目录
一、线性表基本说明
1.1 基本概念
1.2 抽象数据类型
1.3 存储结构
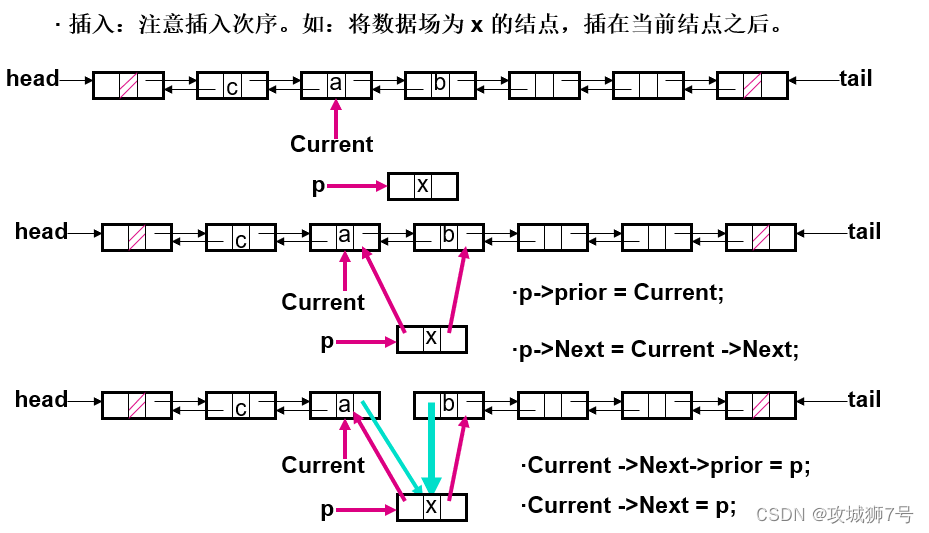
1.4 插入与删除的区别
1.5 顺序存储和链式存储的优缺点
二、链表
2.1 基本概念
2.2 抽象数据类型
2.3 单链表的定义
2.4 单链表的基本操作
2.5 单链表模板形式的类定义与实现
三、单向循环链表
四、双链表、双向循环链表
一、线性表基本说明
1.1 基本概念
线性表,零个或多个数据元素的有限序列称为线性表,例如一个字符串就是一个线性表,比如一个结构体数组也是一个线性表。

1.2 抽象数据类型
ADT 线性表(List)
Data
除第一个元素外,每一个元素有且只有一个直接前驱元素,除了最后一个元素外,每个元素有且只有一个直接后继元素,数据元素之间的关系是一对一的关系
Operation
初始化操作,建立一个空的线性表
若线性表为空,返回true,否则返回false
将线性表清空
将线性表中的第i个位置元素值返回给e
在线性表中查找与给定值e相等的元素,成功返回序号,否则返回0
在线性表中的第i个位置中插入新元素
在线性表中删除第i个位置的元素,并用e返回其值
返回线性表L的元素个数
endADT
1.3 存储结构
线性表的顺序存储
线性表的顺序存储结构,是指使用一段地址连续的存储单元依次存储线性表的数据元素。这种存储方式通常通过数组(Array)来实现,其中数组的每个元素都对应线性表中的一个数据元素。
在数组中,数据元素按照其在线性表中的逻辑顺序存储,即第一个数据元素存储在数组的第一个位置,第二个数据元素存储在第二个位置,依此类推。这种存储方式使得我们可以通过数组的索引直接访问线性表中的任何数据元素,而不需要遍历整个线性表。
需要注意的是,数组的总长度(即数据空间的总长度)并不一定等于线性表的长度。线性表的长度是指线性表中实际存储的数据元素个数,而数组的长度是数组中可以存储的最大数据元素个数。因此,数组的长度通常大于线性表的长度,以便在需要时可以动态扩展。
在实际编程中,我们通常会使用动态数组(Dynamic Array)来实现线性表的顺序存储结构,以便在需要时可以动态调整数组的大小。例如,当线性表的长度超过数组的长度时,可以创建一个新的更大的数组,并将原数组中的数据元素复制到新数组中。
线性表的链式存储
线性表的链式存储结构,是指使用链表(Linked List)来存储线性表的数据元素。在链式存储结构中,每个数据元素都包含一个数据项和一个指向下一个数据元素的指针。这种存储方式可以灵活地进行插入和删除操作,而不需要移动大量的数据。
链式存储结构的优点在于,当需要插入或删除元素时,只需要修改相关节点的指针,而不需要移动大量的数据。因此,链式存储结构在执行插入和删除操作时,通常比顺序存储结构更高效。
然而,链式存储结构也有其缺点。由于每个数据元素都包含一个指针,因此存储空间的利用率不如顺序存储结构高。此外,链式存储结构在执行查找操作时,需要从头开始遍历链表,直到找到目标元素或到达链表的末尾。因此,如果需要频繁地执行查找操作,顺序存储结构可能更适合。
总的来说,选择使用顺序存储结构还是链式存储结构,取决于具体的应用场景。如果需要频繁地执行插入和删除操作,并且数据量不大,那么链式存储结构可能更适合。如果需要频繁地执行查找操作,并且数据量较大,那么顺序存储结构可能更适合。

1.4 插入与删除的区别
顺序线性表的插入与删除:
在顺序存储结构下,线性表在插入新数据前需要将其插入点后面的数据依次后移一个单位,以空出位置让新数据插入
在顺序存储结构下,线性表在删除数据后需要将其删除点后面的数据依次前移一个单位,以补足删除后空出位置
链式线性表的插入与删除:
当我们想在链表中插入一个新数据的时候,只需要申请一段内存空间,然后将其前一个元素的指针指向自己,再将自己的指针指向下一个元素即可,无需操作其他元素
当我们想在链表中删除一个节点时,只需要将前一个节点指向后一个节点,并释放掉自己即可
1.5 顺序存储和链式存储的优缺点
顺序存储和链式存储是两种基本的数据结构,它们在存储和访问数据元素时各有优缺点。
顺序存储(顺序结构):
-
优点:顺序存储的优点在于存储效率高,存取速度快。由于数据元素存储在连续的内存空间中,因此可以通过下标直接访问任何元素,无需遍历整个数据结构。
-
缺点:顺序存储的缺点在于空间大小固定,不易扩充。一旦定义了存储空间的大小,就无法改变。此外,在插入或删除元素时,需要移动大量元素,这会降低效率。
链式存储(链式结构):
-
优点:链式存储的优点在于空间利用率高,可以动态分配和释放存储空间。此外,在插入和删除元素时,只需要修改链接指针,而不需要移动数据元素,因此效率较高。
-
缺点:链式存储的缺点在于存取元素时需要顺序查找,因此存取效率不高。此外,由于每个元素都包含一个指针,因此存储空间的利用率不如顺序存储高。
在实际应用中,选择顺序存储还是链式存储取决于具体的应用需求。如果需要频繁地插入和删除元素,并且数据量不大,那么链式存储可能更适合。如果需要频繁地查找元素,并且数据量较大,那么顺序存储可能更适合。
二、链表
2.1 基本概念
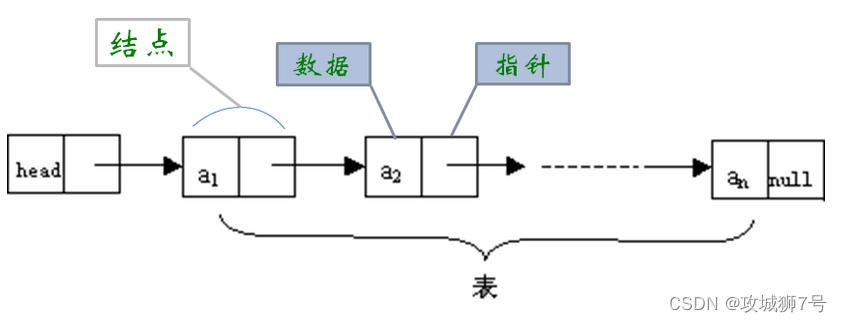
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。
每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址
的指针域循环链表是另一种形式的链式存贮结构。它的特点是表中最后一个结点的指针域指向头结点,整个链表形成一个环。
2.2 抽象数据类型
ADT 链表(List)
Data
除第一个元素外,每一个元素有且只有一个直接前驱元素,除了最后一个元素外,每个元素有且只有一个直接后继元素,数据元素之间的关系是一对一的关系
Operation
初始化操作,建立一个空的链表
若链表为空,返回true,否则返回false
将链表清空
将链表中的第i个位置元素值返回给e
在链表中查找与给定值e相等的元素,成功返回序号,否则返回0
在链表中的第i个位置中插入新元素
在链表中删除第i个位置的元素,并用e返回其值
返回链表的元素个数
endADT
2.3 单链表的定义
链表中最简单的一种是单向链表,它包含两个域,一个数据域和一个指针域。这个链接指向列表中的下一个节点,而最后一个节点则指向一个空值。
单向链表通常由一个头指针(head),用于指向链表头。单向链表有一个尾结点,该结点的指针部分指向一个空结点(NULL)。
2.4 单链表的基本操作
对链表的基本操作有:
创建链表是指,从无到有地建立起一个链表,即往空链表中依次插入若干结点,并保持结点之间的前驱和后继关系。
检索操作是指,按给定的结点索引号或检索条件,查找某个结点。如果找到指定的结点则称为检索成功;否则,称为检索失败。
插入操作是指,在结点之间插入一个新的结点,使线性表的长度增1。
删除操作是指,删除结点ki,使线性表的长度减1
打印输出。
2.5 单链表模板形式的类定义与实现
代码示例:
#include <iostream>// 定义链表节点结构体
template <typename T>
struct Node {T data;Node* next;Node(const T& value) : data(value), next(nullptr) {}
};// 单链表类模板
template <typename T>
class SingleLinkedList {
private:Node<T>* head;int size;public:SingleLinkedList() : head(nullptr), size(0) {}~SingleLinkedList() {while (head != nullptr) {Node<T>* temp = head;head = head->next;delete temp;}}// 插入元素到链表头部void push_front(const T& value) {Node<T>* newNode = new Node<T>(value);newNode->next = head;head = newNode;size++;}// 删除链表头部元素void pop_front() {if (head != nullptr) {Node<T>* temp = head;head = head->next;delete temp;size--;}}// 查找元素Node<T>* find(const T& value) {Node<T>* current = head;while (current != nullptr) {if (current->data == value) {return current;}current = current->next;}return nullptr; // 未找到返回nullptr}// 删除指定元素void remove(const T& value) {if (head == nullptr) return;if (head->data == value) {pop_front();return;}Node<T>* current = head;while (current->next != nullptr) {if (current->next->data == value) {Node<T>* temp = current->next;current->next = current->next->next;delete temp;size--;return;}current = current->next;}}// 获取链表大小int getSize() const {return size;}// 显示链表元素void display() const {Node<T>* current = head;while (current != nullptr) {std::cout << current->data << " ";current = current->next;}std::cout << std::endl;}
};// 示例使用
int main() {SingleLinkedList<int> list;// 插入元素list.push_front(10);list.push_front(20);list.push_front(30);list.display(); // 输出: 30 20 10// 删除元素list.pop_front();list.display(); // 输出: 20 10// 查找元素Node<int>* foundNode = list.find(20);if (foundNode != nullptr) {std::cout << "Found: " << foundNode->data << std::endl;} else {std::cout << "Not found" << std::endl;}// 删除指定元素list.remove(10);list.display(); // 输出: 20// 获取链表大小std::cout << "Size: " << list.getSize() << std::endl; // 输出: Size: 1return 0;
} 在这个代码中,我们定义了一个Node结构体模板来表示链表中的节点,每个节点包含一个数据项和一个指向下一个节点的指针。SingleLinkedList类模板定义了单链表的主要操作,包括构造函数、析构函数、push_front(在链表前端插入元素)、pop_front(从链表前端删除元素)、find(查找元素)、remove(删除指定元素)、getSize(获取链表大小)和display(显示链表中的所有元素)。
在main函数中,我们创建了一个SingleLinkedList<int>对象,并进行了一些操作,以展示如何使用这个模板类。这些操作包括插入元素、删除元素、查找元素、显示链表和获取链表大小。
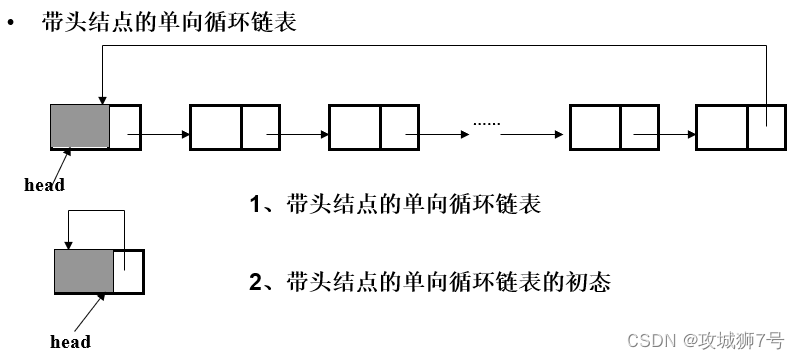
三、单向循环链表
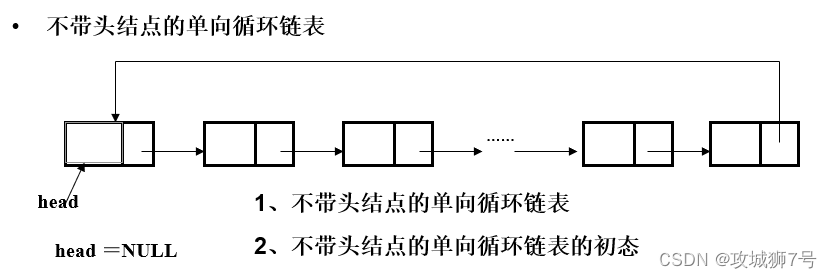
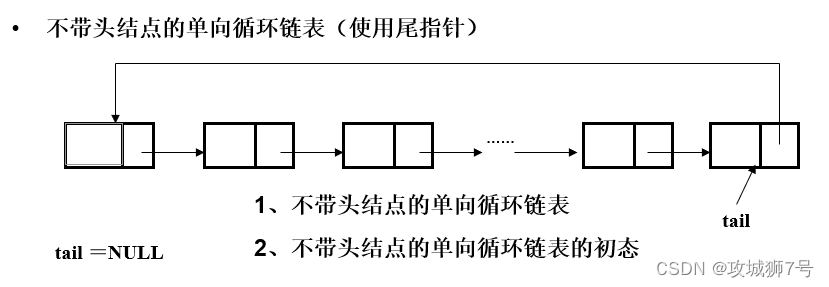
四、双链表、双向循环链表
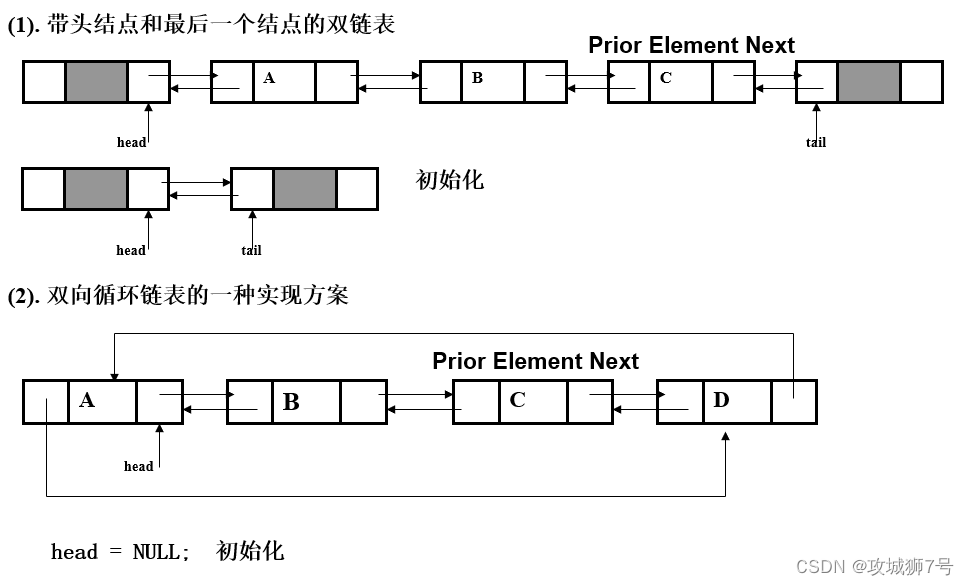
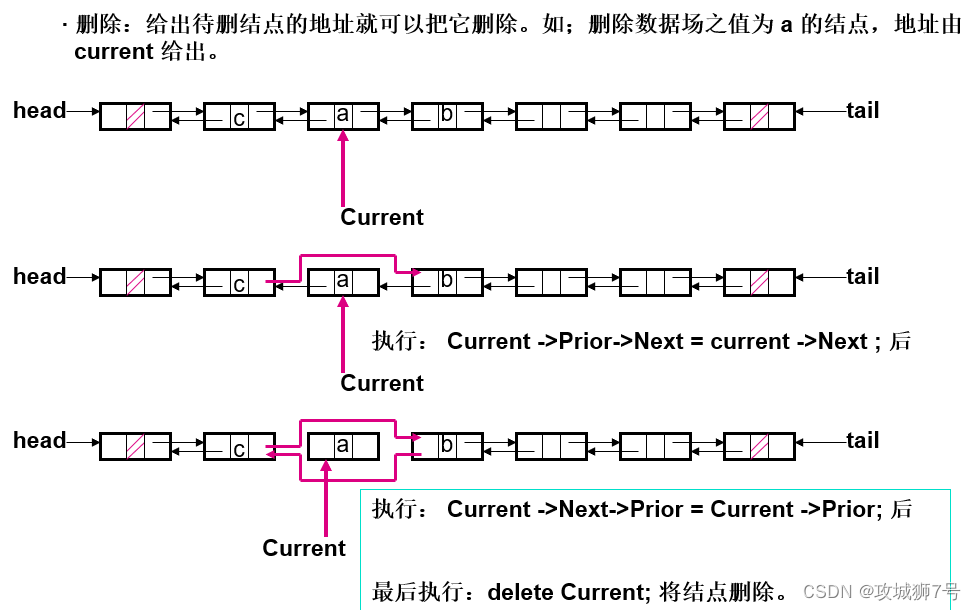
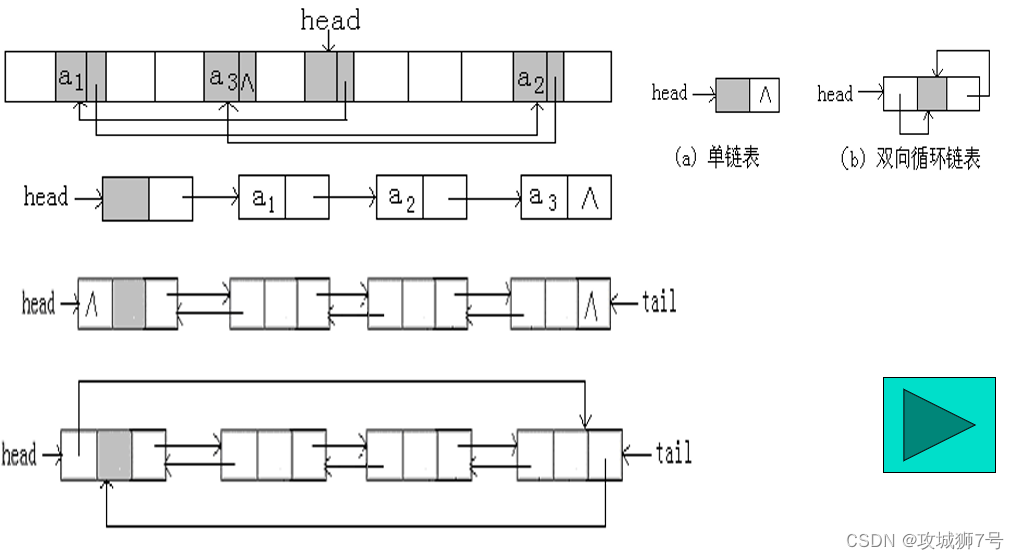
单向链表、单向循环链表、双向链表和双向循环链表都是链表数据结构的不同类型,它们在结构和操作上有所不同。以下是这些链表类型之间的主要区别:
-
单向链表:
-
每个节点包含一个数据项和一个指向下一个节点的指针。
-
链表的末尾节点的指针通常设置为
NULL,表示链表的结束。 -
单向链表不是循环的,它只能从头到尾遍历。
-
-
单向循环链表:
-
与单向链表类似,但链表的最后一个节点的指针指向链表的第一个节点,形成一个循环。
-
这种类型的链表可以从任何节点开始遍历,并且可以无限期地继续。
-
-
双向链表:
-
每个节点包含一个数据项、一个指向下一个节点的指针和一个指向前一个节点的指针。
-
链表的第一个节点的前向指针通常设置为
NULL,表示链表的开始。 -
链表的最后一个节点的后向指针通常设置为
NULL,表示链表的结束。 -
双向链表可以从任意节点开始向前或向后遍历。
-
-
双向循环链表:
-
与双向链表类似,但链表的第一个节点的后向指针指向链表的最后一个节点,形成一个循环。
-
链表的最后一个节点的前向指针指向链表的第一个节点,形成另一个循环。
-
双向循环链表可以从任意节点开始向前或向后遍历,并且可以无限期地继续。
-
选择哪种链表类型取决于你的具体需求。例如,如果你需要频繁地在链表的两端插入和删除元素,双向链表可能是一个好的选择。如果你需要在链表中进行循环遍历,那么单向循环链表或双向循环链表可能更适合。
关于它们的更具体实现和应用后面再详细讲解。