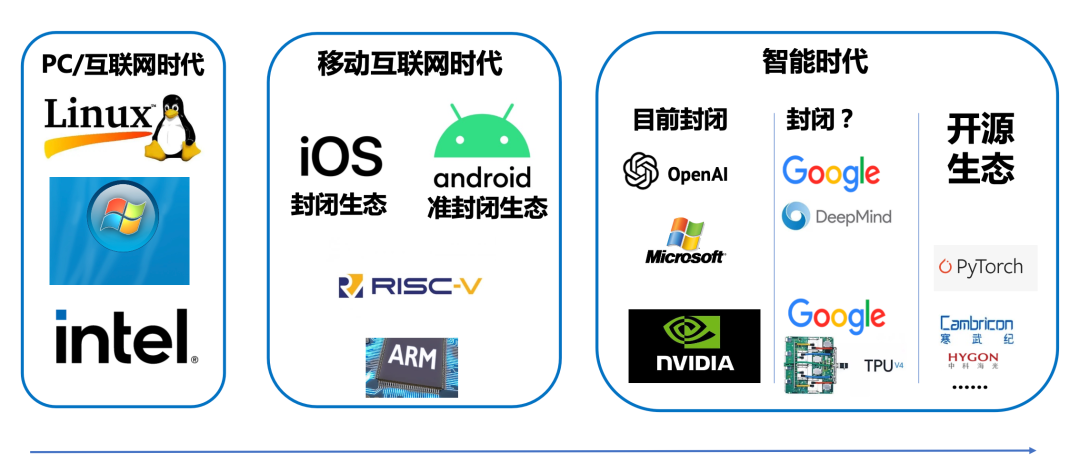
AI 时代封闭生态正在形成,需要建立开源开放的“新 Linux”生态体系。
作者 | 唐门教主
出品 | CSDN(ID:CSDNnews)
2023 年 2 月 28 日,在位于北京海淀的智源人工智能研究院里,FlagOpen 飞智大模型技术开源体系发布的现场,智源人工智能研究院院长黄铁军在演讲中表示,从 PC 时代 Linux 打破 Wintel 联盟的垄断,在 iOS 的封闭生态和 Android 的准封闭生态下,开源的 RISC-V 开始崛起。如今进入智能时代,新的封闭生态开始形成,如何防止历史重演?Linux 和 RISC-V 已经告诉我们如何解决,只是这一次,我们需要从开始就走开源开放的道路。
“智能时代需要真开源,不是 Android 那样的利用开源,不是某一企业控制的开源,而是完全在开源社区发展的、大家的开源,就像 Linux、RISC-V 和 2022 年完全转入开源社区的 PyTorch。大模型时代,需要这样的开源。”黄铁军如是说道。

黄铁军,智源人工智能研究院院长
其实,就在两天前,上海临港,在“新程序员:人工智能新十年”论坛上,智源人工智能研究院副院长兼总工程师林咏华表示,现在大家所看到的 AIGC 文生图应用,和类 ChatGPT 多任务生成生成式模型,其实只是冰山一角。

林咏华,智源人工智能研究院副院长兼总工程师
冰山之下,是大模型技术全栈的创新。林咏华这样说道:“过去几年,智源一直在做大模型研究,并积累冰山之下的大模型技术栈。走到今天,我们不再沉迷于做一枝独秀的大模型,更希望将积累的大模型技术栈,以整体开源的方式分享出来。今天的发布仅仅是一个开始,我们将和更多的企业、团队一起不断丰富 FlagOpen 的能力,推动整个产业在大模型创新上走得更快。”
一方面,是形成 AI 时代的核心竞争力,另一方面,在行业内形成联盟,一起创新突破技术难关。基于此,全部开源、立志做大模型领域的 Linux 的 FlagOpen 飞智大模型技术开源体系正式发布!

接下来,让我们一起来看一下,FlagOpen 飞智大模型技术开源体系究竟都包含哪些。

全部开源的 FlagOpen 飞智大模型技术栈
据林咏华介绍,FlagOpen(飞智)主要由 FlagAI、FlagPerf、FlagEval、FlagData、FlagStudio 和 FlagBoot 构成,旨在建设大模型领域的“Linux”。基于 FlagOpen,国内外开发者可以快速开启各种大模型的尝试、开发和研究工作,企业可以大大降低大模型的研发门槛。
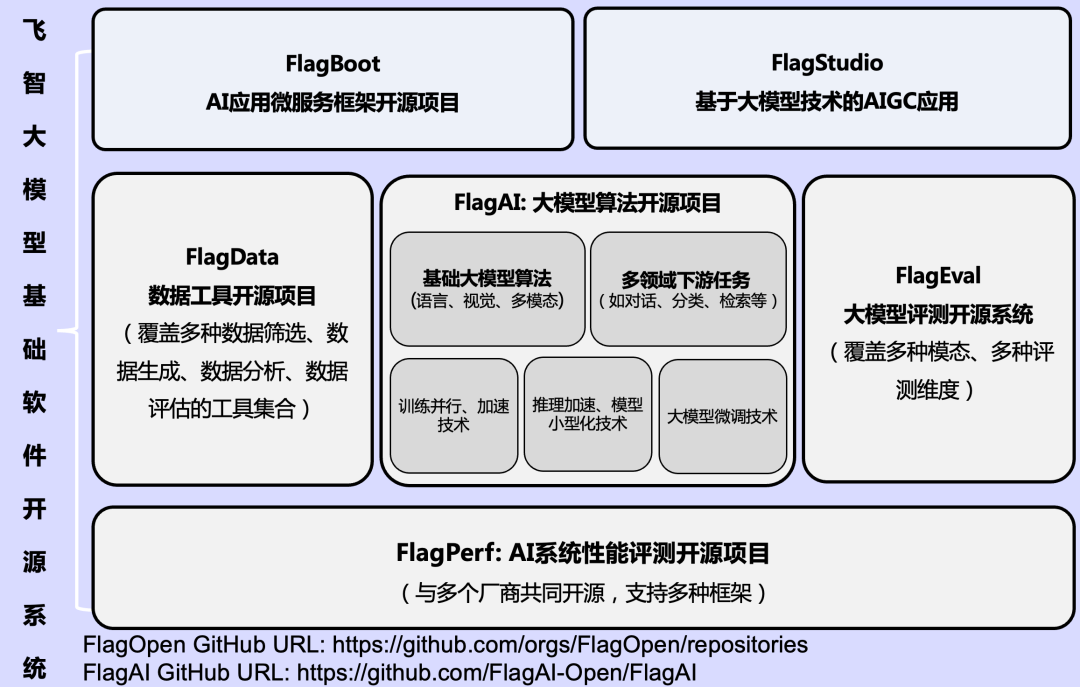
FlagAI:集大模型算法和工具为一体的一站式开源大模型软件体系
集成了多种大模型并行处理和训练加速技术,支持高效训练。FlagAI 中包含了丰富的模型资源,涵盖 NLP、计算机视觉与多模态等多个领域。其中在多模态方面,FlagAI 为 FlagStudio 项目提供了一个多语言版的 AI 艺术创作模型,辅助提高创作效率。
FlagPerf:面向 AI 异构芯片的一体化基准性能评测引擎
旨在建立开放和标准的探索开源、开放、灵活、公正、客观的 AI 芯片评测体系,通过抽象模型训练过程及厂商共建扩展的形式,提供 AI 性能测试的通用性和异构硬件的灵活性。FlagPerf 具备多框架支持,标准化模型接口,支持易用命令行工具,支持容器环境测试等特性。
FlagEval:面向大规模基础模型的一体化评测平台
旨在探索和集合科学、公正、开放的基础模型评测基准、方法及工具,对多领域(如语言、语音、视觉及多模态)的基础模型进行多维度(如准确性、效率、鲁棒性等)的评测。当前,FlagEval 主要开放多模态领域的评测工具,未来会陆续发布更多领域、更多维度的评测工具。
FlagData:面向大模型研究领域的高效易用数据处理工具包
FlagData 集成了包含清洗、标注、压缩、统计分析等功能在内的多个数据处理工具与算法,为自然语言处理、计算机视觉等领域的模型训练与部署提供了数据层面的有效支撑。
FlagStudio:利用人工智能大模型支持艺术创作应用
FlagStudio 是智源研究院应用文生图、文生音乐等人工智能模型支持艺术创作相关的开源项目集合,利用图文、声文等多模态模型,依托研究院在 NLP 和 CV 领域大模型的研究基础,为艺术创作提供更加符合中文场景的人工智能开源算法和模型。当前主要提供文生图相关的能力。
FlagBoot:基于 Scala 开发的轻量级高并发微服务框架
FlagBoot 是基于 Scala 开发的轻量级高并发微服务框架。FlagBoot 框架是默认完全异步的,微服务处理任何一个 API 都是完全异步执行的,FlagBoot 帮助开发者对异步线程控制进行了性能良好的统一管理。FlagBoot 中没有宏、隐式转换等晦涩难懂的代码,再加上 FlagBoot 的代码量极少,这使得开发者能够轻易地了解 FlagBoot 的逻辑,并进行自定义的修改。

智源研究院和 CSDN 联合发布“数据飞轮”数据共享标注计划
在 FlagOpen 飞智大模型技术开源体系发布的同时,智源还与 CSDN 一起联合发布了“数据飞轮”计划。CSDN 副总裁邹欣表示,CSDN 和智源共同意识到,AI 社区要解决当前大模型创新需要解决的数据难题。

邹欣,CSDN 副总裁
当前,我们在数据方面主要面临以下困境:
1. 数据存储分散:构建大模型所需的开放数据集由不同机构构建,需进行搜集并整合;
2. 数据建设成本高昂:据 AI 分析公司 Cognilytica 统计,在 AI 相关研究中,超过 80% 的时间都花费在了数据准备工作上;
3. 数据集不开源:以 ChatGPT 为代表的 AI 研究指令数据集没有开放共享,结果难以复现,数据集分散导致资源浪费。

由此,“数据飞轮”(OpenLabel)数据共享标注计划应运而生。智源研究院和 CSDN 将合力推动数据共享标注,通过 OpenLabel、 CSDN 及广泛的社区合作,以公益互助方式,鼓励人人参与标注,热心共建。基于 FlagData 的分析清洗能力,打造高质量数据集,承诺定期开源发布。