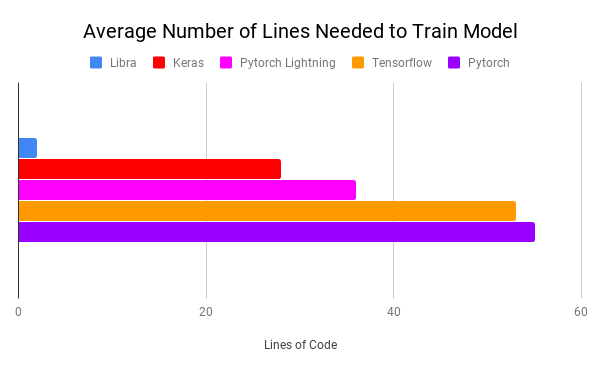
来自天秤座的梦想
Libra is one of the python package, which helps in performing deep learning on a given data set with minimum no of lines of code. The recent usages of Machine Learning in many of daily applications. There has been many platforms for performing Machine Learning on a given data set. The Libra python package is used to automate the end-to-end machine learning process in just few line of code. It is built for both non-technical users and software professionals of all kinds. The Libra package can also be used by experienced developer to perform tuning and identify the best parameters of the model.
Libra是python软件包之一,它有助于以最少的代码行对给定的数据集执行深度学习。 机器学习在许多日常应用中的最新用法。 有许多平台可以在给定的数据集上执行机器学习。 Libra python软件包仅需几行代码即可用于自动化端到端机器学习过程。 它是为非技术用户和各种软件专业人员而构建的。 经验丰富的开发人员也可以使用Libra软件包执行调整并确定模型的最佳参数。
We have to understand only the API’s used to perform the machine learning operations without worrying anything about the instructions. Libra also has large community and many resources available to get help of the package usage.
我们只需要了解用于执行机器学习操作的API,而不必担心任何说明。 天秤座还拥有庞大的社区,可利用许多资源来获得有关软件包使用的帮助。
安装天秤座 (Installing Libra)
In order to use the Libra API, install the latest Libra python package from command line is using pip.
为了使用Libra API,请从命令行使用pip安装最新的Libra python软件包。
pip install -U libra搭建环境 (Setting up the environment)
离线工作 (Working Offline)
Install Python 3.6+
安装Python 3.6+
For Libra, and other libraries, pip is the best option for installing libraries. Install the most recent version.
对于Libra和其他库,pip是安装库的最佳选择。 安装最新版本。
You can you use Jupyter Notebook or any Python IDE (PyCharm) for coding.
您可以使用Jupyter Notebook或任何Python IDE( PyCharm )进行编码。
在线预配置环境 (Online Pre Configured environment)
Google Collaboratory can be used for online usage of the Libra package, as it supports intensive processing and also configures an environment for you.
Google Collaboratory可用于在线使用Libra软件包,因为它支持密集处理并还为您配置了环境。
- Login to your google account and open up a notebook in collab. 登录到您的Google帐户,然后在collab中打开一个笔记本。
- Use !pip install libra to get all the package’s. 使用!pip install libra获取所有软件包。
- Upload your files for data and you are ready to go. 上传您的文件以获取数据,您就可以开始了。
Libra API的结构 (Libra API’s structure)
All the operation are built around the client() object in Libra. We can call different queries on it and everything will be stored under the models field of the object. All the information can be accessed has a dictionary. The latest model called will automatically be the latest.
所有操作都围绕Libra中的client()对象构建。 我们可以对其调用不同的查询,所有内容都将存储在对象的models字段下。 所有可以访问的信息都有一个字典。 最新型号将自动为最新型号。
机器学习模型 (Machine Learning models)
Below are the different Machine Learning models supported in the Libra python package,
以下是Libra python软件包中支持的不同机器学习模型,
#1神经网络 (#1 Neural Network)
The neural_network_query() method can be used to automatically fit a Neural Network to the dataset. Target detection, preprocessing, and scoring are done by default. The neural_network_query() method accepts certain parameters in order to perform the operation on the data set.Below is the sample code for performing the Neural Network operation on the dataset.
neural_network_query()方法可用于将神经网络自动拟合到数据集。 目标检测,预处理和评分默认情况下完成。 neural_network_query()方法接受某些参数以对数据集执行操作。下面是对数据集执行神经网络操作的示例代码。
new_client = client(‘path_to_dataset’)
new_client.neural_network_query(‘Please estimate the number of households.’)
new_client.models[‘regression_ANN’].plots() #access plots#2卷积神经网络 (#2 Convolutional Neural Network)
The convolutional_query() method can be used to automatically fit a Convolutional Neural Network to the dataset. Images are automatically interpolated to the median height and width. Three types of dataset structures(‘setwise’, ‘classwise’ and ‘csvwise’) are supported. Below is the sample code for performing the CNN operation on the dataset.
convolutional_query()方法可用于将卷积神经网络自动拟合到数据集。 图像会自动插值到中间的高度和宽度。 支持三种类型的数据集结构(“ setwise”,“ classwise”和“ csvwise”)。 以下是用于对数据集执行CNN操作的示例代码。
newClient = client('path_to_directory_with_image_folders')
newClient.convolutional_query("Please classify my images", pretrained={'arch':'vggnet19', 'weights':'imagenet'})#3支持向量机 (#3 Support Vector Machine)
The svm_query() method automatically fits a Support Vector Machine to the dataset. Currently classification is only supported. Target detection, preprocessing, and scoring are done by default. Below is the sample code for performing the support vector machine operation on the dataset.
svm_query()方法自动将支持向量机拟合到数据集。 当前仅支持分类。 目标检测,预处理和评分默认情况下完成。 以下是用于对数据集执行支持向量机操作的示例代码。
newClient = client('path_to_file')
newClient.svm_query('Model the type of credit card')#4最近的邻居 (#4 Nearest Neighbors)
The nearest_neighbor_query() method automatically fits the neural network to the dataset. Target detection, preprocessing, and scoring are done by default. Below is the sample code for performing the nearest neighbors operation on the dataset.
最近的nearest_neighbor_query()方法自动使神经网络适合数据集。 目标检测,预处理和评分默认情况下完成。 以下是用于对数据集执行最近邻操作的示例代码。
newClient = client('path_to_file')
newClient.nearest_neighbors_query('Model the type of credit card')#5决策树 (#5 Decision Tree)
The decision_tree_query() method automatically fits a Decision Tree algorithm to the dataset. Target detection, preprocessing, and scoring are done by default. Below is the sample code for performing the decision tree operation on the dataset.
Decision_tree_query decision_tree_query()方法自动将决策树算法拟合到数据集。 目标检测,预处理和评分默认情况下完成。 以下是用于对数据集执行决策树操作的示例代码。
newClient = client('path_to_file')
newClient.decision_tree_query('please estimate ocean proximity')#6 K-Means聚类 (#6 K-Means Clustering)
The kmeans_clustering_query() method automatically fits a clustering algorithm to the dataset. Target detection, preprocessing, and scoring are done by default. Below is the sample code for performing the K-Means clustering operation on the dataset.
kmeans_clustering_query()方法自动将聚类算法拟合到数据集。 目标检测,预处理和评分默认情况下完成。 以下是用于对数据集执行K-Means聚类操作的示例代码。
newClient = client('path_to_file')
newClient.kmeans_clustering_query(preprocess=True, generate_plots=True, drop=[])Each of the methods takes additional arguments for performing the individual operations. The more parameters you specify the more optimized the model will be generated.
每个方法都采用其他参数来执行各个操作。 您指定的参数越多,将生成的模型越优化。
自然语言处理 (Natural Language Processing)
Below are the different Natural Language Processing supported in the Libra python package,
以下是Libra python软件包中支持的不同自然语言处理,
#1文字分类 (#1 Text Classification)
The text_classification_query() method automatically fits a Text Classification model to the dataset. All standard text modification procedures are applied automatically if applicable. It is stored as ‘text_classification’ in models dictionary. Below are the Dataset Guidelines* One column in the file should contain the text to be classified* One column should contain the label of each text and SHOULD BE NAMED LABEL. If it is named something else, the name should be provided in the label_column parameter.
text_classification_query()方法自动将文本分类模型拟合到数据集。 如果适用,将自动应用所有标准文本修改程序。 它以“ text_classification”存储在模型字典中。 以下是数据集准则*文件中的一列应包含要分类的文本*每一列应包含每个文本的标签,并应命名为LABEL。 如果使用其他名称,则应在label_column参数中提供该名称。
Below is the sample code for performing the Text Classification operation on the dataset.
以下是用于对数据集执行“文本分类”操作的示例代码。
new_client = client('path_to_csv')
new_client.text_classification_query('Please estimate the sentiment')
new_client.classify_text('new text to classify')#2文件摘要 (#2 Document Summarization)
The summarization_query() method automatically fits a transfer-learning Document Summarization model to the dataset. The model will have frozen layers with pretrained weights to help with small dataset sizes. It is stored as ‘doc_summarization’ in models dictionary.
summarization_query()方法自动将转移学习文档摘要模型拟合到数据集。 该模型将具有经过预训练权重的冻结图层,以帮助实现较小的数据集大小。 它在模型字典中存储为“ doc_summarization”。
Below is the sample code for performing the Document Summarization operation on the dataset.
下面是用于对数据集执行“文档汇总”操作的示例代码。
newClient = client('path_to_csv')
newClient.summarization_query("Please summarize original text")
newClient.get_summary('new text to summarize')#3图片说明生成 (#3 Image Caption Generation)
The image_caption_query() method automatically fits an caption generation transfer learning model to your dataset. The model will have frozen layers with pretrained weights to help with small dataset sizes. It is stored as ‘image_caption’ in models dictionary.
image_caption_query()方法自动将字幕生成转移学习模型适合您的数据集。 该模型将包含具有预训练权重的冻结图层,以帮助实现较小的数据集大小。 它在模型字典中存储为“ image_caption”。
Below is the sample code for performing the Image Caption Generation operation on the dataset.
以下是用于对数据集执行“图像标题生成”操作的示例代码。
newClient = client('path_to_csv')
newClient.image_caption_query('Generate image captions')
newClient.generate_caption('path to image')#4文字生成 (#4 Text Generation)
The generate_text() method automatically generates text of specified length based on initial prefix text. It is stored as ‘generated_text’ in models dictionary.
generate_text()方法根据初始前缀文本自动生成指定长度的文本。 它在模型字典中存储为“ generated_text”。
Below is the sample code for performing the Text Generation operation on the dataset.
以下是用于对数据集执行“文本生成”操作的示例代码。
newClient = client('path_to_txt’)
newClient.generate_text(“generate text” file_data=False, prefix=“Hello there!”)#5命名实体识别 (#5 Named Entity Recognition)
The get_named_entities() method automatically detects name entities like persons name, geographic locations, organization/companies and addresses from label column containing text. It is stored as ‘named_entity_recognition’ in models dictionary.
get_named_entities()方法自动从包含文本的标签列中检测姓名实体,例如人员姓名,地理位置,组织/公司和地址。 它在模型字典中存储为“ named_entity_recognition”。
Below is the sample code for performing the Named Entity Recognition operation on the dataset.
以下是用于对数据集执行“命名实体识别”操作的示例代码。
newClient = client('path_to_txt’)
newClient.get_named_entities('detect from text')附加方法 (Additional Methods)
Libra also supports some additional methods to perform below operations on the data set.
Libra还支持一些其他方法来对数据集执行以下操作。
更深入的分析 (Deeper Analysis)
The below operations can be performed on the data set for deeper analysis of the data.
可以对数据集执行以下操作,以更深入地分析数据。
#1 Data Analysis [dashboard()]— Launch the fully functional UI to perform data analysis and dimensionality reduction live.
#1数据分析 [ dashboard() ]-启动功能齐全的UI,以实时执行数据分析和降维。
#2 Analyzing [analyze() ]— Generate in-depth statistics about the dataset.
#2分析 [ analyze() ]-生成有关数据集的深入统计信息。
信息检索 (Information Retrieval)
The below operations can be performed for information retrieval from the model for the dataset.
可以执行以下操作,以从数据集的模型中检索信息。
#1 Information [ info() ] — Used to represent each category of data generated for the dataset.
#1信息 [ info() ] —用于表示为数据集生成的每种数据类别。
#2 Plots[plots()] — Display all of the plots generated for the model
#2 Plots [ plots() ] —显示为模型生成的所有图
#3 Vocabulary[vocab()] — Used for document summarization and image caption
#3词汇表 [ vocab() ] —用于文档摘要和图像标题
#4 Prediction[predict()] — It automatically fits a neural network for the dataset.
#4 Prediction [ predict() ] —它自动适合数据集的神经网络。
#5 Model[model()] — It returns the entire dictionary of a specific model
#5 Model [ model() ] —返回特定模型的整个字典
开发团队 (Developer Team)
Below is the team behind the Libra python package.
以下是Libra python软件包背后的团队。
Founder — Palash Shah
创始人-Palash Shah
Developers — Siddharth Akalwadi , Rostam Vakhshoori , Ramya Bhaskara , Pragun Ananda , Pranav Teegavarapu , Anas Awadalla , Juan Bofill , Pratham Chhabria , Sarthak Chauhan, Goral Pahuja, Yash Himmatraka
开发商-Siddharth Akalwadi , Rostam Vakhshoori , Ramya Bhaskara , Pragun Ananda , Pranav Teegavarapu , Anas Awadalla , Juan Bofill , Pratham Chhabria , Sarthak Chauhan , Goral Pahuja , Yash Himmatraka
最后的想法 (Final Thoughts)
Libra is the nexus of modern machine learning. It combines the technology from most of the popular machine learning platforms to create a complete experience. Libra integrates the below capabilities of the Machine learning platform for making it easier to use for anyone.
天秤座是现代机器学习的纽带。 它结合了大多数流行的机器学习平台中的技术,以创建完整的体验。 Libra集成了机器学习平台的以下功能,从而使任何人都更容易使用。
Keras: straightforward model building techniques for improved modularity and ease of deployment.
Keras:简单的模型构建技术,可改善模块化和易于部署。
TensorFlow: core computational fundamentals and detailed functionality.
TensorFlow:核心计算基础和详细功能。
PyTorch: scalable training for highly-dimensional processes.
PyTorch:针对高维度流程的可扩展培训。
Scikit-Learn: one-line quick model building capabilities.
Scikit-Learn:一线快速模型构建功能。
Keras-Tuner: class-wise structure for intelligent neural network tuning.
Keras-Tuner:智能神经网络调整的类结构。
It can be used by complete novice user without worrying about the different instructions. It also helps experienced developers to perform the tuning and identify the best parameters quickly. Even Though, there are other platforms for Machine Learning, Libra helps us in building the model very quickly and perform the required machine learning task in fewer lines of code.
完全的新手用户都可以使用它,而无需担心不同的说明。 它还可以帮助有经验的开发人员快速执行调整并确定最佳参数。 尽管还有其他用于机器学习的平台,但Libra可以帮助我们快速构建模型并以更少的代码行执行所需的机器学习任务。
其他参考: (Further References:)
影片教学 (Video Tutorials)
Machine Learning in One Line of Code by Ahmad Bazzi.
艾哈迈德·巴齐(Ahmad Bazzi)编写的《代码集中的机器学习》
Introduction to Machine Learning using Libra by Palash Shah.
Palash Shah撰写的使用Libra进行机器学习简介 。
Libra — Your Data Talks Meetup by Palash Shah
天秤座— Palash Shah的数据对话聚会
文章 (Articles)
Libra: A Python tool that Automates Machine Learning Process in a Few Lines of Code by marktechpost.
Libra:由marktechpost 使用几行代码自动执行机器学习过程的Python工具 。
One liner Machine learning and Deep Learning using Libra by Ali Aryan.
Ali Aryan 使用Libra进行了一次线性机器学习和深度学习 。
Create a complex Machine Learning model in one line with Libra by Cornellius Yudha Wijaya.
与 Cornellius Yudha Wijaya的Libra一起在一行中创建一个复杂的机器学习模型 。
Fully Automated Machine Learning in One-Liners by Gagandeep Singh.
Gagandeep Singh编写的单线全自动机器学习 。
Machine Learning in One-Minute with Libra by Pranav Teegavarapu.
Pranav Teegavarapu撰写的《 天秤座一分钟的机器学习》 。
网络研讨会 (Webinars)
Become a machine learning expert at Cloud Computing, AI, Big Data.
成为云计算,人工智能,大数据领域的机器学习专家 。
Become a machine learning expert in 45 minutes at Hyphora
在Hyphora中成为45分钟内的机器学习专家
其他 (Other)
Trending Project on Made with ML in August
八月的ML制造趋势项目
Libra Documentation
天秤座文档
Tutorial Notebook on Colaboratory
协作教程笔记本
Slack Channel
松弛通道
Get Started with a Step-by-Step Guide in Medium by Palash Shah
Palash Shah撰写的 Medium中的分步指南入门
“婴儿学会了爬行,走路和奔跑。 应用机器学习时,我们正处于爬行阶段。” 〜 戴夫·沃特斯 (“A baby learns to crawl, walk and then run. We are in the crawling stage when it comes to applying machine learning.” ~Dave Waters)
翻译自: https://medium.com/@ravi07/libra-fully-automated-machine-learning-in-one-liners-27ca352339ed
来自天秤座的梦想
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/54015.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

如何防止人工智能毁灭人类

卡巴斯基郑启良:支持信创发展是卡巴斯基的重要使命

零基础转行网络工程师,过来人给的一些建议
ChatGPT评中国考研最好就业的10大专业!

![前沿重器[34] | Prompt设计——LLMs落地的版本答案](https://img-blog.csdnimg.cn/img_convert/cea34d38cb706fd6142f76d19450d007.png)
前沿重器[34] | Prompt设计——LLMs落地的版本答案
ChatGPT 一招教你安装Mysql

APP下载域名链接在微信被封,被拦截该如何处理

网站域名被微信/QQ红了(被封锁、被屏蔽、被和谐)后最好的解决方法

Docker获9500万美元D轮融资,估值或高达10亿美元

L1-064 估值一亿的AI核心代码 (20 分) Java

不足半年,估值到10亿美元的跨链新秀Axelar,实力还是噱头?

商品期货的估值与驱动

字节跳动要上市?估值4000亿美元

13 Python总结之估值
2023微信手机号筛选器,快速检测出开通微信的号码,检测国外号码过滤微信状态,判断qq是否开通微信软件
