主题介绍
当商家发布一款产品后,通过分析消费者的评论,我们能大致了解消费者对此产品的评价,如正面的,或负面的。我们更进一步可以归类正面评论和负面评论,从中找到产品的主要优点和主要缺陷,进而提出改进产品的意见,提高产品的接受度和好评度。
处理工具及方法
- 收集测试评论(爬虫:scrapy等)
- 数据清洗及数据标记,需要标记出评论是正面或负面(numpy、pandas、scipy)
- 数据建模及测试(sklearn)
- 模型应用及评估
主要步骤:
1.文件导入
import numpy as np
import pandas as pd#导入结构化评论数据
data=pd.read_csv(r"movie.csv")
data.sample(5)
2.空值统计及处理
#统计空值
data.isnull().sum()3.重复值统计及处理
#统计重复数据并删除重复数据
print(data.duplicated().sum())data.drop_duplicates(inplace=True)print(data.duplicated().sum())4.标签映射
#将标签pos和neg映射成1和0
data["label"]=data["label"].map({"pos":1,"neg":0})5.语料清洗及分词
# 用于进行中文分词的库。安装:
# pip install jiebaimport jieba
import re# 获取停用词列表
def get_stopword():# 默认情况下,在读取文件时,双引号会被解析为特殊的引用符号。双引号中的内容会正确解析,但是双引号不会解析为文本内容。# 在这种情况下,如果文本中仅含有一个双引号,会产生解析错误。如果需要将双引号作为普通的字符解析,将quoting参数设置为3。stopword = pd.read_csv(r"stopword.txt", header=None, quoting=3, sep="a")# 转换为set,这样可以比list具有更快的查询速度。return set(stopword[0].tolist())# 清洗文本数据
def clear(text):return re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "", text)# 进行分词的函数。
def cut_word(text):return jieba.cut(text)# 去掉停用词函数。
def remove_stopword(words):# 获取停用词列表。stopword = get_stopword()return [word for word in words if word not in stopword]def preprocess(text):# 文本清洗。text = clear(text)# 分词。word_iter = cut_word(text)# 去除停用词。word_list = remove_stopword(word_iter)return " ".join(word_list)# 对文本数据(评论数据)的处理。步骤:
# 1 文本清洗。去掉一些特殊无用的符号,例如@,#。
# 2 分词,将文本分解为若干单词。
# 3 去除停用词。# 以上步骤通过调用preprocess方法来实现。
data["comment"] = data["comment"].apply(lambda text: preprocess(text))6.建立模型
逻辑回归模型:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_reportX_train, X_test, y_train, y_test = train_test_split(data["comment"], data["label"], test_size=0.25, random_state=0)
# TfidfVectorizer可以看做是CountVectorizer与TfidfTransformer两个类型的合体。
tfidf = TfidfVectorizer()
lr = LogisticRegression(class_weight="balanced")
# lr = LogisticRegression()
steps = [("tfidf", tfidf), ("model", lr)]
pipe = Pipeline(steps=steps)
pipe.fit(X_train, y_train)
y_hat = pipe.predict(X_test)
print(pipe.score(X_train, y_train))
print(pipe.score(X_test, y_test))
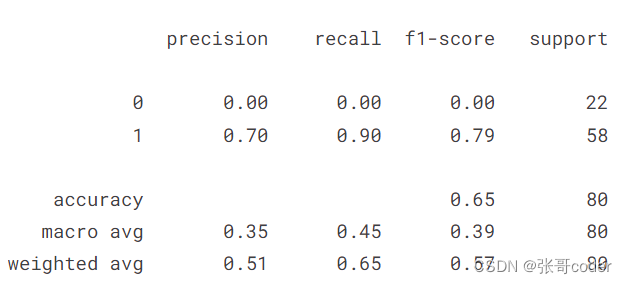
print(classification_report(y_test, y_hat))
随机森林模型:
from sklearn.ensemble import RandomForestClassifierrf = RandomForestClassifier(n_estimators=100, n_jobs=-1, class_weight="balanced")
# rf = RandomForestClassifier(n_estimators=100, n_jobs=-1)
pipe.set_params(model=rf)
pipe.fit(X_train, y_train)
y_hat = pipe.predict(X_test)
print(pipe.score(X_train, y_train))
print(pipe.score(X_test, y_test))
print(classification_report(y_test, y_hat)) 
bagging集合模型:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifierb = BaggingClassifier(base_estimator=DecisionTreeClassifier(), n_estimators=10, n_jobs=-1)
pipe.set_params(model=b)
pipe.fit(X_train, y_train)
y_hat = pipe.predict(X_test)
print(pipe.score(X_train, y_train))
print(pipe.score(X_test, y_test))
print(classification_report(y_test, y_hat))
adaboost模型:
from sklearn.ensemble import AdaBoostClassifierada = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=1), n_estimators=100)
pipe.set_params(model=ada)
pipe.fit(X_train, y_train)
y_hat = pipe.predict(X_test)
print(pipe.score(X_train, y_train))
print(pipe.score(X_test, y_test))
print(classification_report(y_test, y_hat))
知识梳理
列的数据映射
Series对象调用map()函数,向其中传入字典参数,可将原数据映射到新的数据集上
d2=pd.Series(["男","女","男","男","女"])
display(d2)d2=d2.map({"男":1,"女":0})
display(d2)
注:映射并没有在原对象上对数据进行改变,需要将其赋值给新的对象
正则表达式的文本数据清洗
str="@@ hello world *"
re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "", str)re.sub()会检索文本中每个元素,并替换所有匹配到的元素,匹配模式与re.findall()相同
+:匹配大于等于一个的元素
|:或,取并集
jieba分词
str="我不喜欢看电影"
jieba.lcut(str)jieba.lcut()返回列表
jieba.cut()返回生成器
从文本中提取特征
其实质是将每个不同的词汇作为一个特征,并根据词汇在每个字符串中的词频分配权重。
使用TfidfVectorizer来进行文本向量化,具有一个局限(不足):就是语料库中存在多少个单词,就会具有多少个特征,
这样会造成特征矩阵非常庞大,矩阵非常稀疏。我们可以通过pca或词频分析进行降维。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import TfidfVectorizerdocs = np.array(["Where there is a will, there is a way.","There is no royal road to learning.","喜欢 电影"
])#将字符串迭代器中的单词映射成数字,并统计各特征数量
count=CountVectorizer()#将字符串中的特征转换成特征矩阵
tft = TfidfTransformer()#将字符串迭代器中的字符串直接转换成特征矩阵
tfv = TfidfVectorizer()bag=count.fit(docs)print(bag.vocabulary_)
print()print(bag.transform(docs).toarray())
print()print(tft.fit_transform(bag.transform(docs)).toarray())
print()print(tfv.fit_transform(docs).toarray())
print()