虚假新闻检测论文调研
Evidence Inference Networks for Interpretable Claim Verification
基本信息
发表刊物和年份:2021 AAAI
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q29CeLId-1633149862852)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002120839031.png)])](https://img-blog.csdnimg.cn/15536034076d4208ad708a787c98775d.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
摘要
现有方法的缺点
-
现有的方法构造了适当的交互模型(文本与文本,文本与评论,文本与社交网络,这里是指文本与文本之间)来探索声明和相关文章之间的语义冲突,为获得声明中的可解释性的语义特征提供了较为实用的解决方案。
-
然而,这些冲突并不一定都是在质疑声明中的的虚假部分,这使得相当多的语义冲突难以作为证据来解释声明验证的的结果,尤其是那些无法确定声明语义的冲突。
-
本文提出了证据推理网络(EVIN),它关注声明的核心语义冲突,并作为用来解释声明语义冲突的依据。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oY0dO6Wz-1633149862855)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002120759887.png)]](https://img-blog.csdnimg.cn/fe44cf42e74e4c1fbfac81169f4615a0.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
本文做出的贡献
-
1.EVIN首先在相关文章中捕获了声明的核心语义部分和用户的主要观点。
-
2.它从这些观点中精细地识别出每个相关文章中包含的语义冲突
-
3.EVIN构建了一致性模型,以匹配目标声明中核心语义片段作为可解释证据的冲突。
•在两个广泛使用的数据集上的实验表明,EVIN不仅取得了令人满意的性能,而且为最终用户提供了可解释的证据(即核心的语义冲突)
解决方法
-
1.首先设计交互共享层,使声明能够与相关文章交互,自适应地捕获声明中最能表达用户观点的广核心语义段,以及用户在相关文章中的整体观点
-
2然后,本文设计了一个细粒度的冲突发现层,允许整体观点与每个相关文章的个人观点交互,以探索潜在的语义冲突
-
3为了选择能够成为真实证据的冲突,我们提出了证据感知的一致层来构建声明的核心语义段与获得的冲突之间的一致性模型,该模型可以将用户观点与相关声明的核心语义的冲突相匹配(观点匹配)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0UVcrS9Y-1633149862855)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002121331635.png)]](https://img-blog.csdnimg.cn/cc84b3ffea724f44bb1fd1da576eb2a6.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
模型逐层详细解释
输入层
输入由三个种类的序列组成:
-
1声明的文本序列
-
2一个全部相关文章拼接的序列
-
3每个相关文章的序列
对于每一个K TOKEN长度的序列,采用预训练模型获得其每个词的D维度的嵌入(Bert),
对于获得的词嵌入序列shape(K,D),用双向的LSTM学习其的序列特征,则三种输入文本就可以用BiLSTM的最后一隐藏层的输出表示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8dhpLYbd-1633149862857)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002121700039.png)]](https://img-blog.csdnimg.cn/066e45a13c1d4749b1812aa439bc8ede.png)
交互共享层
- 采用交叉注意力机制构建的交互共享层
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fXF9LGQi-1633149862858)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002121859854.png)]](https://img-blog.csdnimg.cn/1a793088fed244f38f30925174a0797f.png)
Q是所有文本的表达,K=V是声明本身
- 采用多头注意力机制提高网络的并行性,每个注意力头的QKV采用不同的权值W
•获得一个文章关于其他用户声明的新的表示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ibBwIxu0-1633149862859)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002122031239.png)]](https://img-blog.csdnimg.cn/72a3afca4dbb4e02a1856516b41ae9e9.png)
两个门仿射吸收模块编码上下文特征
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JWdA96Zm-1633149862859)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002122213644.png)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5CENqMej-1633149862860)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002122158211.png)]](https://img-blog.csdnimg.cn/93360a0324c8421ea52b99aba8a6e38d.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)

-
门仿射吸收模块:
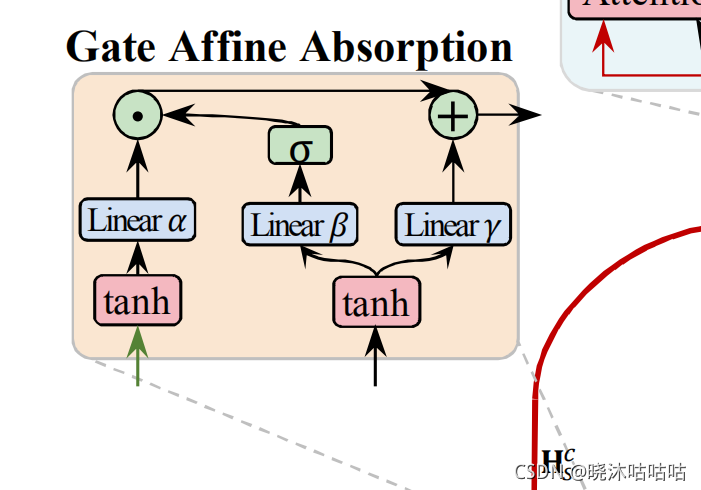
考虑到交互特征是声明和相关文本所共享的,缺乏他们各自的序列特征,所以希望理由门仿射吸收机制使得模型能够抓住上下文的交互性信息
- 既要获得声明中用户普遍关注的突出语义信息,
- 同时也要能够表达出用户的整体观点
做法如下:
- 1对线形映射后的注意力头和声明的表达做非线形映射,提高其各自的非线形特征
- 2然后对各自再做一次线形映射(个人理解是过滤特征,在这个作者的另外一篇文章中有相似的做法)
- 3将得到的映射一方面与BILSTM的隐藏层相拼接,另一部分作为bias
最后经过了门仿射机制处理后,得到的隐藏层输出输出既包含两者共有的特征(核心冲突,整体观点),同时也能够得到相关文章和声明各自的上下文特征。
细粒度的冲突发现层
-
依旧是利用了交叉注意力机制,但是相比于之前文章与全体的评论文本相比,更为细致
-
此时Q,K,V与上有所不同
- 每个评论和每个评论的整体做atttention
![(imoGHj8Zo3Dv-1633149862860)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-201002122620253.png11)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002122620581.png)]](https://img-blog.csdnimg.cn/ae906a2e67de4592ad620dffc39cfcee.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
- 每个评论和每个评论的整体做atttention
证据一致感知层
-
首先使用两个BiLSTM分别将两个核心核心段编码
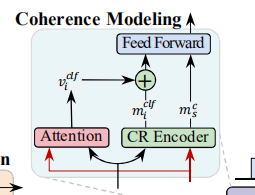
-
然后做attention()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GKEUsWOh-1633149862862)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002123522253.png)]](https://img-blog.csdnimg.cn/afc6f75954814b7fa320f2c9551b281f.png)
-
然后将获得的权重乘上核心冲突(加权冲突语义段)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TL58jbnt-1633149862862)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002123547623.png)]](https://img-blog.csdnimg.cn/db3f76d8a70e45ae8607d62ffee5495c.png)
- 然后将其与BILSTM输出做对应元素相乘喂入全连接神经网络做分类
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8lrPVgpe-1633150307134)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002123633046.png)]20211002123633046.png)] [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cuBHi02C-1633149862863)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002123633046.png)]](https://img-blog.csdnimg.cn/e562dbcd601c485eab245ad86b903586.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vavKfwvg-1633149862863)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002123646990.png)]](https://img-blog.csdnimg.cn/233bfa3cc6814fbb92a6631438ca8518.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
使用的数据集与效果:

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VmSC8141-1633149862863)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20211002123752412.png)]](https://img-blog.csdnimg.cn/9e5b0933a16243719f39d99136f5ed58.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
Different Absorption from the Same Sharing: Sifted Multi-task Learning for Fake News Detection
基本信息
2019EMNLP
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zJ3diL7Y-1633149862864)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922194823452.png)]](https://img-blog.csdnimg.cn/0a6952b2a541489fbc261e545a4d31c2.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
摘要
现有方法的问题
然而,在现有的大多数多任务学习的方法中,共同的特征被完全分配给不同的任务而没有进行选取
(比如将立场检测的特征硬塞给虚假新闻检测任务),这可能导致一些无用甚至不利的特征参与到到特定任务中。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HYkM5KRO-1633149862864)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922195749851.png)]](https://img-blog.csdnimg.cn/8f12967775b541b6a23d5a60ed66f039.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
本文贡献
核心是提出了门控机制对共同特征进行筛选,滤掉共同特征中的不利项
采取的方法
为了解决上述问题,我们设计了具有过滤机制的多任务模型,通过加入立场检测任务来检测假新闻。
具体来说:
-
求共享特征:我们将将共享层的输出引入到每个任务中,用于过滤共享特征。
-
筛选共享特征:由两个单元组成用于选择的共享层特征的部分:
- 用于丢弃无用共享特征的门控单元
- 专注于有利于各自任务的特征的注意力单元。
-
Transformer的使用:此外,为了更好地捕获远程依赖并提高模型的并行性,我们应用了transformer( Vaswani et al., 2017) 到我们的模型,用于对两个任务的输入表示进行编码。实验结果表明,所提出的模型优于比较方法。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OCfas2Er-1633149862865)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922201159520.png)]](https://img-blog.csdnimg.cn/e6dddefcc6cd4fcdb29681032d11a02e.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
模型解释
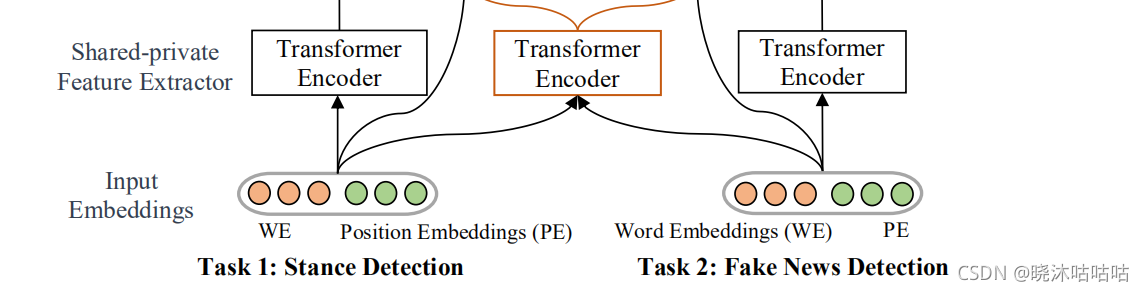
共享层构建
懂得都懂这一步就简单讲(不是重点)
- input是词嵌入和位置编码的拼接(其中位置编码采用独热码,而不是bert推荐的正弦位置编码,原因是表现不佳)
- 然后送到transformer中摘取特征,获得:
- 共享特征
- 立场检测的特征
- 虚假新闻文本的特征
特征选取层
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XPB8dOI3-1633149862865)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922201858269.png)]](https://img-blog.csdnimg.cn/85f568ebdd4940e892107c179fda0e90.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_16,color_FFFFFF,t_70,g_se,x_16)
-
对于每一个任务的这一部分(以下以虚假文本分类举例)
-
门选择(选取共享特征中的有利部分):
-
用非线性激活函数(sigmoid)过滤,W,B 为待训练参数(相当于得到了共享特征中对于每一任务的重要性的权值)
-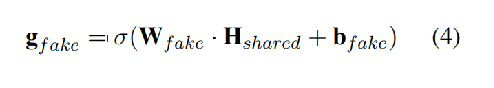
-
再用其点乘共享层输出(权值*特征)
-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hto0O917-1633149862866)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922202646406.png)]](https://img-blog.csdnimg.cn/e6b7a4748c6a474696b2a94f234272d8.png)
-
-
交叉注意力机制
- 这里希望得到的是共享层中各个token关于任务文本的关系(前后transformer的参数共享)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b3wU4195-1633149862866)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922202834956.png)]](https://img-blog.csdnimg.cn/d213fa6d8e3743fbb0d333ef490763b0.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
-
两者连接
-
分类
将上一步输出与各自transformer连接送入全连接分类
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p5mw0G3L-1633149862867)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922203426729.png)]](https://img-blog.csdnimg.cn/cdd6f13cbbee4c4fa62d482d09fec2af.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
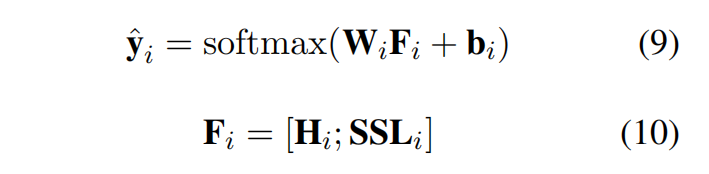
数据集
RumourEval (5568条推,325thread)(在这上面表现性能没有下面的好)
PHEME(105354条推,6426thread)
可视化分析与实验结果对比
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hWQCujci-1633149862867)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922204116970.png)]](https://img-blog.csdnimg.cn/4df67c8f205d4904afb8f6806078137a.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qv6Y9MvC-1633149862867)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922204224284.png)]](https://img-blog.csdnimg.cn/9997a013fcbc42a5908bbac03e62c8d7.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
Capturing the Style of Fake News
基本信息
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pEqkDffr-1633149862868)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922184931013.png)]](https://img-blog.csdnimg.cn/88aeb5aa09534f1db8563dc4ba23a3e1.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
摘要
目前的问题
1.ML 模型可能会学习识别给定文档的来源,并根据来自同一来源的其他文档(即来自网站的其他文章,在训练数据中看到)分配可信度标签。虽然考虑来源的方法具有启发式意义(Metzger、Flana-gin 和 Medders 2010)并且通常建议用于假新闻发现(Hunt 2016),但它在 ML 上下文中可能会产生误导.假新闻网站往往是短暂的(All-cott and Gentzkow 2017),当新的来源取代它们时,这种模式将无济于事。
2.文档主题可能是另一个易于访问但具有误导性的功能。虽然假新闻媒体确实集中在一些保证吸引目标受众的当前主题上(Bakir 和 McStay 2017),但这些主题将随着时间的推移而被替换,从而使分类器过时.在这项研究中,
3我们关注写作风格,即文本的形式而不是其含义(Ray 2015)。由于假新闻来源通常试图为了短期经济利益或政治目标而吸引注意力(Allcott 和 Gentzkow 2017),而不是与读者建立长期关系,因此他们偏爱非正式、耸人听闻、情感丰富的语言(Bakirand McStay 2017)。这个可信度低的指标可以用来建立一个可靠的分类
本文的目标
-
本文旨在以探索基于文本的写作风格的方法来检测低可信度的文本。
-
研究表明,通用的文本分类器,尽管在简单评估时看起来性能很好,但实际上与训练数据中的文档资源过度拟合。
-
为了实现适当的基于风格的预测,我们从223个在线来源中收集了103,219份文件的语料库,并由专家进行标记。
-
设计了现实的评估场景,并设计了两个新的分类器:一个神经网络和一个基于风格测量特征的模型。
-
评估结果显示,所提出的分类器在处理以前未见过的主题(如新事件)和以前未见过的来源(如新兴的新闻网站)的文件时保持了较高的准确性。
-
同时对基于文体风格的模型的分析表明,它确实集中在情感词汇上,这些词汇是典型的假新闻的特征。
本文的贡献
-
.提供了一个包含103219个文档的文本语料库,涵盖了广泛的主题,来自223个来源,这些来源基于PolitiFact和Pew研究中心进行的研究,这些研究是构建文本分类器的有用资源
-
2.使用语料库构建评估环境,训练的时候通过将其应用于来源和主题不可用的文档,更现实地衡量可信度评估方法的性能。
-
3提出了两种分类器:一种是神经网络,另一种是基于文本特征分析的特征的模型,并证明后者确实捕获了情感语言元素
(其实相比于方法,本文核心更侧重于语料库的搭建,其实提出的文本风格的效果没有bert好)
语料库的构建
-
我们使用PolitiFact在2017年标记为假新闻(192个来源)和冒名顶替者(49个)(Gillin 2017)的网站。
-
不幸的是,在2019年,只有不到四分之一的网站仍处于活动状态,但大多数网站仍在WayBackMachine archives6中可用。由于该列表上次更新日期为2017年11月9日,因此对2017年1月1日至2017年11月9日期间可用的网站进行爬取
-
根据中华人民共和国的调查报告(Mitchell等人,2014年),根据可靠来源,我们选择了21家可信或不可信的来源。该程序总共保留了205个不可信网站和18个可信网站并进行爬取。
-
们使用Mallet(McCallum 2002)中实施的LDA(Blei、Ng和Jordan 2003)计算了100个主题的模型。接下来,将每个文档分配给与其关联性最强的主题。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mZ1E3Y0q-1633149862868)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922190213240.png)]](https://img-blog.csdnimg.cn/3e0d2ac6ebab480bb402830fd6d2682e.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
图1显示了来自可信和不可信来源的文档中有多少被分配到最大的15个主题,这些主题由相关关键字描述。我们可以看到,一些主题在不可信的部分更受欢迎:现任总统与其前任和竞选对手之间的比较(主题19和70)、媒体报道(#85)、穆斯林和移民(#23和#11)以及健康/营养(#76)。可靠消息来源更常涉及的领域包括电影(50)和体育(5)。在这两个阶层中普遍存在的问题是俄罗斯调查(62)、犯罪(55)和中东和韩国的国际冲突(17和2)
构建模型
基于文本风格的分类器
在这项研究中,我们特别注意避免采用能够让分类器过度拟合特定来源和主题的特征。这就是为什么我们使用 n-gramsof Part of Speech (POS) 标签而不是流行的 n-gram 词
核心:字典的使用
-
字典的使用:
- 例如Linguistic Inquiry 和 WordCount(LIWC)(Tausczik 和 Pennebaker 2009),用于假新闻检测(Horne 和 Adali 2017;Rashkin 等人 2017;Ṕerez-Rosas 等人 2009)。 ),
- General Inquirer(GI)(Stone et al. 1962),用于超党派新闻识别(Potthast et al. 2018)。
扩充字典:这些资源的弱点在于有限的字典大小,例如GI 包含 182 个类别 8640 个单词7。因此,我们通过根据word2vec(Mikolov et al. 2013)表示用相似的词扩展每个类别来增加其大小。
- 首先,对于 大小为 n 的每个类别,我们构建属于该类别的逻辑回归模型(此时文本已经向量化)。然后,将 4×n 个得分最高的新词添加到类别中。对所有 182 个类别执行此过程会生成一个总大小为 34,293 个单词的字典
-
本文特征的选取:
文档由Stanford CoreNLP(Manning et al. 2014)预处理,包括句子分割、标记化和词性标注。该注解用于生成以下文档特征
- 句子数,平均句子长度(以字为单位)和平均字长(以字符为单位)
- 匹配不同字母方案的字数(全部小写,全部大写,仅第一个字母大写的情况),按文档长度归一化
- POS unigrams(单词)、bigrams(双词) 和trigrams(三词的频率) 的频率,按文档长度归一化计算(如果存在于至少 5 个文档中)
- 属于上文构建的扩展 GI 中属于 182 个单词类别的单词的频率字典,按文档长度归一化。
-
执行分类:
该数据集包括由 39,235 个特征描述的 103,219 个实例。(并没有用到神经网络)
我们采用两阶段方法来选择相关特征:首先进行初步过滤,然后构建一个正则化分类器。
- 初步过滤:使用皮尔逊相关性(画相关性图),选取相关性大的特征作为分类依据(选取关联度比较大的特征)
- 构建分类:逻辑回归+正则化,0.5为阈值
基于深度学习的方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8ef6CLrm-1633149862868)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922193049352.png)]](https://img-blog.csdnimg.cn/3f3dd824a6cc443abdc31fa43529de8b.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_19,color_FFFFFF,t_70,g_se,x_16)
其他比较
-
词袋模型:
池袋模型通过单词的词形(基本形式)的一元组、二元组和三元组的频率来表示文档,至少出现在 200 个文档中。特征过滤和逻辑回归模型构建与风格分类后部分一致。

-
bert:
bert的种类是uncased bert,将bert的表示cls用线性分类器分类
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iQBFq6Ro-1633149862869)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922193610249.png)]](https://img-blog.csdnimg.cn/78c64e9837c84c5db7192901c3c19abe.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
分类精确度
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AwzXlub2-1633149862869)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922193716762.png)]](https://img-blog.csdnimg.cn/73964316a382401bbc2be9d8b6e71096.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_20,color_FFFFFF,t_70,g_se,x_16)
对词的识别
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J3NVQW08-1633149862869)(C:\Users\xiaoMu\AppData\Roaming\Typora\typora-user-images\image-20210922193813862.png)]](https://img-blog.csdnimg.cn/1bcd1a10742f48b7a31859eb144388dc.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pmT5rKQ5ZKV5ZKV5ZKV,size_19,color_FFFFFF,t_70,g_se,x_16)
Different Absorption from the Same Sharing: Sifted Multi-task Learning
基本信息

现有方法的问题
最近的方法通过考虑在训练中加入与声明相关的外部元素来进行虚假文本分类。然而,这些方法需要大量的特征建模和丰富的词典。
本文克服了先前工作的这些局限性,建立了一个端对端模型,用于对任意文本声明进行可解释性的可信度评估,而不需要任何人工干预。 它提出了一个神经网络模型,该模型可以聚合来自外部相关文章的信息、这些文章的语义和其来源的可信度。 它还得出了生成用户可理解的解释的信息特征,使神经网络预测对终端用户透明。
四个数据集的实验和消融实验的研究显示了我们方法的优势。
本文贡献
- 模型:提出了一个端到端的神经网络模型,能够自动评估声明的可信度,没有使用到任何人工提取的特征或引入词典。
- 可解释性:我们模型中的注意力机制,能够生成用户可理解的解释,使可信度判决透明和具有可解释。
- 实验:对四个数据集和消融实验的实验,证明了我们的方法在最先进的基线上的有效性
数据解释

总共涉及四个数据:
- 一个大小为n的声明集合
- 每个声明集合中需要带有m个相关文章
- 每个相关文章的出处
- 声明的出处
模型解释
输入本文嵌入
输入有两部分组成
- 待验证的声明自身
- 相关文章
在进行嵌入的过程中,声明和文章词嵌入层共享参数(目的是保证输出的语义一致)
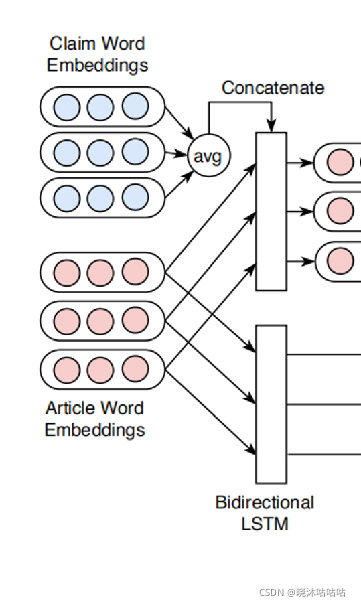
相关评再输入论输入双向LSTM中得到隐藏层输出
针对声明的注意力机制
本文关注于文章中与声明相关词的训练。
为此,我们计算文章中每个token相对于相应声明的整体表示的重要性(为其加权)。
此外,加入注意力有助于使模型透明和检测的可解释,因为它提供了一种在文章中生成最显著的词作为我们模型判断的证据的方法。
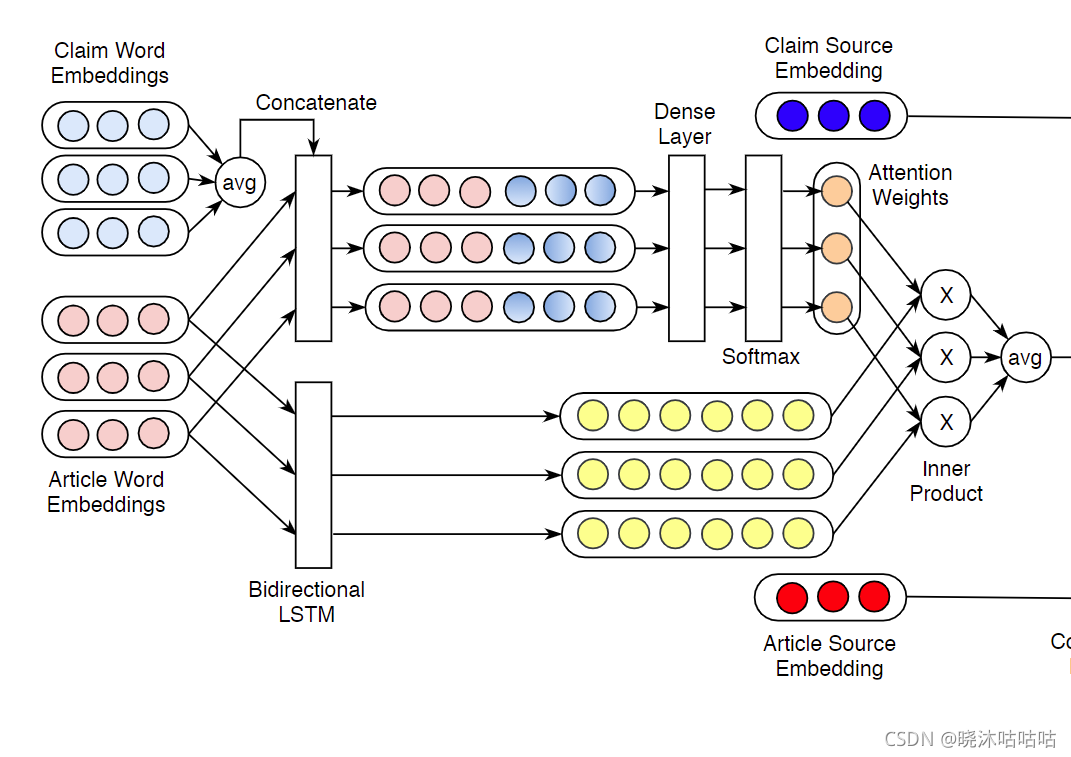
- 其中输入声明的整体表示是通过取所有词嵌入的平均值生成的
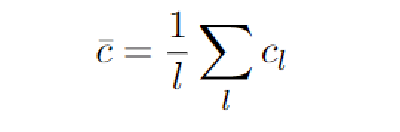
- 我们把这种对claim的总体表述与每个文章的嵌入表示进行拼接。
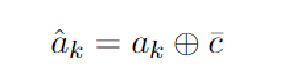
- 然后过全连接神经网络(激活函数为softmax)输出每个词的权重
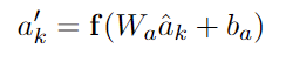
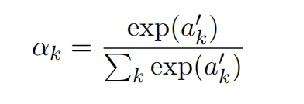
- 然后权重点乘相关文本的token
引入文体元数据(声明来源与相关文章来源)
- 首先对乘上注意力权重后得到的所有文章表示进行加权平均,基于它们相应的注意力得分。
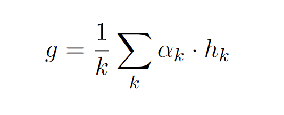
- 然后与声明源,文章源的嵌入进行连接,喂入两个全连接层
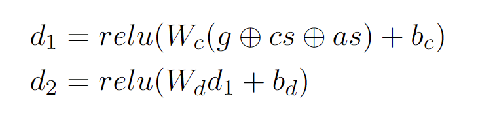
- 最后softmax输出结果。

数据集
还是这两

模型表现