数据湖架构结合了数据湖和数据仓库。虽然它不仅仅是两者之间的简单集成,但其理念是充分发挥两种架构的优势:数据仓库的可靠交易以及数据湖的可扩展性和低成本。
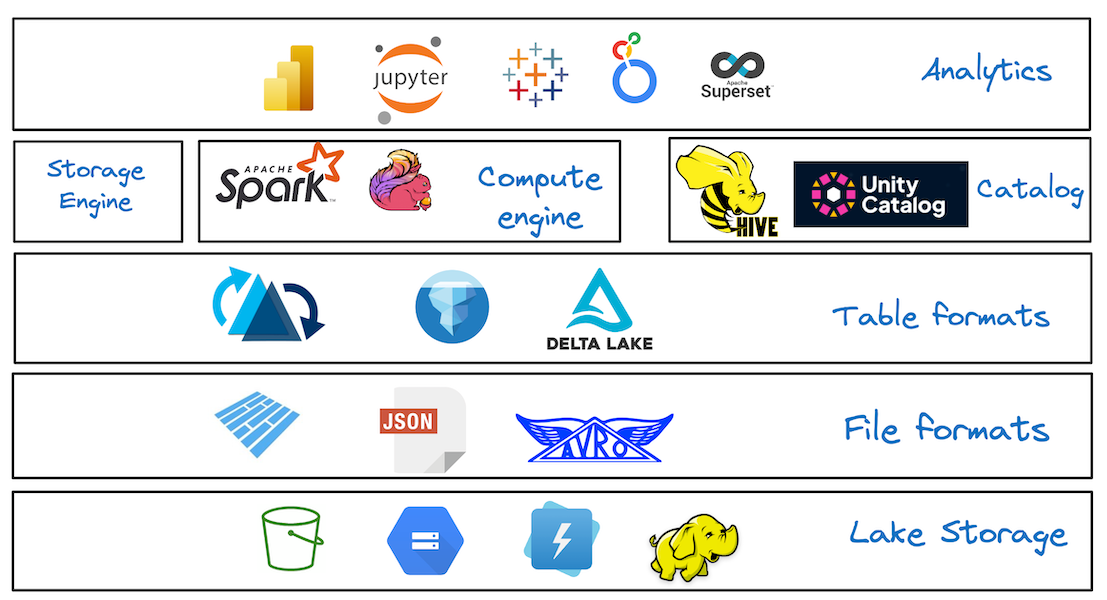
Lakehouse 架构支持管理各种数据类型,例如结构化、半结构化和非结构化数据,并可满足各种用例的需求,包括商业智能、机器学习和实时流式传输。这种灵活性使企业能够摆脱传统的两层架构——使用仓库处理关系工作负载,使用数据湖进行机器学习和高级分析。因此,组织可以通过使用单个数据存储来降低运营成本并简化其数据策略。
目前比较常用的数据湖有hudi、iceberge、delta lake及paimon。
| 项目 | Apache Iceberg | Apache Hudi | Delta Lake | Apache Paimon |
| 开源时间 | 2018/11/6 | 2019/1/17 | 2019/4 | 2023/3/12 |
| Github Star | 6.1k | 5.3k | 7.4k | 2.3k |
| update/delete | 支持 | 支持 | 支持 | 支持 |
| 文件合并 | 手动 | 自动 | 自动 | 自动 |
| 历史数据清理 | 手动 | 自动 | 自动 | 自动 |
| 文件格式 | parquet,avro,orc | parquet,avro | parquet | parquet,avro,orc |
| 计算引擎 | Hive/Spark/Presto/Flink/Impala /Trino等 | Hive/Spark/Presto/Flink/Impala /Trino等 | Hive/Spark/Presto | Hive/Spark/Presto/Flink /Trino |
| 存储引擎 | HDFS/S3 | HDFS/S3/OBS/ALLUXIO/Azure | HDFS/S3/Azure | HDFS/S3/OSS |
| SQL DML | 支持 | 支持 | 支持 | 支持 |
| ACID事务 | 支持 | 支持 | 支持 | 支持 |
| 索引 | 不支持 | 支持 | 不支持 | 支持 |
| Timeline | 支持 | 支持 | 支持 | 支持 |
| 可扩展的元数据存储 | 支持 | 支持 | 支持 | 支持 |