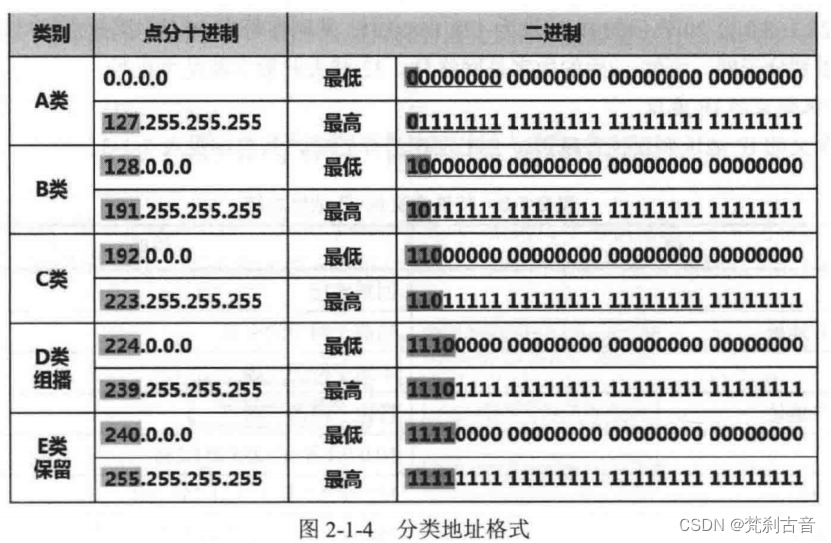
GaussDB关键技术原理:高性能(二)从查询处理综述对GaussDB的高性能技术进行了解读,本篇将从查询重写RBO、物理优化CBO、分布式优化器、布式执行框架、轻量全局事务管理GTM-lite等五方面对高性能关键技术进行分享。
目录
3 高性能关键技术
3.1 查询重写RBO
3.2 物理优化CBO
3.3 分布式优化器
3.4 分布式执行框架
3.5 轻量全局事务管理GTM-lite
3 高性能关键技术
内容概要:本章节介绍GaussDB中实现的高性能关键技术,内容涉及优化器、执行器、分布式数据库、存储引擎等多个方面。
目的:通过对GaussDB数据库关键高性能技术的学习,能够让读者更加清晰的理解数据库内核哪些优化是性能关键点同时也为类似的应用系统实现提供方法论和最佳实践。
3.1 查询重写RBO
在数据库里RBO基于规则的优化一般指查询重写技术,按照一系列关系代数表达式的等价规则,对查询的关系代数表达式进行等价转换,从逻辑上减少执行的总量从而提高查询执行效率,例如,通过条件的推导得出非必要的表扫描、避免非必要的计算表示等。
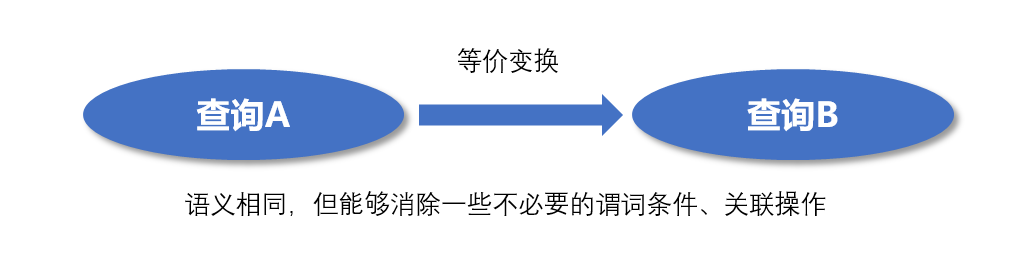
查询重写RBO优化是非常重要的一种逻辑优化手段,通常应用和实施在查询优化过程的前端,将一些肯定能够优化的场景进行优化,RBO优化结束后进行物理优化,以下以常用的几种重写优化进行介绍:
Example 1:谓词化简优化Predicate Simplification
使用谓词查询条件的可满足性Satisfiability (SAT)&可传递性Transitive Closure(TC)对查询进行化简,a.w.k SAT-TC,假设有t1,t2表,他们的定义分别为:T1(c1 int, c2 int);,T2(c1 int, c2 int check (c2 < 30));,则原查询:
SELECT t1.c1,t1.c2, t2.c1, t2.c2
FROM t1 JOIN t2 ON t1.c2 = t2.c2
WHERE t1.c2 > 20可优化为:
SELECT dt1.c1,dt1.c2, dt2.c1, dt2.c2
FROM (select c1,c2 from t1 where t1.c2 between 20 and 30) as dt1,
(select c1,c2 from t2 where t2.c2 between 20 and 30) as dt2
WHERE dt1.c2 = dt2.c2;说明:通过谓词逻辑可以发现当前查询中可以一次实施TC->SAT->TC优化策略。
step1: TC优化:内连接关联条件t1.c2 = t2.c2 && t1.c2 > 20可以得出t2.c2 > 20
step2: SAT优化:t2.c2列上创建有check-constraint可以得出t2.c2 BETWEEN 20 AND 30
step3: TC优化:同理得出t1.c2 BETWEEN 20 AND 30
到此t1,t2在关联之前就可以最大限度减小处理的元组数,达到提升性能的目的,以下是其他SATTC例子:
A=B AND A=C --> B=C
A=5 AND A=B --> B=5
A=5 AND A IS NULL --> FALSE
A=5 AND A IS NOT NULL --> A=5
X > 1 AND Y > X --> Y >= 3
X IN (1,2,3) AND Y=X --> Y IN (1,2,3)Example 2:谓词下推优化Predicate Push Down
将谓词查询条件下沉到中间结果集的最底层提前过滤,可以有效减少读入到内存中数据的数量,减少计算层的代价
优化前:
SELECT MAX(total)
FROM (
SELECT product_key, product_name,
SUM(quantity*amount) AS total
FROM Sales, Product
WHERE sales_product_key=product_key
GROUP BY product_key, product_name
) AS v
WHERE product_key IN (10, 20, 30);优化后:
SELECT MAX(total)
FROM (
SELECT product_key, product_name,
SUM(quantity*amount) AS total
FROM Sales, Product
WHERE sales_product_key=product_key AND product_key IN (10, 20, 30)
GROUP BY product_key, product_name
) AS v
WHERE product_key IN (10, 20, 30);说明:
-
查询在优化前需要事先将中间结果集v计算出。
-
在计算的过程中需要对sales、product两张表的全量数据进行读取进行,然后对结果集进行Group分组、Aggregation聚合操作,但是最终的结果集只要求输出product_key的值为10,20,30的结果集。
-
利用谓词下推规则可以让product_key in(10,20,30)过滤操作在Join之前完成,如果查询条件product_key in(10,20,30)的选择率较低则可以减少Join、Aggregation、Group三个操作处理的数据量,从而提升性能。
Example 3:谓词上移优化Predicate Pullup
将谓词查询条件中比较繁重的函数计算放到最后,期望减小繁重计算的次数达到提升性能的目的。
优化前:
SELECT *
FROM t1,
(SELECT * FROM t2
WHERE complex_func(t2.c2) = 3) AS dt(c1,c2,c3)
WHERE t1.c1 = t2.c1 AND t1.c2 > 30优化后:
SELECT *
FROM t1,
(SELECT * FROM t2) AS dt(c1,c2,c3)
WHERE t1.c1 = t2.c1 AND t1.c2 > 30 AND complex_func(t2.c2) = 3说明:
-
原查询“complex_func(t2.c2) = 3”查询条件在子查询中,如果该条件在子查询DT中被计算则会导致t2表中的全量数据被计算开销较大。
-
通过谓词pullup上移到最外层让t2先和t1做关联和过滤,则能够有效减少complex_func被调用的次数,从而达到性能提升的目的。
查询重写是查询优化器阶主要分类之一,通常可以快速将处理的数据进行成倍数缩减,下图是常见的查询重写分类
3.2 物理优化CBO
在优化器处理完RBO的优化以后,路径的选择往往不能通过实现制定好的规则进行变换,而是需要根据数据的分布(统计信息)情况来对查询执行路径进行评估,从可选的路径中选择一个执行代价最小的路劲进行执行,例如是否选择索引SeqScan vs. IndexScan、选择哪个索引,两表关联选择什么样的连接顺序,选择怎样的具体算法等,因此,可以将物理优化总结为对多个可行的物理执行代价进行评估,选择最优的计划输出到执行器进行执行,例如有以下查询:
select * from t1 join t2 on t1.a=t2.b;可选择的计划有:
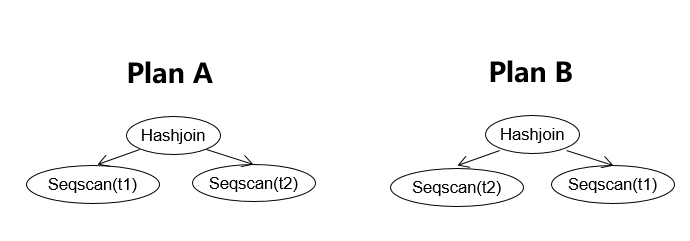
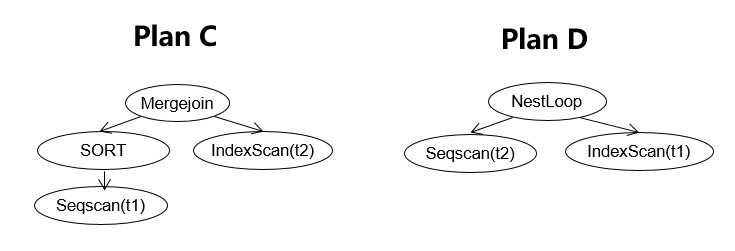
如上图所示,根据T1、T2可访问的执行路径:IndexScan vs. SeqScan,关联算法:HashJoin、MergeJoin、NestLoop;关联内表外表等多个维度的选择,就会生成多达数十种不同的执行计划,由于考虑到T1、T2的表大小,谓词的选择率、是否有索引等因素很难从一个固定的规则里选出一个合理的执行计划,此时需要对T1、T2表的数据特征进行建模,构建代价模型从而选出最优的计划,这个过程按照处理的顺序大体上可以分为:统计信息、行数估算、代价估算、路径搜索、计划生成五个处理步骤:
(1)统计信息,物理优化的依据来源于表信息的统计, 描述基表数据的特征包括唯一值、MCV值等,用于行数估算。
(2)行数估算,代价估算的基础,来源于基表统计信息的推算,估算基表baserel、Join中间结果集joinrel、Aggregation中结果集大小,为代价估算做准备。
(3)代价估算,根据关系的行数,推算出当前算子的执行代价,根据数据量估算不同算子执行代价,各算子代价之和即为计划总代价。
(4)路径搜索,依据若干算子的执行代价对最优路径进行路径搜索,通过求解路径最优算法(e.g. 动态规划、遗传算法)处理连接路径搜索过程,以最小搜索空间找到最优连接路径。
(5)计划生成,将查询的执行路径转换成PlanTree能够输出给执行器做查询执行,在分布式场景下根据数据分布的属性决定Data-Shuffling数据迁移总体方案。
3.3 分布式优化器
分布式数据库场景下表分布在各个节点上,数据的本地性Data Locality是分布式优化器中生成执行计划时重点考虑的因素,基于Share Nothing的分布式数据库中有一个很关键概念就是“移动数据不如移动计算”,之所以有数据本地性就是因为数据在网络中传输会有不小的I/O消耗,网络的overhead通常情况下会大于本地的计算,因此分布式数据库优化的一个重要的原则就是尽量减少这个网络I/O消耗就能够提升效率。例如有以下例子一个聚集查询的例子:
表信息:
- T1: distribute By HASH(c1)
执行查询:
- select sum(c1), c2 from t1 group by c2由于表T1的分布列为c1但实际上要按照c2为键值进行聚集,对聚集列进行重分布是不可避免的一步操作,因此先做聚集还是先做数据迁移重分布就成为分布式优化器的一个选项,针对这一情况可以有以下两种分布式执行计划选择:
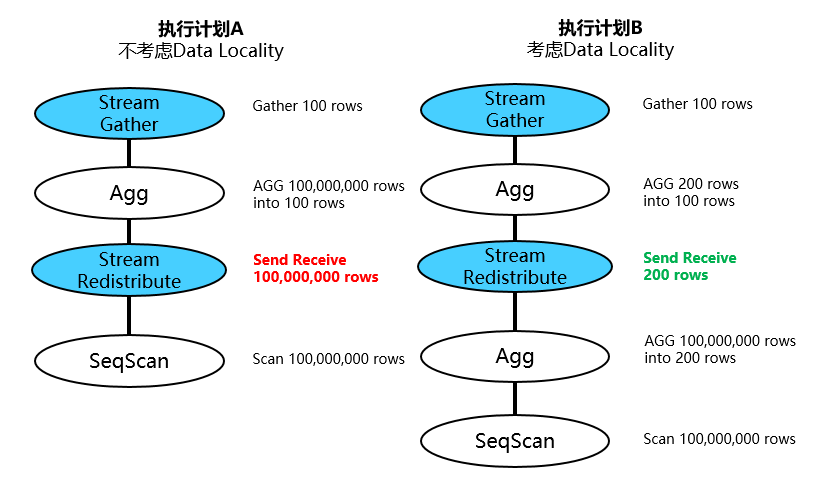
说明:
(1)执行计划A未考虑Data Locality的优化按照聚集的逻辑直接从扫描输出的100m元组进行重分布操作,造成大量的数据传输和网络资源消耗。
(2)执行计划B考虑Data Locality的优化,把AGG算子分解成2次AGG,其中第一次AGG在本地执行对原始数据进行缩减然后再通过网络重分布进入第二次AGG,虽说执行计划B相比A多了1个AGG算子,尽管计算的总量未发生变化但是节省了大量的网络IO操作,端到端提升了查询性能。
表关联也是类似的原理,如果当join列与分布列不一致时,需要网络stream节点算子对数据进行重分布或者复制确保查询执行的语义正确。
3.4 分布式执行框架
由于GaussDB采用的是无共享Shared-nothing的架构,由众多独立且互不共享CPU、内存、存储等系统资源的逻辑节点组成。在这样的系统架构中,业务数据被分散存储在多个物理节点上,数据分析任务会被推送到数据所在位置就近执行,通过控制模块的协调,并行地完成大规模的数据处理工作,实现对数据处理的快速响应。DN是基于本节点存储的数据执行具体的执行计划;DN之间可能会有数据交互,这个数据交互就通过分布式执行框架来完成。分布式框架主要靠网络通信算子Steram完成,Stream算子是分布式执行框架的核心元素,Stream算子主要有2个职责:(1)数据重分布(Data Shuffling):负责将单节点DataNode进程串联成为分布式集群的能力也就是通常理解的数据重分布,其他友商如GreemPlum的Motion节点,VectorWise的DXchg节点也具备类似的功能;(2)分布式流水线(Distribute Pipeline):将原有的分布式执行计划进行并行切分,即以Stream节点作为处理流水线分界由不同的工作线程完成,线程间以PV生产者消费者模式工作,
数据重分布(Data Shuffling)
针对当前GaussDB所支持的数据重分布机制上有3种工作模式:
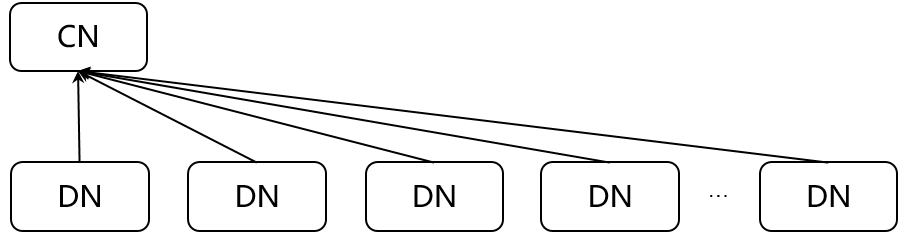
(1)Gather Stream(N:1)每个源节点都将其数据发送给目标节点,一般用于汇总DN节点到CN节点的过程。
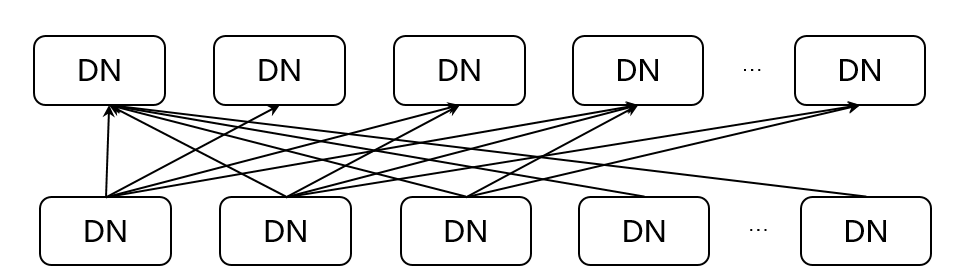
(2)Redistribute Stream(M:N):M个DN节点将其数据根据关联条件、聚集分组表达式算出Hash值,根据重新计算的Hash值进行分布,发送数据到对应的目标节点。一般用于Join、Agg、NodeGroup中的重分布场景。
(3)Broadcast Stream(1:N):有一个源节点将其数据发给N个目标节点。
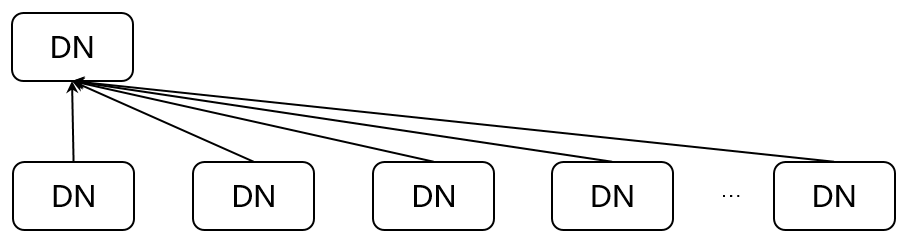
例如下图的分布式执行计划,由于不同的表分布属性不同,因此通过分布式执行框架Stream节点进行数据串联并执行,最后在CN节点进行结果集汇总。
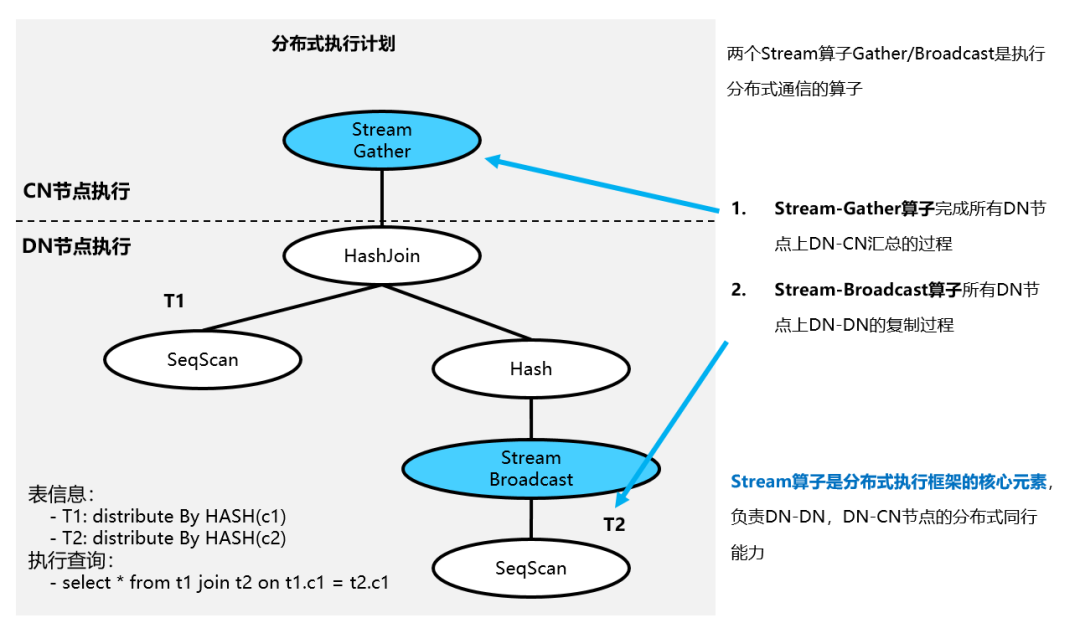
说明:
(1)执行的过程中对T1、T2的扫描都在DN节点上并行完成。
(2)优化器生成的执行计划选择了前一节中描述的方案3,即T1保持不动复制T2到所有节点,并完成分布式HASHJOIN。
(3)HashJoin节点在所有节点上执行完成以后通过Gather节点在CN上进行结果集汇总。
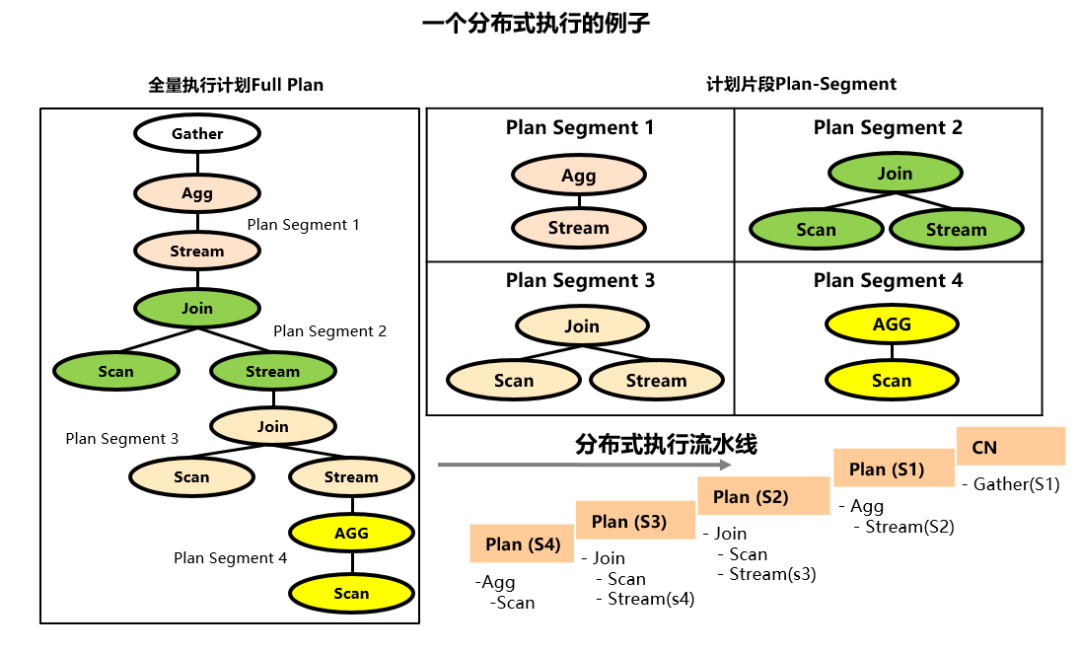
分布式执行流水线(Distribution Pipeline)
在分布式执行过程中如果存在数据搬移,Stream算子的数据发送端、数据接收端有不同的线程完成,他们在时间分片上重叠以并行的方式执行,因此全局执行计划被网络通信算子Stream切分成多个计划片段,分别有不同的线程来完成执行,不同的线程之间采用PC生产者消费者进行交互通信,全局上达到并行执行的效果。如下图,实际的计划执行在DN这一层以Stream算子为界,被切分成多个线程并行处理。
3.5 轻量全局事务管理GTM-lite
GTM,全称Global Transaction Manager,即全局事务管理器,负责全局事务号的分发,事务提交时间戳的分发以及全局事务运行状态的登记,作为事务管理中的重要模块,为支持事务一致性提供必要的保证。事务开始和提交时与GTM进行交互获取必要的全局事务信息,包括事务ID,全局时间戳,全局快照等等。与其他模块一个很重要的不同点就是,为了保证一致性和事务标识全局唯一,集群中只要一个主GTM,即只有一个GTM真正参与事务(不过GTM和DN一样是高可用的,支持一主多备或主备从)。使用GTM来进行事务管理,一个很重要的问题就是会出现单点瓶颈,因为所有需要获取事务唯一标识的事务都需要连接GTM,获取全局快照的时候也都需要连接GTM,在大并发的情况下频繁的交互导致大量的网络通信和锁等待,从而限制了集群性能。
在老的GTM模式下,虽然通过将活跃事务链表替换为CSN来减少了通信量,但是由于仍采用全局事务id的策略,所以每个活跃事务仍要在GTM注册槽位,GTM负责管理和分发全局事务id,这导致当并发量大的时候,GTM容易成为单点瓶颈,主要体现在以下两个方面:
(1)在一个事务的执行流程中,CN会与GTM进行多次交互,如事务开始时在GTM注册槽位、获取快照时从GTM获取全局事务id、事务结束时向GTM提交并移除槽位等,这些频繁的交互会带来大量的网络通信和等待;
(2)当并发量超过槽位数限制时,会由于槽位不够影响业务正常进行。
由此可见,其影响性能的主要原因在于GTM的协调太强,通过对全局事务id的管控,虽然保证了事务的一致性,但是也限制了事务处理的效率。与GTM模式相反,GTM-FREE模式下CN/DN不与GTM交互,通过CN/DN分别维护本地事务id来保证事务系统的正常运行。这种模式下由于缺少全局事务id以及GTM的其他协调(CSN),事务的一致性会受到影响,从而限制了这种模式的适用范围。综上,现有的两种模式在效率和一致性要求上并没有达到一个很好的平衡,而影响这种平衡的主要因素在与“协调”,协调带来更多一致性的保障,但是却降低了性能。由此,一个好的模式应该是在尽可能少的协调的情况下,达到尽可能高的性能,这也是本章介绍的GTM-LITE模式
GTM-LITE的主要目标就是在消除GTM瓶颈影响的同时,尽可能通过更少的信息交互,利用它来协调好事务的并发,从而保证事务一致性的同时提升性能。为此,GTM-LITE的主要设计思路包含以下4点:
(1)本地事务id取代全局事务id。GTM不再分配全局唯一的事务id,每个CN/DN节点用本地产生的事务id,保证节点内事务id不会重复;对于跨节点的事务,由全局唯一的gid标识符前缀来保证写一致性,由全局唯一的csn号来保证事务读的一致性。
(2)GTM不再维护槽位信息,仅在事务提交时下发全局唯一的csn序列号。GTM下发的全局csn是一个递增的uint64值。这一设计消除了BEGIN, GetNewTransactionId同GTM的交互。进一步,如果事务在GTM提交时失败,可以retry重新获取最新的csn,减少网络故障对系统造成的影响。
(3)本地维护多版本过期脏元组的回收,并引入Snapshot Invalid机制,保证全局事务的一致性。由于舍弃全局事务id,无法直接根据RecentGlobalXmin确定需要清理的脏元组,所以需要利用全局csn来计算RecentGlobalXmin,从而实现GTM架构代码的有效复用。
(4)引入prepared array链表对单节点事务可见性判断进行优化。对于单节点的读事务,不再向GTM申请快照,而是使用本地的快照+prepared array链表来进行可见性判断,这种方式在保证读外部一致性的前提下,尽可能的减少同GTM的交互。基本判断方法为:对于csn<本地快照csn的事务以及本地prepared(在prepared array中)且最终提交的事务,均可见。
以上内容从查询重写RBO、物理优化CBO、分布式优化器、布式执行框架、轻量全局事务管理GTM-lite等五方面对高性能关键技术的进行了分享,下篇将从USTORE存储引擎、计划缓存计划技术、数据分区与分区剪枝、列式存储和向量化引擎、SMP并行执行等方面继续解读高性能关键技术,敬请期待!