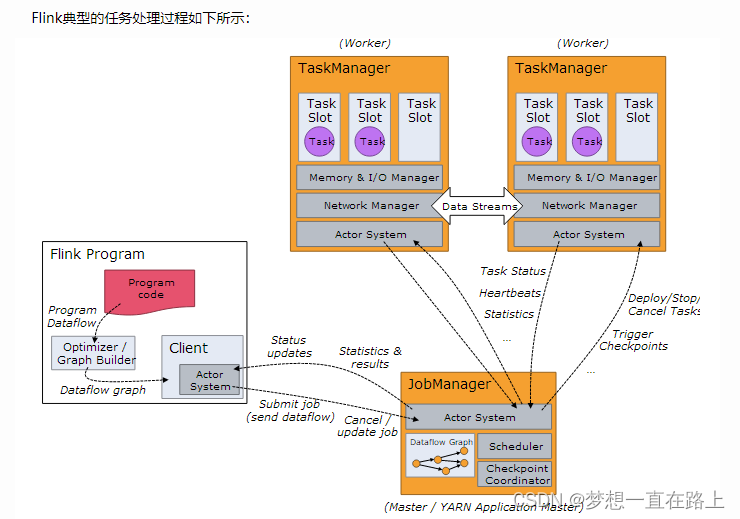
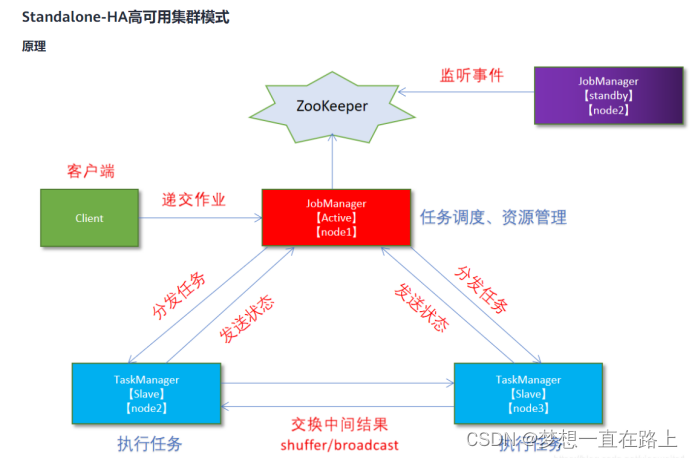
obManager存在单点故障(SPOF:Single Point Of Failure),因此对Flink做HA,主要是对JobManager做HA,根据Flink集群的部署模式不同,分为Standalone、OnYarn,本文主要涉及Standalone模式。
JobManager的HA,是通过Zookeeper实现的,因此需要先搭建好Zookeeper集群,同时HA的信息,还要存储在HDFS中,因此也需要Hadoop集群,最后修改Flink中的配置文件。
Flink 高可用之StandAlone-HA模式
压缩包:
tar -xvzf flink-1.9.1-bin-scala_2.11.tgz -C /opt && cd /opt/flink-1.9.1
集群规划:
1.集群规划
- - 服务器: node1(Master + Slave): JobManager + TaskManager
- - 服务器: node2(Master + Slave): JobManager + TaskManager
- - 服务器: node3(Slave): TaskManager
- 、修改flink-conf.yaml
jobmanager.rpc.port: 6123
jobmanager.bind-host: 0.0.0.0
jobmanager.memory.process.size: 3600m
taskmanager.bind-host: 0.0.0.0
taskmanager.host: 10.100.175.90
taskmanager.numberOfTaskSlots: 64
taskmanager.memory.jvm-metaspace.size: 3G
high-availability.type: zookeeper
high-availability.storageDir: hdfs://xxx:8020/flink-1.18/ha/
high-availability.zookeeper.quorum: xxx:2181,xxx:2181,xxx:2181
# high-availability.zookeeper.client.acl: open
high-availability.zookeeper.path.root: /flink
state.checkpoints.dir: hdfs://xxx.76:8020/flink-1.18/flink-checkpoints
state.savepoints.dir: hdfs://xxx.76:8020/flink-1.18/flink-savepoints
jobmanager.execution.failover-strategy: region
rest.port: 8081
rest.address: 0.0.0.0
rest.bind-address: 0.0.0.0
jobmanager.archive.fs.dir: hdfs://xxx:8020/flink-1.18/completed-jobs/
historyserver.archive.fs.dir: hdfs://xxx:8020/flink-1.18/completed-jobs/
restart-strategy: none
#开启HA,使用文件系统作为快照存储
state.backend: filesystem
#启用检查点,可以将快照保存到HDFS
state.checkpoints.dir:hdfs://server2:8020/flink-checkpoints
#使用zookeeper搭建高可用
high-availability: zookeeper
#存储JobManager的元数据到HDFS
high-availability.storageDir: hdfs://server2:8020/flink/ha/
#配置ZK集群地址
high-availability.zookeeper.quorum: server1:2118,server2:2118,server3:2118
2)、修改masters
vim /usr/local/flink-1.13.5/conf/masters
server1:8081
server2:8081
修改完后,使用scp命令将masters文件同步到其他节点
3)、修改works文件
server1
server2
修改完后,使用scp命令将works文件同步到其他节点
4)conf/zoo.cfg修改
# ZooKeeper quorum peers server.1=DEV-SH-MAP-01:2888:3888 server.2=DEV-SH-MAP-02:2888:3888 server.3=DEV-SH-MAP-03:2888:3888
修改完后,使用scp命令将masters文件同步到其他节点
4)、分发(scp分发)
scp -r /usr/local/flink-1.13.5/conf/flink-conf.yaml server2:/usr/local/flink-1.13.5/conf/
scp -r /usr/local/flink-1.13.5/conf/flink-conf.yaml server3:/usr/local/flink-1.13.5/conf/
scp -r /usr/local/flink-1.13.5/conf/flink-conf.yaml server4:/usr/local/flink-1.13.5/conf/
scp -r /usr/local/flink-1.13.5/conf/masters server2:/usr/local/flink-1.13.5/conf/
scp -r /usr/local/flink-1.13.5/conf/masters server3:/usr/local/flink-1.13.5/conf/
scp -r /usr/local/flink-1.13.5/conf/masters server4:/usr/local/flink-1.13.5/conf/
5)、修改修改node2上的flink-conf.yaml
Jobmanager.rpc.address: node2
、启动HDFS
[root@DEV-SH-MAP-01 conf]# start-dfs.sh
Starting namenodes on [DEV-SH-MAP-01] DEV-SH-MAP-01: starting namenode, logging to /usr/hadoop-2.7.3/logs/hadoop-root-namenode-DEV-SH-MAP-01.out DEV-SH-MAP-02: starting datanode, logging to /usr/hadoop-2.7.3/logs/hadoop-root-datanode-DEV-SH-MAP-02.out DEV-SH-MAP-03: starting datanode, logging to /usr/hadoop-2.7.3/logs/hadoop-root-datanode-DEV-SH-MAP-03.out DEV-SH-MAP-01: starting datanode, logging to /usr/hadoop-2.7.3/logs/hadoop-root-datanode-DEV-SH-MAP-01.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /usr/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-DEV-SH-MAP-01.out
八、启动Zookeeper集群
[root@DEV-SH-MAP-01 conf]# start-zookeeper-quorum.sh
Starting zookeeper daemon on host DEV-SH-MAP-01. Starting zookeeper daemon on host DEV-SH-MAP-02. Starting zookeeper daemon on host DEV-SH-MAP-03.
- 启动集群
/bin/start-cluster.sh
停止集群
/bin/stop-cluster.sh
- 查看进程
cat /export/server/flink/log/flink-root-standalonesession-0-node1.log
分发包:
for i in {2..3}; do scp -r flink-shaded-hadoop-2-uber-2.7.5-10.0.jar node$i:$PWD; done
注意:修改域名
vi hostname
cat hostname
改完以后,添加到hosts中:
改完之后将每台服务器的对应信息添加到hosts文件
vim /etc/hosts
# 添加以下内容到文件中
192.168.188.135 node1-zookeeper
192.168.188.136 node2-zookeeper
192.168.188.137 node3-zookeeper
测试联通性: 比如: ping node3-zookeeper