网络字节序
1、网络字节序 (Network Byte Order)和本机转换
1、大端、小端字节序
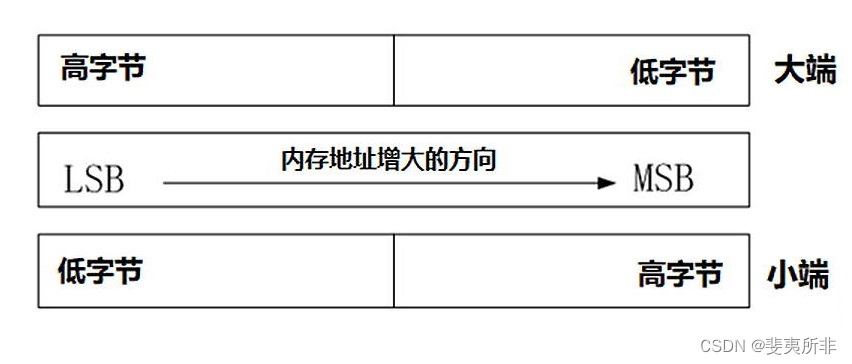
“大端” 和” 小端” 表示多字节值的哪一端存储在该值的起始地址处;小端存储在起始地址处,即是小端字节序;大端存储在起始地址处,即是大端字节序。
-
① 大端字节序(Big Endian): 最高有效位存于最低内存地址处,最低有效位存于最高内存地址处;
-
② 小端字节序(Little Endian):最高有效位存于最高内存地址,最低有效位存于最低内存地址处。
“高位数据"和"低位数据”
通常指的是数据在存储或传输时的位置或顺序。在处理二进制数据、字节序、位操作以及数据存储时非常常见,用于描述数据的物理存储方式或传输顺序。
-
高位数据:指的是数据的高阶位或高字节,通常存储在数据块的起始位置或最高有效位(Most Significant Bit,MSB)。在多字节数据中,高位数据对应于数据的较高位部分。
-
低位数据:指的是数据的低阶位或低字节,通常存储在数据块的末尾或最低有效位(Least Significant Bit,LSB)。在多字节数据中,低位数据对应于数据的较低位部分。
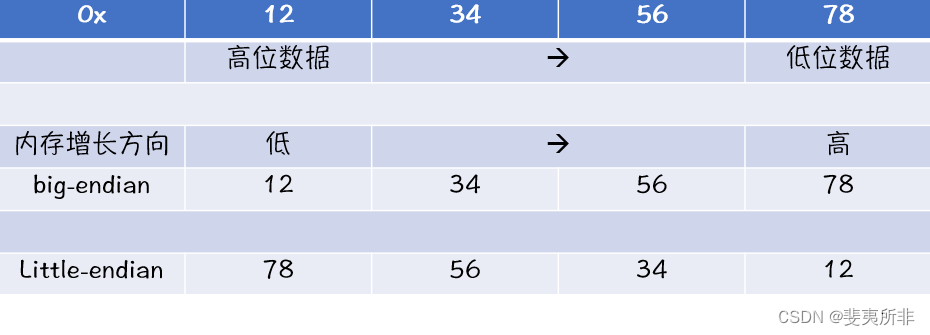
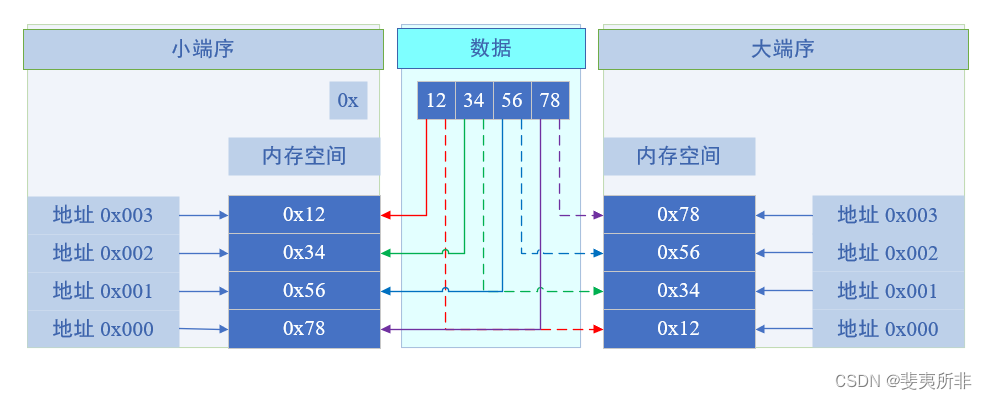
如下图:当以不同的存储方式,存储数据为 0x12345678 时:
视角 1
视角 2
视角 3
网络字节序:大端字节序
网络上传输的数据都是字节流,对于一个多字节数值,在进行网络传输的时候,先传递哪个字节?
也就是说,当接收端收到第一个字节的时候,它将这个字节作为高位字节还是低位字节处理,是一个比较有意义的问题。
UDP/TCP/IP 协议规定:把接收到的第一个字节当作高位字节看待, 这就要求发送端发送的第一个字节是高位字节;而在发送端发送数据时,发送的第一个字节是该数值在内存中的起始地址处对应的那个字节。换句话说,该数值在内存中的起始地址处对应的那个字节就是要发送的第一个高位字节。
所以,网络字节序就是大端字节序, 有些系统的本机字节序是小端字节序,有些则是大端字节序,为了保证传送顺序的一致性, 网际协议使用大端字节序来传送数据。
如何验证自己的机器采用了哪种字节顺序:
/* 确定你的电脑是大端字节序还是小端字节序 */
#include <stdio.h>int check1()
{int i = 1; //1在内存中的表示: 0x00000001char *pi = (char *)&i; //将int型的地址强制转换为char型return *pi == 0; //如果读取到的第一个字节为1,则为小端法,为0,则为大端法
}int main()
{if (check1() == 1)printf("big\n");elseprintf("little\n");return 0;
}
第二种方法,用联合结构解决,其本质差异不大
/* 确定你的电脑是大端字节序还是小端字节序 */
#include <stdio.h>int check2()
{union test {char ch;int i;}test0;test0.i = 1;return test0.ch == 0;
}
int main()
{if (check1() == 1)printf("big\n");elseprintf("little\n");return 0;
}12345678910111213141516171819202122232425262728293031323334353637383940414243
因为联合结构中的变量共用一块存储空间,所以 ch 和 i 拥有同一个地址:
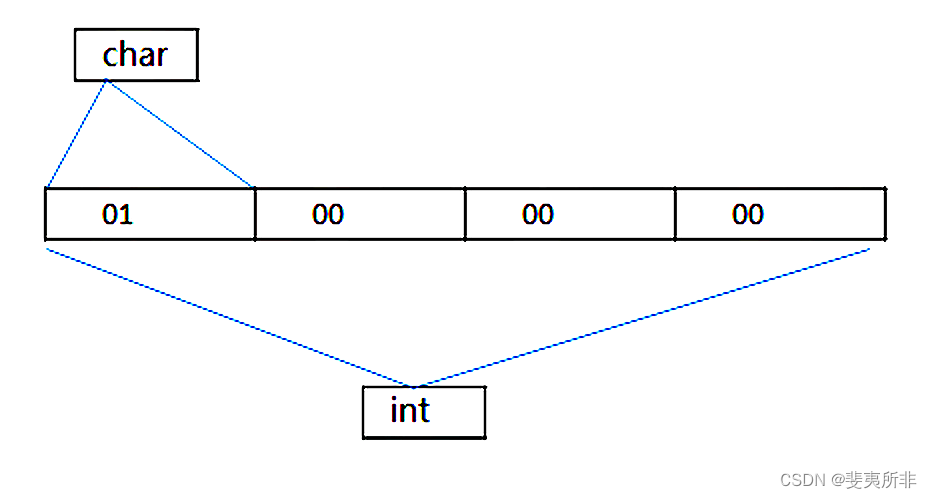
对本例中的联合结构,对它求 sizeof(test0),会发现它的大小为 4,取了 int 的大小。
关于 union,它里边的变量共用一块存储空间,但是它的大小并不总是其中最大的变量所占的空间,还需要考虑对齐!
比如:
union test1 {char[5];int i;}它的大小就是 8 了!
123456789101112131415
2、字节序转换函数
/* 字节序转换函数 */#include <arpa/inet.h>//将主机字节序转换为网络字节序uint32_t htonl (uint32_t hostlong);uint16_t htons (uint16_t hostshort);//将网络字节序转换为主机字节序uint32_t ntohl (uint32_t netlong);uint16_t ntohs (uint16_t netshort);说明:h -----host;n----network ;s------short;l----long。
htons()--"Host to Network Short"
htonl()--"Host to Network Long"
ntohs()--"Network to Host Short"
ntohl()--"Network to Host Long"
1234567891011121314
为什么在数据结构 struct sockaddr_in 中, sin_addr 和 sin_port 需要转换为网络字节顺序,而 sin_family 不需要呢?
答案是: sin_addr 和 sin_port 分别封装在包的 IP 和 UDP 层。因此,它们必须是网络字节顺序。但是 sin_family 域只是被内核 (kernel) 使用来决定在数据结构中包含什么类型的地址,所以它必须是本机字节顺序。同时, sin_family 没有发送到网络上,它们可以是本机字节顺序。
IP 地址如何处理:地址转换函数
IP 地址的三种表示格式及在开发中的应用
- 1)点分十进制表示格式
- 2)网络字节序格式
- 3)主机字节序格式
用IP地址127.0.0.1为例:
第一步 127 . 0 . 0 . 1 把IP地址每一部分转换为8位的二进制数。第二步 01111111 00000000 00000000 00000001 = 2130706433 (主机字节序)然后把上面的四部分二进制数从右往左按部分重新排列,那就变为:第三步 00000001 00000000 00000000 01111111 = 16777343 (网络字节序)
1234567
1、函数inet_addr(),将 IP 地址从 点数格式转换成无符号长整型。使用方法如下:
函数原型
in_addr_t inet_addr(const char *cp);12
转换网络主机地址(点分十进制)为网络字节序二进制值,
- cp 代表点分十进制的 IP 地址,如 1.2.3.4
- 如果参数 char *cp 无效则返回 - 1 (INADDR_NONE),
- 此函数有个缺点:在处理地址为 255.255.255.255 时也返回 - 1,虽然它是一个有效地址,但 inet_addr () 无法处理这个地址。
使用
ina.sin_addr.s_addr = inet_addr("132.241.5.10");
1
现在可以将 IP 地址转换成长整型了。有没有其相反的方法可以将一个 in_addr 结构体输出成点数格式?
2、你就要用到函数 inet_ntoa()(“ntoa"的含义是"network to ascii”),就像这样:
函数原型
char* inet_ntoa(struct in_addr in);
1
参数:
- in 代码 in_addr 的结构体,其结构体如下:
struct in_addr
{union {struct { UCHAR s_b1,s_b2,s_b3,s_b4; } S_un_b;struct { USHORT s_w1,s_w2; } S_un_w;ULONG S_addr;} S_un;
};
123456789
使用
SOCKADDR_IN sock;
sock.sin_family = AF_INET;
//将字符串转换为 in_addr 类型
sock.sin_addr.S_un.S_addr = inet_addr("192.168.1.111");
sock.sin_port = htons(5000);//将 in_addr 类型转换为字符串
printf("inet_ntoa ip = %s\n",inet_ntoa(sock.sin_addr));结果输出:
inet_ntoa ip = 192.168.1.111
123456789101112
注意:
inet_ntoa()将结构体in_addr作为一个参数,不是长整形。需要注意的是它返回的是一个指向一个字符的指针,一个由inet_ntoa() 控制的静态的固定的指针,所以每次调用 inet_ntoa(),它将覆盖上次调用时所得的 IP 地址。
例如:
char *a1, *a2;……a1 = inet_ntoa(ina1.sin_addr); /* 这是198.92.129.1 */a2 = inet_ntoa(ina2.sin_addr); /* 这是132.241.5.10 */printf("address 1: %s\n",a1);printf("address 2: %s\n",a2);输出如下:address 1: 132.241.5.10address 2: 132.241.5.10
Via:
计算机网络——网络字节序(大端字节序(Big Endian)\小端字节序(Little Endian)
https://blog.csdn.net/JMW1407/article/details/108637540