加载模型页面为:https://huggingface.co/liam168/trans-opus-mt-zh-en
文章目录
- 整理文件
- 跑通程序,测试预训练模型
- 拆解Pipeline,逐步进行翻译任务
整理文件
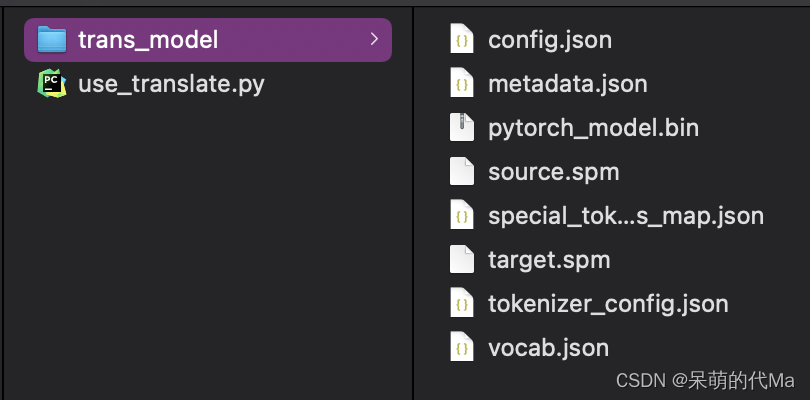
首先下载模型所需的全部文件:https://huggingface.co/liam168/trans-opus-mt-zh-en/tree/main,将文件全部下载到本地,命名为trans_model
然后创建一个调用模型的python程序文件:use_translate.py
整个文件结构如下:
跑通程序,测试预训练模型
在use_translate.py文件中写入:
from transformers import AutoModelWithLMHead, AutoTokenizer, pipelinemode_name = "trans_model"
model = AutoModelWithLMHead.from_pretrained(mode_name)
tokenizer = AutoTokenizer.from_pretrained(mode_name)
translation = pipeline("translation_zh_to_en", model=model, tokenizer=tokenizer)
translate_result = translation('自然语言处理的技术之一:机器翻译', max_length=400)
print(translate_result)
# [{'translation_text': 'One of the technologies for natural language processing: machine translation'}]如果控制台输出:
[{'translation_text': 'One of the technologies for natural language processing: machine translation'}]
则说明模型是通的,都没有问题
拆解Pipeline,逐步进行翻译任务
from transformers import AutoModelWithLMHead, AutoTokenizer# 加载预训练模型
mode_name = "trans_model"
model = AutoModelWithLMHead.from_pretrained(mode_name)
tokenizer = AutoTokenizer.from_pretrained(mode_name)# 开始翻译
text = "自然语言处理的技术之一:机器翻译"# 步骤1:将文本变为token,返回pytorch的tensor
tokenized_text = tokenizer.prepare_seq2seq_batch([text], return_tensors='pt')
# 也可以使用:
# tokenized_text = tokenizer([text], return_tensors="pt")# 步骤2:通过模型,得到预测出的token
translation = model.generate(**tokenized_text) # 执行翻译,返回翻译后的tensor# 步骤3:将预测出的token转为单词
translated_text = tokenizer.batch_decode(translation, skip_special_tokens=True)
print(translated_text)
输出:
['One of the technologies for natural language processing: machine translation']
因此我们可以发现,整体的流程是:
- 将原始中文文本变为token
- 通过模型,得到预测出的token(对应英文的token)
- 将预测出的token转为英文单词