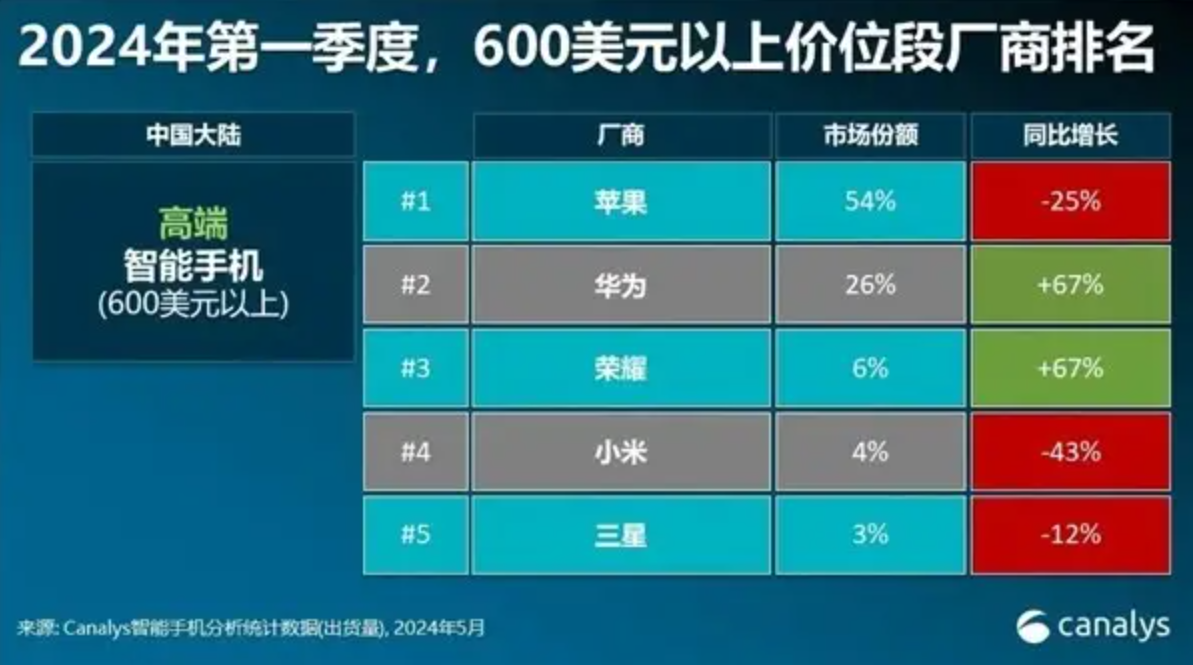
K近邻算法
备注
- kNN是一种基本分类与回归方法.
- 多数表决规则等价于0-1损失函数下的经验风险最小化,支持多分类, 有别于前面的感知机算法
- kNN的k和KDTree的k含义不同
- KDTree是一种存储k维空间数据的树结构
- 建立空间索引的方法在点云数据处理中也有广泛的应用,KDTree和八叉树在3D点云数据组织中应用比较广
- KDTree是平衡二叉树
- KDTree的搜索问题分为k近邻查找和范围查找,一个是已知 k k k,求点集范围,一个是已知范围,求里面有k个点。范围查找问题在维度高的时候复杂度非常高,不太推荐用KDTree做范围查找。
- K近邻问题在杭电ACM里面有收录,HUD4347
- 图像的特征点匹配,数据库查询,图像检索本质上都是同一个问题–相似性检索问题。Facebook开源了一个高效的相似性检索工具Faiss,用于有效的相似性搜索和稠密矢量聚类。
𝑘 近邻法是基本且简单的分类与回归方法。 𝑘 近邻法的基本做法是:对给定的训练实例点和输入实例点,首先确定输入实例点的 𝑘 个最近邻训练实例点,然后利用这 𝑘 个训练实例点的类的多数来预测输入实例点的类。
2. 𝑘 近邻模型对应于基于训练数据集对特征空间的一个划分。 𝑘 近邻法中,当训练集、距离度量、 𝑘 值及分类决策规则确定后,其结果唯一确定。
3. 𝑘 近邻法三要素:距离度量、 𝑘 值的选择和分类决策规则。常用的距离度量是欧氏距离及更一般的pL距离。 𝑘 值小时, 𝑘 近邻模型更复杂; 𝑘 值大时, 𝑘 近邻模型更简单。 𝑘 值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的 𝑘 。常用的分类决策规则是多数表决,对应于经验风险最小化。
4. 𝑘 近邻法的实现需要考虑如何快速搜索k个最近邻点。kd树是一种便于对k维空间中的数据进行快速检索的数据结构。kd树是二叉树,表示对 𝑘 维空间的一个划分,其每个结点对应于 𝑘 维空间划分中的一个超矩形区域。利用kd树可以省去对大部分数据点的搜索, 从而减少搜索的计算量。
k近邻模型
算法
输入: T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x N , y N ) } , x i ∈ X ⊆ R n , y i ∈ Y = { c 1 , c 2 , … , c k } T=\{(x_1,y_1),(x_2,y_2),\dots,(x_N,y_N)\}, x_i\in \cal{X}\sube{\bf{R}^n}, y_i\in\cal{Y}=\{c_1,c_2,\dots, c_k\} T={(x1,y1),(x2,y2),…,(xN,yN)},xi∈X⊆Rn,yi∈Y={c1,c2,…,ck}; 实例特征向量 x x x
输出: 实例所属的 y y y
K近邻算法三要素如下黑体:
步骤:
-
根据指定的距离度量,在 T T T中查找 x x x的最近邻的 k k k个点,覆盖这 k k k个点的 x x x的邻域定义为 N k ( x ) N_k(x) Nk(x)
-
在 N k ( x ) N_k(x) Nk(x)中应用分类决策规则决定 x x x的类别 y y y
y = arg max c j ∑ x i ∈ N k ( x ) I ( y i = c j ) , i = 1 , 2 , … , N , j = 1 , 2 , … , K y=\arg\max_{c_j}\sum_{x_i\in N_k(x)}I(y_i=c_j), i=1,2,\dots,N, j=1,2,\dots,K y=argcjmaxxi∈Nk(x)∑I(yi=cj),i=1,2,…,N,j=1,2,…,K
距离度量
特征空间中的两个实例点的距离是两个实例点相似程度的反映。
距离越近(数值越小), 相似度越大。
这里用到了 L p L_p Lp距离,
- p = 1 p=1 p=1 对应 曼哈顿距离
- p = 2 p=2 p=2 对应 欧氏距离
- 任意 p p p 对应 闵可夫斯基距离
L p ( x i , x j ) = ( ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ p ) 1 p L_p(x_i, x_j)=\left(\sum_{l=1}^{n}{\left|x_{i}^{(l)}-x_{j}^{(l)}\right|^p}\right)^{\frac{1}{p}} Lp(xi,xj)=(l=1∑n xi(l)−xj(l) p)p1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FR0NLtYn-1640089789079)(assets/fig3_2.png)]](https://i-blog.csdnimg.cn/blog_migrate/70fca19b6dd213d51ce2e48b2d56bf7c.png)
考虑二维的情况, 上图给出了不同的 p p p值情况下与原点距离为1的点的图形。
这个图有几点理解下:
- 与原点的距离
- 与原点距离为1的点
- 前一点换个表达方式, 图中的点向量( x 1 x_1 x1, x 2 x_2 x2)的 p p p范数都为1
- 图中包含多条曲线, 关于p=1并没有对称关系
- 定义中 p ⩾ 1 p\geqslant1 p⩾1,这一组曲线中刚好是凸的
补充:
范数是对向量或者矩阵的度量,是一个标量,这个里面两个点之间的 L p L_p Lp距离可以认为是两个点坐标差值的 p p p范数。
k k k值选择
- 关于 k k k大小对预测结果的影响, 书中给的参考文献是ESL, 这本书还有个先导书叫ISL.
- 通过交叉验证选取最优 k k k, 算是超参数
- 二分类问题, k k k选择奇数有助于避免平票
分类决策规则
Majority Voting Rule
误分类率:
1 k ∑ x i ∈ N k ( x ) I ( y i ≠ c i ) = 1 − 1 k ∑ x i ∈ N k ( x ) I ( y i = c i ) \frac{1}{k}\sum_{x_i\in N_k(x)}{I(y_i\ne c_i)}=1-\frac{1}{k}\sum_{x_i\in N_k(x)}{I(y_i= c_i)} k1∑xi∈Nk(x)I(yi=ci)=1−k1∑xi∈Nk(x)I(yi=ci)
如果分类损失函数是0-1损失, 误分类率最低即经验风险最小.
构造KDTree
KDTree的构建是一个递归的过程
注意: KDTree左边的点比父节点小,右边的点比父节点大。
这里面有提到,KDTree搜索时效率未必是最优的,这个和样本分布有关系。随机分布样本KDTree搜索(这里应该是最近邻搜索)的平均计算复杂度是 O ( log N ) O(\log N) O(logN),空间维数 K K K接近训练样本数 N N N时,搜索效率急速下降,几乎 O ( N ) O(N) O(N)
看维度,如果维度比较高,搜索效率很低。当然,在考虑维度的同时也要考虑样本的规模。
考虑个例子
[[1, 1],[2, 1],[3, 1],[4, 1],[5, 1],[6, 1],[100, 1],[1000, 1]]
k k k近邻查找
KNN查找已知查询点 p p p,树当前节点 o o o,近邻数目 k k k
可以用一个优先队列存储最优的 k k k个点,每次比对回溯节点是否比当前最优点更优的时候,就只需用当前最优中距离 p p p最远的节点来对比,而这个工作对于优先队列来说是 O ( 1 ) O(1) O(1)的[^3]
范围查询
给定一个范围,问其中有多少点。比较常见的应用是GIS类应用,使用者附近多大半径内包含多少单车,多少酒店等。
实际上为了实现快速搜索, 在空间数据的存储结构上要有考虑。
这段代码实现了一个简单的 K 最近邻(KNN)算法,使用了 KD 树(K-Dimensional Tree)来加速最近邻搜索。以下是对代码的逐行解释:
代码结构
-
导入必要的库
from collections import namedtuple from pprint import pformat import numpy as npnamedtuple用于创建轻量级的类,便于存储节点信息。pformat用于格式化输出。numpy是一个用于数值计算的库,提供了高效的数组操作。
-
定义 Node 类
class Node(namedtuple('Node', 'location left_child right_child')):def __repr__(self):return pformat(tuple(self))Node类表示 KD 树中的一个节点,包含三个属性:location:节点的位置(数据点)。left_child:左子树。right_child:右子树。
__repr__方法用于格式化节点的输出,便于调试。
-
定义 KNN 类
class KNN(object):- 定义一个名为
KNN的类,表示 K 最近邻算法的实现。
- 定义一个名为
-
初始化方法
def __init__(self, k=1, p=2):self.k = kself.p = pself.kdtree = None__init__方法接受两个参数:k:表示要查找的最近邻的数量,默认为 1。p:表示距离度量的阶数,默认为 2(欧几里得距离)。
self.kdtree用于存储构建的 KD 树。
-
构建 KD 树
@staticmethod def _fit(X, depth=0):try:k = X.shape[1]except IndexError as e:return Noneaxis = depth % kX = X[X[:, axis].argsort()]median = X.shape[0] // 2try:X[median]except IndexError:return Nonereturn Node(location=X[median],left_child=KNN._fit(X[:median], depth + 1),right_child=KNN._fit(X[median + 1:], depth + 1))_fit方法是一个静态方法,用于递归构建 KD 树。depth参数用于跟踪当前的深度,以确定在哪个维度上进行分割。- 通过
X.shape[1]获取数据的维度 k k k。 - 使用
depth % k确定当前分割的轴。 - 将数据按当前轴排序,并找到中位数。
- 创建一个
Node,将中位数作为节点位置,并递归构建左子树和右子树。
-
计算距离
def _distance(self, x, y):return np.linalg.norm(x - y, ord=self.p)_distance方法计算两个点之间的距离,使用 NumPy 的linalg.norm函数,根据给定的 p p p 值计算距离。
-
搜索最近邻
def _search(self, point, tree=None, depth=0, best=None):if tree is None:return bestk = point.shape[0]if best is None or self._distance(point, tree.location) < self._distance(best, tree.location):next_best = tree.locationelse:next_best = bestif point[depth % k] < tree.location[depth % k]:next_branch = tree.left_childelse:next_branch = tree.right_childreturn self._search(point, tree=next_branch, depth=depth + 1, best=next_best)_search方法用于在 KD 树中查找最近邻。- 如果树为空,返回当前最佳结果。
- 更新最佳结果
next_best,如果当前节点比最佳结果更接近目标点。 - 根据当前点在当前维度上的值决定搜索左子树还是右子树。
- 递归调用
_search方法,继续在选定的子树中查找。
-
训练模型
def fit(self, X):self.kdtree = KNN._fit(X)return self.kdtreefit方法用于训练模型,构建 KD 树并存储在self.kdtree中。
-
预测最近邻
def predict(self, X):rst = self._search(X, self.kdtree)return rstpredict方法用于预测给定点的最近邻,调用_search方法进行查找。
总结
这段代码实现了一个基于 KD 树的 K 最近邻算法。通过构建 KD 树,能够高效地进行最近邻搜索。该实现包括了 KD 树的构建、距离计算和搜索功能,适合用于处理多维数据的最近邻查询。
from collections import namedtuple
from pprint import pformat
import numpy as npclass Node(namedtuple('Node', 'location left_child right_child')):def __repr__(self):return pformat(tuple(self))class KNN(object):def __init__(self,k=1,p=2):""":param k: knn:param p:"""self.k = kself.p = pself.kdtree = None@staticmethoddef _fit(X, depth=0):try:k = X.shape[1]except IndexError as e:return None# todo: 这里可以展开,通过方差选择axis = depth % kX = X[X[:, axis].argsort()]median = X.shape[0] // 2try:X[median]except IndexError:return Nonereturn Node(location=X[median],left_child=KNN._fit(X[:median], depth + 1),right_child=KNN._fit(X[median + 1:], depth + 1))def _distance(self, x, y):return np.linalg.norm(x-y, ord=self.p)def _search(self, point, tree=None, depth=0, best=None):if tree is None:return bestk = point.shape[0]# update bestif best is None or self._distance(point, tree.location) < self._distance(best, tree.location):next_best = tree.locationelse:next_best = best# update branchif point[depth%k] < tree.location[depth%k]:next_branch = tree.left_childelse:next_branch = tree.right_childreturn self._search(point, tree=next_branch, depth=depth+1, best=next_best)def fit(self, X):self.kdtree = KNN._fit(X)return self.kdtreedef predict(self, X):rst = self._search(X, self.kdtree)return rst







![[数据集][目标检测]课堂行行为检测数据集VOC+YOLO格式4065张12类别](https://i-blog.csdnimg.cn/direct/4bfdea155da84365bc16a5f849e9160b.png)