文章目录
- ES分页|Paginate search results
- ES深分页的问题
- 一页获取数据量太大,报错
- 分页深度太大,报错
- 官方解释
- 其他解决方案
- Search after
- 解决两个问题
- 有没有深分页查询的必要性?
- search after & PIT的使用方式
- 1.创建pit
- 2.首次查询
- 3.之后的查询
- 延伸
- 4.清除pit
- 滚动搜索|Scroll search results
ES分页|Paginate search results
Paginate search results
By default, searches return the top 10 matching hits.
To page through a larger set of results, you can use the search API’s from and size parameters.
The from parameter defines the number of hits to skip, defaulting to 0.
The size parameter is the maximum number of hits to return.
Together, these two parameters define a page of results.
ES中from,size两个参数定义了一页数据的结果:
from——
跳过多少个doc,
默认地"from":0, 则跳过0个文档,即从第一个doc开始取,即角标第0条数据开始,取size个doc;
“from”:10, 即跳过10个doc,从角标第0个doc开始到角标第9个doc为止,是10个doc,跳过这10个doc,即从第11个doc开始取,即角标为10的doc开始取,取size个doc。
则,可以得知,“from”: m, 就是代表着从角标为m的doc开始取(角标为m的doc包含在内),取size个doc,构成一页(page)数据。
对比关系型数据库,如MySQL的语法是
[LIMIT {[offset,] row_count | row_count OFFSET offset}]`
With two arguments, the first argument specifies the offset of the first row to return, and the second specifies the maximum number of rows to return. The offset of the initial row is 0 (not 1):SELECT * FROM tbl LIMIT 5,10; # Retrieve rows 6-15这个示例使用的
limit offset, row_count,表示跳过offset条数据,取row_count条数据作为一页(page)这里
ES的from与MySQL的OFFSET一样的含义,跳过多少条数据,或者叫做偏移量是多少,都是从0开始,都可以理解所有数据构成一个大数组,这个数值就是数组的角标,第一条数据是角标为0的数据。
ES中不指定from仅指定size参数表示取前size条数据;同样的
MySQL中,不指定offset参数,仅仅limit row_count则表示取前row_count条数据:SELECT * FROM tbl LIMIT 5; # Retrieve first 5 rows
size——
定义一页(a page)有多少个doc(对应关系型数据库的多少条数据),即pageSize(一页数据的大小)
ES的size参数与关系型数据库MySQL的limit offset, row_count语法中的row_count值是一样的,表示取多少条数据或者叫做一页数据的大小是多少。
分页——
要获取第currentPage页的数据,一页数据的个数(或条数)为pageSize个:
ES中GET index_xxx/_search {"from": (currentPage-1) * pageSize,"size": pageSize,//忽略其他... }
MySQL中offset = (currentPage-1) * pageSize
row_count = pageSize
select * from t_xxx limit (currentPage-1) * pageSize, pageSize;
ES深分页的问题
一页获取数据量太大,报错
极限一点,就从开始取一万零一条数据,报错了。
GET my-index-000001/_search
{"from": 0,"size": 10001,"sort": [{"id": {"order": "desc"}}]
}
报错:非法参数异常,结果窗口太大from+size不能超过10000
"caused_by" : {"type" : "illegal_argument_exception","reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting." }
分页深度太大,报错
极限一点,pageSize=1,每页1条数据
现在获取第10001页的数据,报错了。
GET my-index-000001/_search
{"from": 10000,"size": 1,"sort": [{"id": {"order": "desc"}}]
}
报错:
"caused_by" : {"type" : "illegal_argument_exception","reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."}
官方解释
Avoid using from and size to page too deeply or request too many results at once. Search requests usually span multiple shards. Each shard must load its requested hits and the hits for any previous pages into memory. For deep pages or large sets of results, these operations can significantly increase memory and CPU usage, resulting in degraded performance or node failures.
官方的解释:
避免分页深度太大(获取后面的页数据的深度大于获取前边的页数据的深度),避免一次获取太多的数据。
搜索请求通常跨多个分片(因为每个主分片都会存储完整数据的一部分数据,副本分片是主分片的拷贝),
每个分片必须加载(load)请求(所需要分页数据)的数据,以及之前的数据(当前页之前的数据)到内存当中。
也就是说分页不是直接取出所取分页的数据、只获取当前页,而是需要把(from参数)跳过(skip)的数据也要取出来,然后把这些需要跳过的数据再过滤掉。实际上就是说,要把
from需要跳过(skip)的数据和指定分页的数据全部拿到内存中来,然后再去除掉需要跳过(skip)的数据。
那么这个加载过程是耗内存资源的,尤其是在获取后面的分页数据且一次获取的数据量很大,比如取第1000页消耗的内存资源是比取第1页消耗的多的多,一次获取5000条比一次获取1条消耗的内存资源要多得多。
其实结合起来就是,from很大,代表了深分页,size很大,代表了一次性获取数据量的大小很大,总归是加载太多数据会引发性能问题。加载from+size条数据到内存中,当from+size太大,就容易出现性能问题。
对于深分页(deep pages,分页太多,取非常靠后边的分页数据)或者取太多数据(比如一次就要取10000条数据)(乃至深分页且获取大量数据),
这些操作可能会显著增加内存和CPU的使用率,导致性能下降或节点故障。
由于from跳过的数据+要取的size个数据都会被加载到内存中,深分页和获取大量数据就会非常耗资源,既然耗资源,那就不能无止尽的获取后边的分页以及无止尽的一次性取大量数据。
由于分片需要加载到内存的数据条数是from,size共同决定的,因此需要限制from+size
By default, you cannot use from and size to page through more than 10,000 hits. This limit is a safeguard set by the index.max_result_window index setting. If you need to page through more than 10,000 hits, use the search_after parameter instead.
默认地,ES限制了from+size不能超过一万。
这个默认值当然可以改,也提供了修改的方法。但是就如之前的分析,from+size太大会出现性能问题,因此还是不要改的好,如果确实有这样的需求需要换解决方案。
Warning:Elasticsearch uses Lucene’s internal doc IDs as tie-breakers. These internal doc IDs can be completely different across replicas of the same data. When paging search hits, you might occasionally see that documents with the same sort values are not ordered consistently.
Elasticsearch 使用 Lucene 的内部文档 ID 作为决定因素。这些内部文档 ID 在相同数据的副本之间可能完全不同。当分页搜索命中时,您有时可能会发现具有相同排序值的文档的排序不一致。
这个说明是说会为文档单独维护一个内部的id,即使相同数据的副本间,这个id也可能不同。
这样,就可能会引发一个问题:指定相同的排序参数,获取到的结果可能不一样(在指定排序的排序值一样的情况下的文档(doc)排序可能不同,有可能某doc上一次获取的结果是在前边,下一次相同参数请求获取到的doc跑到后面了。**原因就是:**指定排序参数的排序结果中,文档排序一样的话,默认会使用这个内部id排序,而不同的副本这个内部id可能不一样,于是导致排序的结果可能不一致)
这个在下面也会说明。
其他解决方案
Search after
You can use the search_after parameter to retrieve the next page of hits using a set of sort values from the previous page.
Using search_after requires multiple search requests with the same query and sort values. If a refresh occurs between these requests, the order of your results may change, causing inconsistent results across pages. To prevent this, you can create a point in time (PIT) to preserve the current index state over your searches.
可以使用search_after参数来获取下一页数据,search_after参数的值设置为前一页数据的sort值
也就是说,基于前一页的记录的sort值,来往后取数据。
使用search_after要求多次查询使用相同的query条件和排序条件(sort)。
但是,会存在一个问题,多次查询间,发生了数据添加操作(refresh会把新索引的数据(doc)会把数据从内存中的buffer写入到filesystem cache中,并清除内存buffer中的数据,这个doc就可以被检索到),那么这些查询的结果中数据的排序可能会发生变化,导致跨页数据的不一致。
为了避免上面的问题,解决跨页请求数据一致性的问题,可以创建一个pit,保存当前索引的状态。
Elasticsearch pit (point in time) is a lightweight view into the state of the data as it existed when initiated.
pit是一个在它(pit)被创建时刻数据的一个轻量级视图。
也就是说,多次请求,通过同一个pit,可以保证所见的数据视图是一致的,即使发生了数据更新(如插入,删除数据),在这些查询请求间,数据视图是一致的。
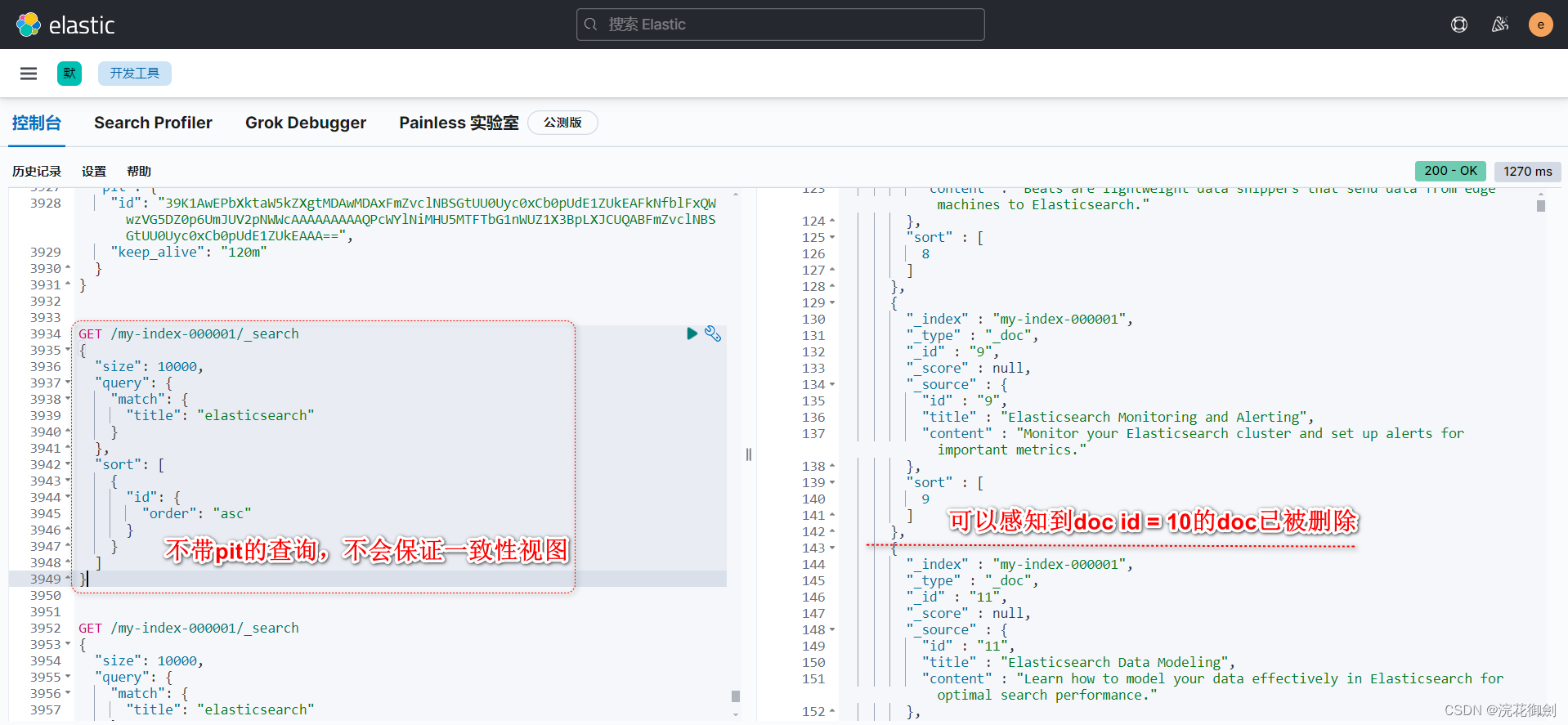
可以进行实验印证:
当pit创建后(pit的使用下面会说明),检索一万条
GET /_search { "size": 10000, "query": { "match": { "title": "elasticsearch" } }, "sort": [ { "id": {"order": "asc" } }, { "_shard_doc": "asc" } ], "pit": { "id": "39K1AwEPbXktaW5kZXgtMDAwMDAxFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAFkNfblFxQWwzVG5DZ0p6UmJUV2pNWWcAAAAAAAAAPQMWYlNiMHU5MTFTbG1nWUZ1X3BpLXJCUQABFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAAA==", "keep_alive": "120m" } }可以发现数据中存在一条数据:
{"_index" : "my-index-000001","_type" : "_doc","_id" : "10","_score" : null,"_source" : {"id" : "10","title" : "Elasticsearch Security and Authentication","content" : "Configure Elasticsearch security features like X-Pack Security for authentication and authorization."},"sort" : [10,110101] },那现在我删除掉doc id为10的文档。
DELETE my-index-000001/_doc/10 //结果: { "_index" : "my-index-000001", "_type" : "_doc", "_id" : "10", "_version" : 7, "result" : "deleted", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 120108, "_primary_term" : 3 }会发现按照刚才的查询再执行一次,还能查询到doc id为10的文档,
注意,如果不使用pit,会检索到最新的数据变动,因此,是否需要保证视图一致性,是否需要检索到最新数据变化,这个看实际需要。
然后现在我们再插入一个新的id为10的文档,内容和原来不一样
POST /my-index-000001/_doc/10 { "id": "10", "title": "Elasticsearch Security and Authentication [[not same with before]] ", "content": "Configure Elasticsearch security features like X-Pack Security for authentication and authorization." } { "_index" : "my-index-000001", "_type" : "_doc", "_id" : "10", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 120109, "_primary_term" : 3 }然后按照之前的查询条件,进行查询,结果还是之前的结果。
{"_index" : "my-index-000001","_type" : "_doc","_id" : "10","_score" : null,"_source" : {"id" : "10","title" : "Elasticsearch Security and Authentication","content" : "Configure Elasticsearch security features like X-Pack Security for authentication and authorization."},"sort" : [10,110101] },但是,普通查询可以查到新插入的数据。
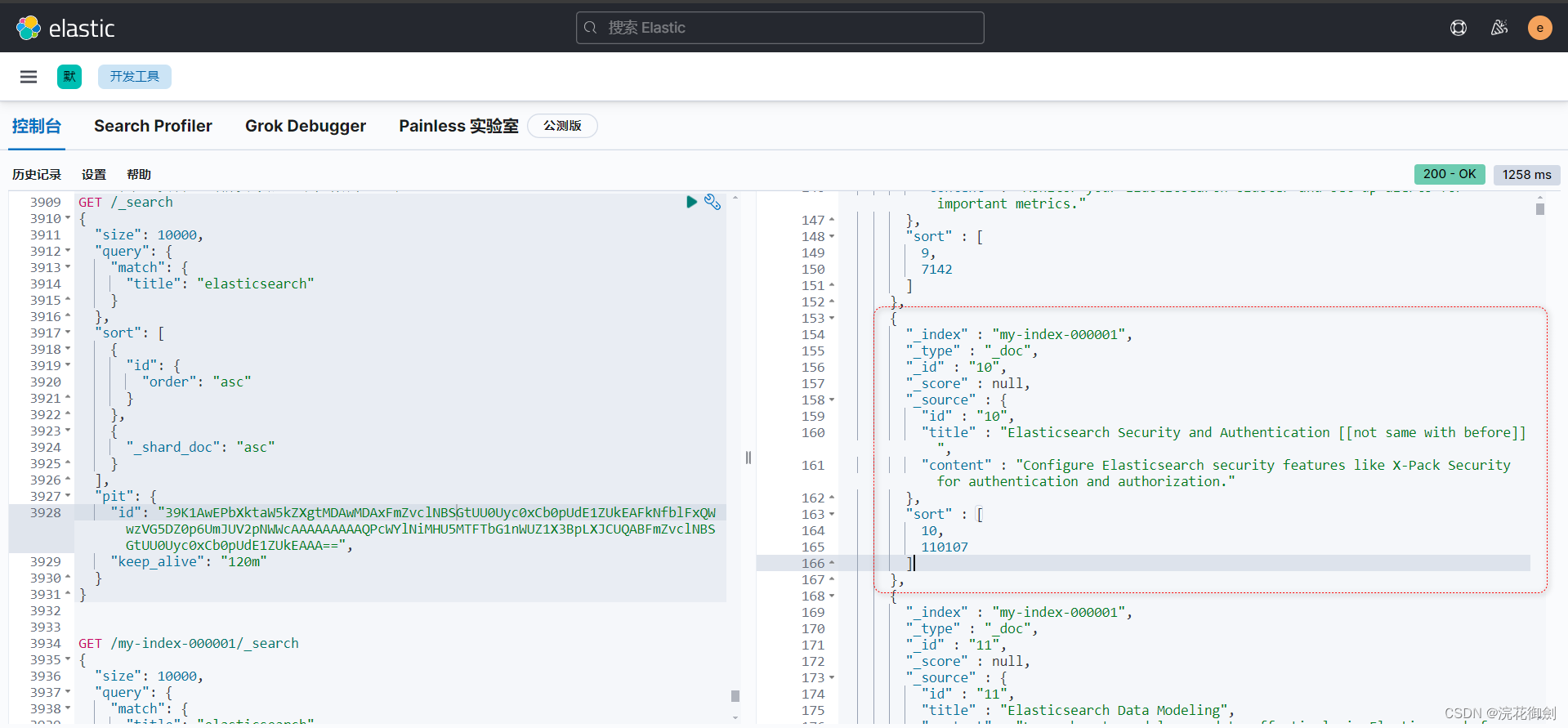
GET my-index-000001/_doc/10 //结果: { "_index" : "my-index-000001", "_type" : "_doc", "_id" : "10", "_version" : 1, "_seq_no" : 120109, "_primary_term" : 3, "found" : true, "_source" : { "id" : "10", "title" : "Elasticsearch Security and Authentication [[not same with before]] ", "content" : "Configure Elasticsearch security features like X-Pack Security for authentication and authorization." } }当然清除掉这个pit
DELETE /_pit { "id" : "39K1AwEPbXktaW5kZXgtMDAwMDAxFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAFkNfblFxQWwzVG5DZ0p6UmJUV2pNWWcAAAAAAAAAPQMWYlNiMHU5MTFTbG1nWUZ1X3BpLXJCUQABFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAAA==" }新生成一个pit进行查询
POST /my-index-000001/_pit?keep_alive=10m可以检索到新的数据。
通过上面的实验可以印证,使用同一个有效的未过期的pit,数据视图始终是一致的,即使之后数据发生了变动,在使用同一个pit查询,看到的视图不会变。当然清除这个pit后使用新的pit进行进行检索,可以检索到最新的数据变动。
解决两个问题
总结下:这里有两个问题,
-
一个是解决深分页问题,可以使用search_after;
相比传统的from + Size分页方式,Search After接口能够更高效地定位到指定位置的数据,避免了需要跳过大量数据的问题,从而提高了查询效率。当查询达到深度分页时,使用from + Size方式的成本会变得很高,而Search After接口通过提供一个活动光标来规避此问题,使用上一页的结果来帮助检索下一页,使得查询更为高效。
Search After接口支持实时数据更新,适用于需要及时获取数据变化的场景。
由于Search After是基于上一页的最后一条数据来确定下一页的位置,因此在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时地反映到游标上。
-
一个是多次从查询间发生了数据变动的问题(需要解决请求间数据视图不一致问题),可以在查询前创建一个pit,保存当前索引状态,使用这个pit参数进行请求,就能够始终得到一个一致的数据视图。
这两个问题不要混在一块了。如果不是很在意视图不一致问题,比如读多写少,数据很少变动,那就没必要使用pit,根据实际情况来。
有没有深分页查询的必要性?
现在我们回过头来,反思下,业务上是否真的需要进行深度分页。
官方为保证ES的性能,限制 from+size 不超过10000。
我们看看看一万是个多大的存在。
以百度搜索、bing搜索为例,一页数据10条,
那10000条意味着可以检索1000页,我们日常通过这些搜索引擎检索内容,几十页都不会去翻;
电子商城买东西,(以50一页看,可以检索200页)基本也不会翻几页,通常会追加条件,更精确的检索;
那就看业务上能否限制下,限制检索页数,像上面的案例200页,1000页足够检索的了,谁也不会闲的没事去点那么多页。
然后一些特殊的需要
search after & PIT的使用方式
注意1:使用search after就不要使用from跳过数据了
注意2:search after不支持随机跳转分页。(可以通过记录上一页的search_after参数和当前页最后一条数据的sort,来实现上一页,下一页)
我们来举个例子:同时使用search after和pit,能够同时满足深分页,以及视图保证前后一致性(一致性视图的问题上面已经讲述,这里不再赘述,仅仅展示用法)。
1.创建pit
POST /my-index-000001/_pit?keep_alive=10m
//结果如下:得到以一个pit id
{"id" : "39K1AwEPbXktaW5kZXgtMDAwMDAxFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAFkNfblFxQWwzVG5DZ0p6UmJUV2pNWWcAAAAAAAAATbUWYlNiMHU5MTFTbG1nWUZ1X3BpLXJCUQABFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAAA=="
}2.首次查询
IMPORTANT:All PIT search requests add an implicit sort tiebreaker field called
_shard_doc, which can also be provided explicitly. If you cannot use a PIT, we recommend that you include a tiebreaker field in yoursort. This tiebreaker field should contain a unique value for each document. If you don’t include a tiebreaker field, your paged results could miss or duplicate hits.重要提示:
所有 PIT 搜索请求都会添加一个名为 _shard_doc 的隐式排序仲裁字段,该字段也可以显式提供。如果您无法使用 PIT,我们建议您在排序中包含决胜局字段(tiebreaker)。此决胜局字段(tiebreaker)应包含每个文档的唯一值。如果您不包含决胜局字段(tiebreaker),则分页结果可能会丢失或重复命中。
这就是上边提到的**”会发现具有相同排序值的文档的排序不一致“**的问题。
我们指定的排序方式,结果中两个文档排序结果一样,那可以通过指定tiebreaker来保证排序的确定性,默认使用doc内部id来排,由于不同副本分片的同一数据的内部id可能不一样,会导致排序结果的不稳定性。
NOTE:Search after requests have optimizations that make them faster when the sort order is
_shard_docand total hits are not tracked. If you want to iterate over all documents regardless of the order, this is the most efficient option.搜索请求进行了优化,当排序顺序为 _shard_doc 并且不跟踪总点hits时,搜索速度会更快。如果您想迭代所有文档而不考虑顺序,这是最有效的选择。
也就是说,不指定排序方式,使用默认的***_shard_doc***排序不关注数据总量(total)(通过查询携带带参数
"track_total_hits": false),搜索速度会更加快速。IMPORTANT:If the
sortfield is adatein some target data streams or indices but adate_nanosfield in other targets, use thenumeric_typeparameter to convert the values to a single resolution and theformatparameter to specify a date format for thesortfield. Otherwise, Elasticsearch won’t interpret the search after parameter correctly in each request.关于Elasticsearch中如何处理不同数据字段(特别是日期字段)在排序(
sort)时的兼容性问题的指导
如果排序字段在某些目标数据流或索引中是日期,但在其他目标中是 date_nanos 字段,请使用 numeric_type 参数将值转换为单一分辨率,并使用 format 参数指定排序字段的日期格式。否则,Elasticsearch 将无法正确解释每个请求中参数后的搜索。
在Elasticsearch中,日期字段可以有两种类型:
date和date_nanos
date类型通常使用毫秒作为时间单位来存储日期和时间。
date_nanos类型则使用纳秒作为时间单位,提供更高的时间精度。当你在进行搜索或排序操作时,如果某些数据流或索引中的
sort字段是date类型,而另一些是date_nanos类型,那么Elasticsearch可能无法正确地解释或比较这些字段,因为它们有不同的时间单位。
解决方式:
- 使用
numeric_type参数:这个参数允许你将日期值转换为统一的分辨率。这样,无论原始字段是date还是date_nanos类型,排序操作都可以基于相同的分辨率进行。- 使用
format参数:这个参数允许你指定日期格式。这确保了在排序时,所有日期值都按照指定的格式进行解析和比较。
重要性:
- 如果不采取上述措施,Elasticsearch在每次请求时可能无法正确解释排序参数,从而导致排序结果不准确或不符合预期。
不带search_after参数,search_after依赖于上一次查询结果。
注意使用pit,请求路径中就不需要就不需要带index
GET /_search
{"size": 10000,"query": {"match": {"title": "elasticsearch"}},"sort": [{"id": {"order": "asc"}},{"_shard_doc": "asc" // <1>}],"pit": {"id": "39K1AwEPbXktaW5kZXgtMDAwMDAxFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAFkNfblFxQWwzVG5DZ0p6UmJUV2pNWWcAAAAAAAAATbUWYlNiMHU5MTFTbG1nWUZ1X3BpLXJCUQABFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAAA==", //<2>"keep_alive": "120m" //<3>}
}
<1>使用显示的 _shard_doc 升序平局处理(tiebreak )对搜索结果进行排序。
<2>PIT ID for the search.
The search response includes an array of
sortvalues for each hit. If you used a PIT, a tiebreaker is included as the lastsortvalues for each hit. This tiebreaker called_shard_docis added automatically on every search requests that use a PIT. The_shard_docvalue is the combination of the shard index within the PIT and the Lucene’s internal doc ID, it is unique per document and constant within a PIT. You can also add the tiebreaker explicitly in the search request to customize the order_shard_doc 值是 PIT 中的分片索引和 Lucene 的内部文档 ID 的组合,它对于每个文档都是唯一的,并且在 PIT 中是恒定的。因此,可以在搜索请求中显式添加tiebreaker以自定义顺序。
<3>You can repeat this process to get additional pages of results. If using a PIT, you can extend the PIT’s retention period using the
keep_aliveparameter of each search request.可以使用每个搜索请求的 keep_alive 参数来延长 PIT 的保留期。
可指定
"track_total_hits": false参数, Disable the tracking of total hits,进一步加快分页速度。
结果:
{"pit_id" : "39K1AwEPbXktaW5kZXgtMDAwMDAxFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAFkNfblFxQWwzVG5DZ0p6UmJUV2pNWWcAAAAAAAAATbUWYlNiMHU5MTFTbG1nWUZ1X3BpLXJCUQABFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAAA==", //<1>"took" : 983,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 10000,"relation" : "gte"},"max_score" : null,"hits" : [//忽略前面的9999条数据,直接看最后这条{"_index" : "my-index-000001","_type" : "_doc","_id" : "10000","_score" : null,"_source" : {"id" : 10000,"title" : "Elasticsearch Performance Tuning","content" : "Replicate indices across multiple Elasticsearch clusters for data redundancy and disaster recovery."},"sort" : [ //<2>10000,77050 //<3>]} ]}
}
<1>更新了的pit_id
<2> Sort values for the last returned hit. (返回的命中值最后一个文档的sort )
<3>The tiebreaker value, unique per document within the
pit_id.(决胜局值(tiebreaker),pit_id 内每个文档都是唯一的。)

3.之后的查询
下一次查询时候要把上一次请求结果最后一条数据的pit_id和sort带过来,分别传到pit.id参数和search_after(数组格式)参数
GET /_search
{"size": 10000,"query": {"match": {"title": "elasticsearch"}},"sort": [{"id": {"order": "asc"}},{"_shard_doc": "asc"}],"pit": {"id": "39K1AwEPbXktaW5kZXgtMDAwMDAxFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAFkNfblFxQWwzVG5DZ0p6UmJUV2pNWWcAAAAAAAAATbUWYlNiMHU5MTFTbG1nWUZ1X3BpLXJCUQABFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAAA==", //<1>"keep_alive": "120m" //<4>},"search_after": [ //<2>10000, 77050 //<3>]
}
<1>根据上次请求结果中的pit_id,更新请求中的pit.id参数,
<2>上一次查询结果命中的文档中最后一个的sort,注意是数组格式
<3>The tiebreaker value, unique per document within the
pit_id.<4>设置keep_alive延长pit的过期时间,m是分钟,这里的实验设置的有点长
结果
{"pit_id" : "39K1AwEPbXktaW5kZXgtMDAwMDAxFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAFkNfblFxQWwzVG5DZ0p6UmJUV2pNWWcAAAAAAAAATbUWYlNiMHU5MTFTbG1nWUZ1X3BpLXJCUQABFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAAA==","took" : 1070,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0}, "hits" : {"max_score" : null,"hits" :[//省略9999个doc{"_index" : "my-index-000001","_type" : "_doc","_id" : "20000","_score" : null,"_source" : {"id" : 20000,"title" : "Elasticsearch Data Ingestion","content" : "Build beautiful visualizations and dashboards with Kibana for your Elasticsearch data."},"sort" : [20000,66357]}]}
}
之后的查询继续步骤3即可。
延伸
注意:由此可见分页已经可以搜索到10000之后,
但是注意,size是不能大于10000,如上面的查询改成size:10001,则报错
"caused_by" : {"type" : "illegal_argument_exception","reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."}
原因不再赘述,上面已经分析过。
4.清除pit
当不再使用这个pit,需要清除掉,或者等待它自动过期失效,自动清除掉。
手动清除如下:
DELETE /_pit
{"id" : "39K1AwEPbXktaW5kZXgtMDAwMDAxFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAFkNfblFxQWwzVG5DZ0p6UmJUV2pNWWcAAAAAAAAATbUWYlNiMHU5MTFTbG1nWUZ1X3BpLXJCUQABFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAAA=="
}
//结果如下:删除成功
{"succeeded" : true,"num_freed" : 1
}
滚动搜索|Scroll search results
We no longer recommend using the scroll API for deep pagination. If you need to preserve the index state while paging through more than 10,000 hits, use the search_after parameter with a point in time (PIT).
官方不再建议使用滚动 API 进行深度分页。
如果需要在分页超过 10,000 个命中时保留索引状态,建议使用带有时间点 (PIT) 的 search_after 参数。