| 生成模型 | 从 VAE 到 Diffusion Model (上)的链接请点击下方蓝色字体: 上部分主要介绍了,GAN, AE, VAE, VQ-VAE, DALL-E |
生成模型 | 从 VAE 到 Diffusion Model (上)
文章目录
- 我们先来看一下生成模型现在的能力
- 一,扩散模型
- 反向过程
- U-NET
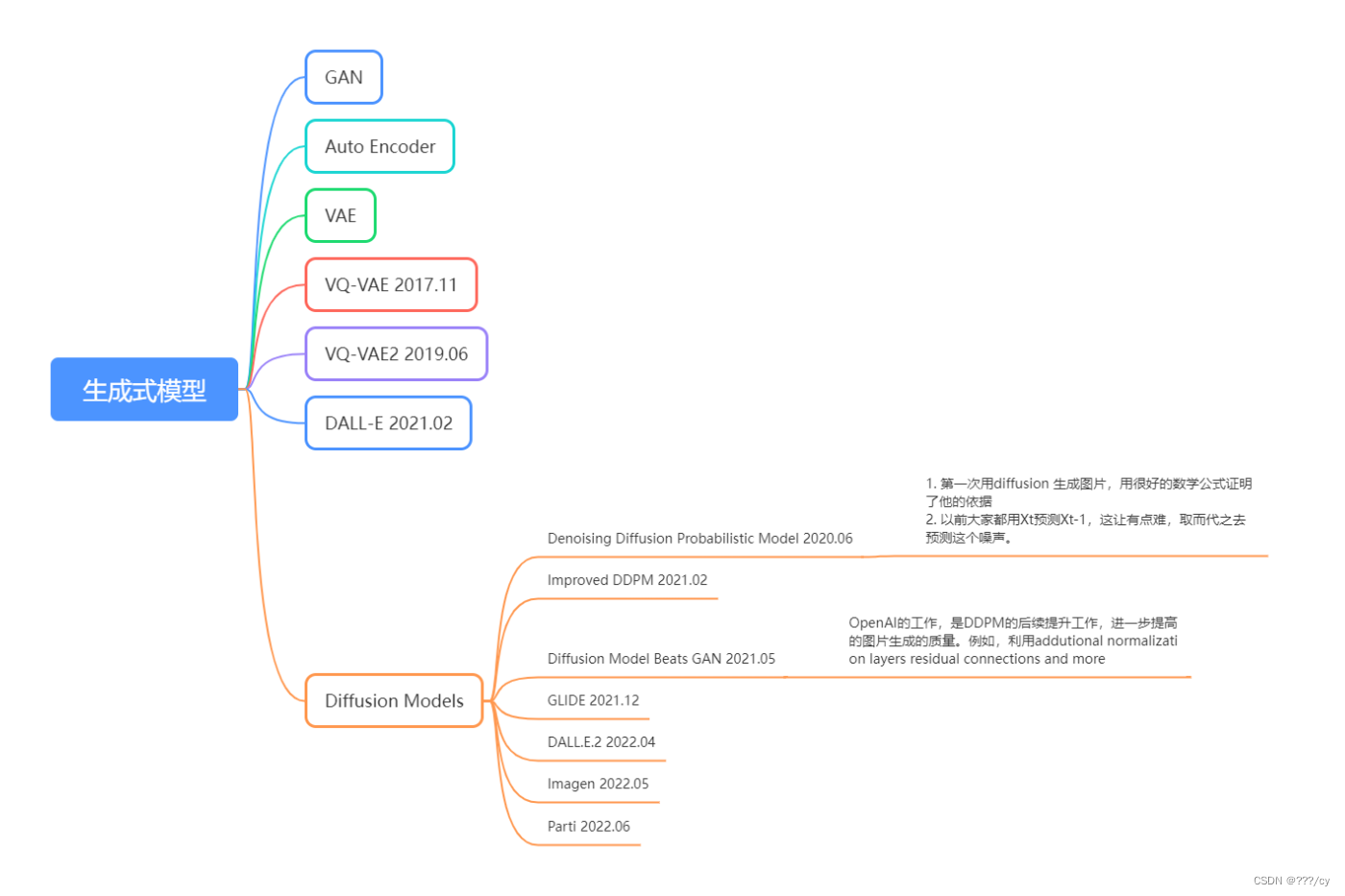
- 二,扩散模型的发展历程
- 1. Denoising Diffusion Probabilistic Model (DDPM) (2020.06)
- 贡献一
- 目标函数
- 贡献二
- VAE 与 Diffusion Model的相似之处
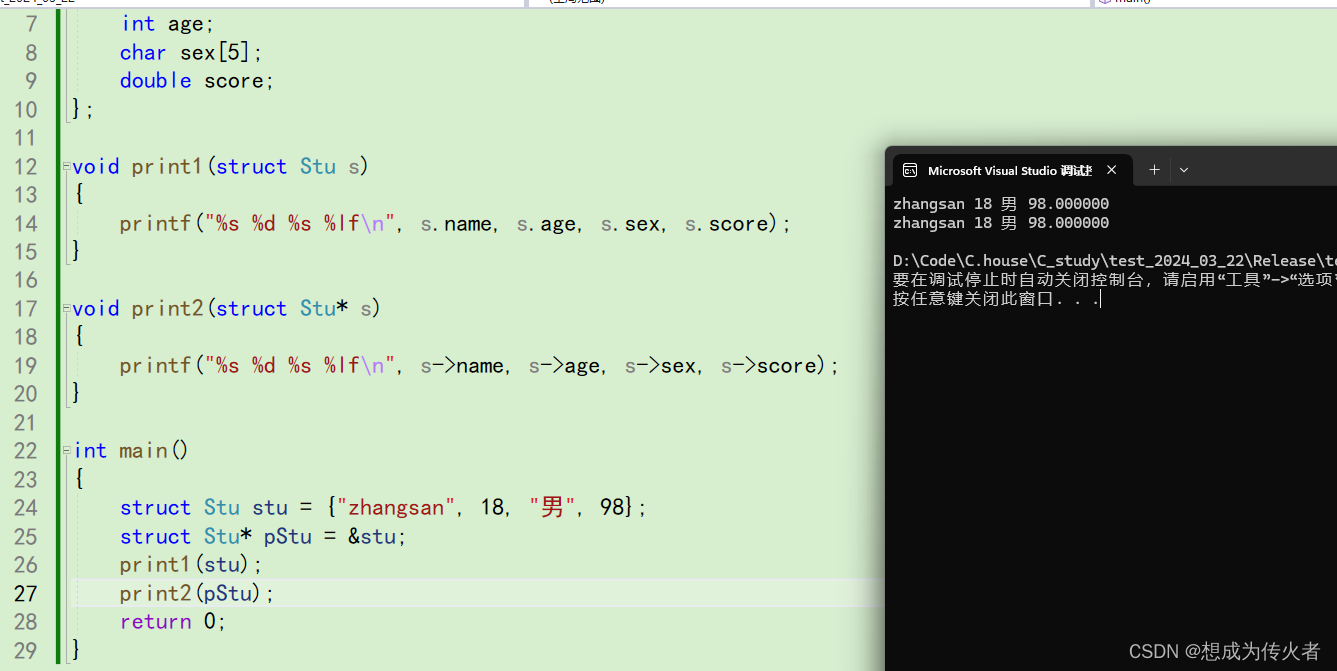
- 2. Improved Denoising Diffusion Probabilistic Model (Improved DDPM) (2021.02)(OpenAI)
- 3. Diffusion Model Beats GAN(2021.05) (OpenAI)
- 4. GLIDE(2021.) (OpenAI)
- 5. DALL-E-2(2021.05) (OpenAI)
- decoder
- prior
- 三,文生图模型的总体架构
- Text Encoder
- Decoder
我们先来看一下生成模型现在的能力
他能干什么:文生图,生成原有图像之外的新内容,修改图片,生成图片的变体
| 生成模型现在的能力 | 示例 |
|---|---|
| 文生图 |  |
| 生成原有图像之外的新内容 | 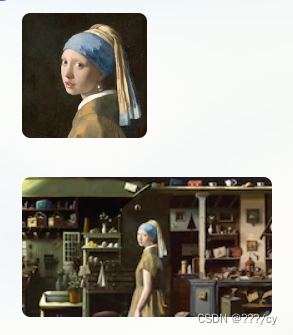 |
| 修改图片 | 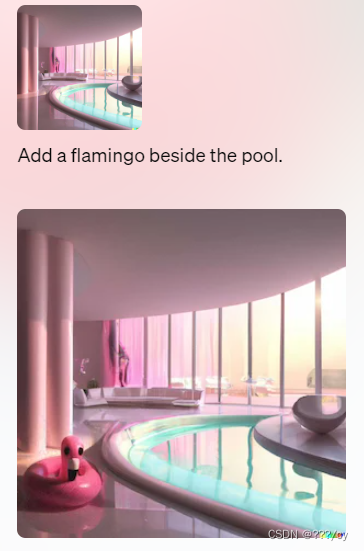 |
| 生成图片的变体 |  |
| 不同公司的生成式模型 | 示例 |
|---|---|
| 之前的生成模型 |  |
| OpenAI |  |
| stability ai |  |
| Midjounery |  |
一,扩散模型
在训练的时候有两个过程:
-
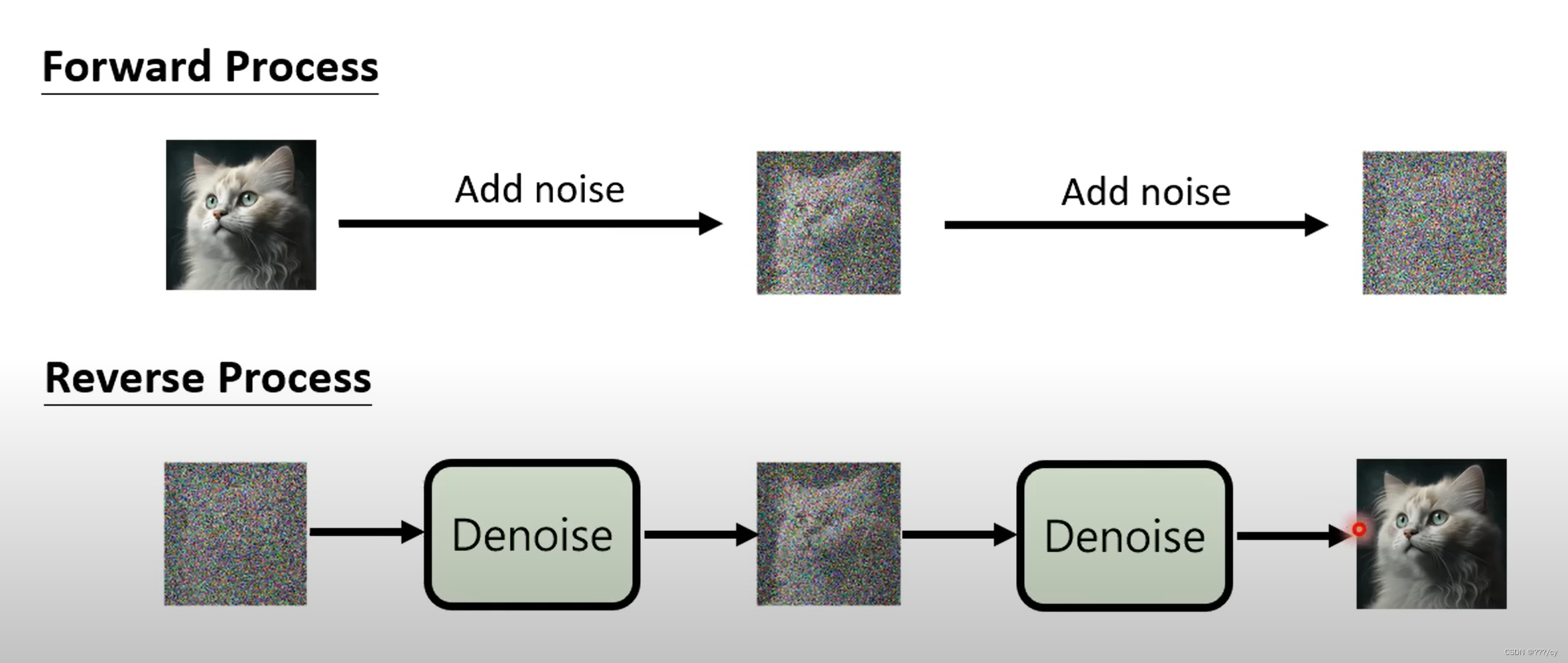
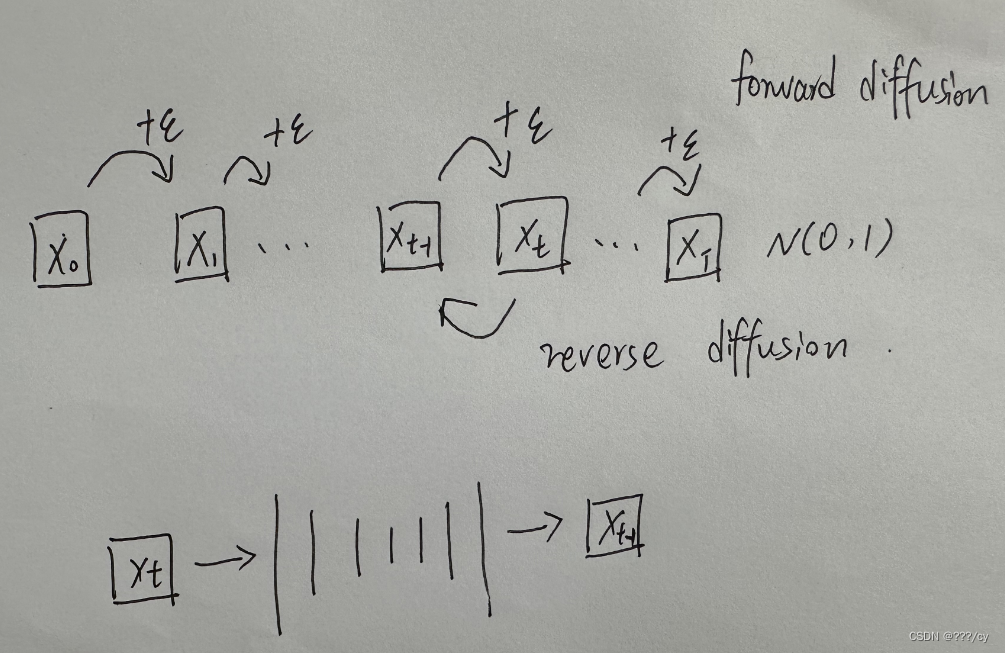
前向过程: 把 噪声 加到图片里面去, 直到图片变成一个纯纯的高斯分布的这么一个噪声。
-
反向过程: 把高斯分布的这么一个噪声 一步步 的去噪,生成图片。
(扩散模型:是一个概率分布模型,他生成这个图片,是从分布里去采样的,所以他的多样性非常好,但是保真度比不过GAN)
数学上,简洁美观,正向,逆向都是高斯分布,所以能做很多推理证明。
如果我现在的输入是一个随机噪声Z(和GAN里面那个一样),找到一种方式,把噪声一点点恢复到最初的图片,就可以做图像生成了。通过这个反向过程来生成图像。
- 我们随机抽样一个噪声,比如说Xt,那我就训练一个模型把它从Xt 还原回 Xt-1,一步一步这样倒退回来。
- 抽样生成很多次,训练比较贵,推理也是最慢的一个。
- 最原始的扩散模型T是选择了1000个step,如果你随机选择一个噪声,你要往前推1000步,一千次forword 一点一点把图像恢复回来。开销很大。
反向过程
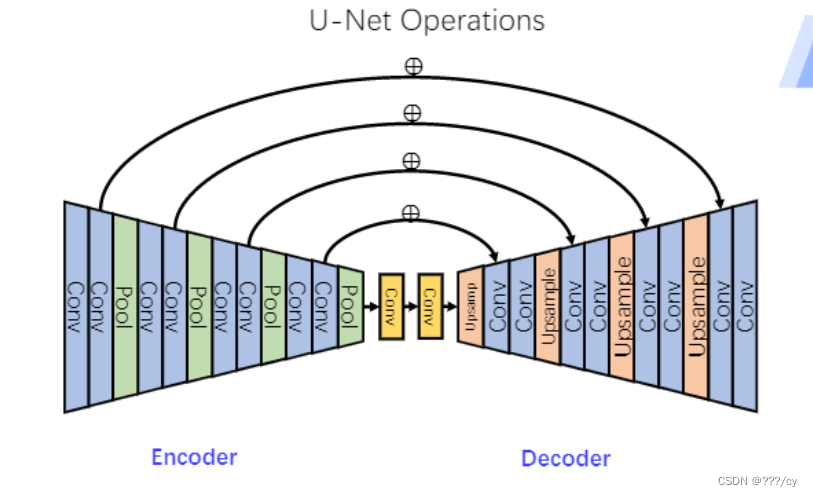
这个reverse 反向模型长什么样呢?每一步的输入输出的图片大小保持不变,在这个情况下,diffusion model采取了一个非常常见的一个模型结构U-NET

U-NET
U-NET: 他的输入输出的特征图大小一样,我们用u-net来做这个噪声的预测
- u-net就是一个CNN ,一点点把图像压小,然后解码一点点把图片恢复回来,前后两个图片尺寸大小是一样的。
- 为了让恢复做的更好,还有一些skip connection, 这样能恢复一些细节。
- 后来又对网络结构有了一些改进,比如加了attention,让模型生成变得更好。
- 这里不一定要用u-net模型,但是大部分扩散网络都用了u-net
二,扩散模型的发展历程
1. Denoising Diffusion Probabilistic Model (DDPM) (2020.06)
贡献一
- 以前大家都用Xt预测Xt-1,这让有点难,取而代之去预测这个噪声。
- 同时这里面也加了time embedding,告诉模型这是我们现在走哪一步了。现在这个输出我是想要糙一点的还是想要细致一点的
- 我们希望u-net在刚开始的反向过程中,可以生成物体大概的轮廓,一些很粗糙的图像,不需要很清晰,不需要很写实
- 随着扩散模型往前走,我们希望模型还原图片的细节信息,比如物体的边边角角,物体细小的特征,让图片变得逼真。
目标函数
训练这个简单的目标函数,我们就把DDPM这个网络训练起来了。

贡献二
- 如果你要预测一个正态分布呢,其实你只要学习他的均值和方差,就可以了
- 作者这里发现,其实你只要去学均值就可以了,方差都不用学,方差变成一个常数,效果就很好了
- DDPM降低了模型优化的难度,第一次能够用扩散模型,能够生成很好的图片,是扩散模型的开山之作
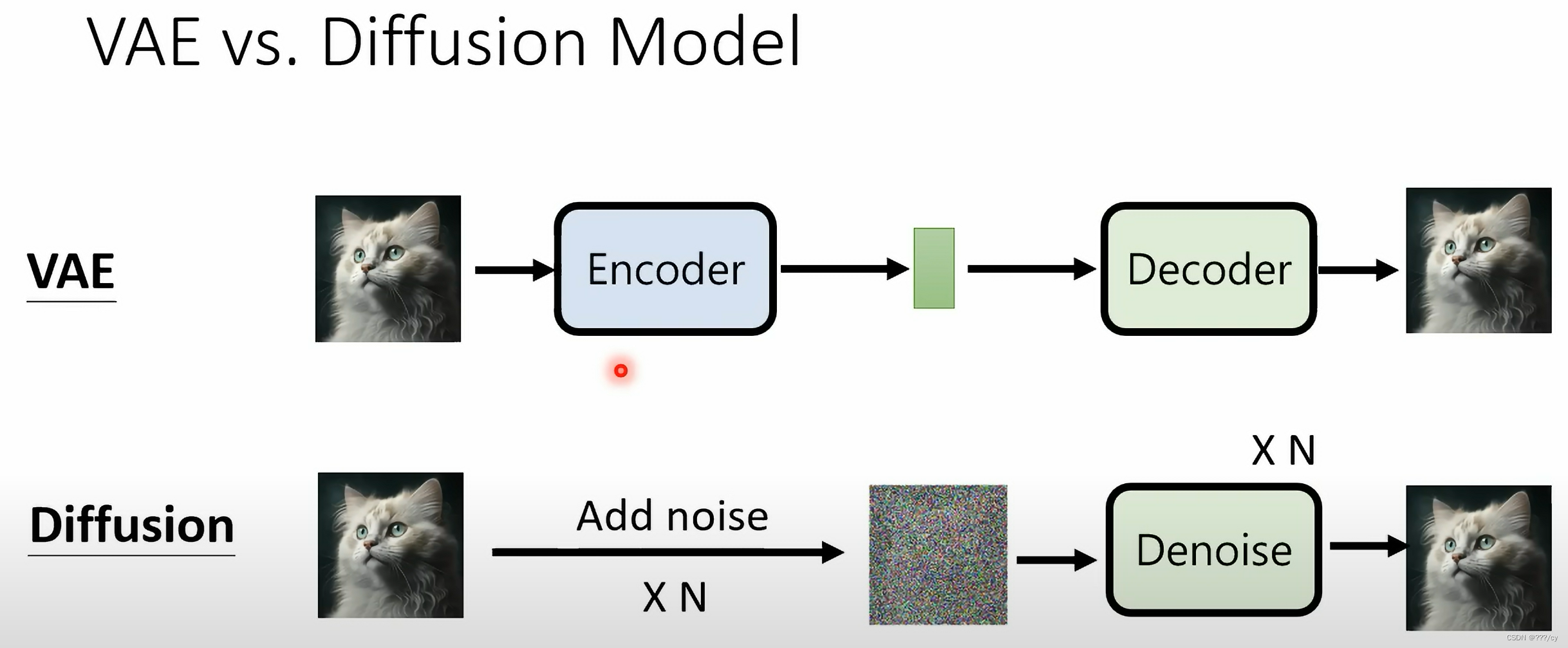
VAE 与 Diffusion Model的相似之处
- 编码器解码器的结构
- 对于扩散模型,每一步的中间过程,和刚开始的输入都是同样维度大小。对VAE来说,中间特征bottleneck 要比输入小很多
- 对扩散模型来说有步数的概念。从随机噪声开始要经过很多很多步才能生成一个图片,所以它有time embedding的概念。而且在所有的time step里所有的模型都是共享参数
- 换一个角度看VAE 和 Diffusion Model
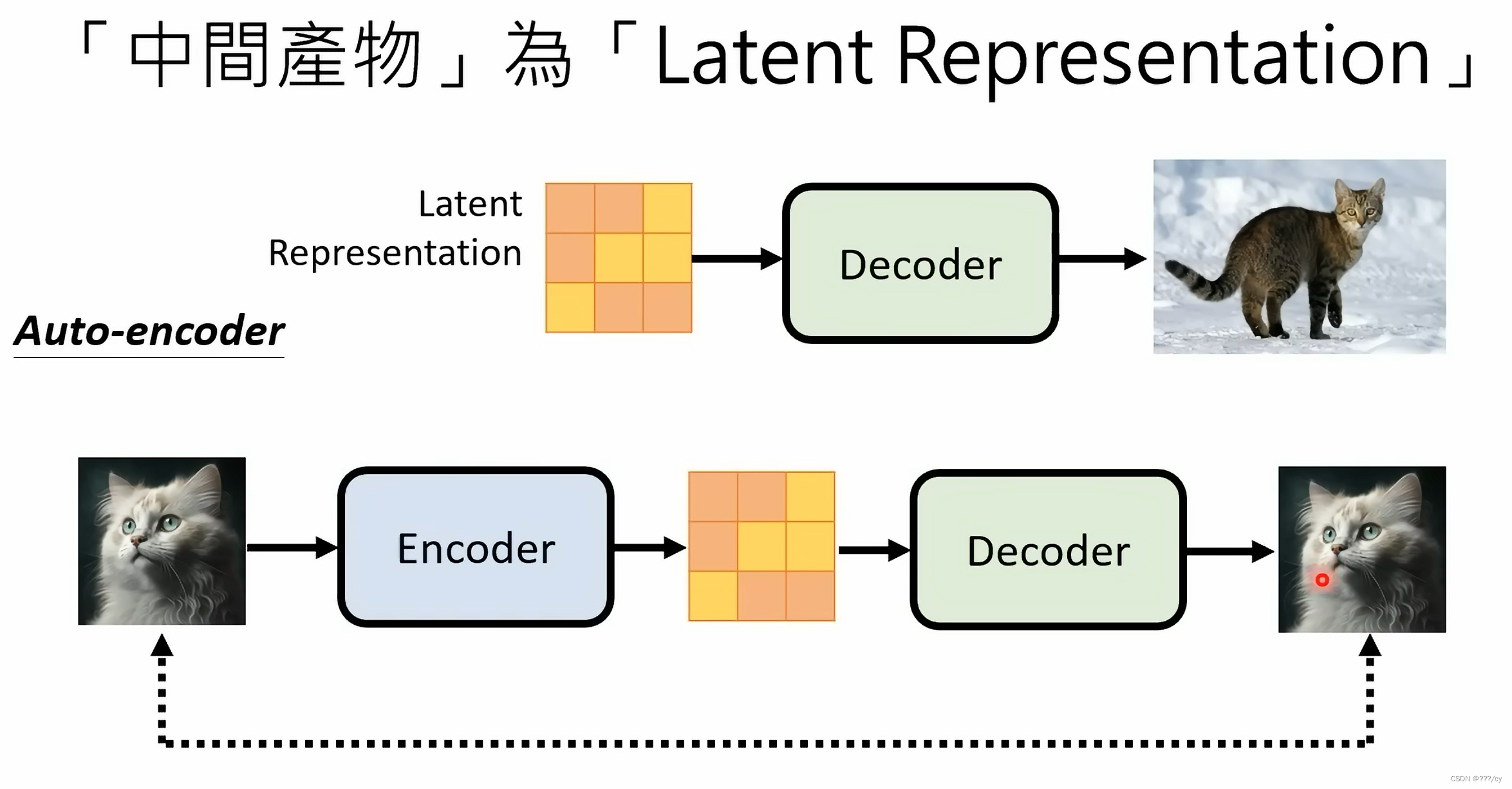
- VAE 先用一个ENCODER, 把Image 变成 Latent presentation, 然后用一个Decoder 把 这个特征还原回图片。
- 扩散模型,你可以把这个前向加噪的过程看成一个ENCODER, 这个encoder不是神经网络,不是学习得来的,而是固定好的,是人设计的。一直加噪,得到这么一个纯粹的噪声图片就像是人类看不懂的Latent presentation。然后把噪声还原的过程就是Decoder的过程。
2. Improved Denoising Diffusion Probabilistic Model (Improved DDPM) (2021.02)(OpenAI)
- 之前的DDPM里面说,正态分布的方差呢,不用学,OpenAI觉得要是学了可能会更好,后来取样,生成的效果都不错
- 更改了如何添加噪声的schedule,从一个线性的schedule, 变成了一个余弦的schedule。
- 模型越大,图像生成更好。
3. Diffusion Model Beats GAN(2021.05) (OpenAI)
- 把模型加大加宽,增加自注意力头的数量,变复杂
- 新的归一化的方式,根据步数做自适应的归一化
- classifier guidance的方法,引导模型做采样和生成,让生成的图片更加的逼真,同时加速了反向采样的速度。
- 之前的扩散模型在计算FID等数值的时候,与GAN相比不具有竞争性,classifier guidance的方法, 提高了FID, INCEPTION SCORE。同时也提升了采样生成的速度。
- classifier guided diffusion: 在训练模型的同时,再训练一个图像分类器,
- 分类器的作用:当我有一个图片Xt,我把它扔给图片分类器,看他分类对不对,我就能算一个交叉熵目标函数,对应的呢就能得到一些 梯度,然后我用这个梯度来帮助模型进行采样和图片的生成。这里的梯度暗含了图片里面的物体,告诉U-NET我现在要生成的图片呢,要看起来更像某一类物体。
- 在classifier guided diffusion 之后生成的图片逼真了很多
- 这篇论文第一次把diffusion model的FID等评价指标得分打败了GAN
- 相当于牺牲了一部分多样性,增加了 写实性。
- 除了用classifier 当作指导信号,还可以用什么当作指导信号?除了梯度,还可以用 clip, image, text 做引导
- 所有的这个方法有一个缺陷:需要用另外一个模型来做这个引导
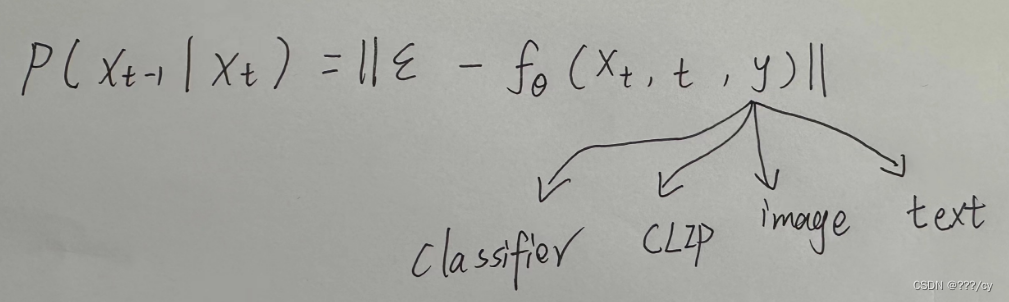
4. GLIDE(2021.) (OpenAI)
- classifier free guidance
- 不想要这些classifier了,能不能找到一种指导信号,让模型生成更好呢?
- 让模型生成两个输出,一个是给定条件生成一个输出,另一个是不给条件生成一个输出。
- 比如,给定的条件是text,生成一个输出,然后随机的不给条件,生成输出。假设我们现在有一个空间,刚才生成的图片分别是有条件生成的图片和没用条件生成图,那我们现在知道,有一个方向 让我们从无条件的输出,成为有条件得到的这个输出,通过训练,我们就会知道他们之间的差距大概是多少。最后在反向扩散图像生成的时候呢,我们能做出一个合理的推测,能从一个没有条件生成的输出,变成一个有条件生成的输出。这样就摆脱了分类器的限制。
- 训练很贵,训练的时候生成两个输出。但是好用。是一个非常重要的技巧,从GLIDE, DALL-E.2 到Imagen都说这是一个非常好用的技巧。
在前面的所有发展历程的积累下,GLIDE模型是一个很好的根据文本生成图片的扩散模型了。只用了3.5B的参数,就直逼之前的DALL-E模型(12B参数)。所以OpenAI就不顺着之前DALL-E, 之前 VQ-VAE的方向去做了,就用扩散模型来做了。
5. DALL-E-2(2021.05) (OpenAI)
任务:给定文本去生成图像:
1. 先训练好一个clip模型, 找到图像和文本对之间的相连关系后
2. 然后把text变成text embedding, 训练一个prior 模型, 把text embedding 变成 image embedding
3. 然后用一个 decoder 把 image embedding 还原成图像
DALL-E2这种显示的生成图像特征的 提高了图片的 多样性, 他们这种基于 扩散模型 的解码器,能够根据给定的图片特征,生成不同的图片,同时保持语义信息和风格都是比较接近的,只是细节不一样。
因为这个是通过文本生成图像,所以很容易的通过clip做为中间的桥梁,从而达到这种图片编辑的功能。
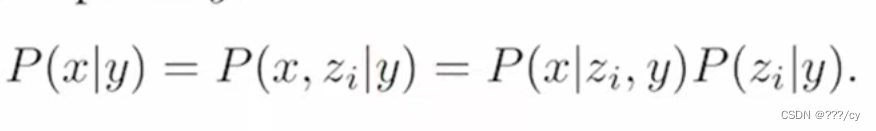
- 给定一个文本y, 恢复图像X。 他可以写成给定一个文本y, 然后生成图片对应的特征Zi,然后根据chain rule,就可以写成最后的式子了。’
- 给定文本生成图片特征,给定y,Zi之后,用图像embedding去生成图像X就是decoder
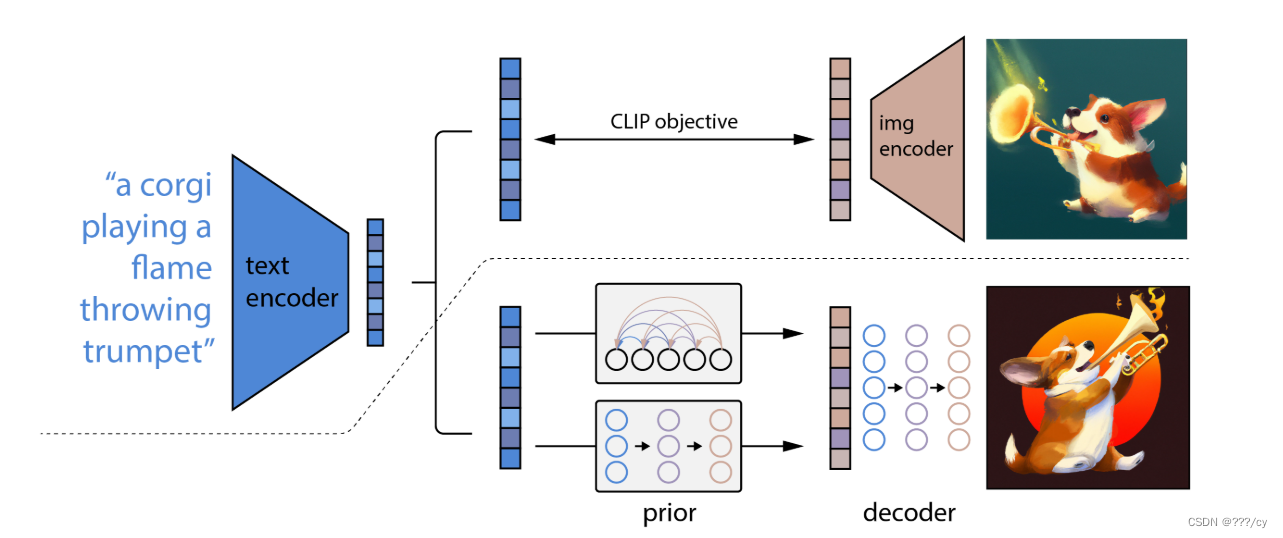
decoder
这里的decoder就是GLIDE模型的变体,他用了clip来作为guidance,也用了classifier-free guidance,能用的都用了。
为了产生高清大图,训练了两个扩散上采样模型,一个从64到256,一个模型从256到1024,
prior
给定一个文本,去生成一个图片的特征。
diffusion prior 作者训练了一个transformer decoder,因为他的输入输出是embedding,所以说用u-net就不太合适,直接上transformer去处理这个序列就可以了。
这里的输入有:文本,clip文本特征,time embedding, 加噪的clip图片特征,transformer自己的embedding(cls token)
最终这个embedding特征呢就拿去预测没有加过噪声的clip图片特征。
这里他不去预测噪声,直接去预测噪声图
简而言之,在GLIDE的基础上,加了prior,用了层级式的生成,最终做出了DALL-E.2。
三,文生图模型的总体架构
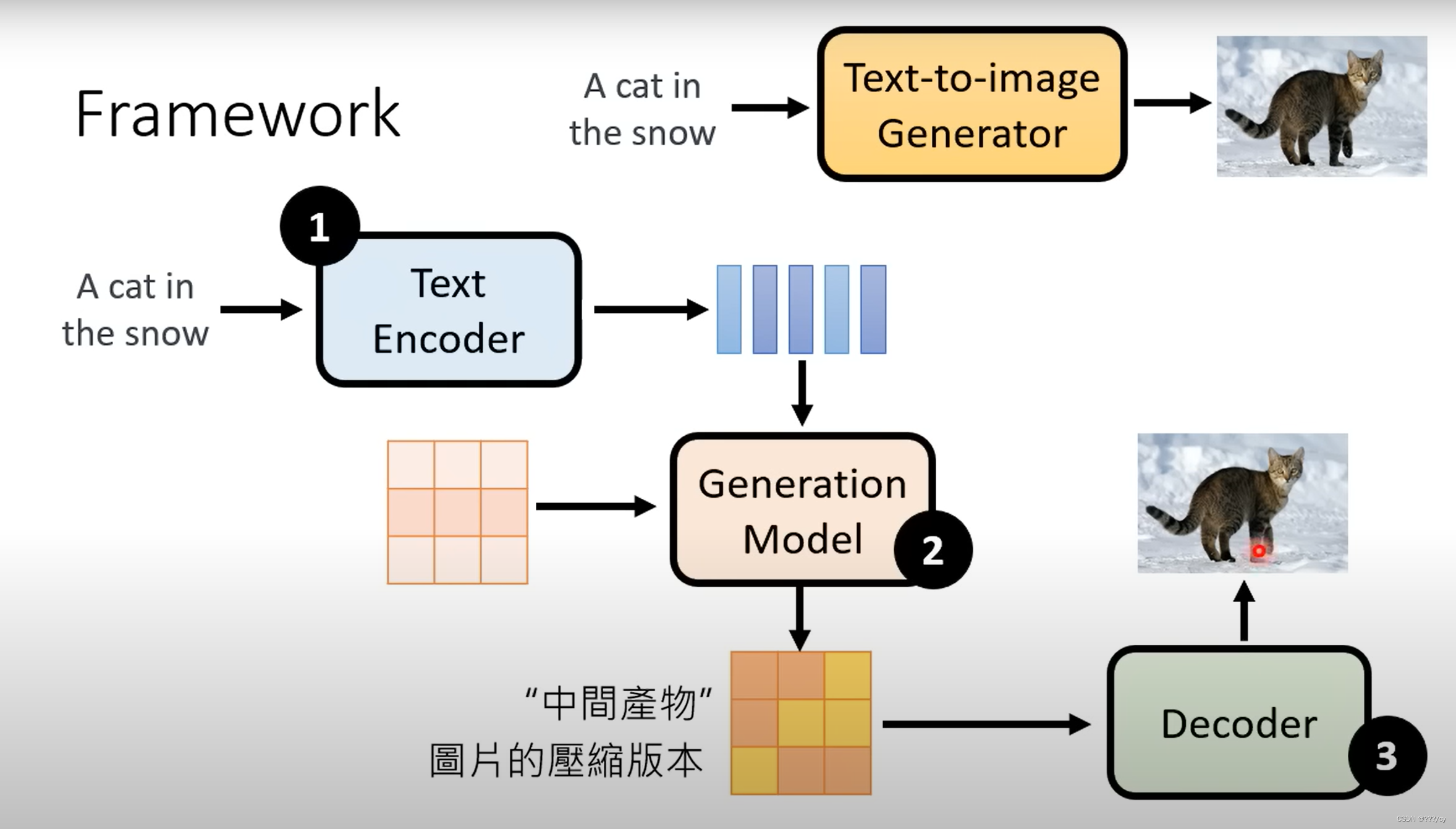
举几个例子:1. stable diffusion 2. DALL-E 系列 3. Imagen
用的trick都大不相同,总之就是大力出奇迹
| 模型 | 模型流程示意图 |
|---|---|
| Stable Diffusion |  |
| DALL-E 系列 | 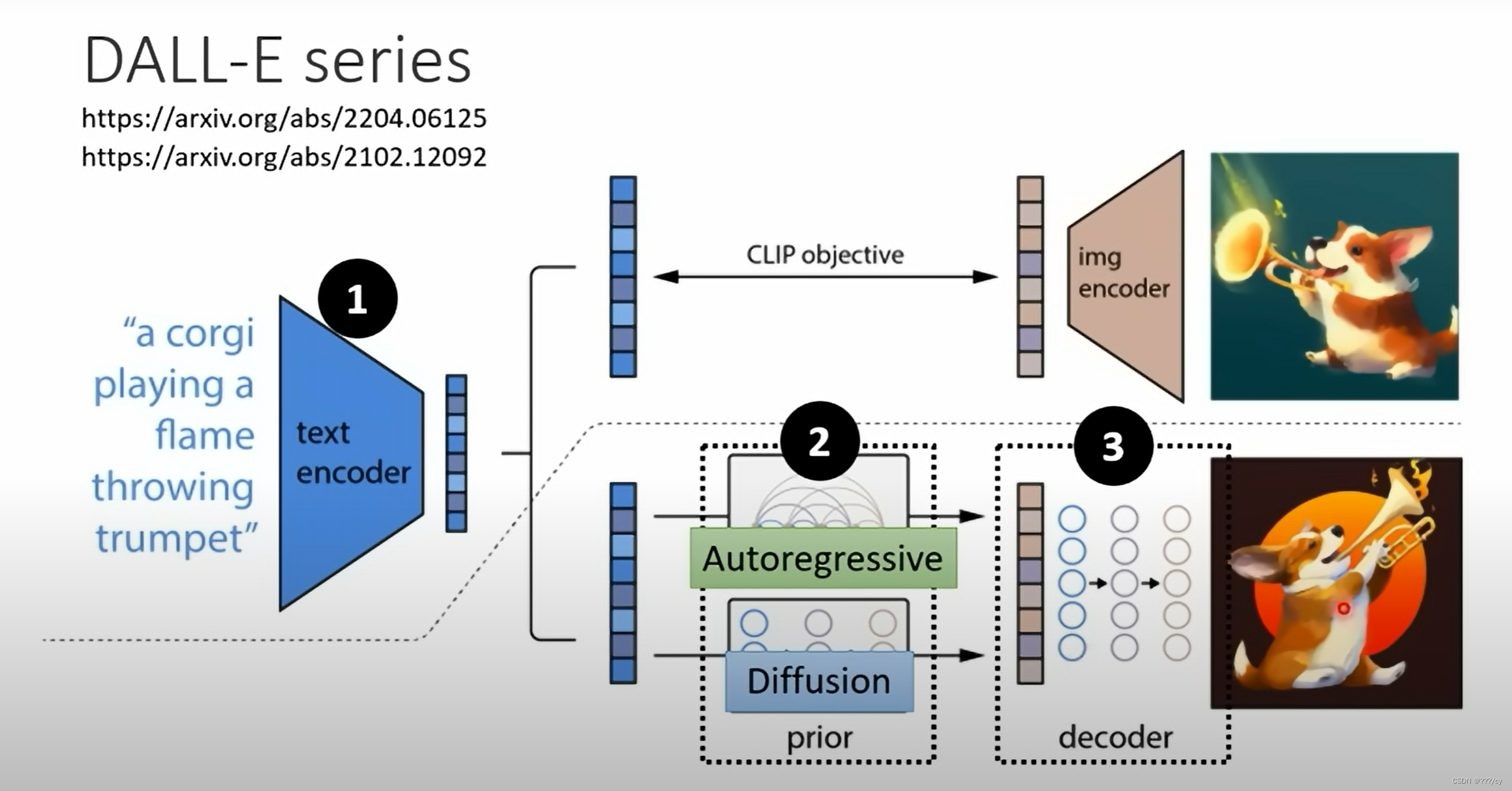 |
| Imagen | 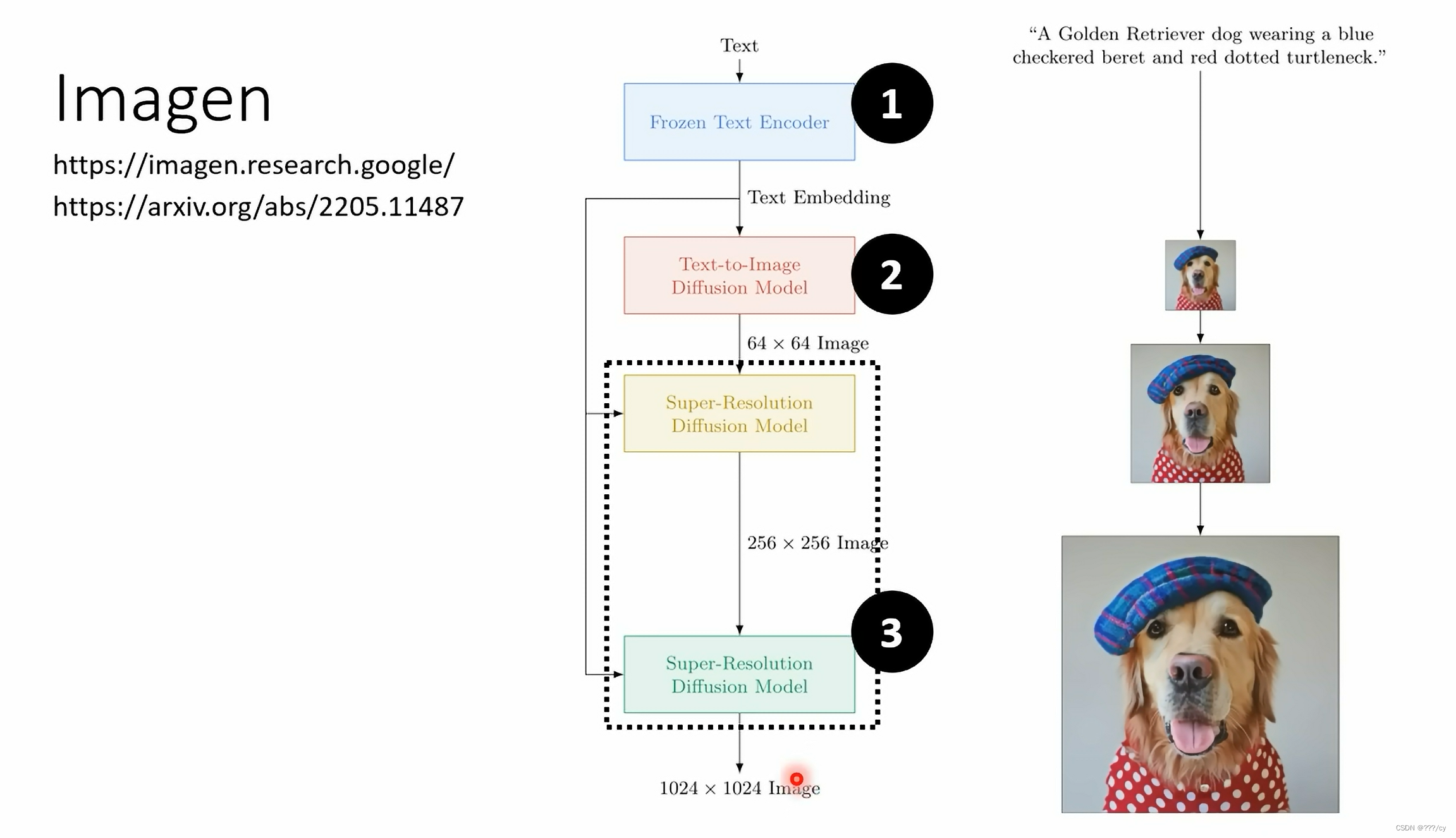 |
Text Encoder
Text Encoder: 把文本特征 ——> 图片特征。
所以训练的数据需要大量的 图像-文本对
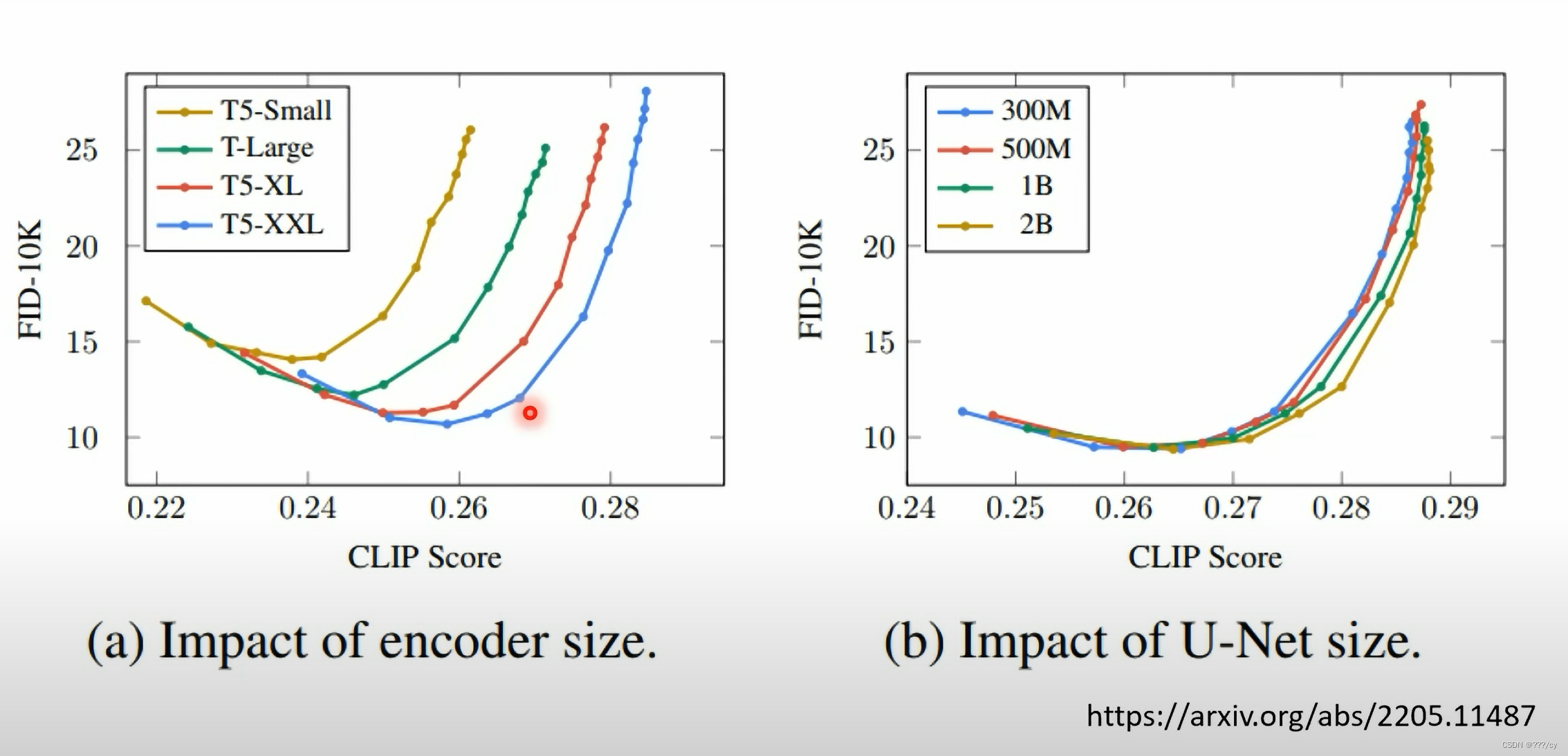
Imagen的实验说,Text Encoder 的模型越大,整个生成模型生成的图片越好。
相对而言,增大DIFFUSION MODEL 对 提升图片生成的效果有限
注:FID越小越好,他评估真实图片与生成图片的距离。 FID-10K的意思就是,他sample了10k数量的图片,来计算FID。
CLIP Score,越大越好, 说明生成的图片与文本联系度很高
Decoder
Decoder的作用:Image embedding → 还原成图片
- Imagen这个模型的 Image embedding 是小图

- stable diffusion, DALL-E 的Image embedding是一个 隐性的特征




![贪心算法[1]](https://img-blog.csdnimg.cn/direct/6783cc1559b641899a07b94a87ce2be4.png)