1 研究MNIST数据集对于本人课题的意义
本人的硕士研究课题是缺陷检测,缺陷检测也是机器学习&深度学习算法在图像处理中的应用,它的难点在于算法创新。因此,在正式开始进行缺陷检测算法的研究之前使用MNIST数据集对于经常用到的图像处理算法进行系统研究具有重要意义。正好我的Python机器学习大作业也是这个题目,因此这篇文章算是研一一整年学习的一个总结。
2 MNIST数据集的优点
结合ChatGPT生成的答案,我总结了MNIST数据集总共有以下两个优点:
1. 在算法与模型创新上,研究手写数字识别可以为研究者提供一个统一的评估标准,可用于比较不同算法在同一任务上的性能,有助于算法的发展和改进;MNIST的简单性和易用性也有利于研究者尝试新的机器学习方法和模型架构,便于验证新方法的可行性和有效性,为复杂视觉任务提供基础。
2. 在特征提取和降维上,MNIST图像数据集维度较低,这很大程度上减小了计算开销,通过在MNIST上探索不同的特征提取和降维技术,可以为更复杂的图像识别任务提供经验和洞察。
3 Kaggle上MNIST数据集的特性
Kaggle上的MNIST数据集存在于Digit Recognizer竞赛中,目前有1584组队伍提交了他们的解决方案,因此对于机器学习和深度学习的新手来说,MNIST数据集及其解决方案会是一个很好的学习资料,不同作者提交的方案包含了机器学习方法和深度学习方法,机器学习方法主要包括线性、非线性分类、支持向量机、随机森林等,深度学习方法主要有深度神经网络、卷积神经网络等。
Kaggle的每一个提交方案上,都会对原始数据进行了不同程度的分析以及图像增强等操作,因此有必要明确一下Kaggle中MNIST数据集的存在形式以及提交要求。
Kaggle竞赛的MNIST数据集主要包含三个csv文件,如图1所示:

在训练数据文件train.csv中,共有42000组数据,label是数字的标签,包含0到9的数字标签。由于每张图像的高度为28个像素,宽度为28个像素,因此每张图像有784个像素,在表格中使用pixel0至pixel783表示,为了在图像上定位这个像素,假设我们已经将x分解为x = i * 28 + j,其中i和j是0到27之间的整数,包括在内。那么像素x就位于28 x 28矩阵的第i行和第j列,(以0为索引)。像素的具体数值是介于0到255之间的整数,数字越大代表这个像素点越暗。部分表格数据如表1所示。
| label | pixel0 | pixel1 | pixel2 | pixel3 | pixel4 | … |
| 1 | 0 | 0 | 0 | 0 | 0 | … |
| 0 | 0 | 0 | 0 | 0 | 0 | … |
| 1 | 0 | 0 | 0 | 0 | 0 | … |
| 4 | 0 | 0 | 0 | 0 | 0 | … |
| 0 | 0 | 0 | 0 | 0 | 0 | … |
测试数据集与训练数据集标签基本相同,只是不包含label列,共有28000组数据。Kaggle提交的文件应该是以下格式:对于测试集中的28000张图像中的每一张,输出一个包含ImageId和你预测的数字的单行。例如,如果参赛者预测第一张图片是3,第二张图片是7,第三张图片是8,那么提交的文件样例如表2.2所示,sample_submission也包含了提交的样例:
| ImageId | label |
| 1 | 3 |
| 2 | 7 |
| 3 | 8 |
| … | … |
最终的评估指标是分类准确率,或者说正确分类的测试图像的比例。例如,分类准确率为0.97,表示除了3%的图像外,参赛者对所有的图像都进行了正确分类。训练集中的每个标签的数量如图2所示,从条形统计图看,基本上做到了数据的均衡。

绘制图2的代码如下:
import matplotlib.pyplot as pltlabels = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
counts = [4132, 4684, 4177, 4351, 4072, 3795, 4137, 4401, 4063, 4188]plt.bar(labels, counts, color='skyblue')plt.xlabel('Label')
plt.ylabel('Count')
plt.title('Label Counts')for i in range(len(labels)):plt.text(labels[i], counts[i] + 100, str(counts[i]), ha='center', va='bottom')plt.xticks(labels)
plt.yticks(range(0, max(counts) + 200, 500))plt.show()
可以使用算法将csv表格中像素点的灰度值转化为手写数字图像,如图3所示。
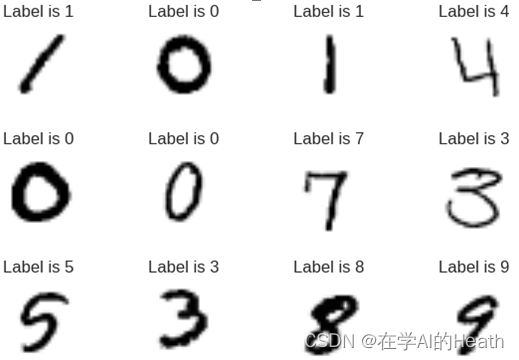
将表格中的像素点的值转换成的手写数字图像的代码如下所示:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as npdata = pd.read_csv("train.csv")# Plots the image represented by a row
def plot_number(row, w=28, h=28, labels=True):if labels:# the first column contains the labellabel = row[0]# The rest of columns are pixelspixels = row[1:]else:label = ''# The rest of columns are pixelspixels = row[0:]# print(row.shape, pixels.shape)# Make those columns into a array of 8-bits pixels# This array will be of 1D with length 784# The pixel intensity values are integers from 0 to 255pixels = 255-np.array(pixels, dtype='uint8')# Reshape the array into 28 x 28 array (2-dimensional array)pixels = pixels.reshape((w, h))# Plotif labels:plt.title('Label is {label}'.format(label=label))plt.imshow(pixels, cmap='gray')# Plots a whole slice of pictures
def plot_slice(rows, size_w=28, size_h=28, labels=True):num = rows.shape[0]w = 4h = math.ceil(num / w)fig, plots = plt.subplots(h, w)fig.tight_layout()for n in range(0, num):s = plt.subplot(h, w, n+1)s.set_xticks(())s.set_yticks(())plot_number(rows.iloc[n], size_w, size_h, labels)plt.show()# Plotting first few rows
print(plot_slice(data[0:12]))4 总结
MNIST数据集被称为计算机视觉领域的“hello world”数据集,对于研究者们试验新算法、学习图像处理具有重要的意义。在进行MNIST图像分类之前,首先需要明确问题:也就是说对于数据集本身的性质有所了解,因此本篇文章也介绍了MNIST数据集的性质、统计了标签分类、对于像素点进行了可视化的处理,为后续的算法研究打下了基础。
![[200724]什么才是高速固态硬盘?](https://img-blog.csdnimg.cn/2020072422001544.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80Njg0MTQyMQ==,size_16,color_FFFFFF,t_70)












![[基因遗传算法]进阶之三:sko.GA的实践TSP](https://img-blog.csdnimg.cn/f36fff3120d043b69a69bb13a6f0f6a0.png)
