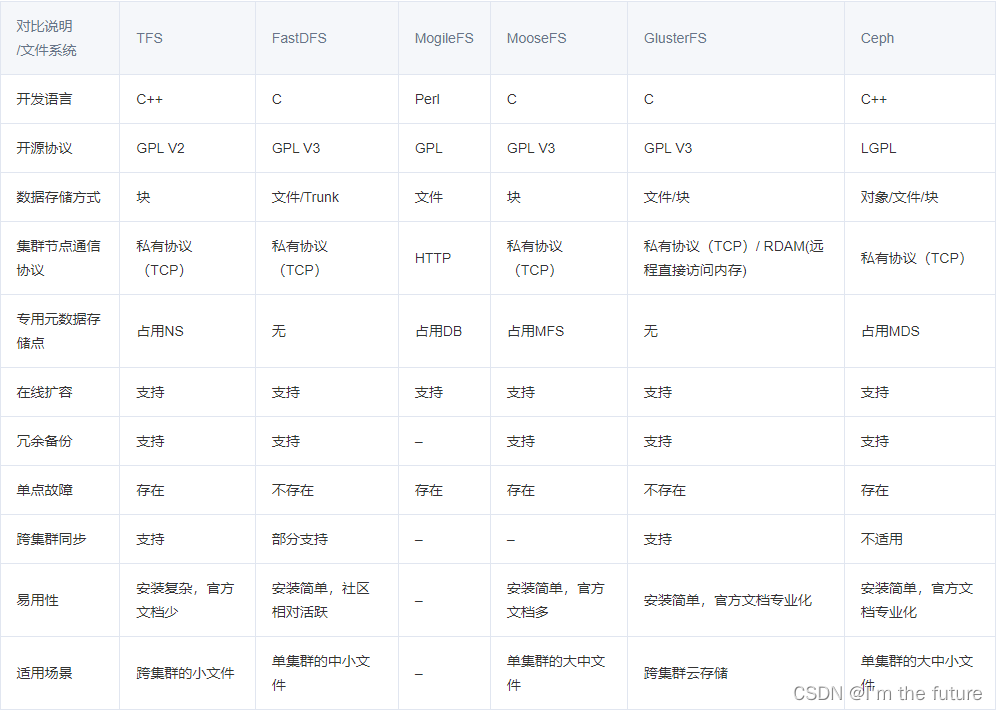
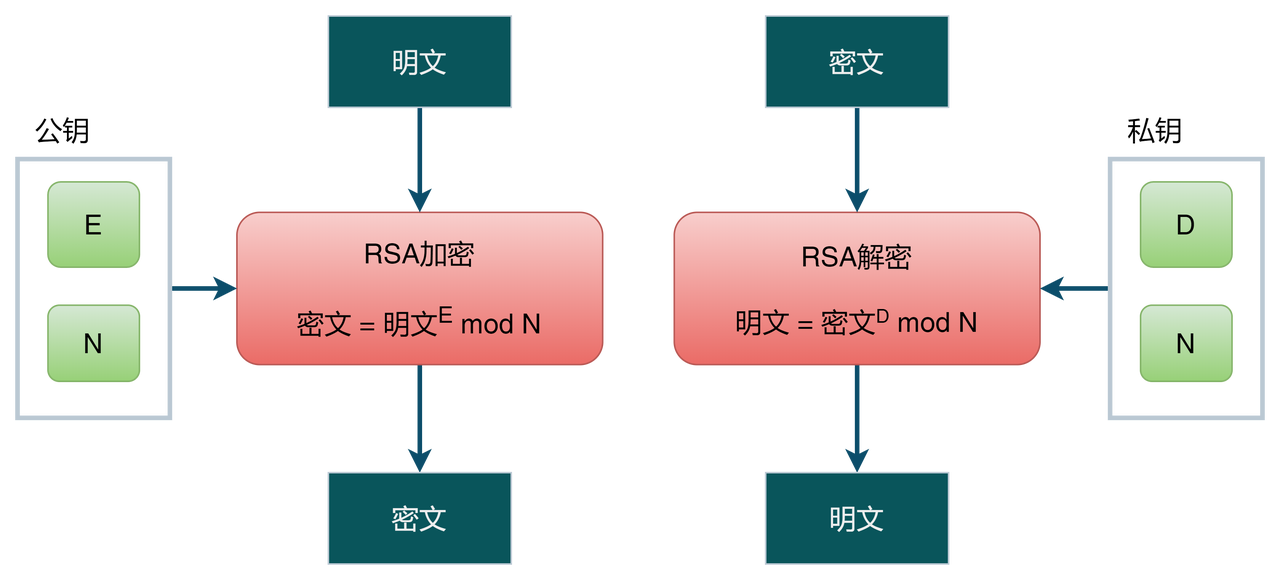
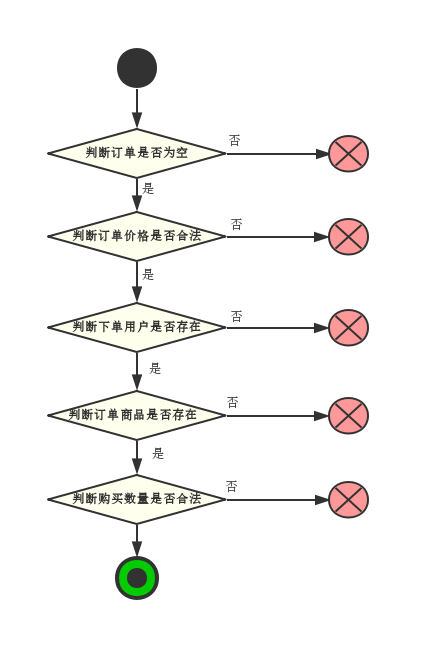
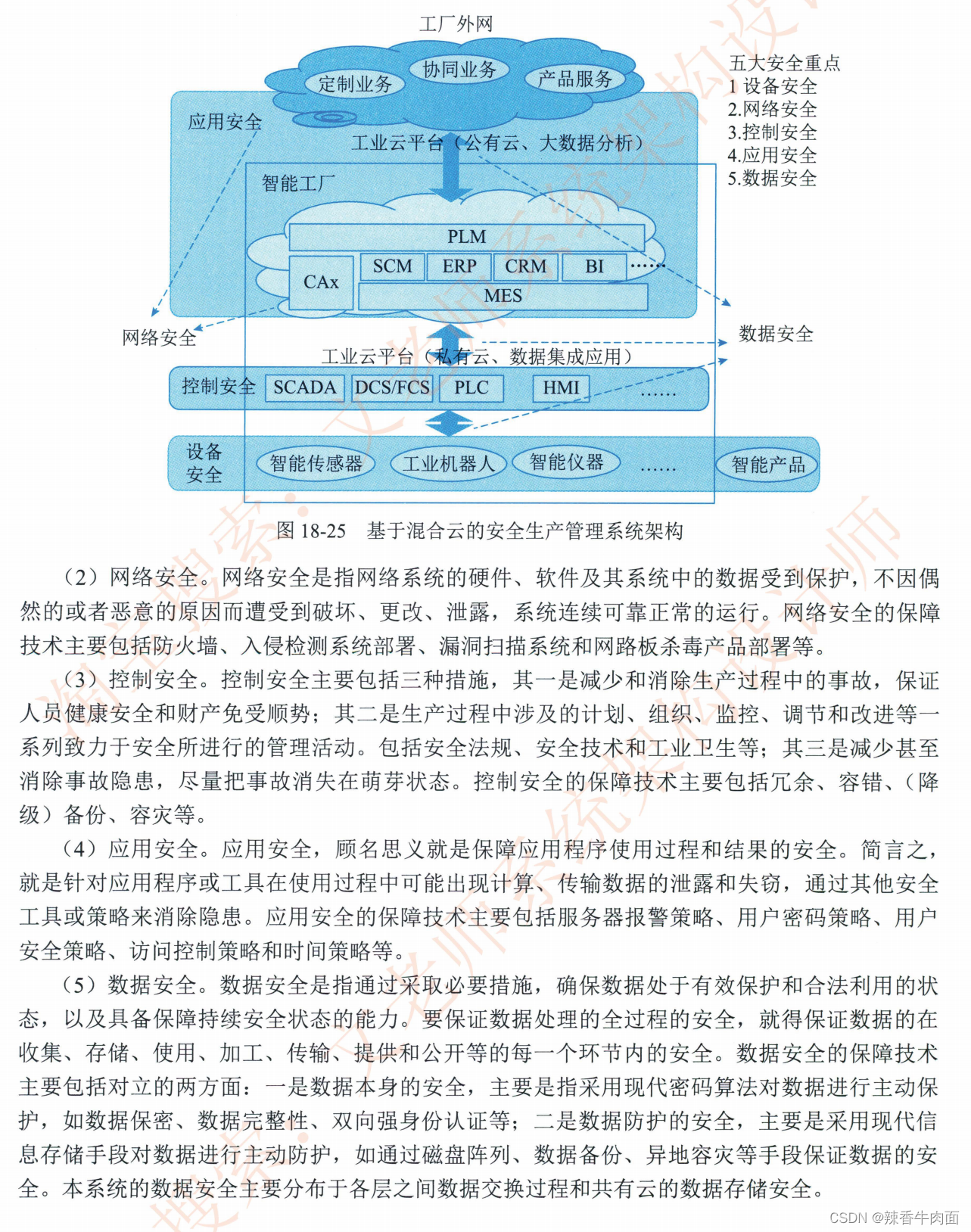
一、DMABUF 框架
dmabuf 是一个驱动间共享buf 的机制,他的简单使用场景如下:

用户从DRM(显示驱动)申请一个dmabuf,把dmabuf 设置给GPU驱动,并启动GPU将数据输出到dmabuf,GPU输出完成后,再将dmabuf设置到DRM 驱动,完成画面的显示。
在这个过程中通过共享dmabuf的方式,避免了GPU输出数据拷贝到drm frame buff的动作。
如下所示,dmabuf 框架分为用户层和驱动层,用户层可以通过 /dev/dmabuf_heap/xxx节点,从名称为xxx的dma heap 中申请dmabuf。申请到的dmabuf 在用户层的视角就是一个文件,并由fd 标识一个dmabuf。将fd 通过DRM、GPU接口传给驱动,驱动就能共享这个dmabuf。
以下是一个简单的dmabuf 的示例代码:
int fd, dmabuf_fd;
struct dma_heap_allocation_data data;
struct pollfd fds;data.len = 1024 * 1024 * 4;
//打开dma heap
fd = open("/dev/dma-heap/xxx");//从dma heap 申请dmabuf
ioctl(fd, DMA_HEAP_IOCTL_ALLOC, &data);//将dmabuf的fd 设置到gpu进行处理
set_dmabuf_to_gpu(data.fd);//等待gpu 输出完毕
fds.fd = data.fd;
fds.events = POLLIN | POLLOUT;
poll(fds, 1, TIMEOUT);//将dmabuf 设置到drm显示
set_dmabuf_to_drm(data.fd);//等待显示完成
poll(fds, 1, TIMEOUT);//释放dmabuf
close(data.fd);
二、DMA Heap
dma heap 就是一个dmabuf 内存池,让用户可以从内存池中申请dmabuf。其代码主要在dma-heap.c,设备驱动可以创建自己的dma heap,从而提供给用户申请dmabuf。例如DRM驱动可以创建一个DRM dma heap。DRM驱动最重要的就算实现struct dma_heap_ops 对象,这个对象需要实现allocate() 函数,即当用户从dma heap 申请dmabuf 时,DRM驱动要如何分配真实的物理内存。
struct dma_heap_ops {int (*allocate)(struct dma_heap *heap,unsigned long len,unsigned long fd_flags,unsigned long heap_flags);
};struct dma_heap {const char *name;const struct dma_heap_ops *ops; //主要实现申请dmabuf的回调函数void *priv;dev_t heap_devt;struct list_head list;struct cdev heap_cdev;
};
dma-heap.c 中其他的代码主要是实现一个简单设备驱动,提供接口给用户。
三、dmabuf
3.1、dmabuf使用场景
在dmabuf 的使用场景中,有两种驱动:exporter 和 importer。
- exporter 是dmabuf 的提供者,是实现dma heap的驱动程序,负责dmabuf 对应的物理内存的申请、释放、映射等实现。
- importer 是dmabuf的使用者,是使用dmabuf 进行输入输出数据的驱动程序,他不关心dmabuf的申请释放,只需要往dmabuf 里读写数据即可。
像上述例子中,DRM驱动首先是exporter,允许用户从dma heap申请内存,又是importer,从dmabuf 中读取数据显示到屏幕。而GPU是纯纯的importer,向dmabuf 中写入数据。
这两种角色的关系如下图所示:

从上述图可见dma_buf_ops 的实现至关重要。所以接下来我们关注dmabuf是如何被创建的。
3.2、dmabuf的创建
dmabuf 是如何从dma heap 中被申请出来的?这部分主要是在allocate回调函数实现的,在大部分驱动中,allocate回调函数中会从物理内存中申请内存,并 调用dma_buf_export() 创建一个dmabuf 对象。
所以我们的重点将分析 dma_buf_export() 函数是如何创建一个dmabuf 对象的。
首先还是看dmabuf 的结构体定义:
struct dma_buf {size_t size;struct file *file; //匿名文件,代表该dmabuf,暴露给用户从而支持跨驱动传输struct list_head attachments; //attachment 链表const struct dma_buf_ops *ops; //重要的回调函数void *vmap_ptr; //dmabuf kernel 地址struct dma_resv *resv; //保留区,用于存放dma fence对象/* poll support */wait_queue_head_t poll; //等待队列,用于pollstruct dma_buf_poll_cb_t {struct dma_fence_cb cb;wait_queue_head_t *poll;__poll_t active;} cb_excl, cb_shared; //用于poll、dma fence
};
以下是dma_buf_export() 的简略版,很简单就是根据exp_info 初始化dmabuf对象,并创建一个文件,将dmabuf 与文件绑定起来。
struct dma_buf *dma_buf_export(const struct dma_buf_export_info *exp_info)
{//初始dmabuf 对象dmabuf = kzalloc(alloc_size, GFP_KERNEL);dmabuf->priv = exp_info->priv;dmabuf->ops = exp_info->ops;dmabuf->size = exp_info->size;dmabuf->exp_name = exp_info->exp_name;dmabuf->owner = exp_info->owner;spin_lock_init(&dmabuf->name_lock);init_waitqueue_head(&dmabuf->poll);dmabuf->cb_excl.poll = dmabuf->cb_shared.poll = &dmabuf->poll;dmabuf->cb_excl.active = dmabuf->cb_shared.active = 0;if (!resv) {resv = (struct dma_resv *)&dmabuf[1];dma_resv_init(resv);}dmabuf->resv = resv;//初始化filefile = dma_buf_getfile(dmabuf, exp_info->flags);file->f_mode |= FMODE_LSEEK;dmabuf->file = file;mutex_init(&dmabuf->lock);INIT_LIST_HEAD(&dmabuf->attachments);//添加到全局链表mutex_lock(&db_list.lock);list_add(&dmabuf->list_node, &db_list.head);mutex_unlock(&db_list.lock);return dmabuf;
}
3.3、dma_buf_ops
exporter驱动只关注struct dma_buf_export_info 对象即可,最重要的是struct dma_buf_ops对象的实现,这点需要根据具体的驱动实现。所以下面分析这些回调函数的含义是什么:
struct dma_buf_ops {//判断当前设备是否能够访问dmabuf的物理内存,一些物理内存只能由指定的设备访问如vram。若设备可以访问改物理内存,则返回一个attachment代表此次访问int (*attach)(struct dma_buf *, struct dma_buf_attachment *);//释放之前获取的attachmentvoid (*detach)(struct dma_buf *, struct dma_buf_attachment *);//importer 调用这个函数,锁定dmabuf的物理内存,使其不能被迁移int (*pin)(struct dma_buf_attachment *attach);//解锁物理内存void (*unpin)(struct dma_buf_attachment *attach);//将dmabuf的物理内存映射到importer的地址空间,表示importer要开始访问物理内存//因为exporter要让所以attach的设备都能访问,所以可能要将物理内存移动到合适的地址,所以函数可能休眠//返回一个sg_table,表示物理地址散列表struct sg_table * (*map_dma_buf)(struct dma_buf_attachment *,enum dma_data_direction);//解除映射并释放sg_tablevoid (*unmap_dma_buf)(struct dma_buf_attachment *,struct sg_table *,enum dma_data_direction);//释放dmabuf,exporter在这个函数释放私有数据void (*release)(struct dma_buf *);//importer在使用cpu读取dmabuf前,调用该接口让exporter 确保数据在内存上且cpu能读取到正确的数据int (*begin_cpu_access)(struct dma_buf *, enum dma_data_direction);//结束cpu 访问int (*end_cpu_access)(struct dma_buf *, enum dma_data_direction);//将dmabuf 物理内存map 到用户地址空间int (*mmap)(struct dma_buf *, struct vm_area_struct *vma);//将dmabuf 物理内存map到内核地址空间void *(*vmap)(struct dma_buf *);void (*vunmap)(struct dma_buf *, void *vaddr);
};
dmabuf框架将一个驱动访问物理内存的动作拆分成这么多个步骤,目的就是为了多个设备能共享一个物理内存,而每个设备的访问能力,访问地址空间都可能不一样,这就需要将访问过程细细拆分,协调好每个设备的访问顺序和关系。
四、dma-fence
dma fence 是用于做同步的。考虑以下场景:
一个dmabuf,先由GPU完成渲染,然后再交给DRM进行显示输出。那么GPU渲染完成后,如何通知DRM进行显示输出呢?也就是GPU和DRM之前如何进行同步?这就需要引入fence用于设备间的同步,fence用于表示一个操作的完成状态,故fence有两个状态,not done和done。
首先GPU在开始渲染操作前,创建一个fence,注册回调函数,将fence添加到dmabuf 中,随后DRM 等待该fence done。当GPU渲染完成中断上来后,会通知fence done。随后DRM线程被唤醒,进行显示操作。
另外,dma fence还需要考虑多设备访问的情况,即可能有多个设备在等待fence完成,那么fence就必须支持多个设备的等待。
那么就先看dma fence的定义:
struct dma_fence {spinlock_t *lock;const struct dma_fence_ops *ops;union {struct list_head cb_list; //回调函数链表,每个等待fence的驱动,都需要注册一个回调节点到该链表,当fence done时,会遍历该链表执行所有驱动的回调函数。/* @cb_list replaced by @timestamp on dma_fence_signal() */ktime_t timestamp;/* @timestamp replaced by @rcu on dma_fence_release() */struct rcu_head rcu;};u64 context;u64 seqno;unsigned long flags;struct kref refcount;int error;
};
如图所示:GPU线程会在操作dmabuf 前,创建fence,并等待fence完成,同时DRM也会等待该fence完成。当GPU渲染完成中断产生后,会调用fence done,依次唤醒GPU、DRM线程,GPU线程此时就可以继续下一帧图像的渲染,而DRM就可以将已经完成渲染的图像显示到屏幕。

这个过程中调用的接口有:
- dma_fence_init():初始化一个dma fence对象
- dma_resv_reserve_shared() :从dma resv 中保留一个share fence 指针
- dma_resv_add_shared_fence():将dma fence添加到resv 对象
- dma_fence_default_wait():向dma fence注册回调函数dma_fence_default_wait_cb,并睡眠等待dma fence完成
- dma_fence_signal():标志dma fence 完成,并回调dma fence 中的所有回调函数
其中有一个叫dma_resv的对象,简单来说dma_resv 是一个存放dma fence的地方,一个dmabuf 可能同时有若干个dma fence,且dma fence还有共享和独占两种。dma_resv可以理解为一块内存区域,专门存放dma fence的,故要将dma fence添加到dmabuf时,要先调用dma_resv_reserve_shared() 预留出dma fence的位置,然后再调用dma_resv_add_shared_fence() 添加到dma resv。
五、poll
前面所述都是在内核态,但对于用户来说,也希望获取到设备的同步信息。例如在本文一开始的例子中,用户会使用poll 系统调用等待gpu渲染完成。这一切都是由dma_buf_fops来实现的。
在3.2中提到dmabuf的创建中,有一个步骤会创建匿名文件,这个匿名文件就是用于暴露给用户的接口。这个文件代表了一个dmabuf,用户通过该文件的fd可以操作该dmabuf的一些功能,dma_buf_fops是所有dmabuf 共享的file_operations,其中就包括poll的实现。
当用户调用poll 系统调用等待dmabuf时,会遍历dmabuf 上的所有fence,并将回调函数dma_buf_poll_cb注册到每一个fence上,并进入休眠。当有任意一个fence done时,就会唤醒用户线程,从而退出poll。