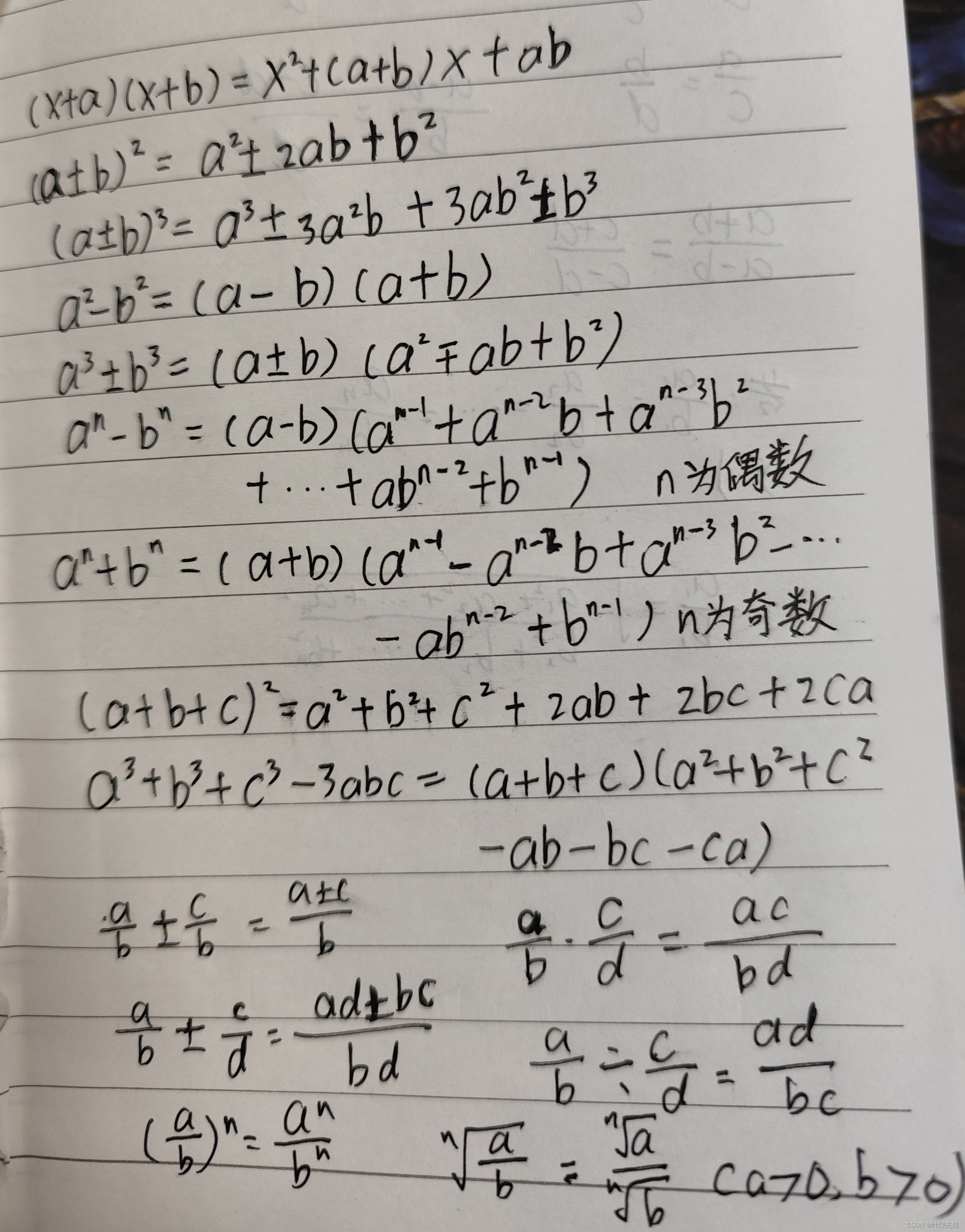ELK
Filebeat
Filebeat 是 ELK 组件的新成员, 也是 Beat 成员之一。基于 Go 语言开发, 无任何依赖, 并且比 Logstash 更加轻量, 不会带来过高的资源占用, 非常适合安装在生产机器上。轻量意 味着简单,Filebeat 并没有集成和 Logstash 一样的正则处理功能, 而是将收集的日志原样输 出。
以下是 Filebeat 的工作流程:当开启 Filebeat 程序的时候,它会启动一个或多个检测进程 (prospectors) 找到指定的日志目录或文件。对于探测器找出的每一个日志文件,Filebeat 启 动读取进程(harvester)。每读取一个日志文件的新内容,便发送这些新的日志数据到处理程 序(spooler)。最后,Filebeat 会发送数据到指定的地点(比如 logstash、elasticserach)。
正是以上原因, 目前, Filebeat 已经完全替代了 Logstash 成为新一代的日志采集器。同 时,鉴于它的轻量、安全等特点,越来越多人开始使用它。
Kafka
Kafka:Kafka是Apache旗下的一款分布式流媒体平台,Kafka是一种高吞吐量、持久性、分布式的发布订阅的消息队列系统。 它最初由LinkedIn(领英)公司发布,使用Scala语言编写,与2010年12月份开源,成为Apache的顶级子项目。 它主要用于处理消费者规模网站中的所有动作流数据。动作指(网页浏览、搜索和其它用户行动所产生的数据)。
Kafka的增长是爆炸性的。财富500强企业中超过三分之一使用卡夫卡。这些公司包括十大旅游公司,十大银行中的七家,十大保险公司中的八家,十大电信公司中的九家,等等。LinkedIn,微软(Microsoft)和Netflix每天用Kafka处理一兆(1,000,000,000,000)的信息。Kafka用于实时数据流,收集大数据,或做实时分析(或两者兼而有之)。Kafka与内存中的微服务一起使用以提供耐用性,并且可以用于向CEP(复杂事件流式传输系统)和IoT / IFTTT式自动化系统提供事件
作用:Kafka通常用于实时流式数据体系结构以提供实时分析。由于Kafka是一个快速,可扩展,耐用和容错的发布、订阅消息传递系统,Kafka被用于JMS,RabbitMQ和AMQP可能因为数量和响应速度而不被考虑的情况。Kafka具有更高的吞吐量,可靠性和复制特性,使其适用于跟踪服务呼叫(跟踪每个呼叫)或跟踪传统MOM可能不被考虑的物联网传感器数据
特点:
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作;
可扩展性:kafka集群支持热扩展;
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败);
高并发:支持数千个客户端同时读写;
支持实时在线处理和离线处理:可以使用Storm这种实时流处理系统对消息进行实时进行处理,同时还可以使用Hadoop这种批处理系统进行离线处理;
作用:
可靠传递:Kafka采用分布式的、持久性的消息日志,确保一旦消息被接收,它就会被保存,即使消费者当前不可用。
防止数据丢失:Kafka的持久性和日志复制机制确保即使在某个Kafka节点失败时,数据仍然可用。每个消息都会被复制到多个节点上,以确保可靠性。
解耦:使用Kafka可以实现生产者和消费者之间的解耦。生产者只关心将消息发送到Kafka,而不需要知道消息会被哪些消费者处理。
水平扩展:Kafka支持水平扩展,可以通过增加更多的节点来处理更多的消息流量。这种能力对于处理大规模日志数据非常重要。
Logstash
数据收集:Logstash支持从各种来源收集数据,包括日志文件、消息队列、网络流量等。
数据处理和转换:Logstash提供强大的过滤和转换功能,可以对收集到的数据进行处理。
插件生态系统:Logstash具有丰富的插件生态系统,包括输入插件、过滤器插件和输出插件,使其可以与各种系统和服务集成。
支持多种输出:支持将处理后的数据发送到各种目标,包括Elasticsearch、Kafka、Amazon S3、Relational Databases等。
可扩展性:Logstash是可扩展的,可以通过增加多个Logstash实例来处理大规模的数据流。
日志和监控:Logstash本身产生的日志和监控信息可以帮助用户追踪和调试数据收集和处理过程。
Elasticserach
分布式架构:Elasticsearch采用分布式架构,可以在多个节点上水平扩展。每个节点都存储数据的一部分,并能够响应用户的搜索和分析请求。
实时搜索:Elasticsearch提供实时搜索能力,用户可以立即看到索引中的新添加或修改的文档。
多种数据类型支持:Elasticsearch不仅支持全文搜索,还支持结构化数据和地理位置数据等多种数据类型的索引和查询。
强大的查询语言:Elasticsearch使用JSON格式的查询语言,用户可以使用丰富的查询语法进行高级搜索。
聚合和分析:Elasticsearch支持聚合框架,用户可以对数据进行聚合和分析,生成各种统计信息和可视化。
与Kibana的集成:Elasticsearch通常与Kibana(一个开源的数据可视化工具)一起使用,形成ELK技术栈。
Kibana
数据可视化:Kibana允许用户创建各种数据可视化,包括折线图、柱状图、饼图、地图等。这些可视化可以直观地展示存储在Elasticsearch中的数据。
实时数据监控:Kibana提供实时的数据监控功能,用户可以实时监控数据的变化和趋势。这对于监控系统、日志分析等实时应用场景非常有用。
搜索和过滤:Kibana允许用户使用强大的搜索和过滤功能,以准确定位感兴趣的数据。
仪表板和报告:用户可以创建仪表板,将不同的可视化组合在一起,形成一个完整的监控和分析视图。
插件生态系统:Kibana具有丰富的插件生态系统,用户可以根据需要安装和使用各种插件,以扩展Kibana的功能。
安全性和权限控制:Kibana提供用户认证和授权机制,允许管理员配置不同用户的权限,以确保对敏感数据的访问受到控制。
FKLEK环境部署
1.资源列表
| 操作系统 | 主机名 | 配置 | IP |
| CentOS7.3.1611 | bogon | 4C8G | 192.168.207.131 |
2.基础环境
1.关闭防火墙
| systemctl stop firewalld systemctl disable firewalld |
2.关闭selinux
| setenforce 0 sed -i "s/.*SELINUX=.*/SELINUX=disabled/g" /etc/selinux/config |
3.安装Docker
#上传软件包,解压安装 docker-ce-24.0.7.rpm.tar.gz
tar zxf docker-ce-24.0.7.rpm.tar.gz
cd docker-ce-24.0.7.rpm
yum -y localinstall *
systemctl start docker4.准备docker compose
#上传软件 docker-ce-24.0.7.rpm FKLEK.tar.gz
chmod +x docker-compose
mv docker-compose /usr/bin/
docker-compose -v5.设置
# 设置es所需配置
cat > /etc/security/limits.d/es.conf << EOF
* soft nproc 655360
* hard nproc 655360
* soft nofile 655360
* hard nofile 655360
EOFcat >> /etc/sysctl.conf << EOF
vm.max_map_count=655360
EOF
sysctl -p
6. 准备测试容器nginx,用来做采集实验
# 准备测试容器nginx所需目录
mkdir /var/log/nginx
chmod -R 777 /var/log/nginx

1. 配置EKLEK
2. 修改kafka的Docker镜像源文件(因为centos停止维护了
vi FKLEK/kafka/Dockercurl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo && \3.启动
#先导成镜像文件docker load < nginx.tar
docker load < centos_7_6_1810.tar
#后台启动
docker-compose up -d
#查看启动状态
docker-compose ps 
7.访问验证
1. 访问nginx触发日志记录
2.访问Kibana查看日志