一、什么叫RC4?优点和缺点
RC4是对称密码(加密解密使用同一个密钥)算法中的流密码(一个字节一个字节的进行加密)加密算法。
优点:简单、灵活、作用范围广,速度快
缺点:安全性能较差,容易被爆破
密钥长度可变
以一个足够大的表S为基础,对表进行非线性变换(一个变换就是一个函数),从而产生密钥流
二、加密解密原理
1.初始化S表(KSA):
对S表进行线性填充,s[0]=0到s[255]=255,一般为256个字节;
用种子密钥填充另一个256字节的K表,如果种子密钥是256的话,那么刚好填充完K表,如果校园长度小于256的话,K表里面的值就密钥的循环使用;
用K表对S表进行初始置换,就是从s[0]开始到s[255],对每个s[i]根据k[i]确定一个方案,将s[i]置换为s中的另一个字节;
假设种子密钥是3,4,5 那么进行循环填充
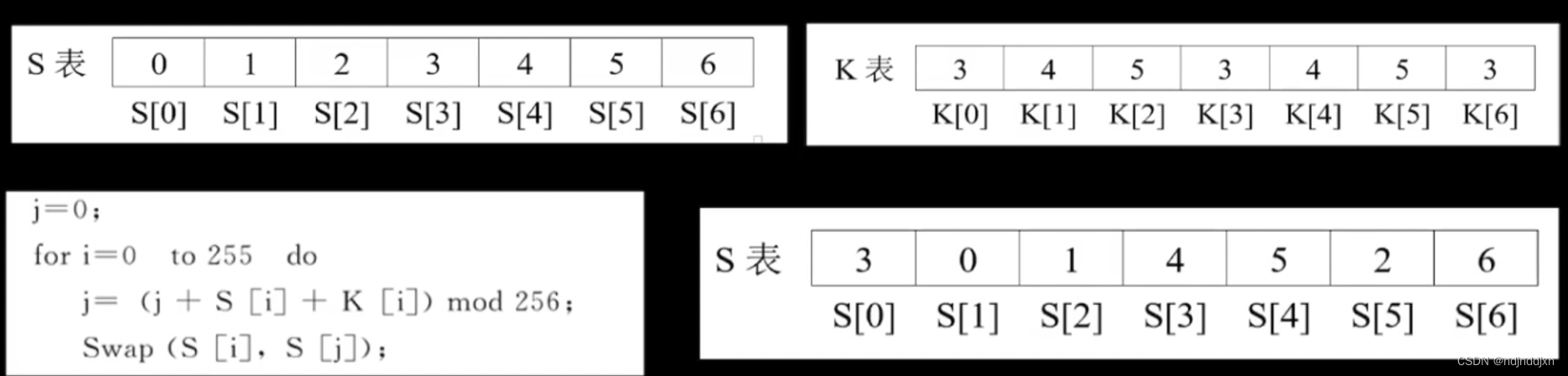
从i=0到 i=255都要进行表内置换,根据公式,j=0+0+3=3,而 mod 256,这里mod 7然后将s[0]和s[3]进行一个置换,那么就得到新的3,1,2,0,4,5,6,将将这个过程循环七次后得到最后的那个S表
S表一但完成初始化,种子密钥就不再使用了。
2.生成密钥流(PRGA)
因为是流密码,所以我们需要为每个待加密的字节生成一个用来异或的随机数值,这个数值也是从s表中获取,那么接下来就是找到它的下标
例如:代码

得到 i=1,j=0,t=3,t就是下标的值
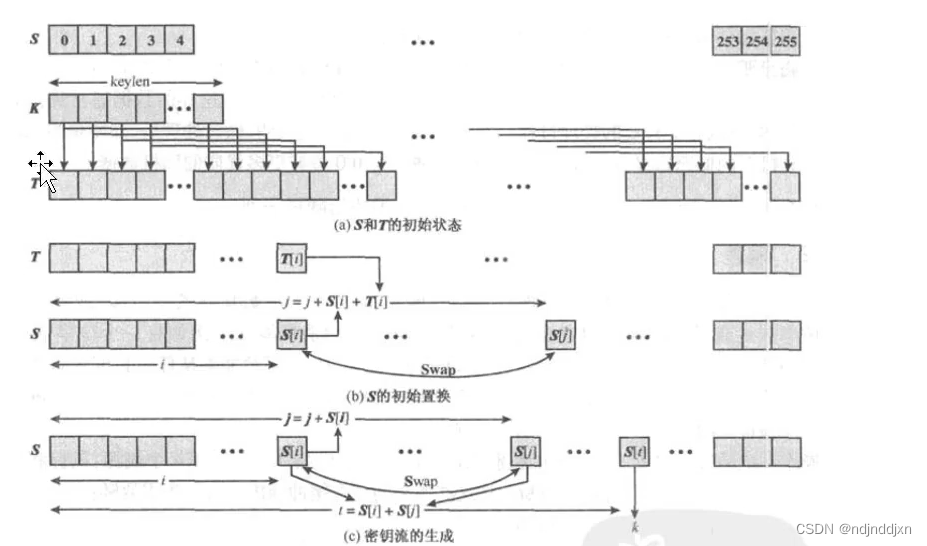
3.密钥流与明文进行异或
三、Python和c语言实现简单的RC4
c语言:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>//s表的长度取256
#define size 256unsigned char sbox[257]={0};//初始化s表
void init_sbox(unsigned char*key){unsigned int i,j,k;int tmp;for(i=0;i<size;i++){sbox[i]=i;}j=k=0;for(i=0;i<size;i++){tmp=sbox[i];j=(j+tmp+key[k])%size;sbox[i]=sbox[j];sbox[j]=tmp;if(++k>=strlen((char*)key))k=0;}
}//加解密函数
void enc_dec(unsigned char*key,unsigned char*data){int i,j,k,R,tmp;init_sbox(key);j=k=0; for(i=0;i<strlen((char*)data);i++){j=(j+1)%size;k=(k+sbox[j])%size;tmp=sbox[j];sbox[j]=sbox[k];sbox[k]=tmp;R=sbox[(sbox[j]+sbox[k])%size];data[i]^=R;}
}int main(){unsigned char key[100]={0};unsigned char data[100]={0};printf("输入你要加密的字符:");scanf("%100s",data);printf("输入密钥:");scanf("%40s",key);enc_dec(key,data);printf("enc: %s\n",data);enc_dec(key,data);printf("dec: %s\n",data);return 0;
}
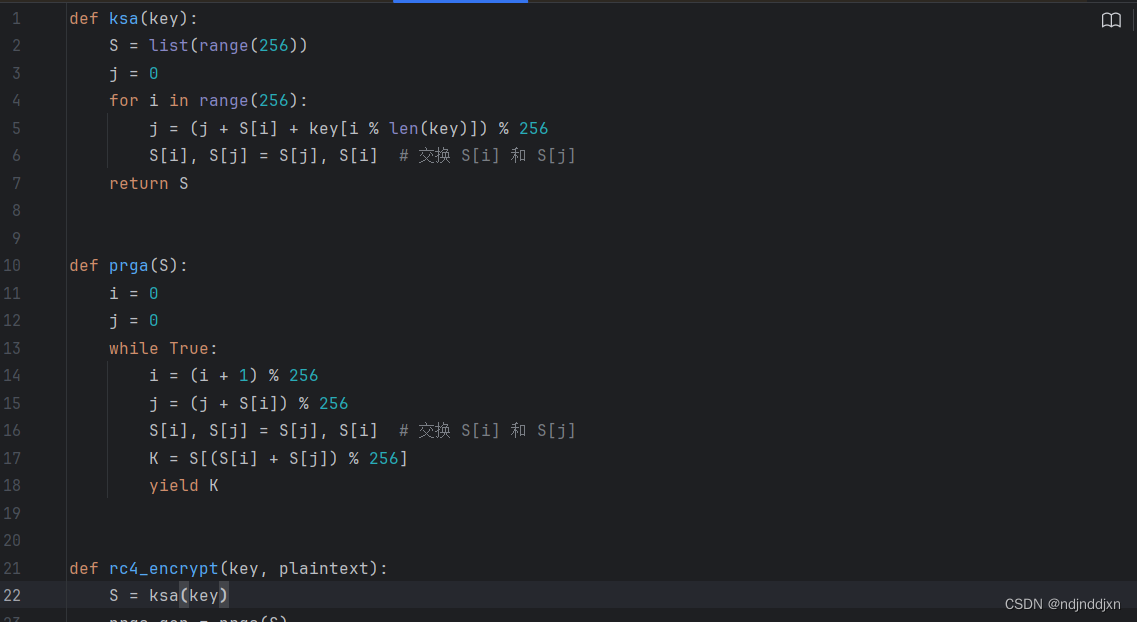
pyhthon实现:
def ksa(key):S = list(range(256))j = 0for i in range(256):j = (j + S[i] + key[i % len(key)]) % 256S[i], S[j] = S[j], S[i] # 交换 S[i] 和 S[j]return Sdef prga(S):i = 0j = 0while True:i = (i + 1) % 256j = (j + S[i]) % 256S[i], S[j] = S[j], S[i] # 交换 S[i] 和 S[j]K = S[(S[i] + S[j]) % 256]yield Kdef rc4_encrypt(key, plaintext):S = ksa(key)prga_gen = prga(S)ciphertext = bytearray()for byte in plaintext:K = next(prga_gen)ciphertext.append(byte ^ K)return ciphertextdef rc4_decrypt(key, ciphertext):# 对于 RC4,加密和解密过程是相同的return rc4_encrypt(key, ciphertext)# 示例用法
key = b'Secret'
# 原始字符串
plaintext= "Hello, World!"# 将字符串转换为UTF-8编码的字节串
utf8_bytes = plaintext.encode('utf-8')ciphertext = rc4_encrypt(key, utf8_bytes)
print('Ciphertext:',utf8_bytes)
decrypted_text = rc4_decrypt(key, ciphertext)
print('Decrypted Text:', decrypted_text)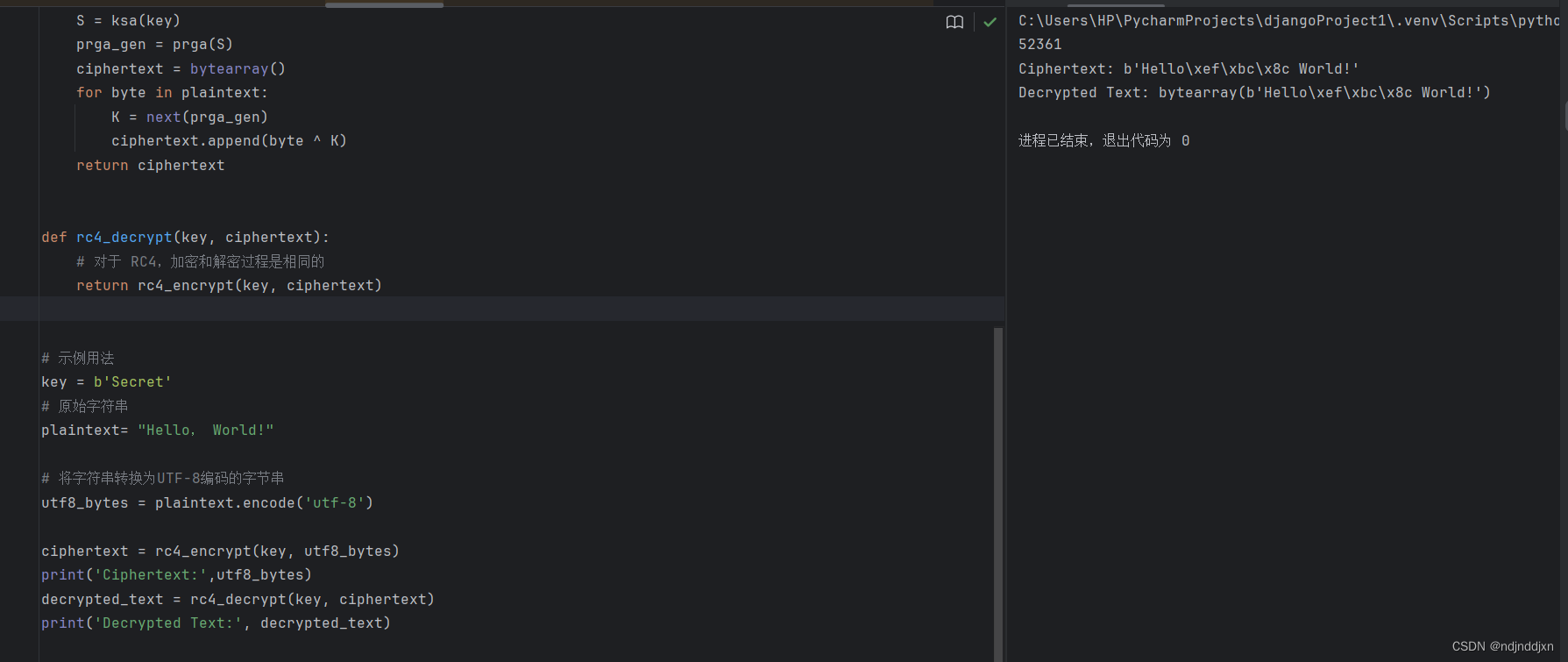
四、例题
RC4的密码较为简单,所以要一般结合其他的东西再来解
比如buuctf上的re
[GUET-CTF2019]encrypt
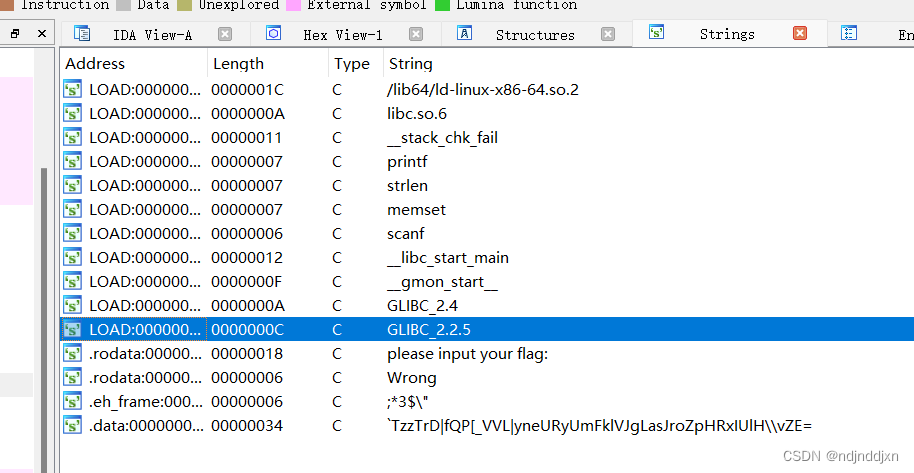
下载后查壳,没有,直接用IDA打开
发现了一串奇怪的字符
按X 后T按ab键,查看伪代码
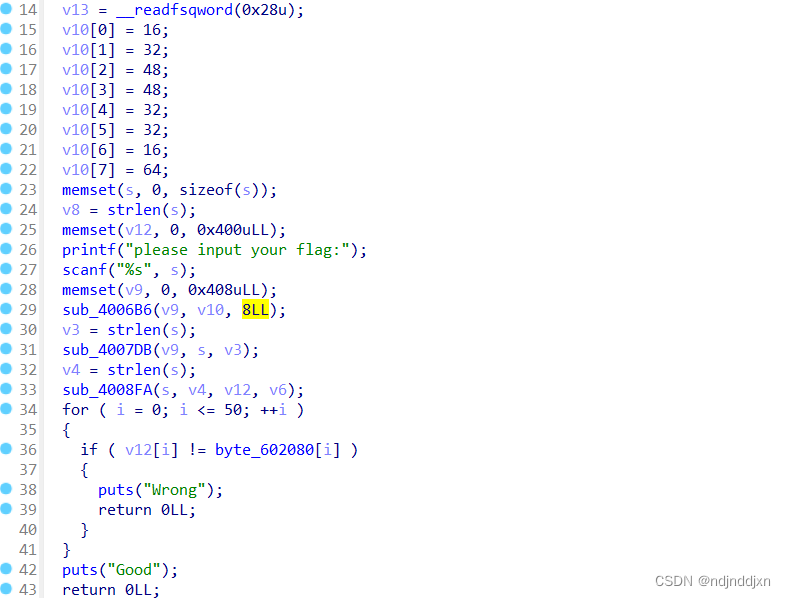
观察一下,大概意思就是读取用户输入一段字符串并验证是否与byte_602080相匹配,还有sub_4006B6进行了RC4加密 ,v10就是key
看了一下其他的内容: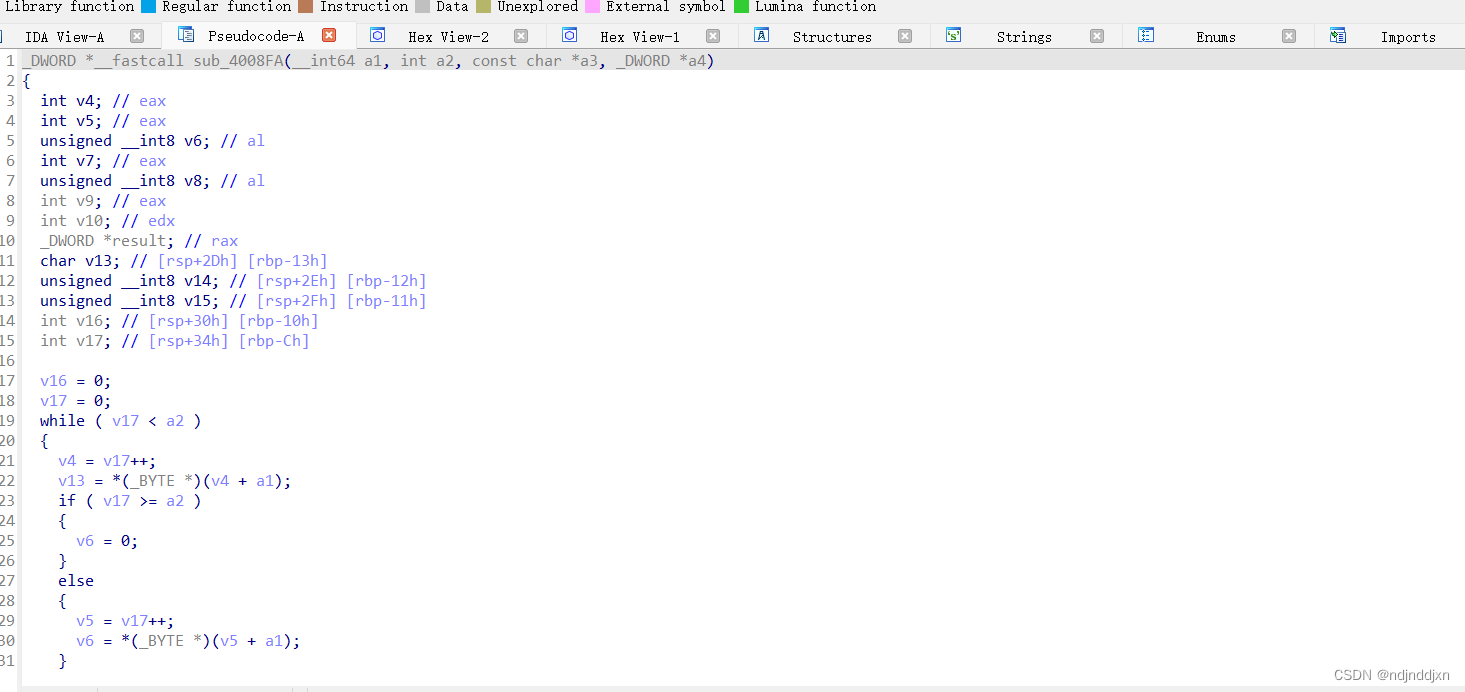
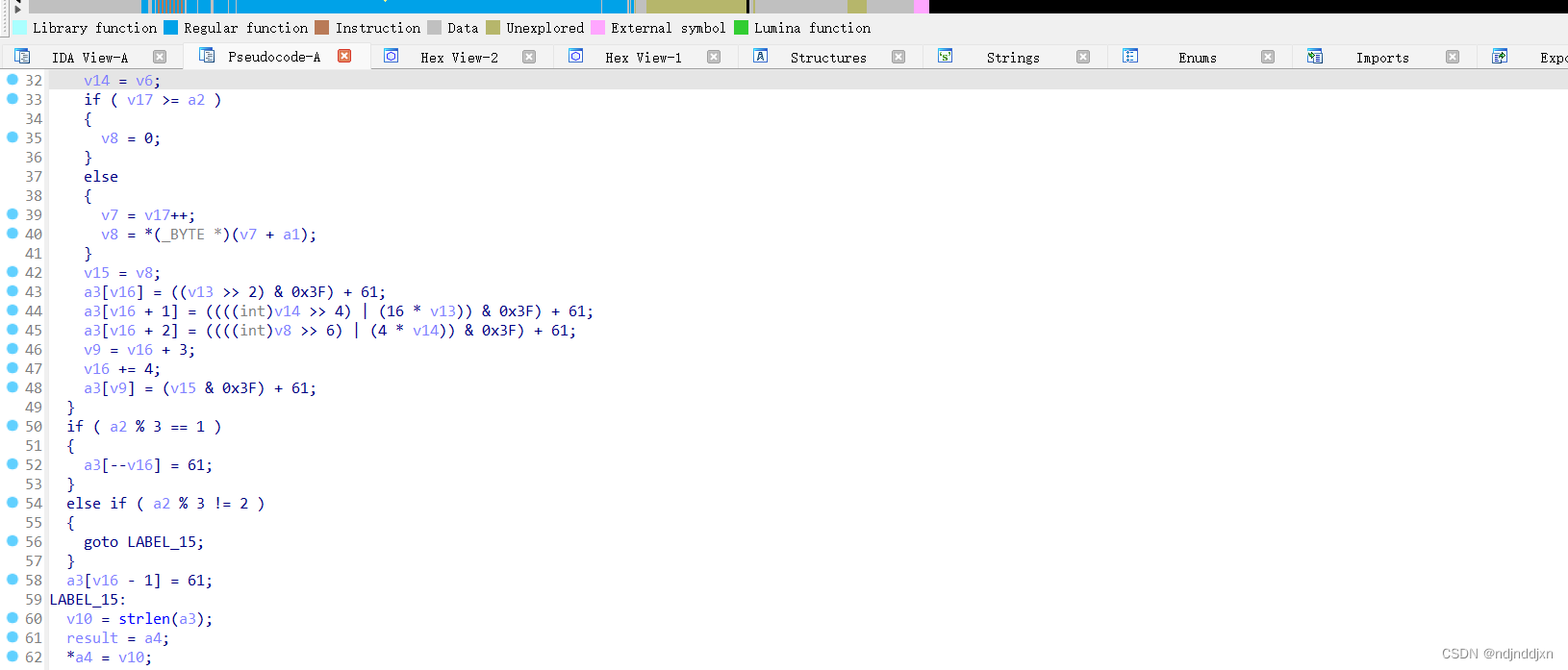
这里看到了base64加密和RC4加密的过程,但是这里的base64加密有点不一样,
编码后的Base64字符是通过加上61(即ASCII中的'='字符加1)得到的,通过简化而形成的,一般的base64,通过'A'到'Z'、'a'到'z'、'0'到'9'、'+'和'/',而这里使用了'='字符加偏移的方式。查询得到是魔化的base64
什么叫做魔化的base64?
魔化的Base64通常指的是Base64编码的一种变体或改进形式,它在标准Base64的基础上进行了某些修改或增强,以适应特定的应用场景或需求。特点:
- 字符集变更:
- 标准Base64使用64个字符的字符集,包括大小写字母、数字、加号(+)、斜杠(/)以及填充字符等号(=)。
- 魔化Base64可能会更改这个字符集,以避免在特定上下文(如URL、数据库或编程环境)中的冲突或特殊解释。
- URL安全:
- 由于标准Base64中的加号(+)和斜杠(/)在URL中具有特殊含义,因此直接用于URL中可能会导致问题。
- 魔化Base64可能会使用其他字符(如连字符(-)和下划线(_))来替换加号(+)和斜杠(/),从而使其URL安全。
- 填充字符:
- 标准Base64使用等号(=)作为填充字符,用于在原始数据长度不是3的倍数时进行填充。
- 魔化Base64可能会保留这个特性,但也可能根据具体应用场景进行不同的处理。
- 数据长度和膨胀:
- Base64编码的特性之一是它会使数据变大,因为每3个字节的原始数据会转换为4个Base64字符。
- 魔化Base64通常不会改变这个基本的数据膨胀率,但在某些情况下可能会进行优化或调整。
- 编码/解码过程:
- 魔化Base64的编码和解码过程与标准Base64类似,但会基于变更的字符集和可能的特殊规则进行调整。
- 应用场景:
- 魔化Base64常用于需要Base64编码但又有特殊需求的场景,如URL编码、数据库存储、编程环境等。
大神wp的补充:
- 把 rc4 加密过的内容三个字节一组,变成四个六位的数(这里和 base64 原理一样)
- 把四个数每个加上 61,存入输出的数组之中
后面就没有什么了,再次梳理一下内容:先用RC4加密——魔化的base64——最后对比
大神接下来就是上脚本了,直接一步得到flag:
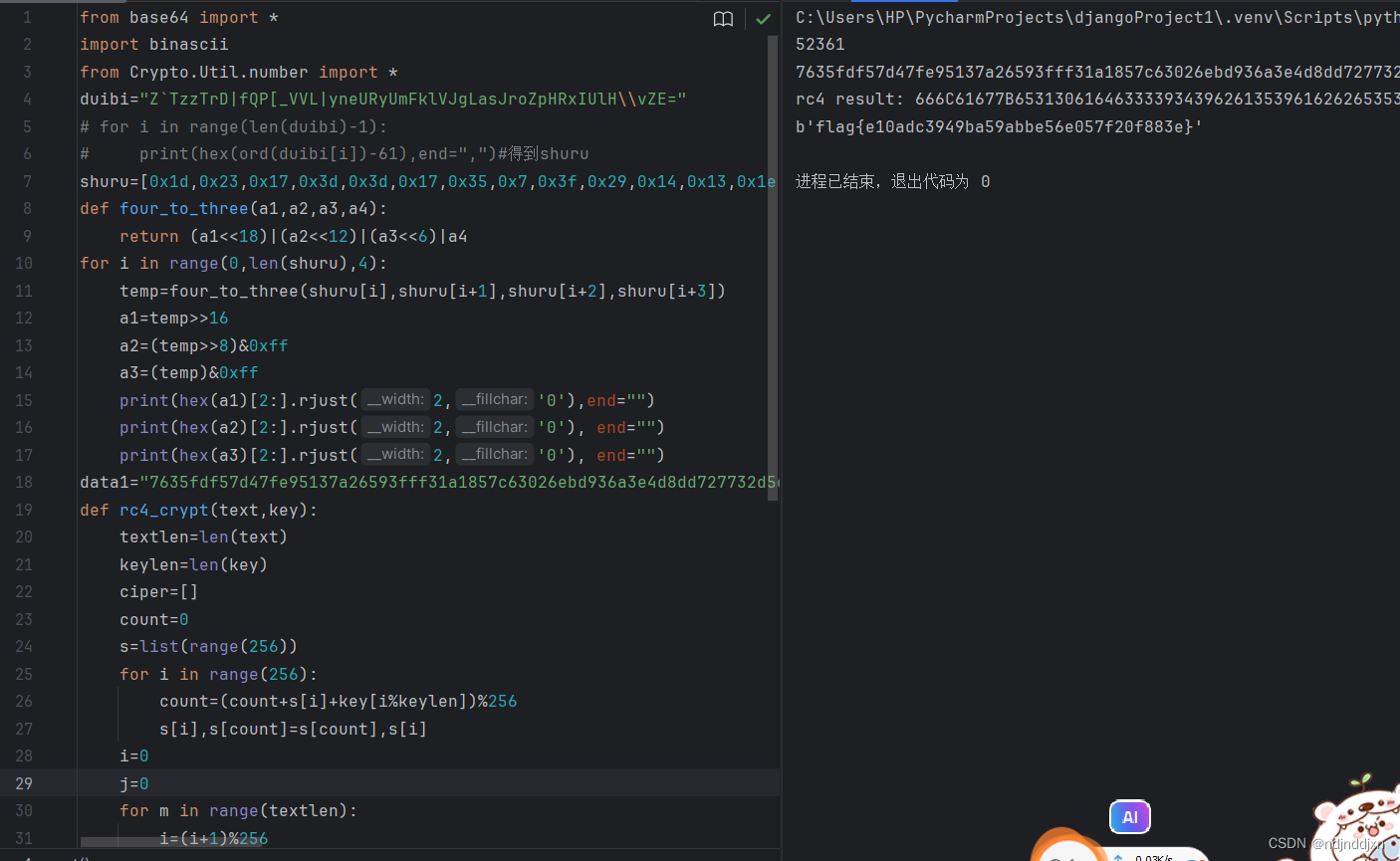
from base64 import *
import binascii
from Crypto.Util.number import *
duibi="Z`TzzTrD|fQP[_VVL|yneURyUmFklVJgLasJroZpHRxIUlH\\vZE="
# for i in range(len(duibi)-1):
# print(hex(ord(duibi[i])-61),end=",")#得到shuru
shuru=[0x1d,0x23,0x17,0x3d,0x3d,0x17,0x35,0x7,0x3f,0x29,0x14,0x13,0x1e,0x22,0x19,0x19,0xf,0x3f,0x3c,0x31,0x28,0x18,0x15,0x3c,0x18,0x30,0x9,0x2e,0x2f,0x19,0xd,0x2a,0xf,0x24,0x36,0xd,0x35,0x32,0x1d,0x33,0xb,0x15,0x3b,0xc,0x18,0x2f,0xb,0x1f,0x39,0x1d,0x8,0]
def four_to_three(a1,a2,a3,a4):return (a1<<18)|(a2<<12)|(a3<<6)|a4
for i in range(0,len(shuru),4):temp=four_to_three(shuru[i],shuru[i+1],shuru[i+2],shuru[i+3])a1=temp>>16a2=(temp>>8)&0xffa3=(temp)&0xffprint(hex(a1)[2:].rjust(2,'0'),end="")print(hex(a2)[2:].rjust(2,'0'), end="")print(hex(a3)[2:].rjust(2,'0'), end="")
data1="7635fdf57d47fe95137a26593fff31a1857c63026ebd936a3e4d8dd727732d5ecc62f2dfe5d2"
def rc4_crypt(text,key):textlen=len(text)keylen=len(key)ciper=[]count=0s=list(range(256))for i in range(256):count=(count+s[i]+key[i%keylen])%256s[i],s[count]=s[count],s[i]i=0j=0for m in range(textlen):i=(i+1)%256j=(j+s[i])%256s[i],s[j]=s[j],s[i]k=s[(s[i]+s[j])%256]ciper.append(k^text[m])ciper_text=''.join("%02x"%i for i in ciper)return ciper_text.upper()
if __name__ == "__main__":data = '7635fdf57d47fe95137a26593fff31a1857c63026ebd936a3e4d8dd727732d5ecc62f2dfe5d2'key = '1020303020201040'print()print("rc4 result:", rc4_crypt(binascii.a2b_hex(data), binascii.a2b_hex(key.upper())))print(long_to_bytes(0x666C61677B65313061646333393439626135396162626535366530353766323066383833657D))#7635fdf57d47fe95137a26593fff31a1857c63026ebd936a3e4d8dd727732d5ecc62f2dfe5d200
#rc4 result: 666C61677B65313061646333393439626135396162626535366530353766323066383833657D
#b'flag{e10adc3949ba59abbe56e057f20f883e}'
那我们的一般思路就是将一开始的奇怪字符串进行Rc4解密,
如果借助在线网站的话,要将key进行十六进制转化,然后再弄,但是得到了的是魔化的base64,不行,
接下来就是利用特性:
RC4加密算法最后是要得到一个数据和明文进行异或
*(_BYTE *)(i + a2) ^= LOBYTE(v9[(unsigned __int8)(v7 + v8)]);
该数据 xor 明文=密文
密文 xor 该数据 =明文
那么要进行动态调试,在liucx里面弄
那么先下载IDA Pro
先去该网站下载
然后赋给执行权限并安装
chmod +x idafree83_linux.run
详解在:[GUET-CTF2019]encrypt_[guet-ctf2019]encrypt详细解答-CSDN博客
[GUET-CTF2019]encrypt 题解-阿里云开发者社区
[SEETF 2023]BabyRC4
题目:
分析过程:
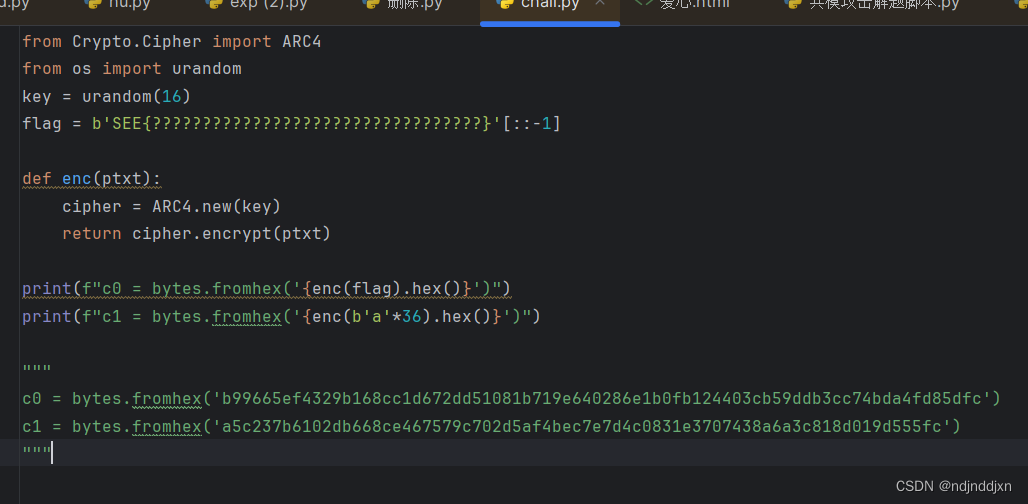
ARC4 :这一行导入一个叫ARc4的加密算法,ARC4就是RC4
urandom:生成随机字符串
flag = b'SEE{?????????????????????????????????}'[::-1]: 定义了一个字节字符串,其内容为'SEE{'后面跟着32个问号,进行了字符串反转了。但反转后,其内容仍然是'SEE{'开头,后跟32个问号,只是问号的顺序与原始顺序相反。
print(f"c0 = bytes.fromhex('{enc(flag).hex()}')"): 使用定义的加密函数enc加密flag,将加密后的字节转换为十六进制字符串,并再次将其转换回字节。不能直接以字节的形式输出,因为先将字节转为16进制,再次转为字节可以检查转换后的字节是否与原始字节相同,确保数据的完整性,而且16进制利于传输和储存
print(f"c1 = bytes.fromhex('{enc(b'a'*36).hex()}')") :加密了一个由36个'a'字符组成的字节字符串,并进行了类似的转换。
那么按我们的思路来编写脚本吧!!!
引入解决RC4的Python函数,这里使用的是strxor,是pycryptodome库中的一个实用函数,用于对两个等长的字节字符串执行按位异或(XOR)操作。异或操作是一种二进制运算,其结果中每一位是相应位置的两个输入位中恰有一个为1时取1,RC4过程中就要进行明文和数据的异或。
定义m1,c0,c1:
m1 是一个由36个'a'字符组成的字节串,每个'a'在ASCII中对应的字节值是0x61。
c0 和 c1 是从十六进制字符串转换而来的字节串,分别代表两个加密或编码后的数据块
最后就可以进行异或,
strxor(m1,c1):m1和c1进行异或操作。由于m1和c1都是36字节长,所以它们的异或结果也是一个36字节长的字节串。
c0[:-2]接着,我们从c0中移除最后两个字节(为了匹配m1和c1的长度)。现在是一个34字节长的字节串。
strxor(c0[:-2],...):c0[:-2]与m1和c1的异或结果进行异或操作。由于c0[:-2]只有34字节,而m1和c1的异或结果是36字节逻辑上是不正确的,因为按位异或要求两个操作数具有相同的长度。但是,在Python中,较短的字节串会在其末尾用\x00(零字节)填充到与较长字节串相同的长度,然后再执行异或操作。
最后就写成了解题脚本:
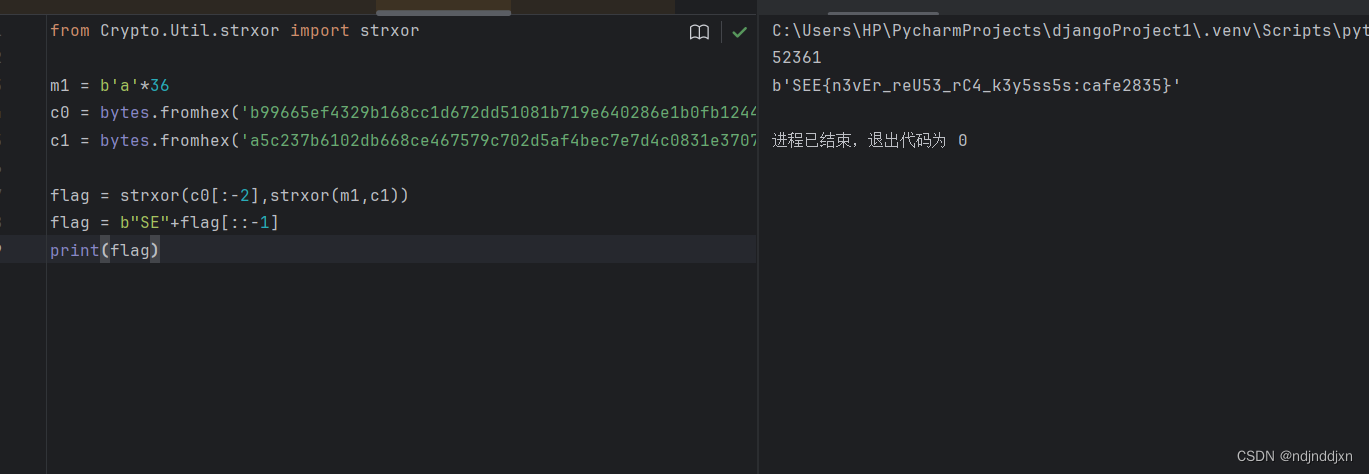
from Crypto.Util.strxor import strxorm1 = b'a'*36
c0 = bytes.fromhex('b99665ef4329b168cc1d672dd51081b719e640286e1b0fb124403cb59ddb3cc74bda4fd85dfc')
c1 = bytes.fromhex('a5c237b6102db668ce467579c702d5af4bec7e7d4c0831e3707438a6a3c818d019d555fc')flag = strxor(c0[:-2],strxor(m1,c1))
flag = b"SE"+flag[::-1]
print(flag)