1. Hive简介
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
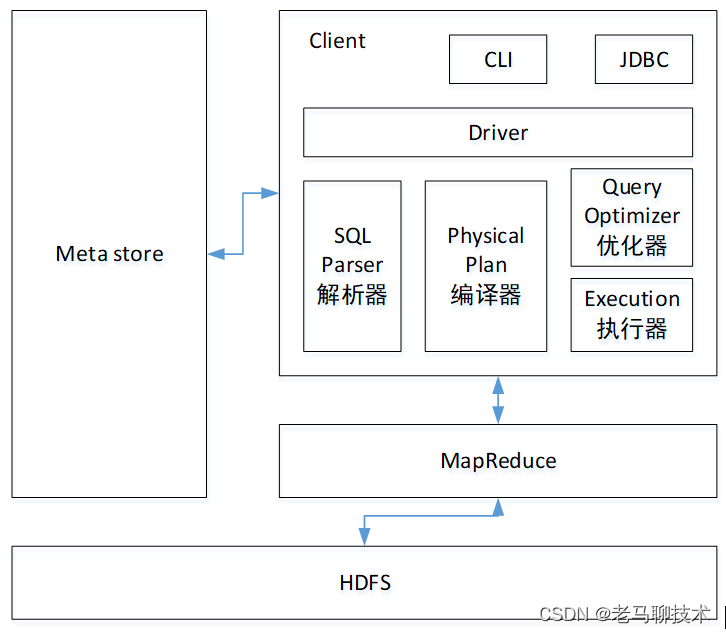
2. Hive体系结构
2.1 用户接口
用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 Cli,Cli 启动的时候,会同时启动一个 hive 副本。Client 是 hive 的客户端,用户连接至 hive Server。在启动 Client 模式的时候,需要指出 hive Server 所在节点,并且在该节点启动 hive Server。 WUI 是通过浏览器访问 hive。
2.2 元数据存储
hive 将元数据存储在数据库中,如 mysql、derby。hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
2.3 解释器、编译器、优化器、执行器
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
2.4 Hadoop
hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(不包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)。
2.5 架构图
3. Hive下载与安装
3.1 安装前的准备工作
3.1.1 Hadoop的安装与配置
3.1.2 MySQL的安装与配置
3.2 从hive官网下载hive的安装包
3.2.1 如下安装包(apache-hive-3.1.3-bin.tar.gz)
![]()
3.2.2 将hive安装包上传到 /opt 目录下

3.3 将hive安装文件解压到/usr/local/software 目录下,并重命名未 hive
tar -zxvf /opt/apache-hive-3.1.3-bin.tar.gz -C /usr/local/software/
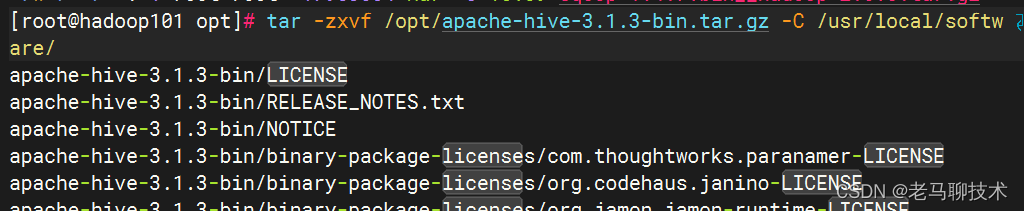
切换到 /usr/local/software/目录下,执行以下命令
mv apache-hive-3.1.3-bin hive

4. Hive 配置
4.1 配置文件
切换到/usr/local/software/hive/conf 目录下,赋值两个核心配置文件
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
4.2 配置 hive-env.sh 文件
主要配置 hadoop的安装目录与hive中conf的目录,如下
vim hive-env.sh
# hadoop 安装路径
export HADOOP_HOME=/usr/local/software/hadoop
# hive 配置文件路径
export HIVE_CONF_DIR=/usr/local/software/hive4.3 配置 hive-site.xml 文件
4.3.1 在此文件中配置数据库配置信息,将如下内容直接添加到hive-site.xml文件末尾即可
备注:此文件有6000多行,可以直接输入命令 G ,直接切换到文件末尾
<!-- 记录HIve中的元数据信息 记录在mysql中 --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop101:3306/hive?useUnicode=true&createDatabaseIfNotExist=true&characterEncoding=UTF8&useSSL=false&serverTimeZone=GMT</value></property><!-- jdbc mysql驱动 --><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property><!-- mysql的用户名和密码 --><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>laoma</value></property><!-- 日志目录 --><property><name>hive.querylog.location</name><value>/user/hive/log</value></property><!-- 设置metastore的节点信息 --><property><name>hive.metastore.uris</name><value>thrift://hadoop101:9083</value></property><!-- 客户端远程连接的端口 --><property> <name>hive.server2.thrift.port</name> <value>10000</value></property><property> <name>hive.server2.thrift.bind.host</name> <value>0.0.0.0</value></property><property><name>hive.server2.webui.host</name><value>0.0.0.0</value></property><!-- hive服务的页面的端口 --><property><name>hive.server2.webui.port</name><value>10002</value></property>4.3.2 hive-site.xml 内部需要修改三个内容
备注:一定要在文件中找到如下三个内容进行修改
hive.querylog.location
hive.exec.local.scratchdir
hive.downloaded.resources.dir
由于这三个属性对应的内容都使用到了相对路径,在使用的使用是有问题的,因此将三个属性对应的内容改为绝对路径,如下
<property><name>hive.querylog.location</name><value>/usr/local/sofeware/hive/log</value><description>Location of Hive run time structured log file</description></property>
<property><name>hive.exec.local.scratchdir</name><value>/usr/local/software/hive/local</value><description>Local scratch space for Hive jobs</description></property><property><name>hive.downloaded.resources.dir</name><value>/usr/local/software/hive/resources</value><description>Temporary local directory for added resources in the remote file system.</description></property>4.3.3 hive-site.xml 中特殊符号修改
hive-site.xml配置文件中,3215行(见报错记录第二行)有特殊字符:
进入hive-site.xml文件,跳转到对应行,删除里面的  特殊字符即可
跳转到指定行的命令:3215G
4.4 Hive 依赖包的修改与更新
4.4.1 删除原有的 protobuf-java-2.5.0.jar 文件
4.4.2 更新如下两个依赖包,上传到 hive/lib目录下
4.4.3 删除 hive/lib目录中的 guava-19.0.jar
拷贝hadoop/share/hadoop/common/lib目录中的 guava-27.0-jre.jar 到 hive/lib 目录
4.5 环境变量配置
vim /etc/profile.d/my_env.sh
export HIVE_HOME=/usr/local/software/hive
export HCATALOG_HOME=/usr/local/software/hive/hcatalogexport PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HCATALOG_HOME/bin:$HCATALOG_HOME/sbin更新环境变量
source /etc/profile
5. 初始化Hive的元数据库
5.1 注意-1:初始化元数据库之前,保证hadoop和mysql正常启动
注意-2:检查mysql的root用户是否可以远程访问
select User,Host from user;
update user set host = '%' where user='root';
flush privileges;
5.2 初始化元数据库
schematool -initSchema -dbType mysql
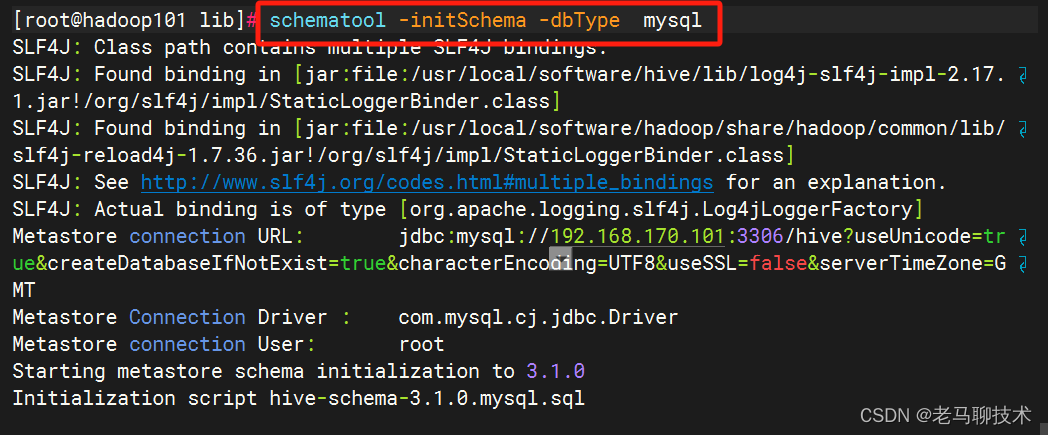
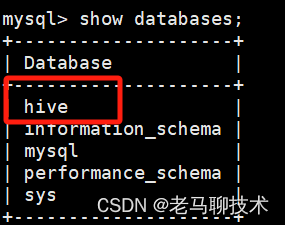
执行结果,登录MySQL查看 是否生成hive数据库
6. Hive 启动与访问
6.1 准备工作
先启动Hadoop 与MySQL 服务
6.2 启动metastore 元数据服务 节点
hive --service metastore
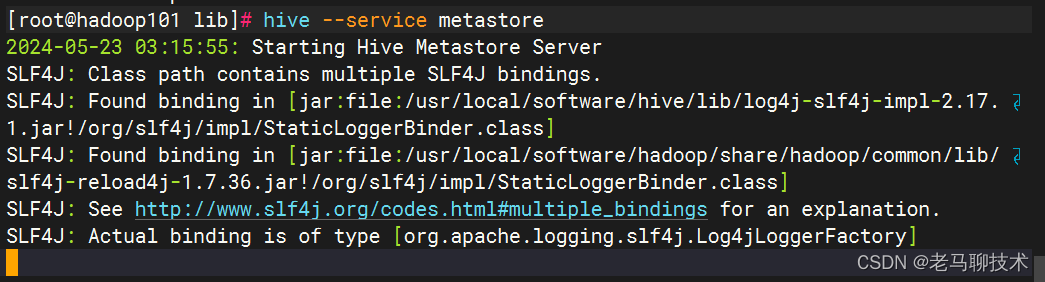
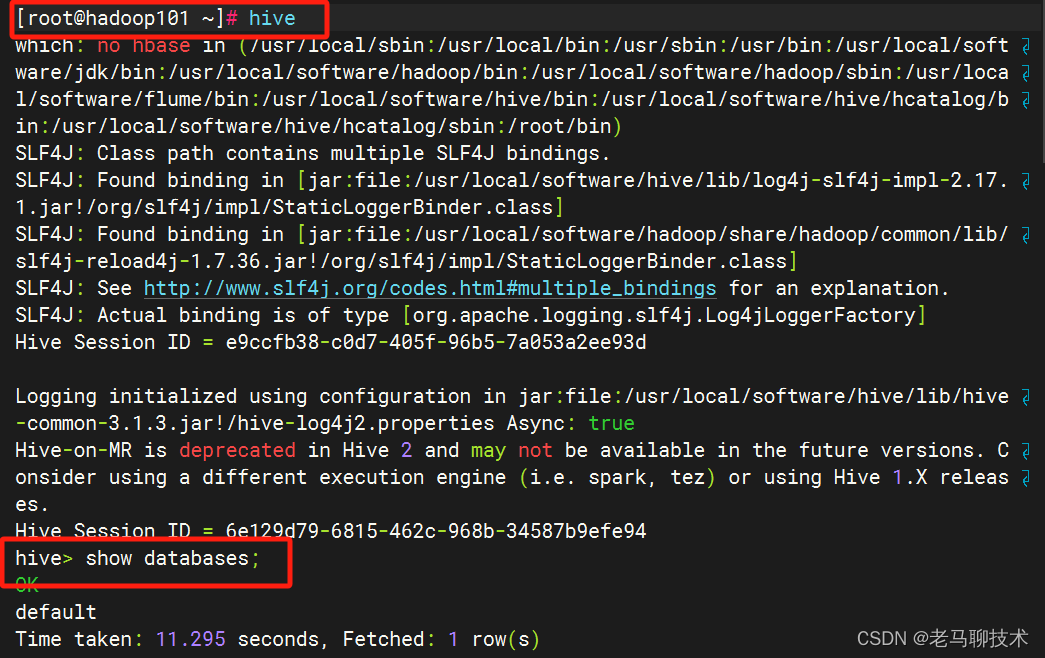
使用 hive 命令操作 hive数据库,并 查看 hive中默认的数据库
6.3 启动hiveserver2服务
HiveServer2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能。
hive --service hiveserver2
利用beeline连接hiveserver2服务
beeline -u jdbc:hive2://hadoop101:10000 -n root
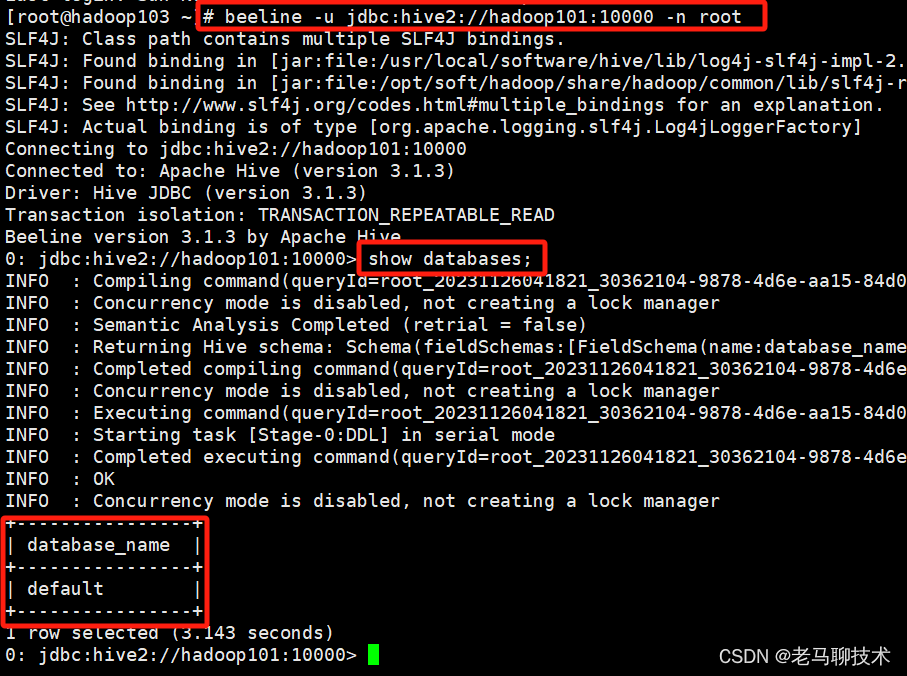
注意:如果beeline远程连接失败的时候,需要在hive-site.xml 配置中添加如下内容:(设置远程连接的用户名与密码)
<property><name>hive.server2.thrift.client.user</name><value>root</value><description>Username to use against thrift client</description></property><property><name>hive.server2.thrift.client.password</name><value>password</value><description>Password to use against thrift client</description></property>
7. Hive 后台启动
# 启动服务端 后台运行
hive --service metastore &
hive --service hiveserver2 &
# 启动服务端 后台运行
nohup hive --service metastore > /dev/null 2>&1 &
nohup hive --service hiveserver2 > /dev/null 2>&1 &
hiveserver2 start
nohup hiveserver2 start >/dev/null 2>&1 &
至此,整理完毕!