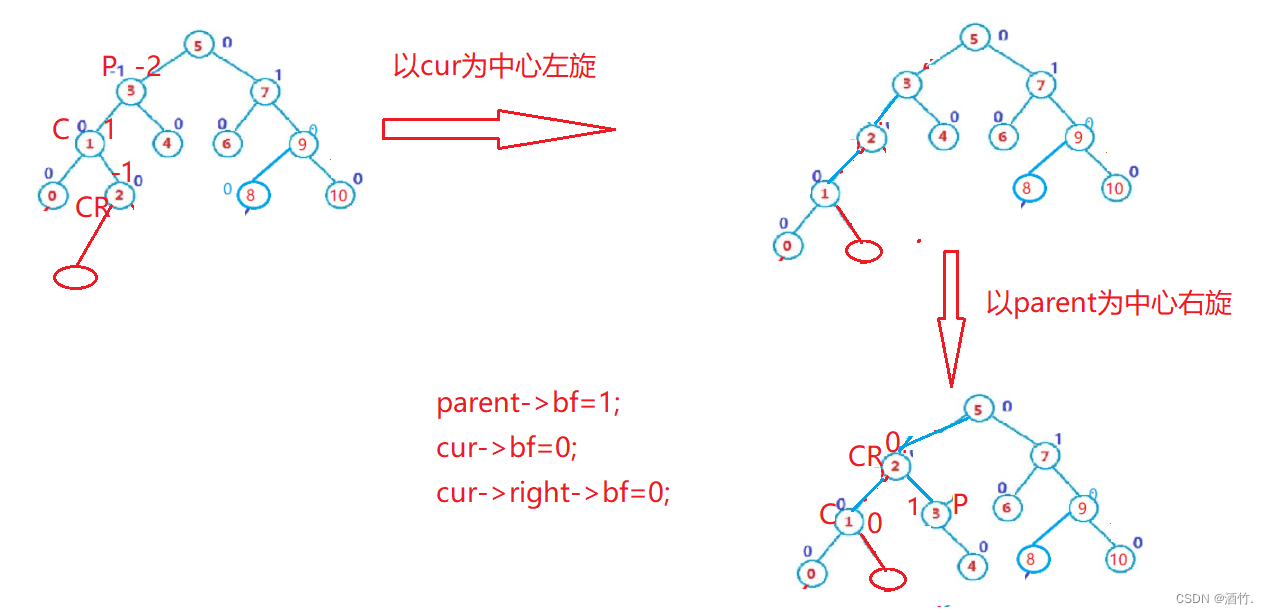
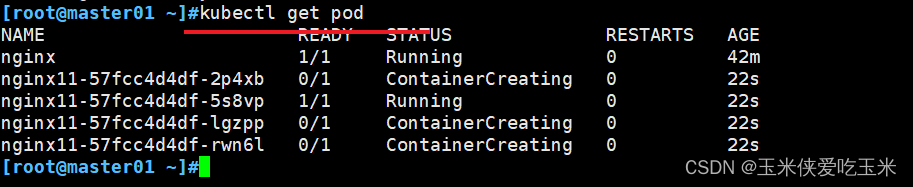
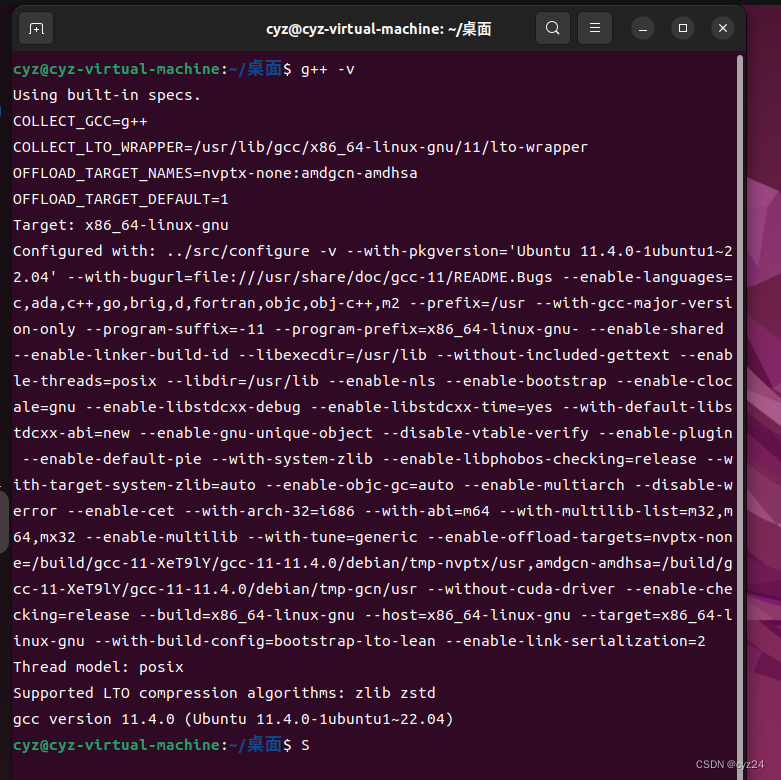
本改进已集成到 YOLOv8-Magic 框架。

我们提出了Axial Transformers,这是一个基于自注意力的自回归模型,用于图像和其他组织为高维张量的数据。现有的自回归模型要么因高维数据的计算资源需求过大而受到限制,要么为了减少资源需求而在分布表达性或实现的便捷性上做出妥协。相比之下,我们的架构既保持了对数据联合分布的完全表达性,也易于使用标准的深度学习框架实现,同时在需要合理的内存和计算资源的同时,达到了标准生成建模基准测试的最先进结果。我们的模型基于axial attention,这是自注意力的一个简单泛化,自然地与张量的多个维度在编码和解码设置中对齐。值得注意的是,所提出的层结构允许在解码过程中并行计算大部分上下文,而不引入任何独立性假设。这种半并行结构极大地促进了甚至是非常大的Axial Transformer的解码应用。我们在ImageNet-32 和 ImageNet-64 图像基准测试以及BAIR Robotic Pushing视频基准测试上展示了Axial Transformer 的最先进结果。我们开源了Axial Transformers 的实现。
1 论文简介
在当今深度学习的研究中,如何有效地处理高维数据,如图像和视频,是一个核心问题。Axial Transformers 提供了一种创新的自注意力机制&#x