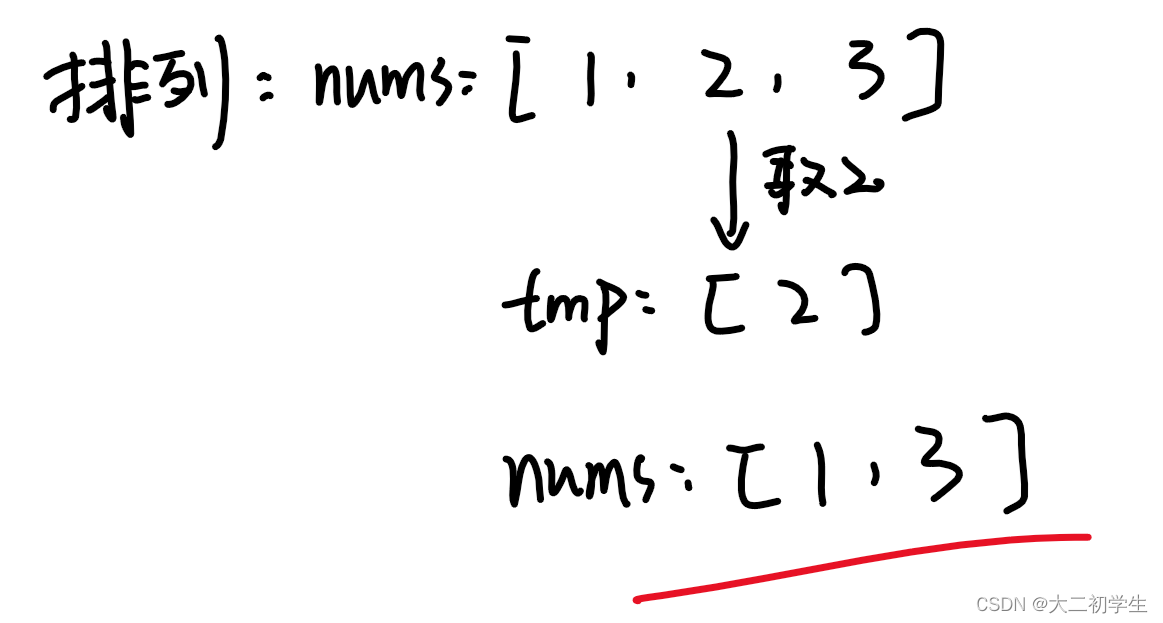先从简单的题型开始刷起,一起加油啊!!
点个关注和收藏呗,一起刷题鸭!!
第一批题目
1.设备编号
给定一个设备编号区间[start, end],包含4或18的编号都不能使用,如:418、148、718不能使用,108可用。请问有多少可用设备编号。
class Solution:def get_normal_device_number(self, start, end):count = 0for i in range(start, end+1):if ('4' in str(i) or '18' in str(i)):continueelse:count += 1return countif __name__ == "__main__":start, end = tuple(map(int, input().strip().split()))function = Solution()result = function.get_normal_device_number(start, end)print(result)2.服务器集群网络延时
给定一个正整数数组表示某服务器集群内服务器的机位编号,请选择一台服务器作为主服务器,使得集群网络延迟最小,并返回该最小值。
- 每台服务器有唯一的机位编号。
- 两服务器之间的网络延迟,可以简单用所在机位编号之差的绝对值表示;服务器到自身的延迟为0。
- 集群网络延迟是指主服务器与所有服务器的网络延迟之和。
class Solution:def cluster_latency(self, arr):res = 0mid = len(arr) // 2arr.sort()for num in arr:res += abs(num - arr[mid])return resif __name__ == "__main__":num = input().strip()arr = list(map(int, input().strip().split()))function = Solution()results = function.cluster_latency(arr)print(results)3.给定差值的组合
给定一个数组,每个元素的值是唯一的,找出其中两个元素相减等于给定差值 diff 的所有不同组合的个数。
输入三行:
第一行为一个整数,表示给定差值diff;范围[-50000, 50000]
第二行也为一个数字,表示数组的长度;范围[2, 102400]
第三行为该数组,由单个空格分割的一组数字组成;其中元素的值范围[-20, 102400]
用例保证第三行数字和空格组成的字符串长度不超过 649999
输出
1个整数,表示满足要求的不同组合的个数
样例
输入样例 1
3 5 1 3 2 5 4
输出样例 1
2
提示样例 1
数组为[1 3 2 5 4], 差值 diff 为 3,其中 4 - 1 = 3,5 - 2 = 3,共 2 个组合满足条件,因此输出 2
class Solution:def proc(self, arr, diff):# 在此添加你的代码if diff == 0:return 0arr_set = set(arr)diff_set = set(ele + diff for ele in arr_set)cross_set = arr_set & diff_setreturn len(cross_set)
if __name__ == "__main__":diff = int(input().strip())count = int(input().strip())arr = list(map(int, input().strip().split(' ')))function = Solution()result = function.proc(arr, diff)print(result)左右指针算法:
class Solution:def __init__(self):self.count, self.left, self.right = 0, 0, 0# 左右指针算法def proc(self, nums, d):# 差值为0,直接返回0if d == 0:return self.count# 升序排序nums.sort()while self.right < len(nums) and self.left < len(nums):# 当右值左值差大于diff时,左指针加一if nums[self.right] - nums[self.left] > d:self.left += 1continue# 当右值左值差等于diff时,左指针加一,右指针加一,结果加一elif nums[self.right] - nums[self.left] == d:self.left += 1self.right += 1self.count += 1# 当右值左值差小于diff时,右指针加一else:self.right += 1return self.count集合交集算法:
class Solution:def __init__(self):self.count = 0def proc_set(self, nums, d):if d == 0:return self.countnums_set = set(nums)diff_set = set(i - d for i in nums_set)return len(nums_set & diff_set)好厉害的算法啊!执行时间也很短
第七批题目
1.IP报文头解析
一个IP报文头及所包含的各信息的关系如图所示:

- 图中从上到下、从左到右依次表示各信息在IP报文头中的顺序。
- 各信息括号内的数字表示所占位数,如:标识(16),表示标识部分占16个bit位即2个字节长度。
现给定一个十六进制格式的IP报文头数据,请解析输出其中的总长度、标志、目的IP地址:
- 总长度、标志为十进制整数
- 目的IP地址为点分十进制格式,如:192.168.20.184
输入样例 1
45 00 10 3c 7c 48 20 03 80 06 00 00 c0 a8 01 02 c0 a8 14 b8
输出样例 1
4156,1,192.168.20.184
对照图示的各信息所在位置:
总长度 :0x103c,十进制值为 4156
标 志 :0x20的二进制为 00100000,其中的高 3 位为标志,二进制为 001,10进制值为 1
目的IP地址:0xc0a814b8,点分十进制为 192.168.20.184
(内心:简单题的题目怎么这么复杂?????看都看不懂)
前置知识:每个十六进制(0x)数字对应4位二进制数。
from typing import List
class Solution:def get_ip_info(self, datas: str) -> str:# 1.先按空格切割data_lst = datas.split()# 2.提取长度字段,16进制转为10进制,最终转为字符串length_str = str(int("0x" + "".join(data_lst[2:4]), 16))# 3.提取标志字段,16进制转10进制,再转2进制(注意zfill补齐前置0),再转10进制,最终转为字符串flag_str = str(int(bin(int("0x" + "".join(data_lst[6]), 16))[2:].zfill(8)[:3], 2))# 4.最后四位转为点分10进制,最终转为字符串ip_str = ".".join([str(int("0x" + x, 16)) for x in data_lst[-4:]])return length_str + "," + flag_str + "," + ip_str
if __name__ == "__main__":data = input().strip()function = Solution()results = function.get_ip_info(data)print(results)length_str = str(int("0x" + "".join(data_lst[2:4]), 16)) ,将十六进制表示的一段数据转换为十进制表示的字符串。我们可以一步步地解读它:
1. `data_lst[2:4]`:这是一个列表切片操作,从列表 `data_lst` 中提取索引2和3的两个元素。这些元素应该是以字符串形式表示的十六进制数。
2. `"".join(data_lst[2:4])`:这个操作将步骤1中提取的元素连接成一个字符串。例如,如果 `data_lst[2]` 是 `'10'`,`data_lst[3]` 是 `'3c'`,那么结果将是 `'103c'`。
3. `"0x" + "".join(data_lst[2:4])`:在连接好的字符串前面加上 `'0x'`,使其成为一个合法的十六进制字符串表示。例如,如果结果是 `'103c'`,那么现在它变成 `'0x103c'`。
4. `int("0x" + "".join(data_lst[2:4]), 16)`:将这个十六进制字符串转换为一个十进制的整数。`int` 函数的第一个参数是要转换的字符串,第二个参数 `16` 表示输入是一个十六进制数。例如,`'0x103c'` 会被转换成十进制的 `4156`。
5. `str(int("0x" + "".join(data_lst[2:4]), 16))`:将上述得到的十进制整数转换为字符串。例如,`4156` 会被转换成 `'4156'`。
举例说明:
假设 `data_lst = ["45", "00", "10", "3c", "7c", "48", "20", "03", "80", "06", "00", "00", "c0", "a8", "01", "02", "c0", "a8", "14", "b8"]`,那么:
- `data_lst[2:4]` 提取的子列表是 `["10", "3c"]`。
- `"".join(data_lst[2:4])` 结果是 `'103c'`。
- `"0x" + "".join(data_lst[2:4])` 结果是 `'0x103c'`。
- `int("0x103c", 16)` 结果是 `4156`。
- `str(4156)` 结果是 `'4156'`。
flag_str = str(int(bin(int("0x" + "".join(data_lst[6]), 16))[2:].zfill(8)[:3], 2)) 代码详细解读
进制转化:16→10→2→10
1.int("0x" + "".join(data_lst[6]), 16),16进制转化成十进制,int("0x20", 16) 结果是 32
2.使用 bin 函数将十进制整数转换为二进制字符串,结果是"0b100000"
3.[2:] 去掉前缀 "0b"
4.zfill(8) 方法将二进制字符串填充到 8 位长度
5.[:3] 使用切片操作提取二进制字符串的高 3 位 对于 "00100000",结果是 "001"
6.使用 int 函数将二进制字符串 "001" 转换为十进制整数
ip_str = ".".join([str(int("0x" + x, 16)) for x in data_lst[-4:]]) 解读
- 对于每个元素
x,首先使用"0x" + x将其转换为十六进制字符串,例如"c0"变为"0xC0"。 - 使用
int("0x" + x, 16)将十六进制字符串转换为十进制整数,例如int("0xC0", 16)结果是192。
注意A.join(B) A 和 B 都是字符串类型
int(A,B) A是字符串类型,返回的是整数类型
2.可漫游服务区
漫游(roaming)是一种移动电话业务,指移动终端离开自己注册登记的服务区,移动到另一服务区(地区或国家)后,移动通信系统仍可向其提供服务的功能。
用户可签约漫游限制服务,设定一些限制区域,在限制区域内将关闭漫游服务。
现给出漫游限制区域的前缀范围,以及一批服务区(每个服务区由一个数字字符串标识),请判断用户可以漫游的服务区,并以字典序降序输出;如果没有可以漫游的服务区,则输出字符串empty。
输入
首行输入两个整数m n,取值范围均为 [1, 1000]。
随后 m 行是用户签约的漫游限制区域的前缀范围,每行格式为start end(含start和end),start和end是长度相同的数字字符串,长度范围为[1, 6],且 start <= end。
接下来 n 行是服务区列表,每行一个数字字符串表示一个服务区,长度范围为[6,15]。
输出
字典序降序排列的可漫游服务区列表,或字符串empty
输入样例 1
2 4 755 769 398 399 3970001 756000000000002 600032 755100
输出样例 1
600032 3970001
提示样例 1
服务区 755100 和 756000000000002 的前缀在漫游限制 [755,769] 范围内,不能漫游。 3970001 和 600032,不在任何漫游限制范围内,因此可以漫游,按字典序降序先输出 600032。
方法一:
prex_len = len(restricts[0][0])ranges = []for i in restricts:start = int(i[0])end = int(i[-1])for j in range(start, end+1):ranges.append(j)res = []for j in areas:if int(j[:prex_len]) not in ranges:res.append(j)res.sort(reverse=True)if not res:print("empty") return res方法二:
def get_roaming_area(self, restricts: List[List[str]], areas: List[str]) -> List[str]:un_limit = []# 备份for j in areas:un_limit.append(j)# 在范围内就删除for k in areas:for i, j in restricts:if int(i) <= int(k[0:len(i)]) <= int(j):un_limit.remove(k)# 输出结果if not un_limit:un_limit = ['empty']else:un_limit = sorted(un_limit, reverse=True)return un_limit# 定义测试样例
restricts_num, areas_num = 2, 4
restricts = [["755", "769"], ["398", "399"]]
areas = ["3970001", "756000000000002", "600032", "755100"]
-
for k in areas:- 这个循环遍历
areas列表中的每一个元素,k代表areas中的一个区域。
- 这个循环遍历
-
for i, j in restricts:- 这个内层循环遍历
restricts列表中的每一个限制条件,i和j分别代表每个限制条件中的两个值。 restricts是一个包含成对限制条件的列表,每对由两个字符串(i和j)组成,表示一个范围。
- 这个内层循环遍历
-
if int(i) <= int(k[0:len(i)]) <= int(j):- 这一行检查当前区域
k是否在当前限制条件i和j之间。 int(i)和int(j)将限制条件i和j转换为整数。k[0:len(i)]提取区域k的前len(i)个字符并转换为整数。这是因为i和j的长度可能不同,代码需要根据i的长度来提取并比较k的相应部分。- 如果提取的部分在
i和j之间(包括边界),条件为真。
- 这一行检查当前区域
-
如果条件为真,从un_limit.remove(k)un_limit列表中移除区域k,表示该区域k符合当前的限制条件,不再属于不受限制的区域。
3.信号解码
无线基站接收到手机上报的某种信息(例如11@2$3@14)后,需要先进行解码操作,再计算结果。假定每条信息中都至少包含特殊运算符 @ 和 $ 的一种,解码规则如下:
x@y = 2*x+y+3x$y = 3*x+2*y+1
- x、y 都是非负整数 ;
- @ 的优先级高于 $ ;
- 相同的特殊运算符,按从左到右的顺序计算。
11@2$3@14
= (2*11+2+3)$3@14
= 27$3@14
= 27$(2*3+14+3)
= 27$23
= 3*27+2*23+1
= 128现给定一个字符串,代表一个手机上报的待解码信息,请按照解码规则进行解码和计算,并返回计算结果。
import re
class Solution:def get_calc_result(self, information: str) -> int:# 这一步把输入拆成数字和符号存入字符串,如11@2$3@14 -> ['11', '@', '2', '$', '3', '@', '14']ex = re.split(r"(\D)", information) pos = 0 #用于保存符号的位置sign = '' #用于记录符号#核心逻辑:边计算,便删除ex表达式中元素,直到只剩一个值即为结果while len(ex)!=1:#如果还存在@则sign记录为@,pos记录为@在ex中的位置;否则记录$信息(实现@优先于$)(sign, pos) = ('@', ex.index('@')) if '@' in ex else ('$', ex.index('$'))ex[pos-1] = self.cal(sign, int(ex[pos-1]), int(ex[pos+1]))del ex[pos:pos+2]return ex[0]def cal(self, sign, x, y):if sign == '@': return 2*x+y+3else: return 3*x+2*y+1
if __name__ == "__main__":information = str(input().strip())function = Solution()results = function.get_calc_result(information)print(results)
1. `re.split(r"(\D)", information)`
- 使用正则表达式 `(\D)` 将 `information` 按非数字字符拆分成一个列表。括号 `()` 表示捕获分组,因而分隔符本身也会包含在结果列表中。例如,字符串 `11@2$3@14` 将被拆分成 `['11', '@', '2', '$', '3', '@', '14']`。
import restring = "a1b2c3d4"
# 使用捕获组 (\D) 来分割字符串
result = re.split(r"(\D)", string)
print(result)#输出
['', 'a', '1', 'b', '2', 'c', '3', 'd', '4', '']import restring = "a1b2c3d4"
# 使用正则表达式 \D 来分割字符串,\D 表示非数字字符
result = re.split(r"\D", string)
print(result)#输出
['', '1', '2', '3', '4']
2. `pos = 0` 和 `sign = ''`
- 初始化变量 `pos` 和 `sign`,分别用于保存符号的位置和记录当前符号。
3. **`while len(ex) != 1:`**
- 这个循环会持续运行,直到 `ex` 列表中只剩下一个元素,即最终计算结果。
4. `(sign, pos) = ('@', ex.index('@')) if '@' in ex else ('$', ex.index('$'))`
- 这行代码检查 `ex` 列表中是否包含 `@` 符号。如果包含,则 `sign` 设为 `@`,`pos` 设为 `@` 在 `ex` 中的位置。如果不包含 `@`,则检查并设置 `$` 符号的信息。这样确保 `@` 的优先级高于 `$`。
A if condition else B
condition是条件,如果条件为真,表达式返回A;否则返回B。如果条件为真,返回一个元组
('@', ex.index('@'))。
sign被赋值为'@'pos被赋值为ex.index('@'),即'@'在ex列表中的索引位置。如果条件为假(即
ex列表中不包含字符'@'),返回一个元组('$', ex.index('$'))。这里:
sign被赋值为'$'pos被赋值为ex.index('$'),即'$'在ex列表中的索引位置。
5.ex[pos-1] = self.cal(sign, int(ex[pos-1]), int(ex[pos+1]))
- 调用 `cal` 方法,传入符号 `sign` 以及符号前后的数字,进行计算,并将计算结果赋值给符号前面的数字位置。
6. **`del ex[pos:pos+2]`**
- 删除符号和符号后面的数字,使得 `ex` 列表长度减少。举例来说,`['11', '@', '2', '$', '3', '@', '14']` 将变为 `['结果', '$', '3', '@', '14']`。
7. **`return ex[0]`**
- 当 `while` 循环结束时,`ex` 列表中只剩下一个元素,即最终计算结果,将其返回。
假设输入 `information = "11@2$3@14"`:
1. 初始分割为 `['11', '@', '2', '$', '3', '@', '14']`。
2. 首先处理 `@` 操作符:
- `11@2` 计算结果为 `2*11 + 2 + 3 = 27`,列表变为 `['27', '$', '3', '@', '14']`。
3. 继续处理 `@` 操作符:
- `3@14` 计算结果为 `2*3 + 14 + 3 = 23`,列表变为 `['27', '$', '23']`。
4. 最后处理 `$` 操作符:
- `27$23` 计算结果为 `3*27 + 2*23 + 1 = 154`,列表变为 `['154']`。
5. 返回 `154` 作为最终结果。
方法二:
#$的优先级低,直接分割,先把@计算完后,再单独计算$lst_info = information.split("$")#判断list中每个元素,没有@则跳过,有@计算for i in range(len(lst_info)):#每个再按@拆if '@' in lst_info[i]:lst1 = lst_info[i].split("@")lst2 = [int(j) for j in lst1]#按栈的方式计算lst2.append(lst2[0])for j in range(1,len(lst2)-1):lst2.append(lst2.pop(-1)*2 +lst2[j]+3)#最后只保留算出来的结果lst_info[i] =lst2[-1]lst_fianl = [int(i) for i in lst_info]#计算$,原理和上面相同lst_fianl.append(lst_fianl[0])for j in range(1, len(lst_fianl) - 1):lst_fianl.append(lst_fianl.pop(-1) * 3 + lst_fianl[j]*2 + 1)return lst_fianl[-1]4.比特翻转
工程师小A在对二进制码流 bits 进行验证,验证方法为:给定目标值 target(0 或 1),最多可以反转二进制码流 bits 中的一位,来获取最大连续 target的个数,请返回该个数。
解答要求时间限制:1000ms, 内存限制:256MB
输入
第一行为 target,取值仅为 0 或 1;
第二行为 bits 的长度 length,取值范围 [1, 10000];
第三行为 bits 数组的元素,只包含 0 或 1 。
输出
一个整数,表示最大连续 target 的个数
样例
输入样例 1
1 9 0 1 1 0 1 0 1 0 0
输出样例 1
4
提示样例 1
0 1 1 0 1 0 1 0 0
目标值为1,表示需要获取最大连续1的个数。
将第二个出现的0反转为1,得到0 1 1 1 1 0 1 0 0 ,获得 4 个连续的1;
其它反转获得连续1的个数最大为3,如 1 1 1 0 1 0 1 0 0 或 0 1 1 0 1 1 1 0 0 。
输入样例 2
0 8 0 0 0 0 0 0 0 0
输出样例 2
8
提示样例 2
不需要反转即可获得最大连续0,个数为8
滑动窗口的解法:
def find_max_consecutive_bits(self, target: int, bits: List[int]) -> int:left, right = 0, 1res = 0while right <= len(bits):if bits[left:right].count(1 - target) <= 1:res = max(res, right - left)right += 1else:left += 1return resif bits[left:right].count(1 - target) <= 1:
计算当前子数组 bits[left:right] 中不同于 target 的位数(即 1 - target 的位数)。如果不同于 target 的位数不超过 1,则当前子数组符合条件。
更新 res 为当前子数组的长度与之前最大长度中的较大者。
将 right 指针右移一位,扩展子数组范围。
def main():target, length, bits = int(input().strip()), int(input().strip()), [*map(int, input().strip().split())]count1 = count2 = max_length = 0 # count2计算前一段连续target的个数 + 1, count1计算当前连续target的个数for i in range(length):if bits[i] == target:count1 += 1continuemax_length = max(max_length, count2 + count1)count2 = count1 + 1count1 = 0max_length = max(max_length, count2 + count1)print(max_length)
if __name__ == "__main__":main()啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊,第一批和第七批的题目比起来还真的不是同一个难度啊
加油啊!!祝我好运
引用的代码就不一一注释原处了,作者介意的请联系我加上