文章目录
- 前言
- 1、概述
- 1.1、简介
- 1.2、工作原理
- 1.2.1、内核空间与用户空间的信息传递
- 1.2.2、Double-Fetch漏洞产生的原因
- 1.2.3、产生Double-Fetch漏洞的情况
- 1.2.4、一个Double-Fetch漏洞示例
- 1.2.5、Double-Fetch漏洞检测工具原理
- 1.3、模式匹配原理分析
- 1.3.1、Coccinelle介绍
- 1.3.2、Coccinelle模式匹配的应用
- 1.3.2.1、Base double-fetch pattern matching
- 1.3.2.2、No pointer change
- 1.3.2.3、Pointer aliasing
- 1.3.2.4、Explicit type conversion
- 1.3.2.5、Combination of element fetch and pointer fetch
- 1.3.2.6、Loop involvement
- 2、安装与使用
- 2.1、源码安装
- 2.1.1、部署系统依赖组件
- 2.1.1.1、下载安装Gcc 11.3.0
- 2.1.1.2、下载安装Coccinelle 1.1.1
- 2.1.2、使用源码安装系统
- 2.2、使用方法
- 2.2.1、文本过滤工具的使用
- 2.2.2、模式匹配工具的使用
- 2.2.3、漏洞修补工具的使用
- 3、测试用例
- 3.1、Linux 2.6.9内核代码测试
- 3.2、Linux 4.6.2内核代码测试
- 3.3、Linux 5.6.2内核代码测试
- 4、总结
- 4.1、部署架构
- 4.2、漏洞检测对象
- 4.3、漏洞检测方法
- 4.4、种子生成/变异技术
- 5、参考文献
- 总结
前言
本博客的主要内容为Double-Fetch漏洞检测工具的部署、使用与原理分析。本博文内容较长,因为涵盖了Double-Fetch漏洞检测工具的几乎全部内容,从部署的详细过程到如何使用Double-Fetch漏洞检测工具对Linux各个版本的内核中的Double-Fetch漏洞进行检测,以及对Double-Fetch漏洞检测工具进行漏洞检测的原理分析,相信认真读完本博文,各位读者一定会对Double-Fetch漏洞检测工具有更深的了解。以下就是本篇博客的全部内容了。
1、概述
1.1、简介
Double-Fetch检测工具是由国防科技大学王鹏飞等人基于他们对Linux内核中的Double-Fetch进行静态分析的结果,这是第一种静态方法,该方法系统地检测Linux内核中潜在的Double-Fetch漏洞。使用基于模式的分析,作者在Linux内核中确定了90次双取。其中57个发生在驱动程序中,以前的动态方法在没有访问相应硬件的情况下无法检测到这些驱动程序。作者手动调查了90次发生的情况,并推断出发生双重提取的三种典型情况,并详细讨论了每一个问题。此外还进一步开发了一种基于Coccinelle匹配引擎的静态分析,用于检测可能导致内核漏洞的Double-Fetch情况。当应用于Linux、FreeBSD和Android内核时,此方法发现了六个以前未知的Double-Fetch错误,其中四个在驱动程序中,其中三个是可利用的Double-Fetch漏洞。所有已识别的错误和漏洞都已得到维护人员的确认和修补。作者提出的方法已经被Coccinelle团队采用,目前正在集成到Linux内核补丁审查中。基于此研究,作者还为预测Double-Fetch错误和漏洞提供了实用的解决方案。最后,作者提供了一种自动修补检测到的Double-Fetch错误的解决方案。此方法基于模式的静态分析,对Double-Fetch漏洞可能产生的三种典型情况进行了分类,在这三种情况下容易双取,并针对这几种容易发生双取的情况提出了推荐的解决方案,以防止Double-Fetch错误和漏洞[1]。
作者已经将Double-Fetch检测工具的源代码开源到GitHub了[3],此工具共包括三个小工具,这三个小工具基于不同的原理,并完成不同的任务。此外,Double-Fetch工具基于C语言和Python语言开发:
- text-filter:文本过滤方法double-fetch检测工具
- cocci:基于coccinelle引擎的模式匹配方法double-fetch检测工具
- auto_fix:基于coccinelle引擎的double-fetch漏洞修补工具
其中,text-filter工具根据最基本的模式匹配去匹配多次重复使用同一“传输”函数,如果匹配成功,那么此代码文件就是一个候选文件,这就是Double-Fetch检测工具进行漏洞检测的第一阶段。当获取到候选文件后,对这些候选文进行更精细的模式匹配,添加六种更精细的规则,以消除误报、假阴性和假阳性,这部分工作由cocci工具完成,这就是Double-Fetch检测工具进行漏洞检测的第二阶段。最后,如果检测到Double-Fetch漏洞,可由auto_fix工具对出现漏洞的源代码文件中的代码进行修补[2]。
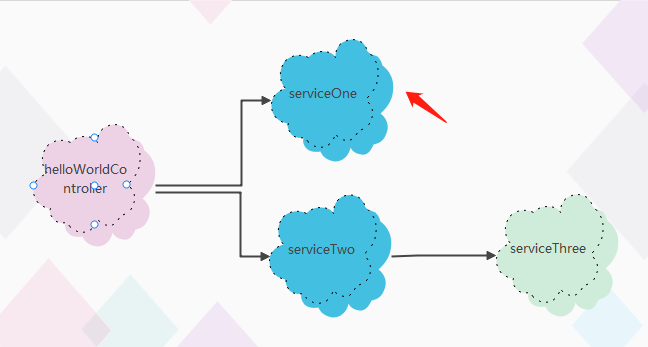
以上就是对Double-Fetch漏洞检测工具的简介以及使用此工具进行漏洞检测的全部流程。对于使用此工具在检测时的具体工作流程细节,请参阅图1.1:

1.2、工作原理
1.2.1、内核空间与用户空间的信息传递
在现代计算机系统中,内存分为内核空间和用户空间。内核空间是内核代码执行和内部数据存储的地方,而用户空间是正常用户进程运行的地方。每个用户空间进程都驻留在自己的地址空间中,并且只能对该空间中的内存进行寻址。内核将这些虚拟地址空间映射到物理内存上,以保证独立空间之间的隔离。内核也有自己独立的地址空间。那么问题来了,内核空间和用户空间如何进行信息传递呢?
操作系统提供了特殊的方案来在内核和用户空间之间交换数据[5]:
- 在Windows中,可以使用设备输入和输出控制(IOCTL)方法,或共享内存对象方法在内核和用户空间之间交换数据,这与共享内存区域非常相似。
- 在Linux和FreeBSD中,提供了在内核空间和用户空间之间安全传输数据的函数,称之为传输函数。例如,Linux有四个常用的传输函数,即
copy_from_user()、copy_to_user()、get_user()和put_user(),它们以安全的方式在用户空间之间复制单个值或任意数量的数据。
1.2.2、Double-Fetch漏洞产生的原因
我们重点关注Linux内核中的传输函数的传输过程,根据定义,当同一用户数据在短时间内被提取两次时,内核中可能会发生双重提取,这个过程如图1.2所示。用户态首先准备好用户态数据(prepare data),然后执行syscall进入内核态后,会对用户态数据进行第一次fetch(使用上面提到的数据传递函数),这一次fetch主要是做一些检测工作(如缓冲区大小、指针是否可用等),在检查通过后会执行第二次fetch对数据进行实际操作。而在这期间是存在一定的时间差,如果我们在用户态数据通过第一次check以后创建一个恶意进程利用二次fetch之间的时间差修改掉原先用户态的数据,那么在内核执行第二次fetch时处理的就并非原先通过检测的数据,而是我们精心准备的恶意数据,而此类漏洞往往会引起访问越界,缓冲区溢出最终造成恶意提权的情况[4]。

所以说,其实双取就是在内核和用户空间之间的内存访问中发生的竞争条件的一种特殊情况。从技术上讲,双取发生在内核函数(如系统调用)中,该函数由用户应用程序从用户模式调用。据此可以得出一个基本模式:该模式与内核函数使用传递函数从同一用户内存区域提取数据至少两次的情况相匹配。在Linux内核的情况下,要匹配的传递函数主要是copy_from_user()和get_user()的所有变体。不过目前我们只讨论这两个函数,因为其它数据传递函数并不会引起Double-Fetch漏洞。
copy_from_user()函数
unsigned long copy_from_user(void *to, const void __user *from, unsigned long n)
{// 休眠might_sleep();// 检查要复制的空间大小是否超过了用户进程空间的大小if (access_ok(VERIFY_READ, from, n))// 进行数据传递的核心汇编代码n = __copy_from_user(to, from, n);else// 若验证失败将内核对应地址的值赋值为0,长度为nmemset(to, 0, n);return n;
}
此函数的目的是从用户空间拷贝数据到内核空间,可以一次性从用户空间获取一个数据块,失败返回没有被拷贝的字节数,成功返回0[6]。此函数的参数含义为:
- *to:将数据拷贝到内核的地址
- *from:需要拷贝数据的地址
- n:拷贝数据的长度(字节)
所以说此函数的具体作用就是将form地址中的数据拷贝到to地址中去,拷贝长度是n。可以看到,copy_from_user()函数并没有对传输的数据进行合法性的检查,只是简单的对源数据的空间大小是否超过了用户进程空间的大小进行了检查,所以当使用此函数进行从用户空间到内核空间的多次数据传递的时候,由于没有对每次获取的用户空间的数据进行合法性的检查,所以有可能产生Double-Fetch漏洞。
get_user()函数
#define get_user(x, ptr)
({// 获取用户空间的指针const void *__p = (ptr);// 休眠might_fault();/*** 使用三目运算符进行判断与赋值,与`copy_from_user()`函数基本一样,都是先对源数据的空间大小是否超过了用户进程空间的大小进行检查。如果合法,就调用__get_user汇编代码进行数据传递,并返回0;反之返回-EFAULT*/access_ok(VERIFY_READ, __p, sizeof(*ptr)) ? __get_user((x), (__typeof__(*(ptr)) *)__p) : ((x) = (__typeof__(*(ptr)))0,-EFAULT);
})
此函数的目的是从用户空间获取单个数据,比如char型、short型或者int型的数据,此外,get_user()要比copy_from_user()的速度更快[7]。此函数的参数含义为:
- x:内核空间待存放数据地址的指针
- ptr:用户空间数据待传输地址的指针
如果数据传输成功,返回0,否则返回-EFAULT。此函数的具体功能与copy_from_user()类似,所以当使用此函数进行从用户空间到内核空间的多次数据传递的时候,由于没有对每次获取的用户空间的数据进行合法性的检查,所以也有可能产生Double-Fetch漏洞。
1.2.3、产生Double-Fetch漏洞的情况
大多数情况下,通过调用一个传递函数就可以直接将数据从用户空间复制到内核空间。然而,当数据具有可变类型或可变长度时,情况会变得复杂。此类数据通常以标头开头,后跟数据的正文。驱动程序经常使用这种可变数据从用户空间向硬件传递消息。如图1.3所示:

作者通过模式匹配上面提到的传递函数,如果在同一个代码段中,多次调用同一个数据传递函数时,就可以认为这是一个可能会产生Double-Fetch漏洞的候选文件,为了对可能产生Double-Fetch漏洞的情况进行细分,作者手动检查双取候选文件,最后注意到有三种常见的情况容易发生双取,将其分类为类型选择、大小检查和浅拷贝[1]。
- 类型选择
当消息头用于类型选择时,会发生双重获取的常见情况。换言之,首先提取消息的标头以识别消息类型,然后根据识别的类型提取和处理整个消息。在Linux内核中,一个驱动程序中的一个函数被设计为通过使用switch语句结构来处理多种类型的消息,这是非常常见的,在switch语句结构中,每个特定的消息类型都被提取,然后被处理。第一次提取的结果(消息类型)用于switch语句的条件,在switch的每种情况下,消息都会通过第二次提取复制到特定类型的本地缓冲区(然后进行处理)。

- 大小检查
当消息的实际长度可能发生变化时,会出现另一种常见情况。在这种情况下,消息头用于标识完整消息的大小。首先将消息头复制到内核以获得消息大小(第一次提取),检查其有效性,并分配必要大小的本地缓冲区,然后进行第二次提取,将整个消息(也包括头)复制到分配的缓冲区中。只要只使用第一次提取的大小,而不是从第二次提取的标头中检索,在这种情况下的双重提取就不会导致double-fetch漏洞或错误。然而,如果从第二次获取的标头中检索并使用大小,内核就会变得容易受到攻击,因为恶意用户可能已经更改了标头的大小元素。

- 浅拷贝
当用户空间中的缓冲区(第一个缓冲区)被复制到内核空间,并且缓冲区包含指向用户空间中另一个缓冲区(第二个缓冲区时)的指针时,就会发生用户和内核空间之间的浅拷贝。传递函数只复制第一个缓冲区(浅拷贝),第二个缓冲区必须通过传递函数的第二次调用来复制(以执行深度拷贝)。有时需要将数据从用户空间复制到内核空间,对数据进行操作,然后将数据复制回用户空间。这样的数据通常包含在用户空间中的第二缓冲区中,并由包含附加数据的用户空间中第一缓冲区中的指针指向。传输函数执行浅拷贝,因此传输函数拷贝的缓冲区中指向的数据也必须显式拷贝,以便执行深度拷贝。这种深度复制将导致对传输函数的多次调用。

1.2.4、一个Double-Fetch漏洞示例
现在我们已经明确,针对Linux内核来说,内核空间想要获取用户空间的数据时,需要调用类似copy_from_user()和get_user()这样的数据传递函数,以获得用户空间的数据,经过上面的分析可以发现,这两个函数并没有进行对于多次从用户空间提取的数据的多次检查,只是简单的对源数据的空间大小是否超过了用户进程空间的大小进行了检查,所以会导致Double-Fetch漏洞。所以说,对于如何检测Linux内核中的Double-Fetch漏洞,应该从匹配上面提到的数据传递函数入手,为了更好的理解Double-Fetch漏洞,下面做简单介绍。
下图显示了Linux 2.6.9中的一个Double-Fetch错误[8],报告为CVE-2005-2490。在compat.c文件中,当用户空间的内容通过sendmsg()复制到内核时,相同的用户数据会被访问两次,而第二次不会进行健全性检查。这可能会导致内核缓冲区溢出,因此可能导致权限提升。函数cmsghdr_from_user_compat_to_kern()分两步工作:它首先检查第一个循环中的参数(第151行),然后复制第二个循环中(第184行)的数据。然而,只有ucmlen的第一次提取(第152行)在使用前被检查(第156–161行),而在第二次提取后(第185行),在使用前没有检查,这可能会导致复制操作(第195行)中的溢出,可以利用该溢出通过修改消息来执行任意代码。

1.2.5、Double-Fetch漏洞检测工具原理
现在我们对Double-Fetch漏洞产生的原因以及易产生Double-Fetch漏洞的情况有了清晰的认识,那么下一步就是对此种类型的漏洞进行检测,我们介绍的工具是Double-Fetch漏洞检测工具,此工具的具体工作流程上面已经介绍过了,在这部分我们从细节着眼,详细的看一看Double-Fetch漏洞检测工具究竟在每一个阶段做了什么,以及这背后的原理究竟是什么。此工具的工作过程主要分为两个阶段[1]。
在第一阶段,主要是完成对get_user ()以及copy_from_user ()函数的模式匹配,因为这两个函数如果在一个函数内被多次调用,并且取得的数据的地址为同一地址,就有可能产生Double-Fetch漏洞,下面展示的函数就是Double-Fetch漏洞检测工具源代码中对以上两个函数进行模式匹配的具体代码[3]。
def is_same(self, in_str1, in_str2):str1 = in_str1.replace(" ", "")str2 = in_str2.replace(" ", "")# 匹配` get_user ()`数据传递函数if str1.find('get_user') != -1 and str2.find('get_user') != -1:loc1s = str1.find(',') loc2s = str2.find(',') if loc1s == -1 or loc2s == -1 :return False loc1e = self.get_end_loc(str1, loc1s)loc2e = self.get_end_loc(str2, loc2s)if loc1e == -1 or loc2e == -1 :return Falseif(str1[loc1s:loc1e] == str2[loc2s:loc2e]):if str1[loc1s:loc1e].find('++') != -1:return Falseelse:return Trueelse:return False# 匹配` copy_from_user ()`数据传递函数 elif str1.find('copy_from_user') != -1 and str2.find('copy_from_user') != -1:loc1s = str1.find(',')loc2s = str2.find(',')if loc1s == -1 or loc2s == -1 :return Falseloc1s = loc1s + 1loc2s = loc2s + 1loc1e = str1.find(',',loc1s) loc2e = str2.find(',',loc2s) if loc1e == -1 or loc2e == -1 :return Falseif(str1[loc1s:loc1e] == str2[loc2s:loc2e]):if str1[loc1s:loc1e].find('++') != -1:return Falseelse:return Trueelse:return False……
当某一源代码文件中的函数中的具体代码被成功匹配,就说明这可能会产生Double-Fetch漏洞,但是此时我们还不能确定,需要更精细的分析以去除误报、假阴性和假阳性,不过这是第二阶段需要做的任务。此时,第一阶段的任务就已经完成了,获取到候选文件后,作者对可能发生Double-Fetch漏洞的情况的分类,并对其进行手动分析,最终确定类型选择、大小检查和浅拷贝这三种情况容易发生漏洞,分类是为了第二阶段更为精细的Double-Fetch漏洞检测。
第二阶段使用了一种改进的Double-Fetch错误检测方法,该方法基于Coccinelle匹配引擎。研究的第一阶段是为了识别和分类发生双重提取的场景,所以第二阶段利用从第一阶段获得的知识来设计改进的分析,旨在去除误报、假阴性和假阳性以专门识别Double-Fetch错误和漏洞。为了进行精细的Double-Fetch漏洞检测,作者提出了以下六个规则[1]:
- Basic double-fetch pattern matching
此项为最基本的模式匹配(正如图1.8中的规则0所示),目的就是匹配get_user ()与copy_from_user ()函数以获得候选文件。 - No pointer change
检测Double-Fetch漏洞的最关键规则是在两次获取之间保持用户指针不变。否则,每次都会提取不同的数据,而不是重复提取相同的数据,这可能会导致误报。从图1.8中的规则1可以看出,这种变化可能包括自增量(++)、添加偏移或分配另一个值的情况,以及相应的减法情况。 - Pointer aliasing
指针别名在Double-Fetch情况下很常见。在某些情况下,用户指针被分配给另一个指针,因为原始指针可能会被更改(例如,在循环中逐段处理长消息),而使用两个指针更方便,一个用于检查数据,另一个用于使用数据。从图1.8中的规则2可以看出,这种赋值可能出现在函数的开头或两个fetch之间。缺少混叠情况可能会导致假阴性。 - Explicit type conversion
当内核从用户空间获取数据时,显式指针类型转换被广泛使用。例如,在大小检查场景中,消息指针将被转换为标头指针,以在第一次获取中获取标头,然后在第二次获取中再次用作消息指针。从图1.8中的规则3可以看出,两个源指针中的任何一个都可能涉及类型转换。缺少类型转换的情况可能会导致假阴性。此外,显式指针类型转换通常与指针别名相结合,导致同一内存区域由两种类型的指针操作。 - Combination of element fetch and pointer fetch
在某些情况下,用户指针既用于获取整个数据结构,也用于通过将指针解引用到数据结构的元素来仅获取一部分。例如,在大小检查场景中,用户指针首先用于通过get_user(len,ptr->len)获取消息长度,然后通过copy_from_user(msg,ptr,len)在第二次获取中复制整个消息,这意味着两次获取使用的指针与传递函数参数不完全相同,但它们在语义上涵盖了相同的值。正如我们从图1.8中的规则4中看到的那样,这种情况可能使用用户指针或数据结构的地址作为传递函数的参数。这种情况通常在显式指针类型转换时出现,如果错过这种情况,可能会导致假阴性。 - Loop involvement
由于Coccinelle对路径敏感,当代码中出现循环时,循环中的一个传递函数调用将被报告为两个调用,这可能会导致误报。此外,从图1.8中的规则5可以看出,当一个循环中有两次提取时,上一次迭代的第二次提取和下一次迭代中的第一次提取将作为双提取进行匹配。这种情况应该作为假阳性删除,因为在遍历迭代时应该更改用户指针,并且这两次获取的值不同。此外,使用数组在循环中复制不同值的情况也会导致误报。
基于以上六个规则,Double-Fetch漏洞检测工具可以对在第一阶段获取到的候选文件进行更细粒度的过滤,最终得到的就是确定存在真正的Double-Fetch漏洞的代码以及源代码文件。整个第二阶段的检测过程如下图所示:

第二阶段最终会获取到发生Double-Fetch漏洞的代码以及源代码文件,其实Double-Fetch漏洞检测工具还有第三个小工具,可以对产生此漏洞的代码进行修复,不过我经过验证发现,第三个小工具的效果非常差,或者说根本没有效果,所以在此不再赘述。
1.3、模式匹配原理分析
1.3.1、Coccinelle介绍
Coccinelle(法语中的“瓢虫”)是一个用于进行源代码分析和转换的程序分析工具。它主要用于检测和修复在软件代码中的缺陷、重构代码以及执行其他源代码转换操作。以下是关于Coccinelle的一些主要特点和用途:
- 匹配和转换规则定义:Coccinelle使用一种称为“Semantic Patch Language”(SPatch)的领域特定语言,允许用户定义匹配源代码中特定模式的规则,并指定如何进行转换。这使得开发人员能够根据他们的需求创建自定义的代码分析和转换工具
- 代码缺陷检测和修复:Coccinelle可以用于检测源代码中的常见错误、漏洞或不良实践,并提供一种方式来自动化修复这些问题。这对于大型代码库的维护和改进代码质量非常有用
- 代码重构:工程师可以使用Coccinelle定义规则,以识别和重构代码中的特定模式。这有助于改进代码的可读性、可维护性和性能
- 跨版本代码变更:Coccinelle能够处理代码库的版本变化,允许开发人员定义规则,以在不同版本的代码中进行匹配和转换
- 跨语言支持:虽然Coccinelle最初是为C语言设计的,但它的规则也可以用于其他编程语言,例如C++、Java等
- 开源和活跃社区:Coccinelle是一个开源项目,其代码和规则库都是公开可用的。它有一个活跃的社区,不断更新和改进工具,同时提供文档和支持
在Double-Fetch漏洞检测过程中,Coccinelle被用于定义一组规则,以匹配和分析特定的代码模式。这些规则涉及到在C语言代码中使用的用户空间内存访问函数(如get_user()、copy_from_user()等),并且通过定义规则,可以检测到一些潜在的代码问题。下面我们就会逐一介绍Coccinelle模式匹配在Double-Fetch漏洞检测中的具体应用。
此外,由于我们目前检测的都是Linux中的Double-Fetch漏洞,所以我们下面分析的就是Double-Fetch漏洞检测工具源代码中的“/cocci/pattern_match_linux.cocci”文件,在此文件中就定义了有关Double-Fetch漏洞待匹配的模式。
1.3.2、Coccinelle模式匹配的应用
1.3.2.1、Base double-fetch pattern matching
这种匹配模式又可被称为:“没有src赋值的正常情况”。故此项为最基本的模式匹配,目的就是匹配get_user()与copy_from_user()等函数以获得可能存在Double-Fetch漏洞的候选函数。此种匹配规则较为简单,就是通过匹配目标函数是否出现了两次,然后再进行数据源地址的筛选后得到候选函数。下面就是这种匹配模式的具体实现函数:
//----------------------------------- case 1: normal case without src assignment
@ rule1 disable drop_cast exists @
expression addr,exp1,exp2,src,size1,size2,offset;
position p1,p2;
identifier func;
type T1,T2;
@@ func(...){ ...
( get_user(exp1, (T1)src)@p1
| get_user(exp1, src)@p1
| __get_user(exp1, (T1)src)@p1
| __get_user(exp1, src)@p1
| copy_from_user(exp1, (T1)src, size1)@p1
| copy_from_user(exp1, src, size1)@p1
| __copy_from_user(exp1, (T1)src, size1)@p1
| __copy_from_user(exp1, src, size1)@p1 ) ... when any when != src += offset when != src = src + offset when != src++ when != src -=offset when != src = src - offset when != src-- when != src = addr ( get_user(exp2, (T2)src)@p2
| get_user(exp2, src)@p2
| __get_user(exp2,(T2)src)@p2
| __get_user(exp2, src)@p2
| __copy_from_user(exp2,(T2)src,size2)@p2
| __copy_from_user(exp2, src,size2)@p2
| copy_from_user(exp2,(T2)src,size2)@p2
| copy_from_user(exp2, src,size2)@p2
) ... } @script:python@
p11 << rule1.p1;
p12 << rule1.p2;
s1 << rule1.src;
@@ print "src1:", str(s1)
if p11 and p12: coccilib.report.print_report(p11[0],"rule1 First fetch") coccilib.report.print_report(p12[0],"rule1 Second fetch") post_match_process(p11, p12, s1, s1)
在此部分代码中,首先通过在某一个主函数中匹配get_user()与copy_from_user()等子函数来获取首次得到的候选子函数,这表明是第一次出现。然后对其进行筛选,对于满足条件的函数再进行第二次匹配,当第二次匹配到与第一次同名的候选子函数,且经过筛选发现数据源地址并没有发生变化,这就表明此函数是为了获取了同一个地址的数据而第二次出现。这样我们就认为匹配到的候选函数中存在Double-Fetch漏洞,这也是最简单的匹配方式。下面我们将对上面的模式匹配代码进行详细分析:
- 第1行:注释,表示这是名为“没有src赋值的正常情况”的匹配模式
- 第2行:
rule1表示规则名称。disable drop_cast表示在匹配时不忽略任何类型转换,即规则将考虑代码中的所有类型转换。而exists关键字则表示规则只匹配包含drop_cast的代码块。这样规则将在包含drop_cast的情况下考虑所有类型转换 - 第3行:
expression是用来声明变量的一种方式,它表示变量的类型为表达式。在上面的代码中,addr,exp1,exp2,src,size1,size2,和offset都被声明为expression类型的变量。这些变量的作用如下(通过这样的声明,我们就可以在规则的匹配模式和处理脚本中使用这些变量,并对它们进行相应的操作):addr:用于表示地址的表达式exp1和exp2:分别表示两个表达式src:表示源地址或源数据的表达式size1和size2:表示大小的表达式offset:表示偏移量的表达式
- 第4行:
position是Coccinelle中用来表示代码位置的关键字。在规则的匹配中,position可以用来捕获匹配到的代码的位置信息,例如行号、文件名等。在这个脚本中,p1和p2是两个position类型的变量,用来捕获匹配到的两个位置。这些位置信息可以在后续的处理中使用,例如打印或记录这些位置信息 - 第5行:这行代码定义了一个名为“func”的标识符,用于在匹配规则中捕获函数名。在Coccinelle中,我们可以使用标识符来捕获匹配到的代码中的某些元素,以便在后续的处理中引用它们
- 第6行:这行代码定义了两个类型标识符,用于匹配不同的类型。在规则中,
T1和T2可以分别代表两次获取的数据的类型。这样,规则可以灵活地适用于不同类型的获取操作。例如,如果第一次获取的数据类型是int,那么T1可以表示为int。如果第二次获取的数据类型是char,那么T2可以表示为char。这样的灵活性使得规则可以适用于多种类型的情况,而不仅仅局限于特定的数据类型 - 第7行:
@@是Coccinelle中的一个关键字,表示规则的主体。在Coccinelle中,规则通常分为两部分:匹配部分和脚本部分。此处的@@用于引导匹配规则的开始,其下面的代码中包含了要匹配的代码模式 - 第8行:这行代码是模式匹配的一部分,用于指定匹配的函数形式。在Coccinelle中,我们可以使用
func(...)这样的形式来表示匹配任意形式的函数,其中...表示函数的参数列表,这可以是任意数量和类型的参数。此外,还使用{表示针对此主函数的模式匹配的开始 - 第9行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第10行~第27行:这部分代码使用
((第10行)和)(第27行)定义了一个匹配块,包含了多个匹配项,每个匹配项对应一种情况。在这部分代码中,使用逻辑或(OR)操作符,即|(第12行、第14行、第16行、第18行、第20行、第22行和第24行)来分隔不同的匹配项。意味着如果其中一个匹配项成功,整个匹配块就被视为成功。这允许在同一个位置匹配多种情况,根据实际的代码结构进行灵活的匹配。下面我们来分析本段代码中的各个匹配项:- 第11行的
get_user(exp1, (T1)src)@p1:表示匹配代码中类似get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)src则是对获取的数据进行类型转换,其中T1是目标类型,src是用户空间的数据源,此外,@p1表示在匹配时记录匹配位置信息,通过将匹配的位置信息保存到p1变量中,以便后续使用 - 第13行的
get_user(exp1, src)@p1:表示匹配代码中类似get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而src是用户空间的数据源,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第15行的
__get_user(exp1, (T1)src)@p1:表示匹配代码中类似__get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)src是用户空间的数据源,并且进行了类型转换,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第17行的
__get_user(exp1, src)@p1:表示匹配代码中类似__get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而src是用户空间的数据源,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第19行的
copy_from_user(exp1, (T1)src, size1)@p1:表示匹配代码中类似copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)src表示用户空间的数据源,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第21行的
copy_from_user(exp1, src, size1)@p1:表示匹配代码中类似copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,而src表示用户空间的数据源,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第23行的
__copy_from_user(exp1, (T1)src, size1)@p1:表示匹配代码中类似__copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)src表示用户空间的数据源,(T1)是类型转换,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第25行的
__copy_from_user(exp1, src, size1)@p1:表示匹配代码中类似__copy_from_user的函数,其中exp1是用于接收获取的用户数据的变量,而src表示用户空间的数据源,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用
- 第11行的
- 第28行~第35行:在这部分代码中,首先使用
...(第28行)表示匹配函数体内的任意代码片段,并且使用when any(第28行)来表示如果这些代码片段满足下面七种情况的任意一种,就可以继续向下匹配,否则匹配失败:- 第29行的
when != src += offset:表示src的值在两次获取之间不以+= offset的形式增加 - 第30行的
when != src = src + offset:表示src的值在两次获取之间不以= src + offset的形式重新赋值 - 第31行的
when != src++:表示src的值在两次获取之间不以++自增 - 第32行的
when != src -=offset:表示src的值在两次获取之间不以-= offset的形式减少 - 第33行的
when != src = src - offset:表示src的值在两次获取之间不以= src - offset的形式重新赋值 - 第34行的
when != src--:表示src的值在两次获取之间不以--自减 - 第35行的
when != src = addr:表示src的值在两次获取之间不以= addr的形式重新赋值为addr
- 第29行的
- 第37行~第53行:这部分代码与第10行~第27行的代码是一样的,只是变量名发生了变化。这部分代码同样使用
((第37行)和)(第53行)定义了一个匹配块,在这个匹配块中包含了多个匹配项,每个匹配项对应一种情况,并使用逻辑或(OR)操作符,即|(第39行、第41行、第43行、第45行、第47行、第49行和第51行)来分隔不同的匹配项。意味着如果其中一个匹配项成功,整个匹配块就被视为成功。这允许在同一个位置匹配多种情况,根据实际的代码结构进行灵活的匹配。对于本段代码中的各个匹配项我们在此不再赘述,因为这部分代码的匹配模式与第10行~第27行的代码的匹配模式一致,只不过使用另一套变量来获取信息(例如exp2、T2、src、@p2和size2)。如果经过之前的匹配和筛选后,在这部分代码中又成功匹配上了目标函数,说明我们匹配的当前的主函数中就存在Double-Fetch漏洞,并将发生漏洞的位置以及其对应的各种信息保存在各自的变量中 - 第54行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第55行:
}表示针对此主函数的模式匹配的结束 - 第57行~第60行:这部分是使用Coccinelle的Python脚本语言扩展,用于将匹配的结果存储到变量中。在这里主要存储了目标函数在代码中两次出现的位置(分别被赋值为
p11和p12)和数据源地址(被赋值为s1)。通过这些存储的变量,我们就可以在后续的操作中使用匹配的结果,例如打印匹配的行号或执行其他处理逻辑 - 第61行:
@@是Coccinelle中的一个关键字,表示规则的主体。在Coccinelle中,规则通常分为两部分:匹配部分和脚本部分。此处的@@用于引导匹配规则的结束,其上面的代码中包含了要匹配的代码模式 - 第63行~第67行:这段代码的作用是在匹配成功后,打印相关的匹配信息,并将这些信息传递给
coccilib.report.print_report()函数和post_match_process()函数以进行进一步处理
1.3.2.2、No pointer change
这种匹配模式又可被称为:“一开始ptr等于src,首先处理ptr”。此种模式匹配也是我们筛选Double-Fetch漏洞的第二种方式,并且稍微复杂一些。此种模式匹配检测Double-Fetch漏洞的最关键规则是在两次获取之间保持用户指针不变。否则,每次都会提取不同的数据,而不是重复提取相同的数据,这可能会导致误报。从图1.8中的规则1可以看出,这种变化可能包括自增量(++)、添加偏移或分配另一个值的情况,以及相应的减法情况。下面就是这种匹配模式的具体实现函数:
//--------------------------------------- case 2: ptr = src at beginning, ptr first
@ rule2 disable drop_cast exists @
identifier func;
expression addr,exp1,exp2,src,ptr,size1,size2,offset;
position p0,p1,p2;
type T0,T1,T2;
@@ func(...){ ...
( ptr = (T0)src@p0 // potential assignment case
| ptr = src@p0
) ...
( get_user(exp1, (T1)ptr)@p1
| get_user(exp1, ptr)@p1
| __get_user(exp1, (T1)ptr)@p1
| __get_user(exp1, ptr)@p1
| copy_from_user(exp1, (T1)ptr,size1)@p1
| copy_from_user(exp1, ptr,size1)@p1
| __copy_from_user(exp1, (T1)ptr,size1)@p1
| __copy_from_user(exp1, ptr,size1)@p1
) ... when != src += offset when != src = src + offset when != src++ when != src -=offset when != src = src - offset when != src-- when != src = addr
( get_user(exp2, (T2)src)@p2
| get_user(exp2, src)@p2
| __get_user(exp2,(T2)src)@p2
| __get_user(exp2, src)@p2
| __copy_from_user(exp2,(T2)src,size2)@p2
| __copy_from_user(exp2, src,size2)@p2
| copy_from_user(exp2,(T2)src,size2)@p2
| copy_from_user(exp2, src,size2)@p2
) ... } @script:python@
p21 << rule2.p1;
p22 << rule2.p2;
p2 << rule2.ptr;
s2 << rule2.src;
@@
print "src2:", str(s2)
print "ptr2:", str(p2)
if p21 and p22: coccilib.report.print_report(p21[0],"rule2 First fetch") coccilib.report.print_report(p22[0],"rule2 Second fetch") post_match_process(p21, p22, s2, p2)
在此部分代码中,首先匹配用户指针的赋值情况,然后再通过在某一个主函数中匹配get_user()与copy_from_user()等子函数来获取首次得到的候选子函数,这表明是第一次出现。然后对其进行筛选,对于满足条件的函数再进行第二次匹配,当第二次匹配到与第一次同名的候选子函数,且经过筛选发现数据源地址并没有发生变化,这就表明此函数是为了获取了同一个地址的数据而第二次出现。这样我们就认为匹配到的候选函数中存在Double-Fetch漏洞。下面我们将对上面的模式匹配代码进行详细分析:
- 第1行:注释,表示这是名为“一开始ptr等于src,首先处理ptr”的匹配模式
- 第2行:
rule2表示规则名称。disable drop_cast表示在匹配时不忽略任何类型转换,即规则将考虑代码中的所有类型转换。而exists关键字则表示规则只匹配包含drop_cast的代码块。这样规则将在包含drop_cast的情况下考虑所有类型转换 - 第3行:这行代码定义了一个名为“func”的标识符,用于在匹配规则中捕获函数名。在Coccinelle中,我们可以使用标识符来捕获匹配到的代码中的某些元素,以便在后续的处理中引用它们
- 第4行:
expression是用来声明变量的一种方式,它表示变量的类型为表达式。在上面的代码中,addr,exp1,exp2,src,ptr,size1,size2,和offset都被声明为expression类型的变量。这些变量的作用如下(通过这样的声明,我们就可以在规则的匹配模式和处理脚本中使用这些变量,并对它们进行相应的操作):addr:用于表示地址的表达式exp1和exp2:分别表示两个表达式src:表示源地址或源数据的表达式ptr:表示指向用户空间数据的指针的表达式size1和size2:表示大小的表达式offset:表示偏移量的表达式
- 第5行:
position是Coccinelle中用来表示代码位置的关键字。在规则的匹配中,position可以用来捕获匹配到的代码的位置信息,例如行号、文件名等。在这个脚本中,p0、p1和p2是三个position类型的变量,分别用来表示用户空间指针的地址和捕获匹配到的两个位置。这些地址和位置信息可以在后续的处理中使用,例如打印或记录这些地址和位置信息 - 第6行:这行代码定义了三个类型标识符,用于匹配不同的类型。在规则中,
T0用于表示用户空间指针的数据的类型,T1和T2可以分别代表两次获取的数据的类型。这样,规则可以灵活地适用于不同类型的获取操作。例如,如果第一次获取的数据类型是int,那么T1可以表示为int。如果第二次获取的数据类型是char,那么T2可以表示为char。若用户空间指针的数据的类型是int,那么那么T0可以表示为int。这样的灵活性使得规则可以适用于多种类型的情况,而不仅仅局限于特定的数据类型 - 第7行:
@@是Coccinelle中的一个关键字,表示规则的主体。在Coccinelle中,规则通常分为两部分:匹配部分和脚本部分。此处的@@用于引导匹配规则的开始,其下面的代码中包含了要匹配的代码模式 - 第10行:这行代码是模式匹配的一部分,用于指定匹配的函数形式。在Coccinelle中,我们可以使用
func(...)这样的形式来表示匹配任意形式的函数,其中...表示函数的参数列表,这可以是任意数量和类型的参数。此外,还使用{表示针对此主函数的模式匹配的开始 - 第11行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第12行~第34行:这部分代码使用
((第12行和第18行)和)(第16行和第34行)定义了两个匹配块,每个匹配块包含了多个匹配项,每个匹配项对应一种情况。在这部分代码中,使用逻辑或(OR)操作符,即|(第14行、第20行、第22行、第24行、第26行、第28行、第30行和第32行)来分隔不同的匹配项。意味着如果其中一个匹配项成功,整个匹配块就被视为成功。这允许在同一个位置匹配多种情况,根据实际的代码结构进行灵活的匹配。下面我们来分析本段代码中各个匹配块的各个匹配项:- 第13行的
ptr = (T0)src@p0:这一行代码表示对ptr进行了一个潜在的赋值操作,其中(T0)src表示将src强制类型转换为T0类型。这里涉及到对用户指针的类型转换。p0是这个赋值操作在源代码中的位置信息 - 第15行的
ptr = src@p0:这一行代码表示对ptr进行了一个潜在的赋值操作,其中src为ptr赋予了新的值。p0是这个赋值操作在源代码中的位置信息 - 第17行的
...:在这行代码中,...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第19行的
get_user(exp1, (T1)ptr)@p1:表示匹配代码中类似get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)ptr则是对获取的数据进行类型转换,其中T1是目标类型,ptr是指向用户空间的数据源的指针,此外,@p1表示在匹配时记录匹配位置信息,通过将匹配的位置信息保存到p1变量中,以方便后续使用 - 第21行的
get_user(exp1, ptr)@p1:表示匹配代码中类似get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而ptr是指向用户空间的数据源的指针,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第23行的
__get_user(exp1, (T1)ptr)@p1:表示匹配代码中类似__get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)ptr是指向用户空间的数据源的指针,并且进行了类型转换,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第25行的
__get_user(exp1, ptr)@p1:表示匹配代码中类似__get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而ptr是指向用户空间的数据源的指针,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第27行的
copy_from_user(exp1, (T1)ptr, size1)@p1:表示匹配代码中类似copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)ptr表示指向用户空间的数据源的指针,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第29行的
copy_from_user(exp1, ptr, size1)@p1:表示匹配代码中类似copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,而ptr表示指向用户空间的数据源的指针,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第31行的
__copy_from_user(exp1, (T1)ptr, size1)@p1:表示匹配代码中类似__copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)ptr表示指向用户空间的数据源的指针,(T1)是类型转换,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第33行的
__copy_from_user(exp1, ptr, size1)@p1:表示匹配代码中类似__copy_from_user的函数,其中exp1是用于接收获取的用户数据的变量,而ptr表示指向用户空间的数据源的指针,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用
- 第13行的
- 第35行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第36行~第42行:这部分条件是用于筛选匹配结果的,其中
src是一个指针,这些条件表示如果src在两次获取之间发生了增加或减少,或者与某个地址相等,那就不符合Double-Fetch漏洞的条件。需要注意的是,这些条件之间是逻辑与(AND)的关系,即所有条件都必须同时满足才能匹配成功。这意味着代码块必须满足所有列出的条件才能通过匹配。这些筛选条件的具体含义如下:- 第36行的
when != src += offset:表示src的值在两次获取之间不以+= offset的形式增加 - 第37行的
when != src = src + offset:表示src的值在两次获取之间不以= src + offset的形式重新赋值 - 第38行的
when != src++:表示src的值在两次获取之间不以++自增 - 第39行的
when != src -=offset:表示src的值在两次获取之间不以-= offset的形式减少 - 第40行的
when != src = src - offset:表示src的值在两次获取之间不以= src - offset的形式重新赋值 - 第41行的
when != src--:表示src的值在两次获取之间不以--自减 - 第42行的
when != src = addr:表示src的值在两次获取之间不以= addr的形式重新赋值为addr
- 第36行的
- 第43行第59行:这部分代码与第12行第34行的代码是一样的,只是变量名发生了变化。这部分代码同样使用
((第43行)和)(第59行)定义了一个匹配块,在这个匹配块中包含了多个匹配项,每个匹配项对应一种情况,并使用逻辑或(OR)操作符,即|(第45行、第47行、第49行、第51行、第53行、第55行和第57行)来分隔不同的匹配项。意味着如果其中一个匹配项成功,整个匹配块就被视为成功。这允许在同一个位置匹配多种情况,根据实际的代码结构进行灵活的匹配。对于本段代码中的各个匹配项我们在此不再赘述,因为这部分代码的匹配模式与第12行~第34行的代码的匹配模式一致,只不过使用另一套变量来获取信息(例如exp2、T2、src、@p2和size2)。如果经过之前的匹配和筛选后,在这部分代码中又成功匹配上了目标函数,说明我们匹配的当前的主函数中就存在Double-Fetch漏洞,并将发生漏洞的位置以及其对应的各种信息保存在各自的变量中 - 第60行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第61行:
}表示针对此主函数的模式匹配的结束 - 第63行~第67行:这部分是使用Coccinelle的Python脚本语言扩展,用于将匹配的结果存储到变量中。在这里主要存储了目标函数在代码中两次出现的位置(分别被赋值为
p21和p22)和数据源指针和地址(被赋值为p2和s2)。通过这些存储的变量,我们就可以在后续的操作中使用匹配的结果,例如打印匹配的行号或执行其他处理逻辑 - 第68行:
@@是Coccinelle中的一个关键字,表示规则的主体。在Coccinelle中,规则通常分为两部分:匹配部分和脚本部分。此处的@@用于引导匹配规则的结束,其上面的代码中包含了要匹配的代码模式 - 第69行~第74行:这段代码的作用是在匹配成功后,打印相关的匹配信息,并将这些信息传递给
coccilib.report.print_report()函数和post_match_process()函数以进行进一步处理
1.3.2.3、Pointer aliasing
这种匹配模式又可被称为:“一开始ptr等于src,首先处理src”。此种模式匹配是我们筛选Double-Fetch漏洞的第三种方式,且稍微复杂一些。Pointer aliasing在Double-Fetch情况下很常见。在某些情况下,用户指针被分配给另一个指针,因为原始指针可能会被更改(例如,在循环中逐段处理长消息),而使用两个指针更方便,一个用于检查数据,另一个用于使用数据。从图1.8中的规则2可以看出,这种赋值可能出现在函数的开头或两个fetch之间。缺少混叠情况可能会导致假阴性。下面就是这种匹配模式的具体实现函数:
//--------------------------------------- case 3: ptr = src at beginning, src first
@ rule3 disable drop_cast exists @
identifier func;
expression addr,exp1,exp2,src,ptr,size1,size2,offset;
position p0,p1,p2;
type T0,T1,T2;
@@ func(...){ ...
( ptr = (T0)src@p0 // potential assignment case
| ptr = src@p0
) ...
( get_user(exp1, (T1)src)@p1
| get_user(exp1, src)@p1
| __get_user(exp1, (T1)src)@p1
| __get_user(exp1, src)@p1
| copy_from_user(exp1, (T1)src,size1)@p1
| copy_from_user(exp1, src,size1)@p1
| __copy_from_user(exp1, (T1)src,size1)@p1
| __copy_from_user(exp1, src,size1)@p1
) ... when != ptr += offset when != ptr = ptr + offset when != ptr++ when != ptr -=offset when != ptr = ptr - offset when != ptr-- when != ptr = addr
( get_user(exp2, (T2)ptr)@p2
| get_user(exp2, ptr)@p2
| __get_user(exp2,(T2)ptr)@p2
| __get_user(exp2, ptr)@p2
| __copy_from_user(exp2,(T2)ptr,size2)@p2
| __copy_from_user(exp2, ptr,size2)@p2
| copy_from_user(exp2,(T2)ptr,size2)@p2
| copy_from_user(exp2, ptr,size2)@p2
) ... } @script:python@
p31 << rule3.p1;
p32 << rule3.p2;
p3 << rule3.ptr;
s3 << rule3.src;
@@
print "src3:", str(s3)
print "ptr3:", str(p3)
if p31 and p32: coccilib.report.print_report(p31[0],"rule3 First fetch") coccilib.report.print_report(p32[0],"rule3 Second fetch") post_match_process(p31, p32, s3, p3)
在此部分代码中,首先匹配用户指针的赋值情况,然后再通过在某一个主函数中匹配get_user()与copy_from_user()等子函数来获取首次得到的候选子函数,这表明是第一次出现。然后对其进行筛选,对于满足条件的函数再进行第二次匹配,当第二次匹配到与第一次同名的候选子函数,且经过筛选发现数据源地址并没有发生变化,这就表明此函数是为了获取了同一个地址的数据而第二次出现。这样我们就认为匹配到的候选函数中存在Double-Fetch漏洞。下面我们将对上面的模式匹配代码进行详细分析:
- 第1行:注释,表示这是名为“一开始ptr等于src,首先处理src”的匹配模式
- 第2行:
rule3表示规则名称。disable drop_cast表示在匹配时不忽略任何类型转换,即规则将考虑代码中的所有类型转换。而exists关键字则表示规则只匹配包含drop_cast的代码块。这样规则将在包含drop_cast的情况下考虑所有类型转换 - 第3行:这行代码定义了一个名为“func”的标识符,用于在匹配规则中捕获函数名。在Coccinelle中,我们可以使用标识符来捕获匹配到的代码中的某些元素,以便在后续的处理中引用它们
- 第4行:
expression是用来声明变量的一种方式,它表示变量的类型为表达式。在上面的代码中,addr,exp1,exp2,src,ptr,size1,size2,和offset都被声明为expression类型的变量。这些变量的作用如下(通过这样的声明,我们就可以在规则的匹配模式和处理脚本中使用这些变量,并对它们进行相应的操作):addr:用于表示地址的表达式exp1和exp2:分别表示两个表达式src:表示源地址或源数据的表达式ptr:表示指向用户空间数据的指针的表达式size1和size2:表示大小的表达式offset:表示偏移量的表达式
- 第5行:
position是Coccinelle中用来表示代码位置的关键字。在规则的匹配中,position可以用来捕获匹配到的代码的位置信息,例如行号、文件名等。在这个脚本中,p0、p1和p2是三个position类型的变量,分别用来表示用户空间指针的地址和捕获匹配到的两个位置。这些地址和位置信息可以在后续的处理中使用,例如打印或记录这些地址和位置信息 - 第6行:这行代码定义了三个类型标识符,用于匹配不同的类型。在规则中,
T0用于表示用户空间指针的数据的类型,T1和T2可以分别代表两次获取的数据的类型。这样,规则可以灵活地适用于不同类型的获取操作。例如,如果第一次获取的数据类型是int,那么T1可以表示为int。如果第二次获取的数据类型是char,那么T2可以表示为char。若用户空间指针的数据的类型是int,那么那么T0可以表示为int。这样的灵活性使得规则可以适用于多种类型的情况,而不仅仅局限于特定的数据类型 - 第7行:
@@是Coccinelle中的一个关键字,表示规则的主体。在Coccinelle中,规则通常分为两部分:匹配部分和脚本部分。此处的@@用于引导匹配规则的开始,其下面的代码中包含了要匹配的代码模式 - 第10行:这行代码是模式匹配的一部分,用于指定匹配的函数形式。在Coccinelle中,我们可以使用
func(...)这样的形式来表示匹配任意形式的函数,其中...表示函数的参数列表,这可以是任意数量和类型的参数。此外,还使用{表示针对此主函数的模式匹配的开始 - 第11行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第12行~第34行:这部分代码使用
((第12行和第18行)和)(第16行和第34行)定义了两个匹配块,每个匹配块包含了多个匹配项,每个匹配项对应一种情况。在这部分代码中,使用逻辑或(OR)操作符,即|(第14行、第20行、第22行、第24行、第26行、第28行、第30行和第32行)来分隔不同的匹配项。意味着如果其中一个匹配项成功,整个匹配块就被视为成功。这允许在同一个位置匹配多种情况,根据实际的代码结构进行灵活的匹配。下面我们来分析本段代码中各个匹配块的各个匹配项:- 第13行的
ptr = (T0)src@p0:这一行代码表示对ptr进行了一个潜在的赋值操作,其中(T0)src表示将src强制类型转换为T0类型。这里涉及到对用户指针的类型转换。p0是这个赋值操作在源代码中的位置信息 - 第15行的
ptr = src@p0:这一行代码表示对ptr进行了一个潜在的赋值操作,其中src为ptr赋予了新的值。p0是这个赋值操作在源代码中的位置信息 - 第17行的
...:在这行代码中,...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第19行的
get_user(exp1, (T1)src)@p1:表示匹配代码中类似get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)src则是对获取的数据进行类型转换,其中T1是目标类型,src是指向用户空间的数据源的指针,此外,@p1表示在匹配时记录匹配位置信息,通过将匹配的位置信息保存到p1变量中,以方便后续使用 - 第21行的
get_user(exp1, src)@p1:表示匹配代码中类似get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而src是指向用户空间的数据源的指针,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第23行的
__get_user(exp1, (T1)src)@p1:表示匹配代码中类似__get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)src是指向用户空间的数据源的指针,并且进行了类型转换,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第25行的
__get_user(exp1, src)@p1:表示匹配代码中类似__get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而src是指向用户空间的数据源的指针,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第27行的
copy_from_user(exp1, (T1)src, size1)@p1:表示匹配代码中类似copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)src表示指向用户空间的数据源的指针,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第29行的
copy_from_user(exp1, src, size1)@p1:表示匹配代码中类似copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,而src表示指向用户空间的数据源的指针,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第31行的
__copy_from_user(exp1, (T1)src, size1)@p1:表示匹配代码中类似__copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)src表示指向用户空间的数据源的指针,(T1)是类型转换,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第33行的
__copy_from_user(exp1, src, size1)@p1:表示匹配代码中类似__copy_from_user的函数,其中exp1是用于接收获取的用户数据的变量,而src表示指向用户空间的数据源的指针,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用
- 第13行的
- 第35行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第36行~第42行:这部分条件是用于筛选匹配结果的,其中
ptr是一个指针,这些条件表示如果ptr在两次获取之间发生了增加或减少,或者与某个地址相等,那就不符合Double-Fetch漏洞的条件。需要注意的是,这些条件之间是逻辑与(AND)的关系,即所有条件都必须同时满足才能匹配成功。这意味着代码块必须满足所有列出的条件才能通过匹配。这些筛选条件的具体含义如下:- 第36行的
when != ptr += offset:表示ptr的值在两次获取之间不以+= offset的形式增加 - 第37行的
when != ptr = ptr + offset:表示ptr的值在两次获取之间不以= ptr + offset的形式重新赋值 - 第38行的
when != ptr++:表示ptr的值在两次获取之间不以++自增 - 第39行的
when != ptr -=offset:表示ptr的值在两次获取之间不以-= offset的形式减少 - 第40行的
when != ptr = ptr - offset:表示ptr的值在两次获取之间不以= ptr - offset的形式重新赋值 - 第41行的
when != ptr--:表示ptr的值在两次获取之间不以--自减 - 第42行的
when != ptr = addr:表示ptr的值在两次获取之间不以= addr的形式重新赋值为addr
- 第36行的
- 第43行第59行:这部分代码与第12行第34行的代码是一样的,只是变量名发生了变化。这部分代码同样使用
((第43行)和)(第59行)定义了一个匹配块,在这个匹配块中包含了多个匹配项,每个匹配项对应一种情况,并使用逻辑或(OR)操作符,即|(第45行、第47行、第49行、第51行、第53行、第55行和第57行)来分隔不同的匹配项。意味着如果其中一个匹配项成功,整个匹配块就被视为成功。这允许在同一个位置匹配多种情况,根据实际的代码结构进行灵活的匹配。对于本段代码中的各个匹配项我们在此不再赘述,因为这部分代码的匹配模式与第12行~第34行的代码的匹配模式一致,只不过使用另一套变量来获取信息(例如exp2、T2、ptr、@p2和size2)。如果经过之前的匹配和筛选后,在这部分代码中又成功匹配上了目标函数,说明我们匹配的当前的主函数中就存在Double-Fetch漏洞,并将发生漏洞的位置以及其对应的各种信息保存在各自的变量中 - 第60行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第61行:
}表示针对此主函数的模式匹配的结束 - 第63行~第67行:这部分是使用Coccinelle的Python脚本语言扩展,用于将匹配的结果存储到变量中。在这里主要存储了目标函数在代码中两次出现的位置(分别被赋值为
p31和p32)和数据源指针和地址(被赋值为p3和s3)。通过这些存储的变量,我们就可以在后续的操作中使用匹配的结果,例如打印匹配的行号或执行其他处理逻辑 - 第68行:
@@是Coccinelle中的一个关键字,表示规则的主体。在Coccinelle中,规则通常分为两部分:匹配部分和脚本部分。此处的@@用于引导匹配规则的结束,其上面的代码中包含了要匹配的代码模式 - 第69行~第74行:这段代码的作用是在匹配成功后,打印相关的匹配信息,并将这些信息传递给
coccilib.report.print_report()函数和post_match_process()函数以进行进一步处理
1.3.2.4、Explicit type conversion
这种匹配模式又可被称为:“在中间发生 ptr = src”。此种模式匹配是我们筛选Double-Fetch漏洞的第四种方式,且稍微复杂一些。当内核从用户空间获取数据时,显式指针类型转换被广泛使用。例如,在大小检查场景中,消息指针将被转换为标头指针,以在第一次获取中获取标头,然后在第二次获取中再次用作消息指针。从图1.8中的规则3可以看出,两个源指针中的任何一个都可能涉及类型转换。缺少类型转换的情况可能会导致假阴性。此外,显式指针类型转换通常与指针别名相结合,导致同一内存区域由两种类型的指针操作。下面就是这种匹配模式的具体实现函数:
//----------------------------------- case 4: ptr = src at middle @ rule4 disable drop_cast exists @
identifier func;
expression addr,exp1,exp2,src,ptr,size1,size2,offset;
position p0,p1,p2;
type T0,T1,T2;
@@ func(...){ ...
( get_user(exp1, (T1)src)@p1
| get_user(exp1, src)@p1
| __get_user(exp1, (T1)src)@p1
| __get_user(exp1, src)@p1
| copy_from_user(exp1, (T1)src,size1)@p1
| copy_from_user(exp1, src,size1)@p1
| __copy_from_user(exp1, (T1)src,size1)@p1
| __copy_from_user(exp1, src,size1)@p1
) ... when != src += offset when != src = src + offset when != src++ when != src -=offset when != src = src - offset when != src-- when != src = addr ( ptr = (T0)src@p0 // potential assignment case
| ptr = src@p0
) ... when != ptr += offset when != ptr = ptr + offset when != ptr++ when != ptr -=offset when != ptr = ptr - offset when != ptr-- when != ptr = addr ( get_user(exp2, (T2)ptr)@p2
| get_user(exp2, ptr)@p2
| __get_user(exp2,(T2)ptr)@p2
| __get_user(exp2, ptr)@p2
| __copy_from_user(exp2,(T2)ptr,size2)@p2
| __copy_from_user(exp2, ptr,size2)@p2
| copy_from_user(exp2,(T2)ptr,size2)@p2
| copy_from_user(exp2, ptr,size2)@p2
) ... } @script:python@
p41 << rule4.p1;
p42 << rule4.p2;
p4 << rule4.ptr;
s4 << rule4.src;
@@
print "src4:", str(s4)
print "ptr4:", str(p4)
if p41 and p42: coccilib.report.print_report(p41[0],"rule4 First fetch") coccilib.report.print_report(p42[0],"rule4 Second fetch") post_match_process(p41, p42, s4, p4)
在此部分代码中,首先通过在某一个主函数中匹配get_user()与copy_from_user()等子函数来获取首次得到的候选子函数,这表明是第一次出现。之后再对其进行筛选。然后再匹配用户指针的赋值情况。对于满足条件的函数再进行第二次筛选和匹配(此过程与第一次筛选和匹配的过程一致)。当第二次匹配到与第一次同名的候选子函数,且经过筛选发现数据源地址并没有发生变化,这就表明此函数是为了获取了同一个地址的数据而第二次出现。这样我们就认为匹配到的候选函数中存在Double-Fetch漏洞。下面我们将对上面的模式匹配代码进行详细分析:
- 第1行:注释,表示这是名为“在中间发生 ptr = src”的匹配模式
- 第3行:
rule4表示规则名称。disable drop_cast表示在匹配时不忽略任何类型转换,即规则将考虑代码中的所有类型转换。而exists关键字则表示规则只匹配包含drop_cast的代码块。这样规则将在包含drop_cast的情况下考虑所有类型转换 - 第4行:这行代码定义了一个名为“func”的标识符,用于在匹配规则中捕获函数名。在Coccinelle中,我们可以使用标识符来捕获匹配到的代码中的某些元素,以便在后续的处理中引用它们
- 第5行:
expression是用来声明变量的一种方式,它表示变量的类型为表达式。在上面的代码中,addr,exp1,exp2,src,ptr,size1,size2,和offset都被声明为expression类型的变量。这些变量的作用如下(通过这样的声明,我们就可以在规则的匹配模式和处理脚本中使用这些变量,并对它们进行相应的操作):addr:用于表示地址的表达式exp1和exp2:分别表示两个表达式src:表示源地址或源数据的表达式ptr:表示指向用户空间数据的指针的表达式size1和size2:表示大小的表达式offset:表示偏移量的表达式
- 第6行:
position是Coccinelle中用来表示代码位置的关键字。在规则的匹配中,position可以用来捕获匹配到的代码的位置信息,例如行号、文件名等。在这个脚本中,p0、p1和p2是三个position类型的变量,分别用来表示用户空间指针的地址和捕获匹配到的两个位置。这些地址和位置信息可以在后续的处理中使用,例如打印或记录这些地址和位置信息 - 第7行:这行代码定义了三个类型标识符,用于匹配不同的类型。在规则中,
T0用于表示用户空间指针的数据的类型,T1和T2可以分别代表两次获取的数据的类型。这样,规则可以灵活地适用于不同类型的获取操作。例如,如果第一次获取的数据类型是int,那么T1可以表示为int。如果第二次获取的数据类型是char,那么T2可以表示为char。若用户空间指针的数据的类型是int,那么那么T0可以表示为int。这样的灵活性使得规则可以适用于多种类型的情况,而不仅仅局限于特定的数据类型 - 第8行:
@@是Coccinelle中的一个关键字,表示规则的主体。在Coccinelle中,规则通常分为两部分:匹配部分和脚本部分。此处的@@用于引导匹配规则的开始,其下面的代码中包含了要匹配的代码模式 - 第11行:这行代码是模式匹配的一部分,用于指定匹配的函数形式。在Coccinelle中,我们可以使用
func(...)这样的形式来表示匹配任意形式的函数,其中...表示函数的参数列表,这可以是任意数量和类型的参数。此外,还使用{表示针对此主函数的模式匹配的开始 - 第12行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第13行~第29行:这部分代码使用
((第13行)和)(第29行)定义了一个匹配块,这个匹配块包含了多个匹配项,每个匹配项对应一种情况。在这部分代码中,使用逻辑或(OR)操作符,即|(第15行、第17行、第19行、第21行、第23行、第25行和第27行)来分隔不同的匹配项。意味着如果其中一个匹配项成功,整个匹配块就被视为成功。这允许在同一个位置匹配多种情况,根据实际的代码结构进行灵活的匹配。下面我们来分析本段代码中各个匹配块的各个匹配项:- 第14行的
get_user(exp1, (T1)src)@p1:表示匹配代码中类似get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)src则是对获取的数据进行类型转换,其中T1是目标类型,src是指向用户空间的数据源的指针,此外,@p1表示在匹配时记录匹配位置信息,通过将匹配的位置信息保存到p1变量中,以方便后续使用 - 第16行的
get_user(exp1, src)@p1:表示匹配代码中类似get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而src是指向用户空间的数据源的指针,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第18行的
__get_user(exp1, (T1)src)@p1:表示匹配代码中类似__get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)src是指向用户空间的数据源的指针,并且进行了类型转换,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第20行的
__get_user(exp1, src)@p1:表示匹配代码中类似__get_user()的函数,其中exp1是用于接收获取的用户数据的变量,而src是指向用户空间的数据源的指针,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第22行的
copy_from_user(exp1, (T1)src, size1)@p1:表示匹配代码中类似copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)src表示指向用户空间的数据源的指针,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第24行的
copy_from_user(exp1, src, size1)@p1:表示匹配代码中类似copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,而src表示指向用户空间的数据源的指针,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第26行的
__copy_from_user(exp1, (T1)src, size1)@p1:表示匹配代码中类似__copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,而(T1)src表示指向用户空间的数据源的指针,(T1)是类型转换,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第28行的
__copy_from_user(exp1, src, size1)@p1:表示匹配代码中类似__copy_from_user的函数,其中exp1是用于接收获取的用户数据的变量,而src表示指向用户空间的数据源的指针,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用
- 第14行的
- 第30行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第31行~第37行:这部分条件是用于筛选匹配结果的,其中
src是一个指针,这些条件表示如果src在两次获取之间发生了增加或减少,或者与某个地址相等,那就不符合Double-Fetch漏洞的条件。需要注意的是,这些条件之间是逻辑与(AND)的关系,即所有条件都必须同时满足才能匹配成功。这意味着代码块必须满足所有列出的条件才能通过匹配。这些筛选条件的具体含义如下:- 第31行的
when != src += offset:表示src的值在两次获取之间不以+= offset的形式增加 - 第32行的
when != src = src + offset:表示src的值在两次获取之间不以= src + offset的形式重新赋值 - 第33行的
when != src++:表示src的值在两次获取之间不以++自增 - 第34行的
when != src -=offset:表示src的值在两次获取之间不以-= offset的形式减少 - 第35行的
when != src = src - offset:表示src的值在两次获取之间不以= src - offset的形式重新赋值 - 第36行的
when != src--:表示src的值在两次获取之间不以--自减 - 第37行的
when != src = addr:表示src的值在两次获取之间不以= addr的形式重新赋值为addr
- 第31行的
- 第39行~第43行:此部分匹配块对潜在的指向用户空间的指针
src重新赋值为ptr变量的行为进行匹配:- 第40行的
ptr = (T0)src@p0:这一行代码表示对ptr进行了一个潜在的赋值操作,其中(T0)src表示将src强制类型转换为T0类型。这里涉及到对用户指针的类型转换。p0是这个赋值操作在源代码中的位置信息 - 第42行的
ptr = src@p0:这一行代码表示对ptr进行了一个潜在的赋值操作,其中src为ptr赋予了新的值。p0是这个赋值操作在源代码中的位置信息
- 第40行的
- 第44行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第45行~第51行:这部分代码的匹配规则与第31行~第37行代码的匹配规则一致,只是在这里匹配的变量变成了重新赋值的
ptr指针,目的是匹配重新赋值的ptr指针是否发生了变化。关于匹配的具体细节我们在此并不赘述,可以参考第31行~第37行的匹配代码 - 第53行~第69行:这部分代码与第13行~第29行的代码是一样的,只是变量名发生了变化。这部分代码同样使用
((第53行)和)(第69行)定义了一个匹配块,在这个匹配块中包含了多个匹配项,每个匹配项对应一种情况,并使用逻辑或(OR)操作符,即|(第55行、第57行、第59行、第61行、第63行、第65行和第67行)来分隔不同的匹配项。意味着如果其中一个匹配项成功,整个匹配块就被视为成功。这允许在同一个位置匹配多种情况,根据实际的代码结构进行灵活的匹配。对于本段代码中的各个匹配项我们在此不再赘述,因为这部分代码的匹配模式与第13行~第29行的代码的匹配模式一致,只不过使用另一套变量来获取信息(例如exp2、T2、ptr、@p2和size2)。如果经过之前的匹配和筛选后,在这部分代码中又成功匹配上了目标函数,说明我们匹配的当前的主函数中就存在Double-Fetch漏洞,并将发生漏洞的位置以及其对应的各种信息保存在各自的变量中 - 第70行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第71行:
}表示针对此主函数的模式匹配的结束 - 第73行~第77行:这部分是使用Coccinelle的Python脚本语言扩展,用于将匹配的结果存储到变量中。在这里主要存储了目标函数在代码中两次出现的位置(分别被赋值为
p41和p42)和数据源指针和地址(被赋值为p4和s4)。通过这些存储的变量,我们就可以在后续的操作中使用匹配的结果,例如打印匹配的行号或执行其他处理逻辑 - 第78行:
@@是Coccinelle中的一个关键字,表示规则的主体。在Coccinelle中,规则通常分为两部分:匹配部分和脚本部分。此处的@@用于引导匹配规则的结束,其上面的代码中包含了要匹配的代码模式 - 第79行~第84行:这段代码的作用是在匹配成功后,打印相关的匹配信息,并将这些信息传递给
coccilib.report.print_report()函数和post_match_process()函数以进行进一步处理
1.3.2.5、Combination of element fetch and pointer fetch
这种匹配模式又可被称为:“首先是元素,然后是指针,在结构体中进行复制”。此种模式匹配是我们筛选Double-Fetch漏洞的第五种方式,更复杂一些。在某些情况下,用户指针既用于获取整个数据结构,也用于通过将指针解引用到数据结构的元素来仅获取一部分。例如,在大小检查场景中,用户指针首先用于通过get_user(len,ptr->len)获取消息长度,然后通过copy_from_user(msg,ptr,len)在第二次获取中复制整个消息,这意味着两次获取使用的指针与传递函数参数不完全相同,但它们在语义上涵盖了相同的值。正如我们从图1.8中的规则4中看到的那样,这种情况可能使用用户指针或数据结构的地址作为传递函数的参数。这种情况通常在显式指针类型转换时出现,如果错过这种情况,可能会导致假阴性。下面就是这种匹配模式的具体实现函数:
//----------------------------------- case 5: first element, then ptr, copy from structure
@ rule5 disable drop_cast exists @
identifier func, e1;
expression addr,exp1,exp2,src,size1,size2,offset;
position p1,p2;
type T1,T2;
@@ func(...){ ...
( get_user(exp1, (T1)src->e1)@p1
| get_user(exp1, src->e1)@p1
| get_user(exp1, &(src->e1))@p1
| __get_user(exp1, (T1)src->e1)@p1
| __get_user(exp1, src->e1)@p1
| __get_user(exp1, &(src->e1))@p1
| copy_from_user(exp1, (T1)src->e1,size1)@p1
| copy_from_user(exp1, src->e1,size1)@p1
| copy_from_user(exp1, &(src->e1),size1)@p1
| __copy_from_user(exp1, (T1)src->e1,size1)@p1
| __copy_from_user(exp1, src->e1,size1)@p1
| __copy_from_user(exp1, &(src->e1),size1)@p1
) ... when != src += offset when != src = src + offset when != src++ when != src -=offset when != src = src - offset when != src-- when != src = addr
( get_user(exp2,(T2)src)@p2
| get_user(exp2,src)@p2
| __get_user(exp2,(T2)src)@p2
| __get_user(exp2,src)@p2
| __copy_from_user(exp2,(T2)src,size2)@p2
| __copy_from_user(exp2,src,size2)@p2
| copy_from_user(exp2,(T2)src,size2)@p2
| copy_from_user(exp2,src,size2)@p2
) ... } @script:python@
p51 << rule5.p1;
p52 << rule5.p2;
s5 << rule5.src;
e5 << rule5.e1;
@@
print "src5:", str(s5)
print "e5:", str(e5)
if p51 and p52: coccilib.report.print_report(p51[0],"rule5 First fetch") coccilib.report.print_report(p52[0],"rule5 Second fetch") post_match_process(p51, p52, s5, e5)
在此部分代码中,首先通过在某一个主函数中匹配get_user()与copy_from_user()等子函数来获取首次得到的候选子函数,这表明是第一次出现。然后对其进行筛选,对于满足条件的函数再进行第二次匹配,当第二次匹配到与第一次同名的候选子函数,且经过筛选发现数据源地址并没有发生变化,这就表明此函数是为了获取了同一个地址的数据而第二次出现。这样我们就认为匹配到的候选函数中存在Double-Fetch漏洞。下面我们将对上面的模式匹配代码进行详细分析:
- 第1行:注释,表示这是名为“首先是元素,然后是指针,在结构体中进行复制”的匹配模式
- 第2行:
rule5表示规则名称。disable drop_cast表示在匹配时不忽略任何类型转换,即规则将考虑代码中的所有类型转换。而exists关键字则表示规则只匹配包含drop_cast的代码块。这样规则将在包含drop_cast的情况下考虑所有类型转换 - 第3行:这行代码定义了名为“func”和名为“e1”的标识符,用于在匹配规则中捕获函数名和捕获结构体中的一个字段或元素。在Coccinelle中,我们可以使用标识符来捕获匹配到的代码中的某些元素,以便在后续的处理中引用它们
- 第4行:
expression是用来声明变量的一种方式,它表示变量的类型为表达式。在上面的代码中,addr,exp1,exp2,src,size1,size2,和offset都被声明为expression类型的变量。这些变量的作用如下(通过这样的声明,我们就可以在规则的匹配模式和处理脚本中使用这些变量,并对它们进行相应的操作):addr:用于表示地址的表达式exp1和exp2:分别表示两个表达式src:表示源地址或源数据的表达式size1和size2:表示大小的表达式offset:表示偏移量的表达式
- 第5行:
position是Coccinelle中用来表示代码位置的关键字。在规则的匹配中,position可以用来捕获匹配到的代码的位置信息,例如行号、文件名等。在这个脚本中,p1和p2是两个position类型的变量,用来表示捕获匹配到的两个位置。这些地址和位置信息可以在后续的处理中使用,例如打印或记录这些地址和位置信息 - 第6行:这行代码定义了两个类型标识符,用于匹配不同的类型。在规则中,
T1和T2可以分别代表两次获取的数据的类型。这样,规则可以灵活地适用于不同类型的获取操作。例如,如果第一次获取的数据类型是int,那么T1可以表示为int。如果第二次获取的数据类型是char,那么T2可以表示为char。这样的灵活性使得规则可以适用于多种类型的情况,而不仅仅局限于特定的数据类型 - 第7行:
@@是Coccinelle中的一个关键字,表示规则的主体。在Coccinelle中,规则通常分为两部分:匹配部分和脚本部分。此处的@@用于引导匹配规则的开始,其下面的代码中包含了要匹配的代码模式 - 第10行:这行代码是模式匹配的一部分,用于指定匹配的函数形式。在Coccinelle中,我们可以使用
func(...)这样的形式来表示匹配任意形式的函数,其中...表示函数的参数列表,这可以是任意数量和类型的参数。此外,还使用{表示针对此主函数的模式匹配的开始 - 第11行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第12行~第36行:这部分代码使用
((第12行)和)(第36行)定义了一个匹配块,这个匹配块包含了多个匹配项,每个匹配项对应一种情况。在这部分代码中,使用逻辑或(OR)操作符,即|(第14行、第16行、第18行、第20行、第22行、第24行、第26行、第28行、第30行和第32行)来分隔不同的匹配项。意味着如果其中一个匹配项成功,整个匹配块就被视为成功。这允许在同一个位置匹配多种情况,根据实际的代码结构进行灵活的匹配。下面我们来分析本段代码中各个匹配块的各个匹配项:- 第13行的
get_user(exp1, (T1)src->e1)@p1:表示匹配形如get_user()的函数,将用户数据存储到变量exp1中,通过(T1)对获取的数据进行类型转换,从结构体src的元素e1中获取用户数据。@p1记录匹配位置信息,保存到变量p1中,以方便后续使用 - 第15行的
get_user(exp1, src->e1)@p1:表示匹配形如get_user()的函数,将用户数据存储到变量exp1中,并从结构体src的元素e1中获取用户数据。@p1记录匹配位置信息,保存到变量p1中,以方便后续使用 - 第17行的
get_user(exp1, &(src->e1))@p1:表示匹配代码中类似get_user()的函数,在获取用户数据时取结构体src的元素e1的地址,并将结果存储到变量exp1中,@p1记录匹配位置信息,保存到变量p1中,以便后续使用 - 第19行的
__get_user(exp1, (T1)src->e1)@p1:表示匹配形如__get_user()的函数,将用户数据存储到变量exp1中,通过(T1)对获取的数据进行类型转换,从结构体src的元素e1中获取用户数据。@p1记录匹配位置信息,保存到变量p1中,以方便后续使用 - 第21行的
__get_user(exp1, src->e1)@p1:表示匹配形如__get_user()的函数,将用户数据存储到变量exp1中,并从结构体src的元素e1中获取用户数据。@p1记录匹配位置信息,保存到变量p1中,以方便后续使用 - 第23行的
__get_user(exp1, &(src->e1))@p1:表示匹配代码中类似__get_user()的函数,在获取用户数据时取结构体src的元素e1的地址,并将结果存储到变量exp1中,@p1记录匹配位置信息,保存到变量p1中,以便后续使用 - 第25行的
copy_from_user(exp1, (T1)src->e1, size1)@p1:表示匹配代码中类似copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,并从结构体src的元素e1开始复制,还通过(T1)对获取的数据进行类型转换,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第27行的
copy_from_user(exp1, src->e1, size1)@p1:表示匹配代码中类似copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,并从结构体src的元素e1开始复制,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第29行的
copy_from_user(exp1, &(src->e1), size1)@p1:表示匹配代码中类似copy_from_user()的函数,在获取用户数据时取结构体src的元素e1的地址,并将结果存储到变量exp1中,@p1记录匹配位置信息,保存到变量p1中,以便后续使用 - 第31行的
__copy_from_user(exp1, (T1)src->e1, size1)@p1:表示匹配代码中类似__copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,并从结构体src的元素e1开始复制,还通过(T1)对获取的数据进行类型转换,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第33行的
__copy_from_user(exp1, src->e1, size1)@p1:表示匹配代码中类似__copy_from_user的函数,其中exp1是用于接收获取的用户数据的变量,并从结构体src的元素e1开始复制,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第35行的
__copy_from_user(exp1, &(src->e1), size1)@p1:表示匹配代码中类似__copy_from_user()的函数,在获取用户数据时取结构体src的元素e1的地址,并将结果存储到变量exp1中,@p1记录匹配位置信息,保存到变量p1中,以便后续使用
- 第13行的
- 第37行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第38行~第44行:这部分条件是用于筛选匹配结果的,其中
src是一个指针,这些条件表示如果src在两次获取之间发生了增加或减少,或者与某个地址相等,那就不符合Double-Fetch漏洞的条件。需要注意的是,这些条件之间是逻辑与(AND)的关系,即所有条件都必须同时满足才能匹配成功。这意味着代码块必须满足所有列出的条件才能通过匹配。这些筛选条件的具体含义如下:- 第38行的
when != src += offset:表示src的值在两次获取之间不以+= offset的形式增加 - 第39行的
when != src = src + offset:表示src的值在两次获取之间不以= src + offset的形式重新赋值 - 第40行的
when != src++:表示src的值在两次获取之间不以++自增 - 第41行的
when != src -=offset:表示src的值在两次获取之间不以-= offset的形式减少 - 第42行的
when != src = src - offset:表示src的值在两次获取之间不以= src - offset的形式重新赋值 - 第43行的
when != src--:表示src的值在两次获取之间不以--自减 - 第44行的
when != src = addr:表示src的值在两次获取之间不以= addr的形式重新赋值为addr
- 第38行的
- 第45行~第61行:这部分代码使用
((第45行)和)(第61行)定义了一个匹配块,这个匹配块包含了多个匹配项,每个匹配项对应一种情况。在这部分代码中,使用逻辑或(OR)操作符,即|(第47行、第49行、第51行、第53行、第55行、第57行和第59行)来分隔不同的匹配项。意味着如果其中一个匹配项成功,整个匹配块就被视为成功。这允许在同一个位置匹配多种情况,根据实际的代码结构进行灵活的匹配。下面我们来分析本段代码中各个匹配块的各个匹配项:- 第46行的
get_user(exp2, (T2)src)@p2:表示匹配代码中类似get_user()的函数,其中exp2是用于接收获取的用户数据的变量,而(T2)src则是对获取的数据进行类型转换,其中T2是目标类型,src是指向用户空间的数据源的指针,此外,@p2表示在匹配时记录匹配位置信息,通过将匹配的位置信息保存到p2变量中,以方便后续使用 - 第48行的
get_user(exp2, src)@p2:表示匹配代码中类似get_user()的函数,其中exp2是用于接收获取的用户数据的变量,而src是指向用户空间的数据源的指针,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用 - 第50行的
__get_user(exp2, (T2)src)@p2:表示匹配代码中类似__get_user()的函数,其中exp2是用于接收获取的用户数据的变量,而(T2)src是指向用户空间的数据源的指针,并且进行了类型转换,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用 - 第52行的
__get_user(exp2, src)@p2:表示匹配代码中类似__get_user()的函数,其中exp2是用于接收获取的用户数据的变量,而src是指向用户空间的数据源的指针,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用 - 第54行的
__copy_from_user(exp2, (T2)src, size2)@p2:表示匹配代码中类似__copy_from_user()的函数,其中exp2是用于接收获取的用户数据的变量,而(T2)src表示指向用户空间的数据源的指针,size2表示要拷贝的数据大小,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用 - 第56行的
__copy_from_user(exp2, src, size2)@p2:表示匹配代码中类似__copy_from_user()的函数,其中exp2是用于接收获取的用户数据的变量,而src表示指向用户空间的数据源的指针,size2表示要拷贝的数据大小,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用 - 第58行的
copy_from_user(exp2, (T2)src, size2)@p2:表示匹配代码中类似copy_from_user()的函数,其中exp2是用于接收获取的用户数据的变量,而(T2)src表示指向用户空间的数据源的指针,(T2)是类型转换,size2表示要拷贝的数据大小,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用 - 第60行的
copy_from_user(exp2, src, size2)@p2:表示匹配代码中类似copy_from_user的函数,其中exp2是用于接收获取的用户数据的变量,而src表示指向用户空间的数据源的指针,size2表示要拷贝的数据大小,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用
- 第46行的
- 第62行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第63行:
}表示针对此主函数的模式匹配的结束 - 第65行~第69行:这部分是使用Coccinelle的Python脚本语言扩展,用于将匹配的结果存储到变量中。在这里主要存储了目标函数在代码中两次出现的位置(分别被赋值为
p51和p52)和数据源指针和地址(被赋值为s5和e5)。通过这些存储的变量,我们就可以在后续的操作中使用匹配的结果,例如打印匹配的行号或执行其他处理逻辑 - 第70行:
@@是Coccinelle中的一个关键字,表示规则的主体。在Coccinelle中,规则通常分为两部分:匹配部分和脚本部分。此处的@@用于引导匹配规则的结束,其上面的代码中包含了要匹配的代码模式 - 第71行~第76行:这段代码的作用是在匹配成功后,打印相关的匹配信息,并将这些信息传递给
coccilib.report.print_report()函数和post_match_process()函数以进行进一步处理
1.3.2.6、Loop involvement
这种匹配模式又可被称为:“先获取第一个元素,然后获取指针,最后从指针复制数据”。此种模式匹配是我们筛选Double-Fetch漏洞的第六种方式,更复杂一些。由于Coccinelle对路径敏感,当代码中出现循环时,循环中的一个传递函数调用将被报告为两个调用,这可能会导致误报。此外,从图1.8中的规则5可以看出,当一个循环中有两次提取时,上一次迭代的第二次提取和下一次迭代中的第一次提取将作为双提取进行匹配。这种情况应该作为假阳性删除,因为在遍历迭代时应该更改用户指针,并且这两次获取的值不同。此外,使用数组在循环中复制不同值的情况也会导致误报。下面就是这种匹配模式的具体实现函数:
//----------------------------------- case 6: first element, ptr, copy from pointer
@ rule6 disable drop_cast exists @
identifier func, e1;
expression addr,exp1,exp2,src,size1,size2,offset;
position p1,p2;
type T1,T2;
@@ func(...){ ...
( get_user(exp1, (T1)src.e1)@p1
| get_user(exp1, src.e1)@p1
| get_user(exp1, &(src.e1))@p1
| __get_user(exp1, (T1)src.e1)@p1
| __get_user(exp1, src.e1)@p1
| __get_user(exp1, &(src.e1))@p1
| copy_from_user(exp1, (T1)src.e1, size1)@p1
| copy_from_user(exp1, src.e1, size1)@p1
| copy_from_user(exp1, &(src.e1), size1)@p1
| __copy_from_user(exp1, (T1)src.e1, size1)@p1
| __copy_from_user(exp1, src.e1, size1)@p1
| __copy_from_user(exp1, &(src.e1), size1)@p1
) ... when != &src += offset when != &src = &src + offset when != &src++ when != &src -=offset when != &src = &src - offset when != &src-- when != &src = &addr
( get_user(exp2,(T2)&src)@p2
| get_user(exp2,&src)@p2
| __get_user(exp2,(T2)&src)@p2
| __get_user(exp2,&src)@p2
| __copy_from_user(exp2,(T2)&src,size2)@p2
| __copy_from_user(exp2,&src,size2)@p2
| copy_from_user(exp2,(T2)&src,size2)@p2
| copy_from_user(exp2,&src,size2)@p2
) ... } @script:python@
p61 << rule6.p1;
p62 << rule6.p2;
s6 << rule6.src;
e6 << rule6.e1;
@@
print "src6:", str(s6)
print "e6:", str(e6)
if p61 and p62: coccilib.report.print_report(p61[0],"rule6 First fetch") coccilib.report.print_report(p62[0],"rule6 Second fetch") post_match_process(p61, p62, s6, e6)
在此部分代码中,首先通过在某一个主函数中匹配get_user()与copy_from_user()等子函数来获取首次得到的候选子函数,这表明是第一次出现。然后对其进行筛选,对于满足条件的函数再进行第二次匹配,当第二次匹配到与第一次同名的候选子函数,且经过筛选发现数据源地址并没有发生变化,这就表明此函数是为了获取了同一个地址的数据而第二次出现。这样我们就认为匹配到的候选函数中存在Double-Fetch漏洞。下面我们将对上面的模式匹配代码进行详细分析:
- 第1行:注释,表示这是名为“先获取第一个元素,然后获取指针,最后从指针复制数据”的匹配模式
- 第2行:
rule6表示规则名称。disable drop_cast表示在匹配时不忽略任何类型转换,即规则将考虑代码中的所有类型转换。而exists关键字则表示规则只匹配包含drop_cast的代码块。这样规则将在包含drop_cast的情况下考虑所有类型转换 - 第3行:这行代码定义了名为“func”和名为“e1”的标识符,用于在匹配规则中捕获函数名和捕获结构体中的一个字段或元素。在Coccinelle中,我们可以使用标识符来捕获匹配到的代码中的某些元素,以便在后续的处理中引用它们
- 第4行:
expression是用来声明变量的一种方式,它表示变量的类型为表达式。在上面的代码中,addr,exp1,exp2,src,size1,size2,和offset都被声明为expression类型的变量。这些变量的作用如下(通过这样的声明,我们就可以在规则的匹配模式和处理脚本中使用这些变量,并对它们进行相应的操作):addr:用于表示地址的表达式exp1和exp2:分别表示两个表达式src:表示源地址或源数据的表达式size1和size2:表示大小的表达式offset:表示偏移量的表达式
- 第5行:
position是Coccinelle中用来表示代码位置的关键字。在规则的匹配中,position可以用来捕获匹配到的代码的位置信息,例如行号、文件名等。在这个脚本中,p1和p2是两个position类型的变量,用来表示捕获匹配到的两个位置。这些地址和位置信息可以在后续的处理中使用,例如打印或记录这些地址和位置信息 - 第6行:这行代码定义了两个类型标识符,用于匹配不同的类型。在规则中,
T1和T2可以分别代表两次获取的数据的类型。这样,规则可以灵活地适用于不同类型的获取操作。例如,如果第一次获取的数据类型是int,那么T1可以表示为int。如果第二次获取的数据类型是char,那么T2可以表示为char。这样的灵活性使得规则可以适用于多种类型的情况,而不仅仅局限于特定的数据类型 - 第7行:
@@是Coccinelle中的一个关键字,表示规则的主体。在Coccinelle中,规则通常分为两部分:匹配部分和脚本部分。此处的@@用于引导匹配规则的开始,其下面的代码中包含了要匹配的代码模式 - 第8行:这行代码是模式匹配的一部分,用于指定匹配的函数形式。在Coccinelle中,我们可以使用
func(...)这样的形式来表示匹配任意形式的函数,其中...表示函数的参数列表,这可以是任意数量和类型的参数。此外,还使用{表示针对此主函数的模式匹配的开始 - 第9行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第10行~第34行:这部分代码使用
((第10行)和)(第34行)定义了一个匹配块,这个匹配块包含了多个匹配项,每个匹配项对应一种情况。在这部分代码中,使用逻辑或(OR)操作符,即|(第12行、第14行、第16行、第18行、第20行、第22行、第24行、第26行、第28行、第30行和第32行)来分隔不同的匹配项。意味着如果其中一个匹配项成功,整个匹配块就被视为成功。这允许在同一个位置匹配多种情况,根据实际的代码结构进行灵活的匹配。下面我们来分析本段代码中各个匹配块的各个匹配项:- 第11行的
get_user(exp1, (T1)src.e1)@p1:表示匹配形如get_user()的函数,将用户数据存储到变量exp1中,通过(T1)对获取的数据进行类型转换,从指针src的元素e1中获取用户数据。@p1记录匹配位置信息,保存到变量p1中,以方便后续使用 - 第13行的
get_user(exp1, src.e1)@p1:表示匹配形如get_user()的函数,将用户数据存储到变量exp1中,并从指针src的元素e1中获取用户数据。@p1记录匹配位置信息,保存到变量p1中,以方便后续使用 - 第15行的
get_user(exp1, &(src.e1))@p1:表示匹配代码中类似get_user()的函数,在获取用户数据时取指针src的元素e1的地址,并将结果存储到变量exp1中,@p1记录匹配位置信息,保存到变量p1中,以便后续使用 - 第17行的
__get_user(exp1, (T1)src.e1)@p1:表示匹配形如__get_user()的函数,将用户数据存储到变量exp1中,通过(T1)对获取的数据进行类型转换,从指针src的元素e1中获取用户数据。@p1记录匹配位置信息,保存到变量p1中,以方便后续使用 - 第19行的
__get_user(exp1, src.e1)@p1:表示匹配形如__get_user()的函数,将用户数据存储到变量exp1中,并从指针src的元素e1中获取用户数据。@p1记录匹配位置信息,保存到变量p1中,以方便后续使用 - 第21行的
__get_user(exp1, &(src.e1))@p1:表示匹配代码中类似__get_user()的函数,在获取用户数据时取指针src的元素e1的地址,并将结果存储到变量exp1中,@p1记录匹配位置信息,保存到变量p1中,以便后续使用 - 第23行的
copy_from_user(exp1, (T1)src.e1, size1)@p1:表示匹配代码中类似copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,并从指针src的元素e1开始复制,还通过(T1)对获取的数据进行类型转换,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第25行的
copy_from_user(exp1, src.e1, size1)@p1:表示匹配代码中类似copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,并从指针src的元素e1开始复制,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第27行的
copy_from_user(exp1, &(src.e1), size1)@p1:表示匹配代码中类似copy_from_user()的函数,在获取用户数据时取指针src的元素e1的地址,并将结果存储到变量exp1中,@p1记录匹配位置信息,保存到变量p1中,以便后续使用 - 第29行的
__copy_from_user(exp1, (T1)src.e1, size1)@p1:表示匹配代码中类似__copy_from_user()的函数,其中exp1是用于接收获取的用户数据的变量,并从指针src的元素e1开始复制,还通过(T1)对获取的数据进行类型转换,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第31行的
__copy_from_user(exp1, src.e1, size1)@p1:表示匹配代码中类似__copy_from_user的函数,其中exp1是用于接收获取的用户数据的变量,并从指针src的元素e1开始复制,size1表示要拷贝的数据大小,此外,@p1表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p1变量中,以便后续使用 - 第33行的
__copy_from_user(exp1, &(src.e1), size1)@p1:表示匹配代码中类似__copy_from_user()的函数,在获取用户数据时取指针src的元素e1的地址,并将结果存储到变量exp1中,@p1记录匹配位置信息,保存到变量p1中,以便后续使用
- 第11行的
- 第35行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第36行~第42行:这部分条件是用于筛选匹配结果的,其中
src是一个指针,这些条件表示如果src在两次获取之间发生了增加或减少,或者与某个地址相等,那就不符合Double-Fetch漏洞的条件。需要注意的是,这些条件之间是逻辑与(AND)的关系,即所有条件都必须同时满足才能匹配成功。这意味着代码块必须满足所有列出的条件才能通过匹配。这些筛选条件的具体含义如下:- 第36行的
when != src += offset:表示src的值在两次获取之间不以+= offset的形式增加 - 第37行的
when != src = src + offset:表示src的值在两次获取之间不以= src + offset的形式重新赋值 - 第38行的
when != src++:表示src的值在两次获取之间不以++自增 - 第39行的
when != src -=offset:表示src的值在两次获取之间不以-= offset的形式减少 - 第40行的
when != src = src - offset:表示src的值在两次获取之间不以= src - offset的形式重新赋值 - 第41行的
when != src--:表示src的值在两次获取之间不以--自减 - 第42行的
when != src = addr:表示src的值在两次获取之间不以= addr的形式重新赋值为addr
- 第36行的
- 第43行~第59行:这部分代码使用
((第43行)和)(第59行)定义了一个匹配块,这个匹配块包含了多个匹配项,每个匹配项对应一种情况。在这部分代码中,使用逻辑或(OR)操作符,即|(第45行、第47行、第49行、第51行、第53行、第55行和第57行)来分隔不同的匹配项。意味着如果其中一个匹配项成功,整个匹配块就被视为成功。这允许在同一个位置匹配多种情况,根据实际的代码结构进行灵活的匹配。下面我们来分析本段代码中各个匹配块的各个匹配项:- 第44行的
get_user(exp2, (T2)src)@p2:表示匹配代码中类似get_user()的函数,其中exp2是用于接收获取的用户数据的变量,而(T2)src则是对获取的数据进行类型转换,其中T2是目标类型,src是指向用户空间的数据源的指针,此外,@p2表示在匹配时记录匹配位置信息,通过将匹配的位置信息保存到p2变量中,以方便后续使用 - 第46行的
get_user(exp2, &src)@p2:表示匹配代码中类似get_user()的函数,其中exp2是用于接收获取的用户数据的变量,而获取的是指针src的地址,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用 - 第48行的
__get_user(exp2, (T2)src)@p2:表示匹配代码中类似__get_user()的函数,其中exp2是用于接收获取的用户数据的变量,而获取的是指针src的地址,并且进行了类型转换,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用 - 第50行的
__get_user(exp2, &src)@p2:表示匹配代码中类似__get_user()的函数,其中exp2是用于接收获取的用户数据的变量,而获取的是指针src的地址,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用 - 第52行的
__copy_from_user(exp2, (T2)&src, size2)@p2:表示匹配代码中类似__copy_from_user()的函数,其中exp2是用于接收获取的用户数据的变量,而获取的是指针src的地址,并向T2进行类型转换,size2表示要拷贝的数据大小,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用 - 第54行的
__copy_from_user(exp2, &src, size2)@p2:表示匹配代码中类似__copy_from_user()的函数,其中exp2是用于接收获取的用户数据的变量,而获取的是指针src的地址,size2表示要拷贝的数据大小,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用 - 第56行的
copy_from_user(exp2, (T2)&src, size2)@p2:表示匹配代码中类似copy_from_user()的函数,其中exp2是用于接收获取的用户数据的变量,而获取的是指针src的地址,并向T2进行类型转换,size2表示要拷贝的数据大小,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用 - 第58行的
copy_from_user(exp2, &src, size2)@p2:表示匹配代码中类似copy_from_user的函数,其中exp2是用于接收获取的用户数据的变量,而获取的是指针src的地址,size2表示要拷贝的数据大小,此外,@p2表示在匹配时记录匹配位置信息,将匹配的位置信息保存到p2变量中,以便后续使用
- 第44行的
- 第60行:在这行代码中,
...主要用于表示匹配函数体内的代码片段,而不对具体的函数体内容进行关注。这是一种通配符,表示匹配任意数量和类型的语句或表达式 - 第61行:
}表示针对此主函数的模式匹配的结束 - 第63行~第67行:这部分是使用Coccinelle的Python脚本语言扩展,用于将匹配的结果存储到变量中。在这里主要存储了目标函数在代码中两次出现的位置(分别被赋值为
p61和p62)和数据源指针和地址(被赋值为s6和e6)。通过这些存储的变量,我们就可以在后续的操作中使用匹配的结果,例如打印匹配的行号或执行其他处理逻辑 - 第68行:
@@是Coccinelle中的一个关键字,表示规则的主体。在Coccinelle中,规则通常分为两部分:匹配部分和脚本部分。此处的@@用于引导匹配规则的结束,其上面的代码中包含了要匹配的代码模式 - 第69行~第74行:这段代码的作用是在匹配成功后,打印相关的匹配信息,并将这些信息传递给
coccilib.report.print_report()函数和post_match_process()函数以进行进一步处理
2、安装与使用
| 软件环境 | 硬件环境 | 约束条件 |
|---|---|---|
| Ubuntu-22.04.2-desktop-amd64(内核版本5.19.0-43-generic) | 使用4个处理器,每个处理器4个内核,共分配16个内核 | 约束条件 本文所使用的Double-Fetch源代码为2023-05-12版本 |
| 具体的软件环境可见“2.1、源码安装”章节所示的软件环境 | 内存16GB | 具体的约束条件可见“2.1、源码安装”章节所示的软件版本约束 |
| 硬盘30GB | ||
| Double-Fetch部署在VMware Pro 17上的Ubuntu22.04.2系统上(主机系统为Windows 11),硬件环境和软件环境也是对应的VMware Pro 17的硬件环境和软件环境 |
2.1、源码安装
2.1.1、部署系统依赖组件
Double-Fetch的安装部署相对于其他漏洞检测工具的部署过程来说比较简单,除了系统自带的软件环境,我们只需要额外安装如下软件即可。下面我们将逐一安装这些软件:
- Gcc 11.3.0
- Coccinelle 1.1.1
2.1.1.1、下载安装Gcc 11.3.0
- 输入如下命令安装Gcc 11.3.0:
$ sudo apt install gcc
- 使用如下命令验证是否安装成功:
$ gcc --version
- 可以发现已经成功安装Gcc 11.3.0了:

2.1.1.2、下载安装Coccinelle 1.1.1
- 下载源码后进入并进入对应目录生成configure,最后查看是否生成成功:
# 下载源码
$ sudo git clone https://github.com/coccinelle/coccinelle.git
# 进入coccinelle代码目录
$ cd coccinelle/
# 生成configure
$ sudo ./autogen
# 查看源代码目录信息
$ ls -l
- 如果没有任何问题,就会成功生成configure文件:

- 然后执行如下命令来检查当前系统环境是否满足Coccinelle的安装要求:
$ sudo ./configure
- 如果没有问题,就说明符合要求,那么下面就来编译Coccinelle源代码:
$ sudo make
- 如果没有报错,就说明编译成功,下面安装Coccinelle即可:
$ sudo make install
- 如果没有任何报错就代表Coccinelle安装成功了:

注:实际执行中遇到的问题及解决方法
A 问题1:
- 生成configure的时候,可能会报如下图所示的错误:

- 根据报错信息我们可以发现,这是因为我们没有安装automake[9],那我们就按照提示安装automake即可:
$ sudo apt-get install automake
B 问题2:
- 检查当前系统环境是否满足Coccinelle的安装要求的时候,可能会报如下图所示的错误

- 经过阅读报错信息可以发现,是由于我们没有安装OCaml[10],我们只需要输入如下命令来安装OCaml:
$ sudo apt-get install ocaml
C 问题3:
- 编译Coccinelle源代码的时候,可能会报如下图所示的错误

- 这是因为我们没有安装make[11],执行如下命令安装make即可:
# 更新软件源
$ sudo apt-get update
# 安装make
$ sudo apt-get install make
2.1.2、使用源码安装系统
- 下载源代码并查看其中内容[3]:
# 下载源码
$ sudo git clone https://github.com/UCL-CREST/doublefetch.git
# 进入源代码文件夹
$ cd doublefetch/
# 查看源代码文件夹中的内容
$ ls -l
- 下图就是整个代码目录的全部内容:

- text-filter:文本过滤方法double-fetch检测工具
- cocci:基于coccinelle引擎的模式匹配方法double-fetch检测工具
- auto_fix:基于coccinelle引擎的doublt-fetch漏洞修补工具
- README.md:项目的帮助手册
- 其实这就已经安装完成了,本项目的安装还是比较简单的,下面介绍一下各个工具文件夹中各个文件的作用,输入如下命令进入text-filter工具文件夹,并查看其中具体内容:
# 进入text-filter工具文件夹
$ cd text-filter/
# 查看此目录中的具体内容
$ ls -l
- 此目录的全部内容如下图所示:

- filter.py:文本过滤方法检测double-fetch漏洞第一阶段的源代码,并将第一阶段得到的结果保存到output文件夹中
- filter2.py:文本过滤方法检测double-fetch漏洞第二阶段的源代码,并将第二阶段得到的结果保存到output2文件夹中
- readme.txt:工具的帮助手册
- start.sh:工具启动的shell脚本
- 然后我们再进入cocci工具文件夹看一下:
# 返回上一级
$ cd ..
# 进入cocci工具文件夹
$ cd cocci/
# 查看此目录中的具体内容
$ ls -l
- 此目录的全部内容如下:

- testdir:保存待检测的源代码
- copy_files:将可能存在double-fetch漏洞的源代码文件复制到outcome目录,以便于人工分析
- pattern_match_freebsd.cocci:检测FreeBSD操作系统中Double-Fetch漏洞的源代码,其中存储了作者为模式匹配添加的规则,并将日志记录到result.txt
- pattern_match_linux.cocci:检测Linux操作系统中Double-Fetch漏洞的源代码,其中存储了作者为模式匹配添加的规则,并将日志记录到result.txt
- startcocci_freebsd.sh:启动FreeBSD操作系统下此工具的shell脚本,此脚本将删除上次解析剩下的文件,并调用相应的cocci脚本
- startcocci_linux.sh:启动Linux操作系统下此工具的shell脚本,此脚本将删除上次解析剩下的文件,并调用响应的cocci脚本
- readme.txt:工具的帮助手册
- test.c:测试代码
- 然后我们再进入auto_fix工具文件夹看一下:
# 返回上一级
cd ..
# 进入auto_fix目录
cd auto_fix/
# 查看此目录的具体内容
ls -l
- 此目录的全部内容如下图所示:

- bug_files:存放待检测的源代码文件
- patched_files:存放检测并修复漏洞后的源代码文件
- test func:测试代码
- fix.cocci:基于coccinelle引擎的double-fetch漏洞修补工具的源代码
- readme:工具的帮助手册
- start.sh:工具启动的shell脚本
2.2、使用方法
2.2.1、文本过滤工具的使用
- 进入文本过滤工具源代码的目录并创建启动工具相关的文件夹:
# 进入文本过滤工具源代码目录
$ cd /opt/code/doublefetch/text-filter/
# 创建存放待检测源代码文件的文件夹
$ sudo mkdir test
# 创建存放第一阶段检测结果的文件夹
$ sudo mkdir output
# 创建存放第二阶段检测结果的文件夹
$ sudo mkdir output2
# 创建存放相关源文件的文件夹
$ sudo mkdir source
- 执行如下命令来向test文件夹中存入一份存在Double-Fetch漏洞的源代码文件:
$ sudo cp /opt/code/doublefetch/auto_fix/bug_files/auditsc.c /opt/code/doublefetch/text-filter/test/
- 此时我们已经做好了准备工作,直接使用如下命令来启动检测:
$ sudo ./start.sh
- 如果成功,会出现如下提示:

- 成功之后,可以使用如下命令来查看检测后的结果:
$ sudo vim output/1-auditsc.c
- 可以发现,成功检测到了Double-Fetch漏洞:

注:实际执行中遇到的问题及解决方法
A 问题1:
- 在启动检测工具的时候,可能会报如下图所示的错误:

- 上面的错误提示乍一看是代码错误,实则不然,出现这种错误的原因是因为Ubuntu为了加快开机速度,默认将root指向dash,而dash是轻量化的shell,不支持很多命令,所以我们应该将dash指向取消[12]。在Ubuntu虚拟机界面中的终端执行如下命令即可:
$ sudo dpkg-reconfigure dash
- 然后会出现如下图所示的界面,选择“否”,然后按一下“Enter”键:

- 可以发现已经成功取消了dash的指向:

B 问题2:
- 在启动检测工具的时候,可能会报如下图所示的错误:

- 既然提示信息告诉我们“start.sh”的第52行报错了,我们就使用如下命令来看一下究竟这行代码为什么报错了:
$ sudo vim start.sh
- 经过观察,可以发现,这个其实也不算是代码错误,这是因为Ubuntu 22.04.2默认安装的Python版本为3.10.6,如果执行Python命令只能使用“python3”来执行,而代码中使用的却是“python”来执行,这自然就会报错:

- 所以我们只需要将“start.sh”中的“python”全部修改为“python3”(一共有两处需要修改):

C 问题3:
- 在启动检测工具的时候,可能会报如下图所示的错误:

- 根据报错信息,可以发现此错误是由于代码中混用了tab和4个space[13],所以我们应该修改代码,要么全用tab,要么全用4个space。我们首先修改filter.py,因为目前是这个代码文件报错了,使用如下命令打开此代码文件:
$ sudo vim filter.py
- 首先在vim的命令模式下键入如下内容,然后回车。这行命令的目的是用space代替tab:

- 然后在vim的命令模式下键入如下内容,然后回车。这行命令的目的是将当前代码文件中的所有代码行都用4个space代替tab:

- 保险起见,再按照上面的两步修改一下filter2.py代码文件
D 问题4:
- 在启动检测工具的时候,可能会报如下图所示的错误:

- 分析以上报错,这是因为filter.py代码中的“print”语句没有加括号:

- 所以我们只需要将filter.py中的所有“print”语句全部加上括号即可,filter2.py中目前没有发现这个问题,所以不用修改:

2.2.2、模式匹配工具的使用
- 输入如下命令进入模式匹配工具的源代码目录:
$ cd /opt/code/doublefetch/cocci/
- 在“testdir/truecases”中已经保存了一些测试文件,所以不需要手动添加了,如果有自定义检测的需要,可以将待检测文件放到“testdir/truecases”中。因为我们检测的是Linux内核中的Double-Fetch漏洞,所以使用如下命令开始检测:
$ sudo ./startcocci_linux.sh
- 如果成功执行,会出现如下图所示的提示信息:

- 成功执行后,输入如下命令来查看一下检测日志:
$ sudo vim result.txt
- 可以发现,模式匹配工具已经将发生double-fetch漏洞的代码行记录下来了:

- 然后使用如下命令来查看一下检测结果:
$ ls outcome/
- 可以发现,模式匹配工具已经成功将发生Double-Fetch漏洞的源代码文件保存到“outcome”文件夹中了:

注:实际执行中遇到的问题及解决方法
A 问题1:
- 在启动检测工具的时候,可能会报如下图所示的错误:

- 看到这两个报错先别着急,这两个报错是不是和运行文本过滤工具中的报错差不多呢?一个是因为“print”函数没加“()”,一个是因为Python 3.10.6的执行命令是“python3”,所以做和之前一样的修改即可:

2.2.3、漏洞修补工具的使用
- 使用如下命令进入漏洞修补工具的源代码文件夹中:
$ cd /opt/code/doublefetch/auto_fix/
- 直接使用作者提供的存在double-fetch漏洞的源代码文件进行测试即可,如有自定义检测的需要,就将需要检测的源代码文件放到“bug_files”中。我们只需要执行如下命令来启动漏洞修补工具:
$ sudo ./start.sh
- 这次没有任何问题,成功执行了:

- 然后输入如下命令来查看一下Double-Fetch漏洞的修复结果:
$ ls patched_files/
- 可以发现,漏洞修补工具已经成功将修复后的源代码文件保存到“patched_files”文件夹中了:

3、测试用例
为了比较在不同版本的Linux内核代码中Double-Fetch漏洞检测工具的检测能力以及查看随着Linux内核的版本更新,以前的Double-Fetch漏洞是否被修复,分别选择Linux 2.6.9、Linux 4.6.2和Linux 5.6.2版本内核进行对比测试。为了保证测试的准确性与可比较性,我们在三个版本下选择的测试文件均相同。
需要强调的是,随着Linux内核版本的更新,在Linux 2.6.9版本内核中的mic_virtio.c与mic_virtio.h源代码随着内核版本的不断更新,这两个函数在Linux 4.6.2与Linux 5.6.2版本内核中已经不存在或者被替换了,所以这两个源代码并不在我们的对比测试用例之内。下面就是具体的对比测试结果。
3.1、Linux 2.6.9内核代码测试
- 在“/opt/code/doublefetch/cocci/testdir/truecases”目录存入如下测试文件[3]:

- 然后返回到cocci工具目录下,执行如下代码进行测试:
# 进入cocci工具目录
$ cd /opt/code/doublefetch/cocci/
# 开始检测
$ sudo ./startcocci_linux.sh
- 如果成功执行,会出现如下图所示的提示信息:

- 成功执行后,输入如下命令来查看一下检测日志:
$ sudo vim result.txt
- 可以发现,模式匹配工具已经将发生Double-Detch漏洞的代码行记录下来了:

- 然后使用如下命令来查看一下检测结果:
$ ls outcome/
- 可以发现,模式匹配工具已经成功将发生Double-Fetch漏洞的源代码文件保存到“outcome”文件夹中了:

3.2、Linux 4.6.2内核代码测试
- 在“/opt/code/doublefetch/cocci/testdir/truecases”目录存入如下测试文件[14]:

- 然后返回到cocci工具目录下,执行如下代码进行测试:
# 进入cocci工具目录
$ cd /opt/code/doublefetch/cocci/
# 开始检测
$ sudo ./startcocci_linux.sh
- 如果成功执行,会出现如下图所示的提示信息:

- 成功执行后,输入如下命令来查看一下检测日志:
$ sudo vim result.txt
- 可以发现,模式匹配工具已经将发生Double-Detch漏洞的代码行记录下来了:

- 然后使用如下命令来查看一下检测结果:
$ ls outcome/
- 可以发现,模式匹配工具已经成功将发生Double-Fetch漏洞的源代码文件保存到“outcome”文件夹中了:

3.3、Linux 5.6.2内核代码测试
- 在“/opt/code/doublefetch/cocci/testdir/truecases”目录存入如下测试文件[15]:

- 然后返回到cocci工具目录下,执行如下代码进行测试:
# 进入cocci工具目录
$ cd /opt/code/doublefetch/cocci/
# 开始检测
$ sudo ./startcocci_linux.sh
- 如果成功执行,会出现如下图所示的提示信息:

- 成功执行后,输入如下命令来查看一下检测日志:
$ sudo vim result.txt
- 可以发现,模式匹配工具已经将发生Double-Detch漏洞的代码行记录下来了:

- 然后使用如下命令来查看一下检测结果:
$ ls outcome/
- 可以发现,模式匹配工具已经成功将发生Double-Fetch漏洞的源代码文件保存到“outcome”文件夹中了:

根据以上的对比试验可以发现,在Linux 2.6.9版本的内核中,共有四个源代码文件中的五对代码发生了Double-Fetch漏洞,而在Linux 4.6.2版本的内核中,共有三个源代码文件中的四对代码发生了Double-Fetch漏洞,经过Linux内核版本的不断更新,在Linux 5.6.2版本的内核中,只有一个源代码文件中的两对代码发生了Double-Fetch漏洞。
虽然Linux的内核在不断更新,但是到了Linux 5.6.2版本的内核中仍旧存在Double-Fetch漏洞,此漏洞出现在Linux 5.6.2版本内核的commctrl.c源代码文件中的第67与104行和第504与522行,经过查阅发现,此处确实出现了Double-Fetch漏洞,至于官方为何仍没有修复,现在不得而知。未来若有机会,会检测Linux 6.x版本的内核,来看一下官方是否修复此漏洞,若仍没有修复,说明此处的“漏洞”并不会造成影响,也就侧面验证本文介绍的Double-Fetch漏洞检测工具仍有完善的空间。
不过经过对比试验,发现Double-Fetch漏洞检测工具确实可以检测到正确的Double-Fetch漏洞,作者也提到了,他们发现了一些漏洞,并且提交给官方并修复了,这也可以从本次对比试验中发现,经过Linux内核版本的不断迭代,Linux内核中“疑似或确定”的Double-Fetch漏洞越来越少,说明本工具有一定的作用以及研究价值。
4、总结
4.1、部署架构
关于Double-Fetch部署的架构图,如下所示。

对于以上架构图,我们具体来看Double-Fetch是否对其中的组件进行了修改。详情可参见下方的表格。
| 是否有修改 | 具体修改内容 | |
|---|---|---|
| 主机内核 | 无 | 无 |
| 主机操作系统 | 无 | 无 |
4.2、漏洞检测对象
- 检测的对象为主机内核
- 针对的内核版本为Linux 2.6.9、Linux 4.6.2和Linux 5.6.2
- 检测的漏洞类型为Double-Fetch错误
4.3、漏洞检测方法
- 使用文本过滤工具和模式匹配工具捕获主机Linux内核源码中对内存相邻两次的访问
- 将捕获到的潜在的Double-Fetch错误记录在主机中
4.4、种子生成/变异技术
由于不涉及种子,故没有用到任何种子生成/变异技术。
5、参考文献
- 26th USENIX Security Symposium
- 内核漏洞挖掘技术系列——静态模式匹配
- UCL-CREST/doublefetch
- Kernel Pwn基础教程之 Double Fetch
- Linux用户空间与内核空间交互的几种方式
- copy_from_user的详细用法!
- put_user()和get_user()用户空间传递数据
- CVE-2005-2490
- Ubuntu中解决aclocal:not found 未找到的问题
- Linux 静态代码检查工具:Coccinelle 的安装和使用
- 关于的Linux 的make命令的安装
- Ubuntu默认的dash带来的问题
- vim编辑python程序报错inconsistent use of tabs and spaces in indentation
- Linux-4.6.2
- Linux-5.6.2
总结
以上就是本篇博文的全部内容,可以发现,Double-Fetch漏洞检测工具的部署与使用还是比较简单的,虽然还是踩了很多坑,不过我都在博客中一一列出来了,避免各位读者再次遇到同样的问题。
对于各类漏洞检测工具的深入研究,我都已经整理成博客供大家学习了,因为知识是共享的。若对该方向感兴趣的读者一定可以从我的博客中收获满满。
总而言之,Double-Fetch漏洞检测工具是一个检测Linux内核中的Double-Fetch漏洞的很好的工具,值得大家学习。相信读完本篇博客,各位读者一定对Double-Fetch漏洞检测工具有了更深的了解。