上交&商汤联合提出一种虚拟试穿的创新方法,利用自监督视觉变换器 (ViT) 和扩散模型,强调细节增强,通过将 ViT 生成的局部服装图像嵌入与其全局对应物进行对比。虚拟试穿体验中细节的真实感和精确度有了显着提高,大大超越了现有技术的能力。从效果展示来看很不错。


相关链接
论文地址:https://arxiv.org/pdf/2406.10539v1
论文阅读

用于增强虚拟衣服试穿的自监督视觉变压器
摘要
虚拟试穿已成为网上购物的重要功能,为消费者提供了一个可视化服装合身程度的重要工具。在我们的研究中,我们介绍了一种虚拟试穿的创新方法,利用自监督视觉变换器 (ViT) 和扩散模型。我们的方法强调细节增强,通过将 ViT 生成的局部服装图像嵌入与其全局对应物进行对比。条件指导和重点关注关键区域等技术已融入我们的方法中。这些组合策略使扩散模型能够以更高的清晰度和真实感再现服装细节。实验结果显示,虚拟试穿体验中细节的真实感和精确度有了显着提高,大大超越了现有技术的能力。
方法
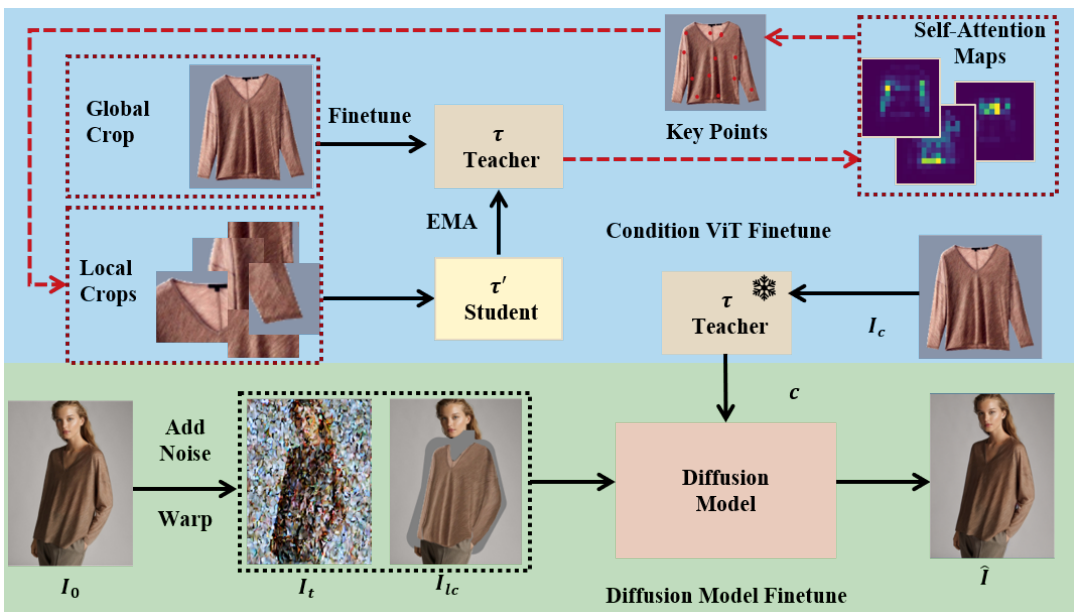
网络总体框架。我们利用稳定扩散 (SD) 修复网络,并使用经过特别微调的视觉变换器 (ViT) 将网络的焦点引导到复杂的衣服图像细节上。微调的 ViT(表示为 τ)也充当重要特征提取器,有助于计算损失并进一步完善修复过程。此外,我们将扭曲特征集成到输入中,以增强网络内部特征与给定条件下的特征之间的一致性。为了简化表示,我们在描述中省略了 SD 网络的编码器 E 和解码器 D。
在这项研究中,我们的目标是利用扩散用于虚拟试穿的绘画框架中的模型任务,侧重于服装的复杂性,如袖子,项圈和文本模式。以前的方法探索了注入明确信息的各种方法,但他们经常忽略这些关键的服装细节。为了解决这个问题,我们引入了一个基于自监督学习的细节增强器,旨在帮助我们的网络更好地学习认识和整合这些基本特征。

平均头部注意力的可视化ViT中的Class Token。“SS-”表示没有任何参数的场景 微调时,“SS RF”表示使用随机的本地作物进行 自监督微调,“SS SF”表示应用程序 我们的方法,包括选择性地选择当地的作物 self-supervised整合。
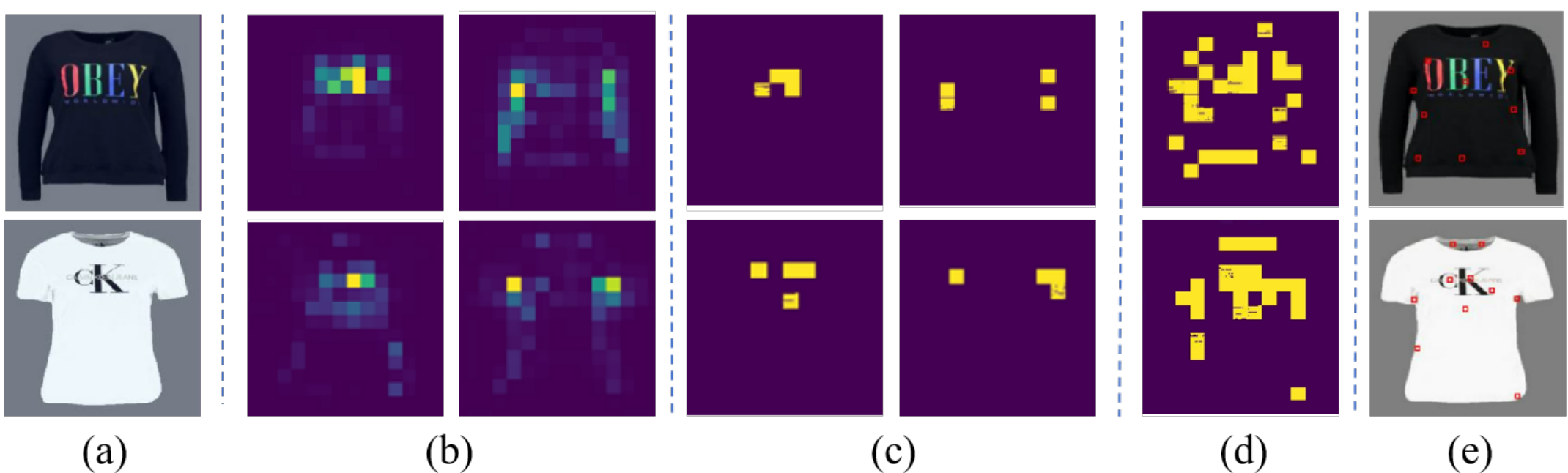
在这个可视化中,(a) 显示了输入到条件编码器 τ 的原始图像。子图 (b) 说明了 ViT 的自注意力机制中两个特定头部的注意力图,突出显示了关注区域。子图 (c) 显示了从 (b) 中呈现的注意力图中得出的焦点,精确定位了受到最高关注的特定区域。(d) 描绘了所有头部的焦点聚合,展示了全面的注意力格局。基于 (d) 中的焦点,进行聚类以确定关键聚类中心,这些中心在子图 (e) 中以红色突出显示,表示所有头部的关注区域。
效果展示
定性比较



在DressCode数据集的定性比较


与VITON-HD数据集基线的定性比较



方法局限性

结论
在本文中,我们提出了一种创新且有效的虚拟试衣方法。该方法将自监督的 ViT 与扩散模型相结合。它专注于通过比较 ViT 中的局部和全局服装图像嵌入来增强细节,展示了对复杂视觉元素的敏锐理解。条件指导、关注关键区域和专门的内容丢失等技术有助于其彻底性。这些策略使扩散模型能够准确复制服装细节,从而显着增强虚拟试衣体验的真实感和清晰度。