一、概述
title:Injecting Domain Knowledge in Language Models for Task-Oriented Dialogue Systems
论文地址:https://arxiv.org/abs/2212.08120
代码:GitHub - amazon-science/domain-knowledge-injection
1.1 Motivation
- 如何在PLM中引入特定领域的知识是一个问题。
- 对话大量的,静态的外部知识,可以通过下游继续做fine-tuning来实现(这个待确定是否是这个意思),但是对于任务型对话系统task-oriented dialogue(TOD)来做,领域知识是可以修改的,可变的,直接利用fine-tuning来做成本比较大。
1.2 Methods
- 针对于TOD任务,通过注入的方式引入特定领域知识,而不是通过fine-tuning来实现。
- 通过一个轻量级的adpter,与PLMs预训练模型的中间层的表征进行结合,来指导模型的预测,通过这种方式引入外部知识。好处是可以将不同的KBs知识,学习到的内容做成一个repository的服务,然后在PLMs大语言模型端进行集成。
- 最后通过knowledge probing using response selection (KPRS)生成选择的知识探针来衡量知识注入的有效性。
1.3 Conclusion
- 构建了一个轻量级的adapter来集成外部知识,这种adapters能够以较高的精度记住KBs知识。
- 通过探针实验,验证了此方法既能够生成于对话历史一致的对话,同时还与内部知识库KB相关。
- 证明了可以接入领域知识而没必要直接去请求外部知识库,降低了机器人在query处理工程化的一些需求。
1.4 limitation
- 还需要人工设置模板来将三元组知识引入。
- 不能适应与实时的数据修改,因为每次修改都需要重新训练一下adapter。
- 尽管注入知识的准确率还可以,但是可能会犯错。
- KPRS只评估了是否能引入事实数据,没有确保他可以理解和利用这些知识做复杂的推理。
二、详细内容
2.1 如何将原始的知识图谱知识转化成自然语言形式的知识呢?

相当于是利用模板做了一个转换,将三元组的知识,转化成自然语言处理的形式。
2.2 如何 Memorization(记忆)& Utilization(利用)知识?
在记忆阶段,适配器连接到冻结的PLM,并负责重新构建损坏的KB事实,相当于利用2.1的数据,冻结原始PLM,基于该知识训练adapters模型记住特定领域的知识数据。具体任务是mask单个attribute属性来实现。
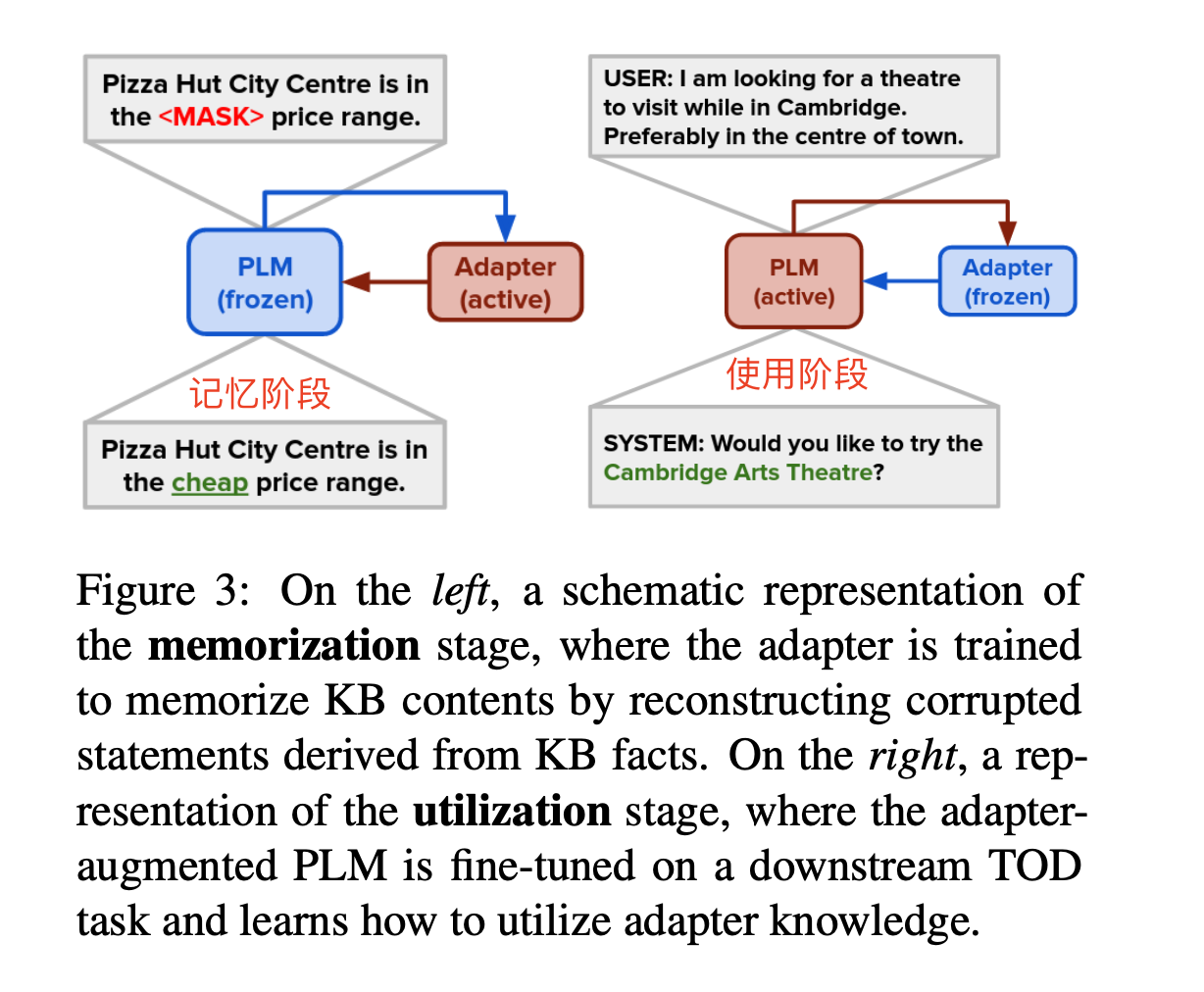
- 说明:
-
- 记忆阶段:冻结了PLM,然后训练adapter去记住kb知识。
- 使用阶段:冻结了adapter(保存原始知识),然后继续在下游任务上做fine-tuning,学会利用adapter中的知识。
2.3 探针实验的测试样例

可以看出,探针实验中,有reference,这个是和原始知识相关的,用绿色来表示,另外红色,感觉是没有出现在原始知识中。
2.4 实验结果
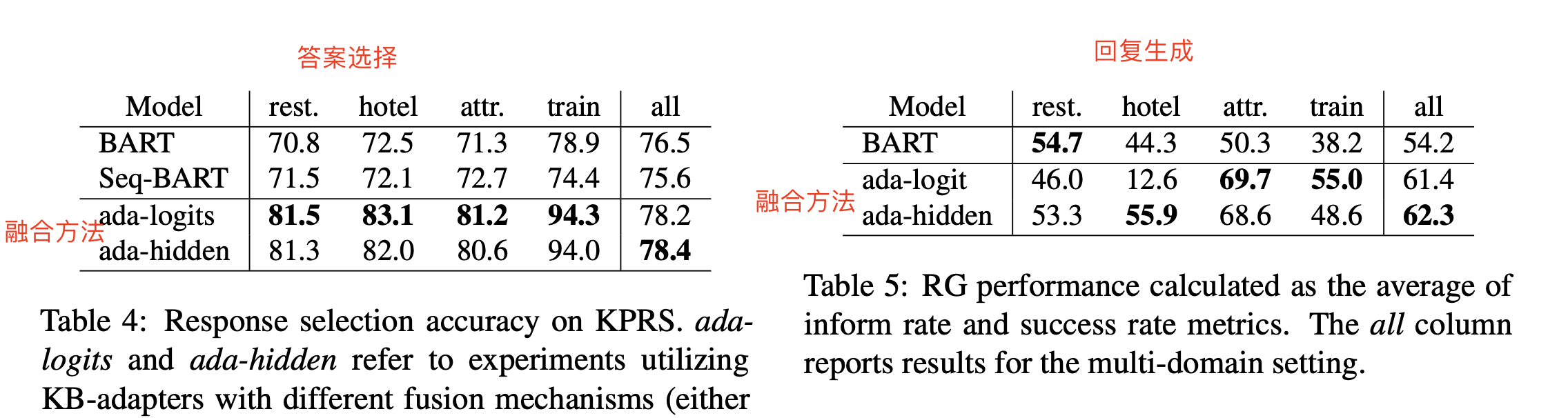
- 比较了引入图谱知识的效果,以及不同融合方法的效果差异。