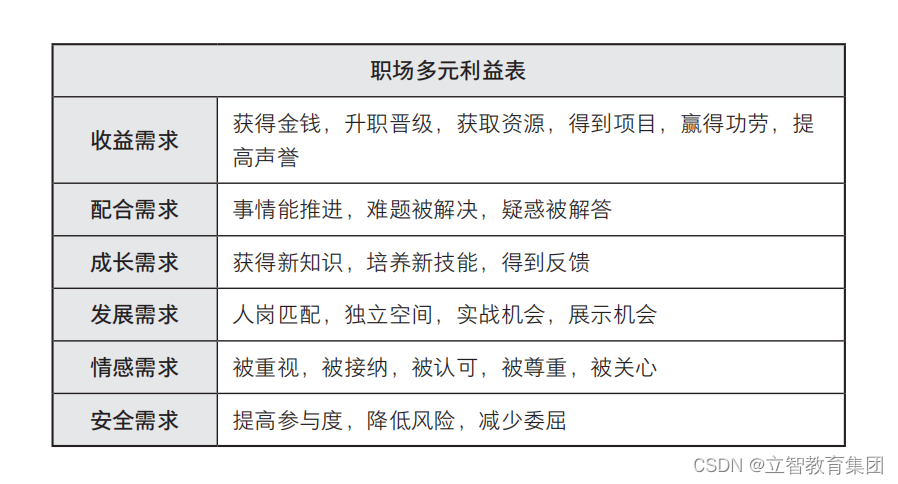
面试准备-项目【面试准备】
- 前言
- 面试准备
- 自我介绍:
- 项目介绍:
- 论坛项目功能总结
- 简介
- 数据库表设计
- 注册功能
- 登录功能
- 显示登录信息功能
- 发布帖子
- 评论
- 私信
- 点赞功能
- 关注功能
- 通知
- 搜索
- 网站数据统计
- 热帖排行
- 缓存
- 论坛项目技术总结
- Http的无状态
- cookie和session的区别
- 为什么要使用多线程本地存储,代替Session?
- CSRF
- JWT
- redis的使用
- redis的高级数据结构
- hyperloglog
- 为什么使用mq
- Kafka的使用
- es的使用
- 什么是ElasticSearch,存储原理,功能,特点
- 倒排索引的理解:
- Quartz的使用
- 什么是Quartz,特点,专业术语,项目应用
- 什么是Caffeine,如何缓存,项目应用
- 秒杀项目
- 简介
- 1数据设计
- 2用户注册
- 2用户登录
- 3商品列表和详情
- 3商品列表和详情
- 7缓存商品与用户
- 8异步化扣减库存
- 9削峰限流与防刷
- 秒杀下单完整操作的流程
- 如何解决超卖
- 使用redis的原子命令:decrement
- 改成一个Lua脚本
- redis分布式锁实现
- 怎么合理地设置分布式锁的过期时间
- Redisson
- redisson分布式锁的原理
- redisson分布式锁比setnx有什么优势?
- 其他问题
- 本地缓存
- RateLimiter
- 线程池
- RocketMQ的事务消息的好处
- RocketMQ重试机制
- 分布式ID
- UUID
- 类snowflake方案
- 数据库生成
- Leaf方案实现
- Leaf-segment数据库方案
- 缓存相关的问题
- 3种缓存更新策略是怎样的?
- 面经
- 消息堆积解决方案
- 消息发送、消费过程
- 消息一致性 不可重复性(以RabbitMQ角度来阐述的)
- 如果ack丢了,会有重复消息吗(重试 幂等)
- 刚才讲的是消费端的处理策略,生产端的处理策略是什么,怎么保障消息能发出去,不丢失?
- 正常消息队列的消息都是能正常发送的,在极端情况下消息队列的消息才会发不出去,对于消息队列来说有必要消耗一些性能对每一个消息做反查吗?
- 有用过其他的消息队列吗
- 讲讲RocketMQ事务消息的发送过程
- Caffeine的实现原理
- Guava的LoadingCache和ReloadableCache(没了解过)
- Kafka、RocketMQ、RabbitMQ的区别
- MQ
- Kafka如何保证消息不丢失
前言
2023-09-14 16:09:11
公开发布于
2024-5-22 00:14:02
面试准备
Java牛客网社区项目——知识点&面试题
高并发商城秒杀项目总结
自我介绍:
面试官,你好
项目介绍:
论坛项目 是软件工程实验的一个项目
使用了Springboot、Mybatis、MySQL、Redis、Kafka等工具。
主要实现了用户的注册、登录、发帖、点赞、系统通知、按热度排序、搜索等功能。
秒杀项目 本项目主要针对秒杀的场景进行的开发工作
实现了用户注册和登录,显示商品列表和详情,用户下单
主要是异步化扣减库存,使用redis解决超卖问题,rocketmq消息队列保证redis和mysql最终一致性

论坛项目功能总结
简介
主要使用了Springboot、Mybatis、MySQL、Redis、Kafka、等工具。
主要实现了用户的注册、登录、发帖、点赞、系统通知、按热度排序、搜索等功能。
另外引入了redis数据库来提升网站的整体性能,实现了用户凭证的存取、点赞关注的功能。
基于 Kafka 实现了系统通知:当用户获得点赞、评论后得到通知。
利用定时任务定期计算帖子的分数,并在页面上展现热帖排行榜。
数据库表设计
user
#id Iusername password salt Iemail type status activation_code header_url create_time discuss_post
#id Iuser_id title content type status create_time comment_count scorecomment
#id primary key Iuser_id entity_type Ientity_id target_id content status create_timemessage
#id Ifrom_id Ito_id Iconversation_id content status create_time timestamp nulllogin_ticket
#id user_id Iticket status expired
注册功能
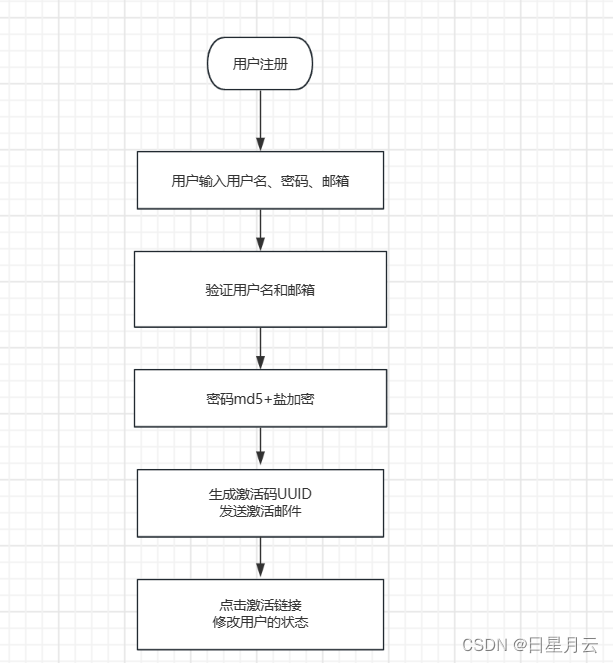
前端输入:用户名,密码,和邮箱
通过表单提交数据(账号、密码、邮箱)
服务端处理register()
调用service层
空值处理 验证账号 验证邮箱
/*虽然说账号和邮箱是普通索引,但是在应用层保证了其唯一性*/
注册用户
密码使用md5盐值加密
/*
md5 王小云团队破解了,sha-1
“彩虹表”(Rainbow Table)是一种预先计算的表格,用于加速哈希函数的逆向破解过程。
通过预先计算大量的输入和对应的哈希值,将它们存储在表格中。
当需要破解某个哈希值时,可以在预先计算好的表格中查找对应的输入值。
*/
激活码UUID
// http://localhost:8080/community/activation/101/code
发送激活邮件
返回操作(注册)-结果(成功)页面|返回注册页面
用户点击激活邮件
服务端调用activation()
调用service层
用户状态==1:重复激活
激活码相同:设置状态为1,激活成功
激活失败
跳转到操作(激活)-结果页面

登录功能
用户进入登录页面,就会请求后端,获取验证码
原来是把验证码存入session中
后面是存入cookie中,进而存入redis中
/*
给每一个访客生成一个UUID,存入到cookie中
redis使用uuid作为键,验证码结果作为值
可以作访客匿名登录方式来浏览网站,再进行其他操作,再使用账密登录
这个功能好像没有实现
*/
cookie(kaptchaOwner,UUID) (KaptchaKey_redisKey,验证码结果,60s)
用户填写信息:账号、密码、验证码
提交表单
后端就调用login方法
取出验证码的答案
原来是session中取出
后来是Cookie-->kaptchaOwner-->(Redis)kaptcha
验证码正确:下一步 ;否则返回错误信息
验证:用户名,密码
调用Service层
空值处理 验证账号 验证状态(用户的激活状态) 验证密码
如果都正确就生成登录凭证(userId ticket status )
原来的登录凭证是插入到一个数据库表中
后来是存入到redis中
通过Map返回错误信息,或者登录凭证
如果有登录凭证,就跳转到首页
并且把ticket存入到cookie中
如果没有,就返回错误信息
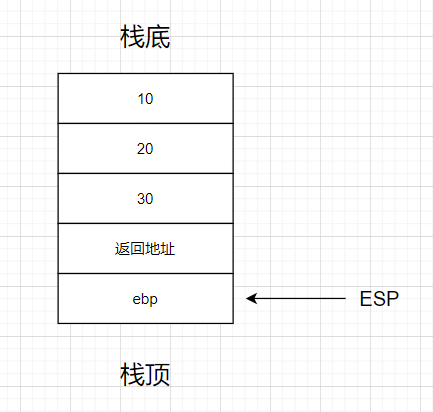
显示登录信息功能
编写一个拦截器:LoginTicketInterceptor
preHandle()
//Controller执行之前,拿到登录用户
在Cookie中获取凭证
//数据库查询登录凭证的状态
后来使用redis存凭证
本次请求持有用户 https://www.nowcoder.com/study/live/246/2/27 38::48
存入HostHolder(ThreadLocal) 多线程存储代替Session存储
postHandle()
//Controller执行之后:把loginUser返回mav
从HostHolder中拿到用户
存入mav中
afterCompletion()
//请求处理完毕
清理HostHolder
配置WebMvcConfig:登录拦截器
@Overridepublic void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor(loginTicketInterceptor).excludePathPatterns("/**/*.css", "/**/*.js", "/**/*.png", "/**/*.jpg", "/**/*.jpeg");}发布帖子
在MySQL中保存帖子
调用service层
转义HTML标记 过滤敏感词
触发发帖事件来进行系统通知,并且同步es中的数据
记录帖子分数
存入id到redis中,
定时任务查看需要刷新的帖子
计算帖子分数,更新到数据库中
order by来进行排序
评论
存储评论
调用service层
事务
添加评论 转义HTML标记 过滤敏感词
更新帖子评论数量
如果是回复的话(评论评论)
触发评论事件
如果是评论的话(评论帖子)
触发发帖事件
计算帖子分数
存入id到redis中,来进行排行
重定向到帖子详情
私信
构建消息对象
ConversationId(小id_大id)
status:0是未读,1是已读,2是删除
调用service层
转义HTML标记 过滤敏感词
设置已读:把所有未读的消息都设置为已读
点赞功能
点赞
点赞使用set存储用户id
判断是否点赞过可以在set中取到不?isMember()
redis事务
isMember()//需要先查
multi()
添加|移除 用户
增加|减少 点赞数量
exec()
数量
状态
返回的结果(数量和状态)
触发点赞事件
如果是对帖子点赞
计算帖子分数
关注功能
关注
调用service层
redis事务
multi()
add关注列表
add粉丝列表
exec()
触发关注事件
取关
调用service层
redis事务
multi()
remove关注列表
remove粉丝列表
exec()
通知
kafka
通知表没有单独设计,而是复用了私信表
| id | from_id | to_id | conversation_id | content | status | create_time |
|---|---|---|---|---|---|---|
| 39 | 111 | 131 | 111_131 | 嘎嘎嘎 | 0 | 2022-08-23 15:27:06 |
| 92 | 1 | 111 | like | {“entityType”:1,“entityId”:237,“postId”:237,“userId”:112} | 1 | 2022-08-23 15:27:06 |
| 主键 | 发 | 收 | 交流id:小_大 | 内容 | ‘0-未读;1-已读;2-删除;’ | 时间 |
| 主键 | 1是系统发通知 | 收 | 主题 | 信息 | ‘0-未读;1-已读;2-删除;’ | 时间 |
搜索
es
搜索帖子
聚合数据 (帖子 作者 点赞数量)
分页信息
使用kafka保证数据库和es的一致性
发布帖子和删除帖子,都会利用kafka来在es中保存和删除
网站数据统计
统计网站UV getUV()
调用service层整理该日期范围内的key
合并这些数据
union()
返回统计的结果
统计活跃用户DAU getDAU()
调用service层整理该日期范围内的key
进行OR运算
OR bitCount
返回统计的结果
使用Redis的高级数据结构:
HyperLogLog:超级日志,统计独立整数个数。统计UA(独立访问)时,以日期为 rediskey ,将客户端IP add 到HyperLogLog中(redisTemplate.opsForHyperLogLog().add(redisKey, i);)
Bitmap:位图,比如365天的签到,只需要365/8个字节的大小。统计DAU(日活跃用户)时,以日期为 rediskey ,以用户ID作为位(在数据中的位置),用 or 操作,既可以方便的统计一段时间内的注册用户访问人数。
热帖排行
mysql order by
执行刷新的方法
判断Redis中没有需要刷新的帖子id
执行刷新方法
刷新帖子分数 refresh()
是否精华
评论数量
点赞数量
计算权重=精华分+评论数×10 +点赞数×2
分数 = log10(max(帖子权重,1) + 距离天数
更新帖子分数
同步搜索数据
缓存
缓存帖子
本地缓存
redis缓存
mysql中
缓存用户
查询用户的时候,
1.优先在缓存中取
2.取不到,初始化缓存
3.数据变更时清除缓存数据
更新数据的数据库与缓存的一致性:
先更新数据库,再删除缓存
论坛项目技术总结
Http的无状态
HTTP(Hypertext Transfer Protocol)是一种无状态协议。这意味着每个HTTP请求都是独立的,服务器不会保留之前的请求信息或状态。
当客户端发送HTTP请求到服务器时,服务器会根据请求的内容做出响应,但服务器不会记住之前的请求或客户端的状态。每个请求都是相互独立的,服务器不会在请求之间建立连接或保持会话。
这种无状态的设计使得HTTP具有一些优势,包括简单、高效和可扩展。无状态的HTTP允许服务器处理大量的并发请求,并且不需要为每个请求维护额外的状态信息。这降低了服务器的负担,并使得系统更具可伸缩性。
然而,由于HTTP是无状态的,它限制了服务器在处理多个请求时共享和存储用户状态的能力。为了解决这个问题,通常会使用Session、Cookie或其他机制来实现状态的跟踪和管理。
cookie和session的区别
Cookie和Session是两种常见的用于在Web应用中跟踪用户状态和存储用户相关数据的机制。它们的主要区别如下:
存储位置:
Cookie:Cookie是存储在用户浏览器中的小型文本文件。服务器通过响应头将Cookie发送给客户端浏览器,并由浏览器保存在本地。当浏览器再次请求同一网站时,会在请求头中自动将相应的Cookie发送给服务器。
Session:Session是存储在服务器端的一种数据结构。每个Session都有一个唯一的会话ID,服务器将会话ID通过Cookie或URL参数发送给客户端,客户端在后续请求中通过会话ID来标识自己。
数据存储:
Cookie:Cookie可以存储少量的键值对数据。每个Cookie的大小通常有限制(如4KB),因此适合保存较小的数据。
Session:Session可以存储更大、更复杂的数据结构,如对象和数组。因为Session数据存储在服务器端,所以没有明确的大小限制。
安全性:
Cookie:Cookie是存储在客户端的,容易受到安全攻击。为了增加安全性,可以使用加密和签名等机制来保护Cookie的内容。
Session:Session存储在服务器端,相对而言更安全。然而,Session ID 可能会受到会话劫持和会话固定攻击等安全威胁,因此需要采取相应的防护措施,如使用HTTPS协议和生成随机的会话ID。
生命周期:
Cookie:Cookie可以设置过期时间,可以是会话Cookie(存储在内存中,关闭浏览器即失效)或持久Cookie(存储在硬盘上,过期时间之前有效)。
Session:Session通常在用户第一次访问网站时创建,并在用户关闭浏览器或超过一定时间(如30分钟)无活动时过期。
综上所述,Cookie适用于需要在客户端存储少量简单数据的场景,而Session适用于需要在服务器端存储较大复杂数据且需要一定安全性的场景。在实际应用中,Cookie和Session通常是结合使用的,Cookie用于存储会话ID,而Session用于存储用户的具体数据。
为什么要使用多线程本地存储,代替Session?
使用多线程本地存储代替Session的主要原因是解决在多线程环境下使用Session可能出现的线程安全问题。
Session是一个服务器端的存储机制,用于保存用户的会话信息。在多线程环境下,如果不进行额外的处理,每个线程都会共享同一个Session对象,这可能导致以下问题:
线程安全问题:多个线程同时访问和修改同一个Session对象时,可能会引发竞争条件和并发访问问题。这可能导致数据不一致、数据丢失或者系统崩溃。
性能问题:由于Session是服务器端存储,多个线程同时对Session进行读写操作时,可能会引起性能瓶颈。尤其在高并发场景下,频繁的Session读写操作可能成为系统的瓶颈。
为了解决这些问题,可以使用多线程本地存储来代替Session。多线程本地存储是指为每个线程维护一个独立的存储空间,使得每个线程都可以独立操作自己的存储空间,从而避免了线程安全问题和性能问题。
多线程本地存储可以使用ThreadLocal来实现。ThreadLocal是一个线程本地变量,每个线程都有自己独立的ThreadLocal变量副本,并且每个线程可以独立修改自己的副本,而不会影响其他线程的副本。这样就可以在多线程环境下,为每个线程维护独立的存储空间,避免线程安全问题和性能问题。
综上所述,使用多线程本地存储代替Session可以提供更好的线程安全性和性能,在多线程环境下更加可靠和高效。
CSRF
跨站请求伪造(Cross-Site Request Forgery,CSRF)是一种恶意攻击,攻击者通过伪装合法用户的请求来执行非法操作。CSRF攻击利用了Web应用程序对用户发出的请求缺乏验证机制的漏洞。
攻击者通常会利用用户已经登录的状态来进行CSRF攻击。攻击者会在恶意网站上嵌入特制的代码,当用户访问这个网站时,恶意代码会发送伪造的请求到目标网站上。目标网站会将这个请求当作是合法用户的请求,并且执行对应的操作,从而达到攻击者的目的。
为了防止CSRF攻击,可以采取以下措施:
验证来源(Referer):在服务器端验证请求的来源,确保请求来自于合法的网站。这种方法依赖于浏览器发送请求时自动添加的Referer头,但是这个头可能被篡改或者被禁用。
添加随机令牌(Token):在每个表单中添加一个随机生成的令牌,该令牌会在服务器端进行验证。攻击者无法获取到合法用户的令牌,因此无法伪造合法的请求。
同源策略(Same-Origin Policy):浏览器的同源策略会阻止网页从一个不同源的网址获取或发送数据。这种策略可以防止恶意网站获取到用户的登录状态,从而防止CSRF攻击。
使用验证码:在一些敏感操作上使用验证码,要求用户输入验证码才能执行操作。这可以有效防止CSRF攻击,因为攻击者无法获取到正确的验证码。
综合使用以上多种防护措施可以提高系统的安全性,防止CSRF攻击。在开发Web应用程序时,应该注意对用户请求的验证和防护措施的实施,确保应用程序的安全性。
JWT
springBoot 的jwt实现权限认证
JWT(JSON Web Token)是一种用于在网络应用之间传递信息的开放标准(RFC 7519)。它是基于JSON的轻量级认证机制,用于在客户端和服务器之间安全地传递信息。
JWT由三个部分组成:头部(Header)、载荷(Payload)和签名(Signature)。
头部(Header):包含了两个部分,分别是令牌的类型和采用的加密算法(例如HMACSHA256、RSA等)。头部通常是Base64编码的JSON字符串。
载荷(Payload):包含了一些声明和数据。声明是一些有关实体(用户)和其他数据的声明,可以包括用户ID、角色、过期时间等。载荷也是Base64编码的JSON字符串。
签名(Signature):使用私钥对头部和载荷进行加密生成签名。签名用于验证JWT的真实性和完整性,确保JWT在传输过程中没有被篡改。签名通常由头部、载荷、密钥和指定的加密算法生成。
使用JWT进行身份验证的流程如下:
用户提供用户名和密码进行登录。
服务器验证用户的身份信息,如果验证成功,生成JWT并返回给客户端。
客户端将JWT保存在本地,以后的请求中都会携带该JWT。
服务器收到请求后,会验证JWT的签名和有效期,如果验证通过,处理请求。
JWT的优点是轻巧、可扩展和易于传递。由于JWT包含了自身的认证信息,减少了对服务器存储状态的需求,使得跨多个服务的分布式应用变得更加容易。但需要注意的是,由于JWT的所有信息都是可见的,因此不应将敏感信息存储在JWT中,以防止信息泄露的安全风险。

#1.认证流程
- 首先,前端通过Web表单将自己的用户名和密码发送到后端的接口。这一过程一般是一个HTTP POST请求。建议的方式是通过SSL加密的传输(https协议),从而避免敏感信息被嗅探。
- 后端核对用户名和密码成功后,将用户的id等其他信息作为JWT Payload(负载),将其与头部分别进行Base64编码拼接后签名,形成一个JWT。形成的JWT就是一个形同111.zzz.xxx的字符串。 token head.payload.singurater
- 后端将JWT字符串作为登录成功的返回结果返回给前端。前端可以将返回的结果保存在localStorage或sessionStorage上,退出登录时前端删除保存的JWT即可。
- 前端在每次请求时将JWT放入HTTP Header中的Authorization位。(解决XSS和XSRF问题)
- 后端检查是否存在,如存在验证JWT的有效性。例如,检查签名是否正确;检查Token是否过期;检查Token的接收方是否是自己(可选)。
- 验证通过后后端使用JWT中包含的用户信息进行其他逻辑操作,返回相应结果。
#2.jwt优势
- 简洁(Compact):可以通过URL,POST参数或者在HTTP header发送,因为数据量小,传输速度也很快
- 自包含(Self-contained)︰负载中包含了所有用户所需要的信息,避免了多次查询数据库
- 因为Token是以JSON加密的形式保存在客户端的,所以JWT是跨语言的,原则上任何web形式都支持。
- 不需要在服务端保存会话信息,特别适用于分布式微服务。redis的使用
五种数据结构
string hash list set zset
string
存储登录验证码结果
做缓存 缓存用户信息
先更新数据库再删除缓存
1.优先从缓存中取值
2.取不到初始化缓存数据
3.数据变更时清除缓存数据
set
存储点赞
点赞和取赞是根据redis是否赞列表存储过该用户
无:点赞;存:取赞
事务:添加用户 add() 点赞increment()
事务:移除用户 remove移除 取赞decrement()
查询某实体点赞的数量 size()
查询某人对某实体的点赞状态 isMember()
查询某个用户获得的赞 get()
存储需要书刷新帖子分数的帖子id
key:帖子分数
value:discussPostId
用来定时刷新帖子分数的
zset
存储关注列表、粉丝列表
score 日期 按时间降序排列
事务:关注 add添加 关注列表 粉丝列表
事务:取消关注 remove移除 关注列表 粉丝列表
查询关注|粉丝数量 zCard()
查询当前用户是否已关注该实体 score()
查询某用户关注的人 reverseRange() 取出id再到User表中查询
查询某用户的粉丝 reverseRange() 取出id再到User表中查询
hyperLogLog
统计uv
存储ip add()
指定日期统计union()
bitmap
统计dau
存储userId setBit()
统计指定日期范围内的DAU OR运算 bitCount()
redis的高级数据结构
拦截器:记录uv,dau访问过一次判断其为活跃
hyperLogLog
统计uv
key:uv_日期
value:ip
add()
指定日期范围统计union()之后再size返回
bitmap
统计dau
key:dau_日期
value:userId
setBit()
统计指定日期范围内的DAU OR运算 bitCount()
hyperloglog
三分钟了解Redis HyperLogLog 数据结构
HyperLogLog是一种基数估计算法,它可以在只使用很少的内存空间的情况下,近似地估计一个集合中不重复元素的数量。
在Redis中,HyperLogLog是通过一个专门的命令来实现的,这个命令的名称是PFADD,它可以用来添加元素到HyperLogLog中,还有一个命令PFCOUNT,可以用来获取HyperLogLog中不重复元素的数量。
为什么使用mq
解耦 异步 削峰
比如:论坛项目中的,关注,点赞或评论帖子,做系统通知
如果写出一个方法的话,还需要保证事务,设置事务的传播行为
但是别人点赞了,和你收到系统通知,其实是两个业务
别人点赞了,系统通知的业务执行失败,你也不能回滚
这两个操作也是异步的
削峰,秒杀项目的扣减库存
Kafka的使用
系统通知事件:发送系统消息(关注、点赞、评论)
发帖或删帖事件:es数据和MySQL中的同步
es的使用
搜索帖子
与mysql的一致性是通过kafka来实现的
什么是ElasticSearch,存储原理,功能,特点
概念:ES是一个基于lucene构建的,分布式的,RESTful的开源全文搜索引擎。
存储原理:数据按照Index – Type – Document – 字段四级存储,其中Index对应数据库,Type对应表,Document为搜索的原子单位,包含一个或多个容器,基于JSON表示。字段是指JSON中的每一项组成,类似于数据库中的行/列。Mapping是文档分析过滤后的结果,根据用户自定义,将某些文字过滤掉,类似于表结构定义DDL??。同时ES也和分布式数据库一样,支持shard的replication。
功能:
1、分布式的搜索引擎和数据分析引擎
2、全文检索,结构化检索,数据分析。
3、对海量数据进行近实时的处理
特点:
1、可以作为分布式集群处理PB级别的数据,也可单机使用。
2、不是特有技术,而是将分布式+全文搜索(lucene) + 数据分析合并在一起。
3、操作简单,作为传统数据库的补充,提供了数据库所不具备的很多功能。
倒排索引的理解:
倒排索引(Inverted Index)是一种用于快速定位文档的索引结构。在倒排索引中,每个关键词都维护了一个包含包含该关键词的文档列表。通过倒排索引,可以快速地找到包含特定关键词的文档,而无需遍历所有文档。
倒排索引的构建过程包括以下几个步骤:
文档分词:将每个文档拆分为一个个的词语(或称为术语,terms),这通常是通过分词器(tokenizer)来实现的。分词器可以根据各种规则和算法将文本切分为合适的词语。
构建倒排索引:对于每个词语,将它出现的文档ID记录到倒排索引中。倒排索引的数据结构通常是一个关联数组(Associative Array),其中词语作为键,文档ID的列表作为值。
优化倒排索引:为了提高查询性能和减少索引的大小,通常还会对倒排索引进行优化。例如,可以使用压缩算法对文档ID列表进行压缩,或者使用数据结构如跳表(Skip List)来加速查找过程。
通过倒排索引,可以在搜索时快速定位包含特定关键词的文档。比如,当用户在搜索引擎中输入一个关键词时,搜索引擎可以通过倒排索引找到包含该关键词的文档,并返回给用户相关的搜索结果。倒排索引是大部分搜索引擎(包括Elasticsearch)的核心组成部分,它能够提供快速、灵活和准确的搜索功能。
Quartz的使用
redis存储需要刷新的帖子id
定时任务刷新帖子分数
到mysql中
什么是Quartz,特点,专业术语,项目应用
概念:quartz是一个开源项目,完全基于java实现。是一个优秀的开源调度框架。
特点:
1,强大的调度功能,例如支持丰富多样的调度方法
2,灵活的应用方式,例如支持任务和调度的多种组合方式
3,分布式和集群能力
专业术语:
scheduler:任务调度器 , scheduler是一个计划调度器容器,容器里面有众多的JobDetail和trigger,当容器启动后,里面的每个JobDetail都会根据trigger按部就班自动去执行
trigger:触发器,用于定义任务调度时间规则
job:任务,即被调度的任务, 主要有两种类型的 job:无状态的(stateless)和有状态的(stateful)。一个 job 可以被多个 trigger 关联,但是一个 trigger 只能关联一个 job
misfire:本来应该被执行但实际没有被执行的任务调度
项目应用:定时的统计帖子分数(如何设置定时任务和trigger)
什么是Caffeine,如何缓存,项目应用
概念:Caffeine 是一个基于Java 8的高性能本地缓存框架
初始化cache:缓存保存的对象,使用Caffeine.newBuilder()创建,创建时设置缓存大小,过期时间,缓存未命中时的加载方式。
为什么只缓存热度帖子?答:因为不会经常变。
秒杀项目
简介
秒杀项目 模仿京东实现的一个秒杀项目
实现了用户注册和登录,显示商品列表和详情,用户下单
使用Reids缓存商品与用户,做了简单的削峰限流
采用异步化扣减库存,使用rocketmq消息队列解决超卖问题
1数据设计
用户 user_info
#id Uphone password密码 nickname昵称 gender性别 age年龄商品 item
#id title price sales image_url description商品库存表 item_stock
#id Uitem_id stock商品活动 promotion
#id name start_time end_time U:item_id promotion_price订单表 order_info
#id user_id item_id promotion_id order_price order_amount order_total order_time序列号表 serial_number
#U name具体业务 value值 step步长库存流水表 item_stock_log
#id UUID item_id哪个商品 amount购买数量 status状态 '0-default; 1-success; 2-failure;'
2用户注册
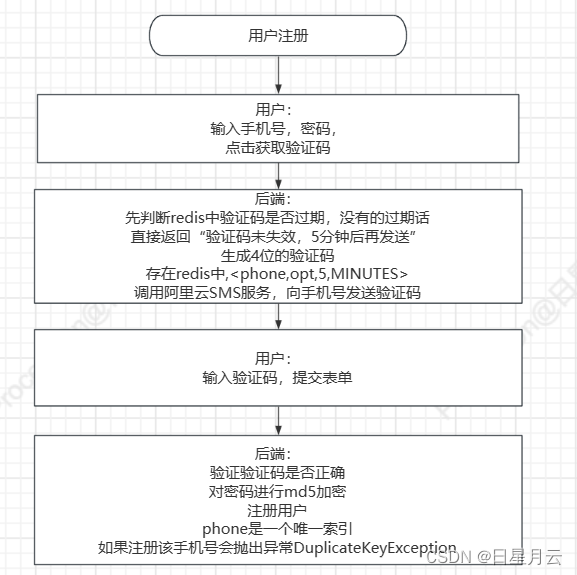
用户:
- 点击个人注册
- 输入手机号
- 点击获取验证码
前端请求后端:获取验证码
// 生成OTP
UUID:4位的随机数(0~9)
// 绑定OTP
2用户注册与登录:后端:把验证码存入到session中
6分布式状态管理:存入到redis中的<phone,otp,5mins>
// 发送OTP
输出到控制台里改为短信发送
短信验证码【java提高】
用户填写信息(手机号和密码),点击立即注册
前端请求后端:注册
UserController:调用register()
// 验证OTP
2用户注册与登录:session.getAttribute()
6分布式状态管理:取到phone对应的otp
// 加密处理
// 注册用户

2用户登录
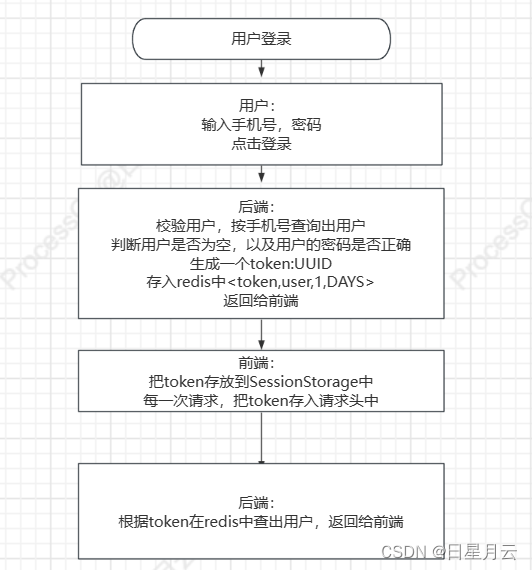
用户输入手机号和密码
前端请求后端:登录
后端调用login()
校验用户名和密码
2用户注册与登录:存入loginUser到session中
6分布式状态管理:存入到redis中的<token,loginUser>中 返回token给前端
前端:把返回的token存入到浏览器sessionStorage
每次ajax异步请求都会带上token,为了得到当前登录用户
前端请求时,把token放入到请求头的Authorization字段中
后端获取token,在redis中查询用户返回JSON

3商品列表和详情
商品列表
除了数据库表设计的范式
之外还考虑到了库存和商品信息的一个锁的粒度
商品
dao层不需要商品,库存,活动三表的连接
在业务层中拼接ValueObject
//查询出来所有的商品public List<Item> findItemsOnPromotion() {List<Item> items = itemMapper.selectOnPromotion();return items.stream().map(item -> {// 查库存ItemStock stock = itemStockMapper.selectByItemId(item.getId());item.setItemStock(stock);// 查活动Promotion promotion = promotionMapper.selectByItemId(item.getId());if (promotion != null && promotion.getStatus() == 0) {item.setPromotion(promotion);}return item;}).collect(Collectors.toList());}
商品详情
查询本地缓存 guava 初始10 最大100 过期1分种
查询redis缓存 3分种
查询mysql
3商品列表和详情
商品列表
除了数据库表设计的范式
之外还考虑到了库存和商品信息的一个锁的粒度
商品
dao层不需要商品,库存,活动三表的连接
而是分别查出来PO(Persistant Object)持久对象
在业务层中拼接BO(Business Object)业务对象
//查询出来所有的商品public List<Item> findItemsOnPromotion() {List<Item> items = itemMapper.selectOnPromotion();return items.stream().map(item -> {// 查库存ItemStock stock = itemStockMapper.selectByItemId(item.getId());item.setItemStock(stock);// 查活动Promotion promotion = promotionMapper.selectByItemId(item.getId());if (promotion != null && promotion.getStatus() == 0) {item.setPromotion(promotion);}return item;}).collect(Collectors.toList());}
商品详情
查询本地缓存 guava 初始10 最大100 过期1分种
查询redis缓存 3分种
查询mysql
7缓存商品与用户
缓存商品信息
先找本地guava缓存guava 初始10 最大100 过期1分种
在找redis缓存 3分种
在查找商品信息中添加缓存
在显示商品信息时访问缓存
缓存用户信息
没有使用本地缓存,不适合
本地缓存应缓存最重要最频繁的数据,数据量不应该太大
在查找用户时添加缓存
获取redis秒杀令牌的检查用户的时候
在创建订单中访问缓存
再次校验用户
8异步化扣减库存
rocketmq的事务型消息
两阶段提交
保证消息的一致性
保证本地事务和消息的消费者的一致性
提交–消费
回滚–不消费

步骤
1-4 :第一阶段
5,7 很长时间仍没结果得不到正确的执行,把半成品消息放到死信队列中,人工介入
- 生产者 send MQ Server 发送半成品消息
- ok 不会让消费者先消费这条消息
- 访问mysql执行本地事务
- 成功就commit,失败就rollback 是否允许消费者消费这条消息 第4步没有传递 Server,半成品消息一直消费不了
- 加入回查机制check 时间递增
- 服务器去check数据库
- 反馈结果给MQ
- 半成品消息转为正式消息,让消费者消费
代码需要体现1 3 6 步
异步扣减库存的实现

步骤
- 生成流水,在发送消息之前。 流水为了更好的判断库存状态用于check
- 发送消息
- 预减库存(在缓存中),创建订单
- 更新流水
- check 检查流水
- 检查库存流水 锁的粒度比库存较小
- 最后扣减库存
9削峰限流与防刷
Java项目笔记之秒杀接口防刷限流
https://www.shangyexinzhi.com/article/2741037.html
验证码:秒杀请验证是否是人
秒杀大闸:需要拿令牌,才能进行秒杀
队列泄洪:单机限流器,线程池taskExecutor
private RateLimiter rateLimiter = RateLimiter.create(1000);
# ThreadPool
spring.task.execution.pool.core-size=5
spring.task.execution.pool.queue-capacity=10
spring.task.execution.pool.max-size=30
秒杀下单完整操作的流程
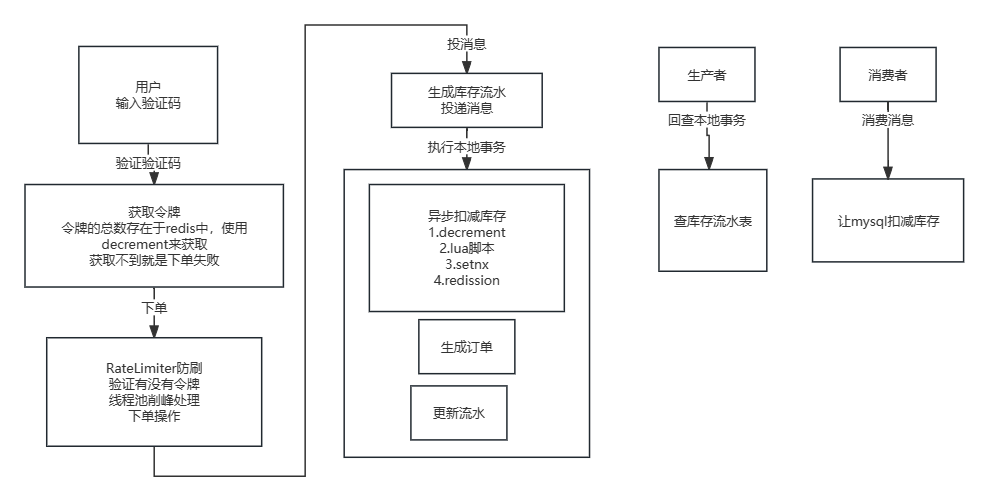
验证码输入验证码正确之后
获取凭证会先判断商品是不是售罄了,商品售罄是会在redis中添加标识// 校验用户 缓存中 redis 30 mins MySQL
// 校验商品 缓存中 guava 1 min redis 3 mins mysql
cache = CacheBuilder.newBuilder().initialCapacity(10).maximumSize(100).expireAfterWrite(1, TimeUnit.MINUTES).build();// 校验活动秒杀大闸,decrementredis中存入凭证
RateLimter.create(1000);//每秒最多允许请求数1000//限制单机流量 例如限制API调用的速率,确保系统不会被过多的请求压垮。
rateLimiter.tryAcquire(1,TimeUnit.SECONDS)
尝试从速率限制器中获取一个许可,速率限制器的最大速率为每秒1个许可。//验证活动凭证
从redis中取凭证队列泄洪
线程池处理任务,异步下单扣减库存
检查售罄标识生成库存流水 status:0发送事务消息,扣减库存
生成者:
执行本地事务:预减库存:redis中,售罄表示创建订单:事务 @Transactional订单号的生成:日期+流水号 序号表中(获取流水号+更新流水号) 事务 @Transactional(propagation = Propagation.REQUIRES_NEW)外部事务回滚,本地事务不回滚spring事务的传播机制更新流水:status:1
回查本地事务:检查流水表
0:unknow 1:commit rollback消费者:
扣减库存
如何解决超卖
5.3 redis分布式锁【Java 面试第三季】
- 使用redis的原子命令:decrement,先decrement(stock,amount),判断返回值<0,然后就回补库存increment(stock,amount)
但是是两个操作,没有原子性 - 使用lua脚本实现,先查询库存,再判断扣减库存
- 改为redis分布式锁,setnx,加锁来保证原子性,解锁时,先判断锁的归属,解锁(Lua脚本)
锁的过期时间和业务时间不好把控 - 使用redission分布式锁,锁的自动续期
使用redis的原子命令:decrement
//预扣库存//redisTemplate.opsForValue().decrement(key, amount);//售罄标识//redisTemplate.opsForValue().set("item:stock:over:" + itemId, 1);@Overridepublic boolean decreaseStockInCache(int itemId, int amount) {if (itemId <= 0 || amount <= 0) {throw new BusinessException(PARAMETER_ERROR, "参数不合法!");}String key = "item:stock:" + itemId;long result = redisTemplate.opsForValue().decrement(key, amount);if (result < 0) {// 回补库存this.increaseStockInCache(itemId, amount);logger.debug("回补库存完成 [" + itemId + "]");} else if (result == 0) {// 售罄标识redisTemplate.opsForValue().set("item:stock:over:" + itemId, 1);logger.debug("售罄标识完成 [" + itemId + "]");}return result >= 0;}在上述代码中,使用Redis的decrement操作来预扣库存。如果库存数量减为负数(result < 0),则说明库存不足,需要回补库存。如果库存数量减至0(result == 0),则设置售罄标识。
这段代码可以一定程度上缓解超卖问题,但并不能完全解决。在高并发场景下,多个线程可能会同时进行decrement操作,导致库存数量减为负数。
可以通过以下方式来进一步解决超卖问题:
使用悲观锁或乐观锁来保证同一时间只有一个线程能够进行decrement操作,避免超卖问题。
在decrement操作前,通过GET命令获取当前库存数量,然后进行判断。如果库存数量小于等于请求的数量,则不进行decrement操作,避免超卖问题。
使用Lua脚本来确保decrement操作的原子性,同时进行判断和减少库存数量,避免并发问题。
综上所述,单纯使用Redis的decrement操作无法完全解决超卖问题,需要结合其他策略来确保库存的准确性和一致性。
改成一个Lua脚本
//使用Lua脚本//得到stock//判断stock>amount//DECRBY stockKey, amount//SET stockOverKey, 1@Overridepublic boolean decreaseStockInCache(int itemId, int amount) {if (itemId <= 0 || amount <= 0) {throw new BusinessException(PARAMETER_ERROR, "参数不合法!");}String script = "local itemId = ARGV[1]\n" +"local amount = tonumber(ARGV[2])\n" +"local stockKey = \"item:stock:\" .. itemId\n" +"local stockOverKey = \"item:stock:over:\" .. itemId\n" +"local stock = tonumber(redis.call(\"GET\", stockKey))\n" +"if stock == nil or stock < amount then\n" +" return 0\n" +"else\n" +" local result = redis.call(\"DECRBY\", stockKey, amount)\n" +" if result == 0 then\n" +" redis.call(\"SET\", stockOverKey, 1)\n" +" end\n" +" return 1\n" +"end";List<String> keys = new ArrayList<>();keys.add("item:stock:" + itemId);keys.add("item:stock:over:" + itemId);Object result = redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), keys, itemId, amount);return result != null && (Long) result == 1;}
使用Lua脚本可以解决一些并发操作的问题,特别是在Redis中。由于Redis的单线程特性,执行Lua脚本可以保证原子性操作,并避免了多个命令的竞态条件。
在预扣库存的场景中,使用Lua脚本可以确保以下几点:
原子性操作:Lua脚本在Redis中被作为一个整体进行执行,中间不会被其他操作打断,从而保证了预扣库存操作的原子性。
避免超卖:通过在Lua脚本中检查库存数量,并在预扣成功后减少库存,可以避免超卖问题的发生。
但是需要注意的是,即使使用Lua脚本也不能完全解决所有并发问题。在高并发场景下,可能仍然存在一些问题,比如竞争条件和网络延迟等。因此,在实际应用中,还需要结合其他技术和策略来提高系统的并发性和可靠性,例如分布式锁、分布式事务等。
上述代码是一个使用Lua脚本来实现分布式锁和解决超卖问题的例子。具体步骤如下:
首先,定义了一个Lua脚本,脚本中包含了获取库存、检查库存是否足够、扣减库存和标记库存是否售罄的逻辑。
在Java代码中,通过RedisTemplate的execute方法来执行Lua脚本。在执行过程中,需要传入脚本、键列表和参数。
脚本:使用DefaultRedisScript指定脚本和返回值类型。
键列表:包含了需要操作的键,这里是"item:stock:“+itemId和"item:stock:over:”+itemId。
参数:itemId和amount,即商品ID和购买数量。
执行结果返回一个Object对象,需要根据具体业务逻辑进行判断。这里判断如果返回的结果不为空,且结果等于1,表示扣减库存成功;否则表示库存不足或者其他错误。
需要注意的是,在实际应用中,还需要考虑到异常处理、分布式锁的释放、并发情况下的处理等问题。此处的代码只是一个简化的示例,具体的实现方式需要根据具体业务需求和实际情况进行调整和完善。
redis分布式锁实现
//1.定义一个公共的方法来获取分布式锁。private boolean acquireLock(String lockKey, String requestId, int expireTime) {boolean lockAcquired = false;try {lockAcquired = redisTemplate.opsForValue().setIfAbsent(lockKey, requestId, expireTime, TimeUnit.MILLISECONDS);logger.info("获取分布式锁成功");} catch (Exception e) {// 锁获取失败的处理逻辑logger.info("获取分布式锁失败");return false;}return lockAcquired;}//2.在方法中添加获取分布式锁的逻辑。@Overridepublic boolean decreaseStockInCache(int itemId, int amount) {if (itemId <= 0 || amount <= 0) {throw new BusinessException(PARAMETER_ERROR, "参数不合法!");}String lockKey = "item:lock:" + itemId;String requestId = UUID.randomUUID().toString();int expireTime = 10000; // 锁的过期时间,单位为毫秒boolean lockAcquired = acquireLock(lockKey, requestId, expireTime);if (!lockAcquired) {// 获取锁失败的处理逻辑logger.info("获取分布式锁失败");return false;}try {// 执行库存扣减的逻辑String script = "local itemId = ARGV[1]\n" +"local amount = tonumber(ARGV[2])\n" +"local stockKey = \"item:stock:\" .. itemId\n" +"local stockOverKey = \"item:stock:over:\" .. itemId\n" +"local stock = tonumber(redis.call(\"GET\", stockKey))\n" +"if stock == nil or stock < amount then\n" +" return 0\n" +"else\n" +" local result = redis.call(\"DECRBY\", stockKey, amount)\n" +" if result == 0 then\n" +" redis.call(\"SET\", stockOverKey, 1)\n" +" end\n" +" return 1\n" +"end";List<String> keys = new ArrayList<>();keys.add("item:stock:" + itemId);keys.add("item:stock:over:" + itemId);Object result = redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), keys, itemId, amount);return result != null && (Long) result == 1;} finally {// 释放锁boolean releaseLock = releaseLock(lockKey, requestId);if (releaseLock){logger.info("释放分布式锁成功");}else {logger.info("释放分布式锁失败");}}}//3.定义一个公共的方法来释放分布式锁。private boolean releaseLock(String lockKey, String requestId) {String script = "if redis.call('get', KEYS[1]) == ARGV[1] then " +" return redis.call('del', KEYS[1]) " +"else " +" return 1 " +"end";List<String> keys = new ArrayList<>();keys.add(lockKey);Object result = redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), keys, requestId);return result != null && (Long) result == 1;}怎么合理地设置分布式锁的过期时间
上面设置了10s
需要确保RedisLock过期时间大于业务执行时间的问题
设置分布式锁的过期时间是否合理取决于你的具体需求和业务场景。一般来说,过期时间需要根据以下因素进行考虑:
业务处理时间:你需要根据业务处理的预估时间来设置过期时间。如果你的业务处理时间通常在几秒钟内完成,可以设置一个稍微长一点的过期时间,以免在处理期间锁已经过期失效。
并发访问量:如果同时对某个资源进行大量的并发操作,你可能需要更短的过期时间,以便尽快释放锁,让其他请求能够获得锁。
锁争用频率:如果对某个资源的锁争用频率很高,建议设置较短的过期时间,以便其他请求能够更快地获取到锁。
根据你的描述,如果你的业务处理时间在几秒钟内,而且对资源的锁争用频率不是特别高,10秒的过期时间可能是一个合理的选择。但请注意,在实际应用中,你可能需要根据实际情况进行调试和优化,以找到最适合你的业务场景的过期时间设置。
Redisson
<!-- redisson --><dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.13.4</version></dependency>
@Configuration
@PropertySource("classpath:application.properties")
public class RedisConfiguration {@Autowiredprivate Environment env;@Beanpublic Redisson redisson() {Config config = new Config();String redisHost = env.getProperty("spring.redis.host");String redisPort = env.getProperty("spring.redis.port");String redisPassword = env.getProperty("spring.redis.password");int redisDatabaseNumber = env.getProperty("spring.redis.database", Integer.class, 0);String redisAddress = "redis://" + redisHost + ":" + redisPort;config.useSingleServer().setAddress(redisAddress).setPassword(redisPassword).setDatabase(redisDatabaseNumber);return (Redisson)Redisson.create(config);}
}
@Overridepublic boolean decreaseStockInCache(int itemId, int amount) {if (itemId <= 0 || amount <= 0) {throw new BusinessException(PARAMETER_ERROR, "参数不合法!");}String lockKey = "item:lock:" + itemId;String REDIS_LOCK = lockKey+":"+UUID.randomUUID().toString();RLock redissonLock = redisson.getLock(REDIS_LOCK);redissonLock.lock();logger.debug("redissonLock加锁成功");try {// 执行库存扣减的逻辑String script = "local itemId = ARGV[1]\n" +"local amount = tonumber(ARGV[2])\n" +"local stockKey = \"item:stock:\" .. itemId\n" +"local stockOverKey = \"item:stock:over:\" .. itemId\n" +"local stock = tonumber(redis.call(\"GET\", stockKey))\n" +"if stock == nil or stock < amount then\n" +" return 0\n" +"else\n" +" local result = redis.call(\"DECRBY\", stockKey, amount)\n" +" if result == 0 then\n" +" redis.call(\"SET\", stockOverKey, 1)\n" +" end\n" +" return 1\n" +"end";List<String> keys = new ArrayList<>();keys.add("item:stock:" + itemId);keys.add("item:stock:over:" + itemId);Object result = redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), keys, itemId, amount);logger.debug("执行库存扣减的逻辑成功");return result != null && (Long) result == 1;} finally {// 释放锁//避免IllegalMonitorStateException: attempt to unlock lock,not locked by current thread by node idif (redissonLock.isLocked()){if (redissonLock.isHeldByCurrentThread()){redissonLock.unlock();logger.debug("redissonLock释放成功");}}}}在上述代码中,通过使用分布式锁确保了库存扣减的原子性操作,从而避免了多线程环境下的超卖问题。当多个线程同时执行库存扣减操作时,只有一个线程能够获取到锁,其他线程会在redissonLock.lock()处阻塞等待。
在获取到锁后,通过Lua脚本执行库存扣减的逻辑,并且使用DECRBY命令原子性地减少库存数量。如果库存不足,返回0表示扣减失败,否则返回1表示扣减成功。在扣减成功后,通过SET命令将标识库存已售罄的键设置为1。
这种方式可以有效地解决超卖问题。但是需要注意的是,使用分布式锁会增加系统的复杂性和延迟,并且需要保证Redis服务器的可用性和性能。因此,在设计系统时需要权衡分布式锁的使用场景和影响,确保在高并发环境下依然能够保持系统的稳定性和性能。
另外,除了使用分布式锁来解决超卖问题,还可以考虑其他方案,如使用乐观锁或悲观锁、使用消息队列等。具体选择哪种方案取决于系统的需求和特点。
2023-8-17 17:14:14
redisson分布式锁的原理
Redisson是一个基于Redis的分布式Java对象和服务库,它提供了多种分布式功能,包括分布式锁。Redisson的分布式锁机制主要基于Redis的特性和命令实现。
Redisson分布式锁的原理如下:
客户端通过Redisson框架的API请求获取锁。
Redisson将客户端的请求转化为Lua脚本,并通过eval命令发送给Redis服务器。
Redis服务器在单线程下执行Lua脚本,保证了脚本的原子性和线程安全性。
Lua脚本在Redis服务器中执行以下操作:
- 首先,通过SET命令尝试将锁对应的键设置为指定值(通常是一个唯一标识符)。
- 如果设置成功,则表示获取锁成功,返回成功标识。
- 如果设置失败,则表示锁已被其他客户端占用,返回失败标识。
- 同时,设置锁的过期时间,防止锁无限占用。
- Redisson客户端接收到Redis服务器返回的结果,根据结果判断锁的获取是否成功,如果成功则继续执行业务逻辑,否则等待或进行其他处理。
- Redisson的分布式锁实现利用了Redis的原子操作,通过设置指定的值来实现锁的获取和释放。同时,使用Lua脚本可以保证获取锁的操作是原子的,避免了竞争条件和并发问题。
需要注意的是,Redisson的分布式锁还具备可重入性和红锁特性,使得锁的使用更加灵活和可靠。
redisson分布式锁比setnx有什么优势?
Redisson分布式锁相对于直接使用SETNX命令实现分布式锁具有以下几个优势:
-
可重入性:Redisson分布式锁支持可重入,也就是同一线程可以多次获取同一个锁而不会被阻塞。这种可重入性能够解决一些特定场景下的并发问题。
-
锁的自动续期:Redisson分布式锁支持锁的自动续期,即在获取锁后,锁的过期时间会不断更新,防止持有锁的客户端在执行业务逻辑时由于各种原因导致锁过期而被其他客户端抢占。
-
防止死锁的解锁机制:Redisson分布式锁通过监听锁的失效事件来实现解锁操作,避免了因为客户端崩溃或其他原因导致的锁无法释放的情况。
-
红锁特性:Redisson分布式锁支持红锁特性,即在多个Redis节点之间实现锁的互斥。当多个Redis节点之间进行通信时,可以使用分布式锁的红锁特性保证在大多数节点上加锁成功才算真正获取到锁,避免了分布式环境下的数据不一致问题。
-
强大的扩展性:Redisson分布式锁是基于Redisson框架的分布式Java对象和服务库实现的,提供了很多其他功能和特性,如分布式服务、分布式集合等。使用Redisson分布式锁可以很方便地与其他分布式功能进行集成和扩展。
综上所述,Redisson分布式锁相比于直接使用SETNX命令实现分布式锁,具有更多的功能和特性,可以更方便地应对分布式环境中的并发和竞争问题。
其他问题
本地缓存
浅析本地缓存技术-Guava Cache | 京东物流技术团队
Guava Cache
RateLimiter
线程池
RocketMQ的事务消息的好处
RocketMQ的事务消息具有以下几个好处:
-
数据一致性:事务消息可以确保数据在生产者和消费者之间的一致性。在发送事务消息时,生产者先发送预提交消息,然后执行本地事务。一旦本地事务执行成功,生产者发送确认消息,否则发送回滚消息。消费者在接收到确认消息后才会消费事务消息,确保了数据的一致性。
-
高可靠性:事务消息通过两阶段提交的方式来保证消息的可靠性。在发送阶段,消息会被写入到消息存储中,确保消息的可靠性。在确认阶段,消费者只有在接收到确认消息后才会消费事务消息,避免了消息的丢失。
-
高吞吐量:RocketMQ的事务消息通过异步方式执行本地事务,减少了事务执行的时间,提高了系统的吞吐量。在发送事务消息后,生产者可以继续发送其他事务消息,不需要等待本地事务的执行结果。
-
事务状态查询:RocketMQ提供了事务状态查询的功能,可以查询事务消息的状态,包括事务消息的提交状态和回滚状态。这对于排查问题、监控和管理事务消息非常有帮助。
-
容错机制:RocketMQ的事务消息具有容错机制,当消息发送过程中发生异常或者网络故障时,可以通过重试机制来重发事务消息,确保消息的送达。
总而言之,RocketMQ的事务消息提供了一种可靠、高效的消息传递方式,可以确保数据的一致性和可靠性。同时,提供了事务状态查询的功能,方便进行事务消息的管理和监控。
RocketMQ重试机制
RocketMQ的重试机制是指在消息发送过程中,如果发生异常或网络故障导致消息发送失败,RocketMQ会进行自动的重试。重试机制有两个方面的含义:生产者重试和消费者重试。
-
生产者重试:当生产者发送消息失败时,RocketMQ会自动进行重试。重试的次数和时间间隔可以通过配置参数进行设置。如果在重试次数内发送成功,则消息会被成功发送到Broker;如果达到重试次数后仍然失败,则消息发送失败。
-
消费者重试:当消费者消费消息失败时,RocketMQ会自动进行重试。消费者的重试机制可以通过设置消费模式和消费进度进行控制。在集群消费模式下,如果一个消费者消费消息失败,RocketMQ会将该消息重新发送给其他消费者进行消费。在广播消费模式下,如果一个消费者消费消息失败,RocketMQ会将该消息重新发送给该消费者进行重试。
重试机制在RocketMQ中起到了非常重要的作用,它可以在一定程度上提高消息的可靠性。通过自动的重试机制,RocketMQ可以尽量保证消息的成功发送和消费,减少消息的丢失和重复消费的可能性。同时,重试机制也可以提高系统的吞吐量,降低了因消息发送或消费失败而导致的性能损失。
分布式ID
Leaf——美团点评分布式ID生成系统
我的订单ID 的设计
数据库生成的,
8位的日期+12位的序号
序号的获取是有一个序号表
记录它的业务名,值,以及步长
另外可以多加几列字段,(服务器流水号、用户尾号)
事务:@Transactional(propagation = Propagation.REQUIRES_NEW)
先获取流水号
再更新流水号
select for update保证ID
事务:@Transactional
生成订单的时候
如果回滚了,就会浪费一个订单号
UUID
类snowflake方案
数据库生成
自增主键
Leaf方案实现
Leaf-segment数据库方案
第一种Leaf-segment方案,在使用数据库的方案上,做了如下改变: - 原方案每次获取ID都得读写一次数据库,造成数据库压力大。改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。 - 各个业务不同的发号需求用biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
数据库表设计如下:
+-------------+--------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+-------------------+-----------------------------+
| biz_tag | varchar(128) | NO | PRI | | |
| max_id | bigint(20) | NO | | 1 | |
| step | int(11) | NO | | NULL | |
| desc | varchar(256) | YES | | NULL | |
| update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+-------------+--------------+------+-----+-------------------+-----------------------------+
重要字段说明:biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step,大致架构如下图所示:
重要字段说明:biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step,大致架构如下图所示:
缓存相关的问题
缓存和数据库的一致性
先更新数据库再删除缓存
库存的一致性是mq实现事务消息
缓存穿透
场景:
场景查询根本不存在的数据,使得请求直达存储层
导致其负载过大,甚至宕机。
解决方案:
1.缓存空对象存储层未命中后,仍然将空值存入缓存层。再次访问该数据时,缓存层会直接返回空值。
2.布隆过滤器将所有存在的key提前存入布隆过滤器,在访问缓存层之前,先通过过滤器拦截,若请求的是不存在的key,则直接返回空值。
缓存击穿
场景:
一份热点数据,它的访问量非常大。在其缓存失效瞬间,大量请求直达存储层,导致服务崩溃。
解决方案:
1.加互斥锁对数据的访问加互斥锁,当一个线程访问该数据时,其他线程只能等待。这个线程访问过后,缓存中的数据将被重建,届时其他线程就可以直接从缓存取值。
2.永不过期不设置过期时间,所以不会出现上述问题,这是“物理”上的不过期。为每个value设置逻辑过期时间,当发现该值逻辑过期时,使用单独的线程重建缓存。
缓存雪崩
场景:
由于某些原因,缓存层不能提供服务,导致所有的请求直达存储层,造成存储层宕机。
解决方案:
1.避免同时过期设置过期时间时,附加一个随机数,避免大量的key同时过期。
2.构建高可用的Redis缓存部署多个Redis实例,个别节点宕机,依然可以保持服务的整体可用。
3.构建多级缓存增加本地缓存,在存储层前面多加一级屏障,降低请求直达存储层的几率。
4.启用限流和降级措施对存储层增加限流措施,当请求超出限制时,对其提供降级服务。
3种缓存更新策略是怎样的?
面试官:3种缓存更新策略是怎样的?
Cache Aside(旁路缓存)策略是最常用的,应用程序直接与「数据库、缓存」交互,并负责对缓存的维护,该策略又可以细分为「读策略」和「写策略」。

Read/Write Through(读穿 / 写穿)策略原则是应用程序只和缓存交互,不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了。
下面是 Read Through/Write Through 策略的示意图:

Write Back(写回)策略在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行。
实际上,Write Back(写回)策略也不能应用到我们常用的数据库和缓存的场景中,因为 Redis 并没有异步更新数据库的功能。

面经
快手 秋招 Java 一二面(凉经 已自闭)
消息堆积解决方案
消息堆积是指系统在处理消息时,由于资源不足或处理速度不够快,导致消息积压在系统中未能及时处理的情况。解决消息堆积的方案可以从以下几个方面考虑:
增加资源:增加系统的处理能力,例如增加服务器的数量、提升硬件性能、优化网络带宽等。通过增加资源,可以提高系统的处理速度,减少消息堆积的可能性。
异步处理:将消息的处理过程异步化,通过将消息放入消息队列或消息中间件中进行处理。异步处理可以将消息的处理与消息的产生解耦,提高系统的并发能力,减少消息堆积的风险。
调整消息消费速度:根据系统的实际情况,调整消息的消费速度,使得消费速度能够与消息的产生速度保持一定的平衡。可以通过调整消费者的线程数、消费者的处理逻辑等方式来控制消息的消费速度。
设置消息过期时间:对于一些不重要或过期的消息,可以设置消息的过期时间,超过一定时间后自动丢弃。通过设置消息的过期时间,可以避免消息堆积过多,减少系统的负载。
监控和报警机制:建立监控系统,实时监测消息的积压情况,并设置报警机制,及时通知相关人员进行处理。通过监控和报警机制,可以及时发现并解决消息堆积问题,避免对系统的影响。
数据分片和分布式处理:对于大规模的消息堆积问题,可以考虑使用数据分片和分布式处理的方式来解决。将消息分片存储在不同的节点上,并利用分布式处理框架进行并行处理,以提高系统的处理能力和效率。
综上所述,通过增加资源、异步处理、调整消息消费速度、设置消息过期时间、监控和报警机制以及数据分片和分布式处理等方案,可以有效地解决消息堆积问题,提高系统的性能和稳定性。
消息发送、消费过程
消息发送和消费是一种常见的消息通信模式,通常用于分布式系统或异步任务处理。下面是消息发送和消费的一般过程:
消息发送过程:
a. 发送者创建消息,并将消息发送到消息队列或消息中间件。消息可以包含不同的数据,例如文本、JSON、二进制等。
b. 发送者指定目标消息队列或主题,以确定消息的接收者。
c. 发送者将消息发送到消息队列或消息中间件。消息队列可以是一种存储和转发消息的中间件,确保消息的可靠分发。
消息消费过程:
a. 消费者订阅或注册对特定消息队列或主题的监听。这样,消费者就可以接收到该队列或主题中的消息。
b. 当有消息到达消息队列或主题时,消费者会收到通知。
c. 消费者从消息队列或主题中获取消息,并进行处理。处理包括执行业务逻辑、数据处理、状态更新等操作。
d. 消费者可以发送确认消息给消息队列或主题,表示已成功消费该消息。确认消息的发送可以触发消息队列的删除操作,或标记消息为已消费状态。
在消息发送和消费的过程中,还可以根据实际需求使用一些高级特性,例如消息过滤、消息优先级、消息延时等。这些特性可以根据业务需求进行配置和使用,以满足系统的具体要求。
需要注意的是,消息发送和消费过程中可能会出现异常情况,例如网络故障、消息丢失、消息重复等。因此,在设计和实现消息发送和消费系统时,需要考虑到这些异常情况,并采取相应的容错和恢复机制,以确保消息的可靠传递和处理。
消息一致性 不可重复性(以RabbitMQ角度来阐述的)
Kafka和RocketMQ都提供了消息一致性和不可重复性的保证,但它们采用了不同的实现方式。
消息一致性:
Kafka:Kafka使用分布式提交日志的方式来实现消息一致性。它将所有的消息写入到持久化的日志中,并通过分区和副本机制来确保消息的可靠性和一致性。当消息被写入到多个副本中并且被确认提交后,才认为消息被成功处理。
RocketMQ:RocketMQ使用主从复制的方式来实现消息一致性。消息发送到Master节点,并通过同步或异步方式复制到多个Slave节点。当Master节点收到所有Slave节点的确认后,才认为消息被成功处理。
不可重复性:
Kafka:Kafka通过给每个消息分配唯一的偏移量来保证消息的不可重复性。消费者在消费消息时,根据偏移量来确保每条消息只被处理一次。
RocketMQ:RocketMQ通过给每个消息分配唯一的Message ID来保证消息的不可重复性。消费者在消费消息时,根据Message ID来确保每条消息只被处理一次。
总的来说,Kafka和RocketMQ都可以提供消息的一致性和不可重复性保证,但在实现细节上有所不同。选择哪个系统取决于具体的使用需求和场景。
如果ack丢了,会有重复消息吗(重试 幂等)
如果消息的确认(ack)丢失,可能会导致消息的重复传递。这是因为当消息发送者收到消息的确认时,会假设消息已经成功传递并删除消息的本地副本。如果确认消息丢失,发送者会重新发送相同的消息,可能导致消息的重复传递。
为了解决这个问题,通常可以采取以下两种方式来保证消息不会重复传递:
幂等性:消息的幂等性是指对于同一条消息的重复传递,最终的结果是一致的。这意味着即使同一条消息被多次传递,最终的处理结果不会受到影响。在消费者端,可以通过设计幂等的消费逻辑来保证消息的幂等性。
重试机制:当消息的确认丢失时,发送者可以设置重试机制来重新发送丢失的消息。在接收端,可以通过幂等性来保证即使同一条消息被重复发送,最终的结果也是一致的。同时,接收端可以在处理消息时检测是否已经处理过相同的消息,避免对重复消息的重复处理。
需要注意的是,重试机制和幂等性并不能完全消除重复消息的可能性,但可以在很大程度上减少重复消息的发生。为了进一步提高消息系统的可靠性,通常还需要考虑其他因素,如消息的唯一标识、消息的去重策略等。
刚才讲的是消费端的处理策略,生产端的处理策略是什么,怎么保障消息能发出去,不丢失?
生产端的处理策略可以通过以下几个方面来保证消息能够成功发出,不丢失:
可靠的消息发送:生产端可以采用可靠的消息发送机制,例如使用消息队列或消息中间件来发送消息。这些消息系统通常具有持久化机制,会将消息存储在可靠的存储介质中,确保即使系统宕机或网络中断,消息也能够被保留下来,不会丢失。
批量发送:为了提高消息发送的效率,可以将多个消息批量发送到消息队列或消息中间件中,而不是每条消息都进行单独发送。批量发送可以减少网络开销和资源消耗,并且减少了消息丢失的风险。
异步发送与确认:生产端可以采用异步发送消息的方式,即发送消息后不需要等待确认结果,而是立即返回。同时,生产端可以通过接收到的确认消息来判断消息是否成功发送,如果没有收到确认消息,可以进行重试或记录错误信息,以确保消息的可靠发送。
重试机制:在消息发送过程中,如果发生网络故障或其他异常情况,生产端可以设置重试机制来重新发送消息。重试机制可以通过设定重试次数和间隔时间来进行配置,以确保消息最终能够成功发送出去。
消息的持久化:为了避免消息在发送过程中丢失,可以将消息进行持久化处理,即将消息保存到持久化存储中,例如数据库或文件系统。这样即使在发送过程中出现故障,消息也可以从持久化存储中进行恢复,确保消息的可靠性。
需要注意的是,即使采取了上述策略,由于网络故障、系统故障等不可控因素,仍然存在消息发送丢失的风险。因此,在设计和实现消息系统时,需要综合考虑多种策略,以提高消息的可靠性和稳定性。
正常消息队列的消息都是能正常发送的,在极端情况下消息队列的消息才会发不出去,对于消息队列来说有必要消耗一些性能对每一个消息做反查吗?
对于消息队列来说,在正常情况下,大部分消息是能够正常发送的。然而,在极端情况下,例如网络故障、硬件故障或消息队列系统自身的问题等,仍然存在消息发送失败的可能性。
针对这种情况,是否对每个消息都进行反查需要综合考虑以下几个因素:
可靠性需求:如果系统对消息的可靠性要求非常高,不能容忍任何消息丢失,那么对每个消息都进行反查是一个可行的选择。通过反查,可以确保每个消息都能够成功发送出去,从而提高系统的可靠性。然而,这会对系统性能造成一定的影响,因为每个消息都需要进行反查操作。
性能考虑:反查每个消息会带来一定的性能消耗,包括网络开销、系统资源消耗等。如果系统对性能要求较高,需要尽量减少不必要的操作,那么可以考虑在极端情况下进行反查,而在正常情况下不进行反查。
容错机制:除了反查每个消息外,还可以通过其他容错机制来保障消息的可靠发送。例如,可以配置消息队列的重试策略,当消息发送失败时进行自动重试;或者使用消息队列的持久化功能,将消息保存在可靠的存储介质中,确保即使在发送过程中出现故障,消息也能够被保留下来。
综上所述,是否对每个消息进行反查需要根据具体的业务需求和系统性能要求来决定。在选择时需要权衡可靠性和性能之间的关系,以找到适合系统的最佳方案。
有用过其他的消息队列吗
RocketMQ
讲讲RocketMQ事务消息的发送过程
RocketMQ是一款分布式消息队列系统,支持事务消息的发送和处理。下面是RocketMQ事务消息的发送过程:
发送方发送事务消息:发送方应用程序首先发送一条预备消息(Half Message),消息状态为“预发送”状态。在消息中包含业务数据和事务ID。
RocketMQ事务协调器进行执行和确认:RocketMQ事务协调器由RocketMQ提供,作为一个独立的服务运行。事务协调器接收到预备消息后,执行对应的本地事务操作。事务协调器执行结果有两种可能:
成功执行:如果本地事务操作成功,事务协调器会发送一条确认消息(Commit Message),消息状态为“已提交”状态。
执行失败:如果本地事务操作失败,事务协调器会发送一条回滚消息(Rollback Message),消息状态为“已回滚”状态。
发送方确认事务状态:发送方应用程序接收到事务协调器发送的确认消息或回滚消息后,根据消息的状态进行相应的处理。
如果接收到的是确认消息,发送方继续发送消息,并将消息状态更新为“已提交”状态。
如果接收到的是回滚消息,发送方不再发送消息,并将消息状态更新为“已回滚”状态。
消费方消费消息:消费方应用程序从RocketMQ消费消息,并根据消息的状态进行相应的业务处理。
通过上述过程,RocketMQ事务消息的发送方可以在发送消息时保证消息的可靠性,同时事务协调器能够支持消息事务的执行和确认,确保消息的最终一致性。消费方可以根据消息的状态进行相应的业务逻辑处理,保证消息处理的正确性。
Caffeine的实现原理
Caffeine是一个高性能的Java缓存库,它提供了类似于Guava的CacheBuilder的功能。下面是Caffeine的一些关键实现原理:
数据结构:Caffeine使用了一种称为"强连通哈希表"的数据结构。这个数据结构是一个特殊的哈希表,它能够快速定位和访问缓存中的键值对,同时支持高并发的读写操作。
缓存策略:Caffeine使用了一种淘汰策略,称为"最近不经常使用"(Least Recently Used,LRU)。在LRU策略下,当缓存空间不足时,Caffeine会移除最近最少使用的键值对,以腾出空间给新的键值对。
弱引用和软引用:Caffeine还使用了弱引用和软引用来管理缓存中的键和值。弱引用在内存不足时会被垃圾回收器回收,而软引用则会尽量保留,直到内存真正不足时才会被回收。这样一来,在内存紧张的情况下,Caffeine可以及时释放不再使用的缓存对象,以优化内存使用。
并发控制:Caffeine使用了一些并发控制技术来保证多线程安全。例如,它使用了锁分段(lock striping)来允许多个线程并发地访问不同的缓存段,从而提高并发性能。
异步加载:Caffeine还支持异步加载缓存项。当缓存中不存在某个键对应的值时,Caffeine可以调用用户提供的异步加载函数来加载该值,而不是阻塞线程等待加载完成。这样可以避免因为加载操作而导致的性能瓶颈。
总体来说,Caffeine通过使用高效的数据结构、缓存策略、引用管理和并发控制等技术,实现了高性能和高并发的缓存功能。它在许多场景下都比传统的HashMap或ConcurrentHashMap更加高效和灵活。
Guava的LoadingCache和ReloadableCache(没了解过)
Guava是一个Google开发的Java工具包,其中包含了许多实用的功能和库。在Guava中,有两个与缓存相关的类:LoadingCache和ReloadableCache。
-
LoadingCache:LoadingCache是Guava提供的一个接口,用于构建带有自动加载功能的缓存。它有以下特点:
- 自动加载:当缓存中不存在某个键对应的值时,LoadingCache会自动调用用户提供的加载函数来加载该值,并将其放入缓存中。
- 缓存过期:LoadingCache可以基于时间、大小或其他条件来设置缓存项的过期策略。一旦缓存项过期,下一次访问该项时将重新加载该值。
- 并发支持:LoadingCache使用并发数据结构来支持高并发的读写操作,保证多线程环境下的线程安全性。
- 缓存统计:LoadingCache可以提供缓存的统计信息,如击中率、加载次数、缓存命中率等。
-
ReloadableCache:ReloadableCache是Guava新增的一个实验性缓存类,用于构建可重载的缓存。它有以下特点:
- 可重载:ReloadableCache允许使用者在缓存项过期后,通过自定义的重新加载函数来重新加载缓存项的值。这样可以避免缓存项过期后的热点请求导致的性能问题。
- 异步加载:ReloadableCache支持通过异步方式重新加载缓存项的值,避免阻塞线程等待重新加载完成。
- 缓存过期:ReloadableCache可以基于时间、大小或其他条件来设置缓存项的过期策略,以及重新加载策略。
需要注意的是,ReloadableCache是Guava中的一个实验性特性,它可能在未来的版本中有改动或移除。因此,在使用ReloadableCache时需要谨慎考虑其稳定性和可靠性。
希望这个解释对你有帮助。如有其他问题,请随时提问。
Kafka、RocketMQ、RabbitMQ的区别
Kafka、RocketMQ和RabbitMQ是目前非常流行的消息队列中间件。下面是它们之间的一些比较:
-
性能和吞吐量:
- Kafka:Kafka注重高性能和高吞吐量,适用于大数据量、高并发的场景。
- RocketMQ:RocketMQ具有较高的吞吐量和低延迟,适用于大规模分布式系统的消息通信。
- RabbitMQ:RabbitMQ是一个功能丰富的消息队列中间件,注重可靠性和灵活性。
-
消息持久化:
- Kafka:Kafka将消息持久化到日志文件中,可以将消息保存一段时间,支持高可靠性和数据持久化。
- RocketMQ:RocketMQ也将消息持久化到磁盘上,可以保证消息的持久性和可靠性。
- RabbitMQ:RabbitMQ将消息保存在内存中,对于持久化消息需要额外的配置。
-
分布式支持:
- Kafka:Kafka支持分布式部署,具有高可用性和扩展性。
- RocketMQ:RocketMQ是为分布式场景设计的,支持分布式部署和多个消费者组。
- RabbitMQ:RabbitMQ也支持分布式部署,但在大规模集群上的扩展性相对较弱。
-
消息顺序性:
- Kafka:Kafka保证单个分区内的消息是有序的,但多个分区之间的消息可能是无序的。
- RocketMQ:RocketMQ在分区内和分区间都保证消息的顺序性。
- RabbitMQ:RabbitMQ可以通过单一队列和顺序消费者来实现有序消息。
-
社区和生态系统:
- Kafka:Kafka有非常活跃的社区和庞大的生态系统,有丰富的第三方工具和库可供使用。
- RocketMQ:RocketMQ的社区相对较小,但仍在不断发展中,生态系统较为成熟。
- RabbitMQ:RabbitMQ是一个成熟的消息中间件,拥有庞大的社区和丰富的生态系统。
选择适合的消息队列中间件取决于具体的需求和场景。如果需要高性能和高吞吐量,推荐使用Kafka或RocketMQ;如果注重可靠性和灵活性,推荐使用RabbitMQ。
MQ
Kafka如何保证消息不丢失
【Java每日一题】Kafka如何保证消息不丢失的?
Kafka是一个用来实现异步消息通讯的一个中间件
它的整个架构是由Producer、Consumer和Broker组成
所以对于Kafka如何保证消息不丢失的这个问题,可以从三个方面考虑和实现
首先是Producer端,确保消息能够到达Broker端,并且实现消息的存储
在这个层面上有可能会出现网络问题,导致消息发送失败,
所以能针对Producer端可以通过两种方法来避免消息的丢失
第一个,Producer默认是异步发送消息的,那么这种情况下要确保消息是发送成功的
那么这里面有两个方法
1把异步发送改成同步发送,这样producer就能实时知道消息发送的结果
2添加异步回调函数来监听消息发送的结果。如果发送失败。可以在回调中重试
第二个,Producer本事提供一个重试参数,叫retries,
如果因为网络问题或者Broker端故障导致发送失败,那么Producer会自动重试
然后是Broker端,Broker端需要确保Producer发送过来消息是不会丢失的,也就是说只要去把这个消息持久化到磁盘就可以了
但是Kafka为了提升性能采用了异步批量刷盘的实现机制,也就是说,按照一定的消息量和时间间隔去刷盘
而最终刷新到磁盘这个动作,是由操作系统来调度的,所以如果在刷盘之前系统崩溃了,就会导致数据的丢失
Kafka并没有提供同步刷盘的一个实现机制,所以针对这个问题
需要通过Partition的副本机制和acks机制来解决
我简单说一下Partition副本机制,它是针对每个数据分区的高可用策略
每个Partition副本集,会包含唯一的一个Leader和多个Follower
Leader专门处理事务类型的请求,而Follower负责同步Leader的数据
那么在这样一个机制的基础上呢,Kafka提供了一个acks的参数,
Producer可以去设置acks参数,去结合Broker的副本机制来共同保证数据的可靠性
acks这个参数的值呢有几个选择
第一个是acks=0,表示Producer不需要等待Broker的响应,就认为消息就发送成功了,那么这种情况下会存在消息丢失
第二个是acks=1,表示Broker中的Leader Partition,受到消息之后,不等待其他的Follower Partition的同步,就给Producer返回了一个确认。这种情况下,假设Leader Partition挂了,就会存在数据丢失,
第二个是acks=-1,表示Broker中的Leader Partition,受到消息之后,并且等待ISR列表中的所有Follower同步完成,在去给Producer返回了一个确认。这样的一个配置是可以保证数据的一个可靠性的。
最后,就是Consumer端,必须要能够消费的这个消息,
实际上我认为,只要Producer和Broker端的消息可靠性得到保障,那么消费端是不太可能出现消息无法消费的问题的。除非是Consumer没有消费完这个消息,就已经提交了这样offset。但是即便是出现这样一个情况,我们也可以通过重新调整offset的值,来实现重新消费
以上就是我对于这个问题的理解。