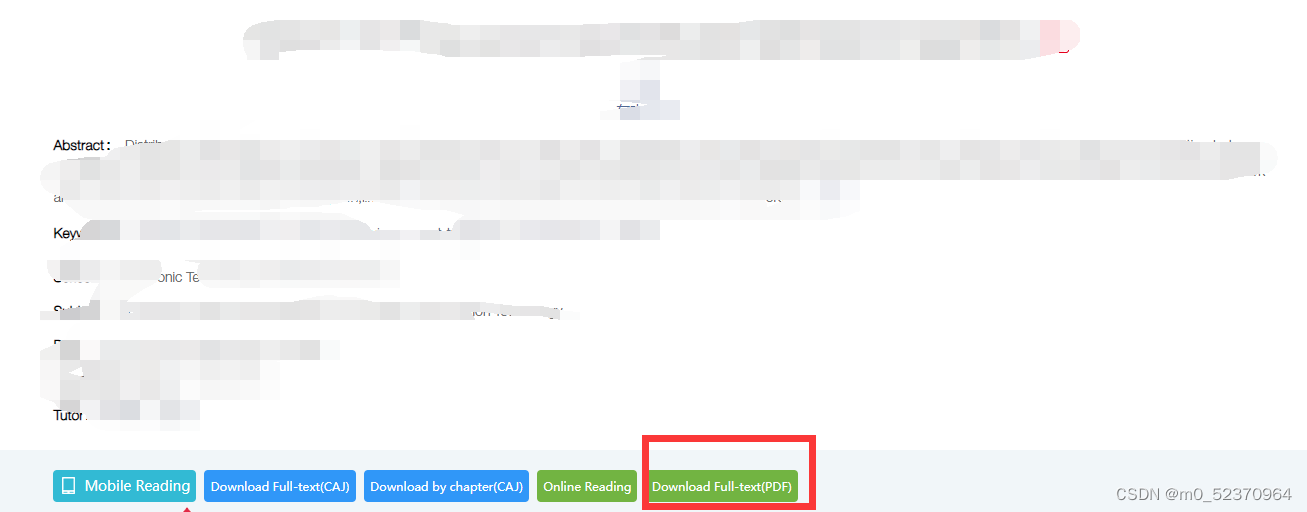
基于《知网》的词汇语义相似度计算复现源码:点击下载
源来自gittub:https://github.com/daishengdong/WordSimilarity
问题描述:
“西红柿”和“茄子”这两个词,基于字面检测相似度为0,但是我们都知道它是一个东西,所以引入基于语义的相似度检测。1
1.语义相似定义
两个任意的词语如果在不同的上下文中可以相互替换且不改变文本的语义的可能性越大,那么两者之间的相似度就越高,否则相似度就越低。2
2.语义距离
定义:数值在0到正无穷,0表示相似度为1,正无穷表示相似度为0。
检测方法:
1.基于世界知识。根据世界知识方法一般是利用一部同义词词典来计算词语语义距离,现在常用的同义词词典有同义词词林、WordNet 和 HowNet 等,其中同义林词林和 WordNet 都是将所有的概念归结到一个树状的概念层次体系中,而 HowNet 是将用来描述概念的义原组织在多棵树状的层次体系中,处于同一棵树状图中的任意两个节点之间有且只有一条可达路径,因此,两个概念之间的语义距离就可以通过这条可达路径的长度来表示。
2.基于大规模语料库。根据词汇上下文信息的概率分布计算词语语义相似度,该方法所计算得到的词语语义相似度结果精确度较高,但是计算量比较大,计算方法也比较复杂,因为该方法需要依赖于训练所用的语料库,此外,由于数据稀疏和数据噪声等因素对基于统计的方法干扰较
大,故该方法一般很少使用。
3.知网(Hownet)简介
知网是由机器翻译专家董振东借助计算机建立的一个基于知识的系统,创建知网的本意是为了解决机器翻译的问题,它是一个以汉语和英语词语所代表的概念为描述对象的知识库和常识库。
知网中主要包含义项和义原两个概念。
义项(概念):对词语语义的一种描述。例如“组织”这个词,其义项为‘组织’活动这个动词以及世界卫生‘组织’这个名词等。
义项(概念)组成,即三元组:〈W_X = 词语 G_X = 词语词性 DEF = 概念定义〉(表达一个词语的其中一个意思)
义原是用于描述义项(概念)的最小意义单位。2
一个义项(概念)由多个义原构成。
《知网》的知识描述语言2
《知网》对概念的描述是比较复杂的。在《知网》中,每一个概念用一个记录来表示,如下所示:
NO.=017144
W_C=打
G_C=V
E_C=~ 网球, ~ 牌,~ 秋千,~ 太极,球~得很棒
W_E=play
G_E=V
E_E=
DEF=exercise|锻练,sport|体育
其中NO.为概念编号,W_C,G_C,E_C分别是汉语的词语、词性和例子,W_E、G_E、E_E分别是英语的词语、词性和例子,DEF是知网对于该概念的定义,我们称之为一个语义表达式。其中DEF是知网的核心。我们这里所说的知识描述语言也就是DEF的描述语言。

注:表中描述符号含义可以参考2

每个义原是有层次结构的。
4.基于《知网》的语义相似度计算方法
4.1.把词语相似度等价于第一独立义原的相似度。
优点:简单。
缺点:没有充分利用知网的其他语义。
4.2.词语语义相似度计算
思路:比较两个词语所有概念的相似度,找出最相似的那个。
注:考虑的是独立词语,如果有上下文,则可以排除一些概念在比较。
4.3.义原相似度比较
由于所有的概念都最终归结于用义原(个别地方用具体词)来表示,所以义原的相似度计算是概念相似度计算的基础。
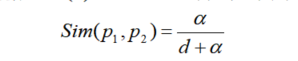
其中p1和p2表示两个义原(primitive),d是p1和p2在义原层次体系中的路径长度,是一个正整数。α是一个可调节的参数。
缺点:1)只利用了义原的上下位关系,可以考虑其他关系,如:具有反义或者对义关系的两个义原比较相似,因为它们在实际的语料中互相可以互相替换的可能性很大。2)一些义原可能再出现具体词(概念),容易造成无限递归,增加算法复杂度。
解决2):
具体词与义原的相似度一律处理为一个比较小的常数(γ);
具体词和具体词的相似度,如果两个词相同,则为1,否则为0。
4.4虚词概念的相似度的计算
我们认为,在实际的文本中,虚词和实词总是不能互相替换的,因此,虚词概念和实词概念的相似度总是为零。
由于虚词概念总是用“{句法义原}”或“{关系义原}”这两种方式进行描述,所以,虚词概念的相似度计算非常简单,只需要计算其对应的句法义原或关系义原之间的相似度即可。
4.5实词概念的相似度的计算
思路:
假设两个整体A和B都可以分解成以下部分:A分解成A1,A2,……,An,B分解成B1,B2,……,Bm,那么这些部分之间的对应关系就有m×n种。问题是:这些部分之间的相似度是否都对整体的相似度发生影响?如果不是全部都发生影响,那么我们应该如何选择那些发生影响的那些部分之间的相似度?选择出来以后,我们又如何得到整体的相似度?
我们认为:一个整体的各个不同部分在整体中的作用是不同的,只有在整体中起相同作用的部分互相比较才有效。例如比较两个人长相是否相似,我们总是比较它们的脸型、轮廓、眼睛、鼻子等相同部分是否相似,而不会拿眼睛去和鼻子做比较。
对于实词概念的语义表达式,我们将其分成四个部分:
1)第一独立义原描述式:我们将两个概念的这一部分的相似度记为Sim1(S1,S2);
2)其他独立义原描述式:语义表达式中除第一独立义原以外的所有其他独立义原(或具体词),我们将两个概念的这一部分的相似度记为Sim2(S1,S2);
3)关系义原描述式:语义表达式中所有的用关系义原描述式,我们将两个概念的这一部分的相似度记为Sim3(S1,S2);
4)符号义原描述式:语义表达式中所有的用符号义原描述式,我们将两个概念的这一部分的相似度记为Sim4(S1,S2)。
分成的部分各自比较,按照第一义原权重最高,其余各自对应添加权重进行比较。具体参考2
李蕾, 大数据环境下相似重复记录数据清洗关键技术研究, 2019, 南京邮电大学. ↩︎
刘群, 李素建. 基于《 知网》 的词汇语义相似度计算[J]. 中文计算语言学, 2002. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎