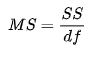文章目录
- 整体把握
- 训练集修改的创新点
- 出发点
- 修改
论文代码:https://github.com/foolwood/DaSiamRPN
论文题目:Distractor-aware Siamese Networks for Visual Object Tracking
整体把握
本篇论文赢得了vot2018短时跟踪比赛的冠军,长时跟踪比赛的第二名,比较值得研读,尤其要注意其中对于训练数据集的修改思想,值得借鉴。
这篇论文的核心内容在于:
- 通过对训练样本集的改善,从而达到提高跟踪器精度的目的。(主要)
- 提出了一种新的选取跟踪候选框的方法,即以前是通过余弦窗惩罚等惩罚选择得分最大的候选框作为跟踪框,现在是新建了一个可识别干扰的函数来挑选跟踪候选框。
- 提出了一种从局部到全局的搜索策略,这种策略主要应用在长时跟踪里面。策略的内容为当目标被遮挡时,搜索范围相应的扩大。
上述中的第2、3步并没有在代码中出现,作者给出的理由是如果加上了这些策略明显的跟踪速度会大大降低。其实我认为可能这项技术不成熟(狗头)。
训练集修改的创新点
出发点
- 训练数据集的质量越高,跟踪器的性能越好。
- 训练样本不均衡,尤其在语义信息(跟踪目标信息)、语义背景(非跟踪目标的物体信息)和非语义背景(非跟踪目标的背景信息)之间。消除样本不均衡,可以提高跟踪器的泛化能力。
修改
数据集的修改一共有三点:
-
正对的多样性会提高跟踪器的泛化能力
- 目前经常采用训练数据集一般都是从一个视频中的不同帧进行标注的,这样就会导致训练类别非常少,如VID 为20个类别,YouTube-BB为30个类别。那么若果跟踪器跟踪的目标是一种训练集没有出现的物体,跟踪的效果就会很差。
- 基于上述理由,作者提出了增加训练样本的多样性,从而提高跟踪器的泛化能力。
- 如果是重新标注的话,需要耗费大量的时间精力,于是作者将关注点转移到了目标检测领域的ImageNet和COCO检测数据集,这些数据集的种类繁多,符合训练样本多样性的要求。
- 由于我们的主体跟踪器是SiamRPN,它对于训练样本的要求为是一对图像对。于是,作者利用图像增强技术(平移,调整大小等)将静态图片转换成一对图像对后进行训练。
- 上述操作后,训练样本的数量大大增强,提高了跟踪器的判别能力和回归准确性。
-
语义否定对可以提高判别能力
- 语义否定对的含义:顾名思义,就是一对由非跟踪目标的物体组成的训练图片对。

如上图所示,如果滑板女孩是跟踪目标,那么图片中出现的老人和连衣裙女孩就是非跟踪的物体。 - 论文中提出了两个不均衡的观点印证语义否定对的出现的必要性:
- 目前的训练样本中背景占了很大的比重,导致了大多数的负样本都是非语义的(非物体),这就造成了语义对象之间的损失被大量容易否定的东西压倒。也就是跟踪器前景和背景的训练样本所占的比重过大而忽略了跟踪对象与非跟踪对象的训练样本,从而导致样本不均衡。
- 训练样本处理非跟踪对象的方法,是作为硬负性样本。本来跟踪对象与非跟踪对象训练样本占的分量就很小,如果只是固定的挑选负分数最高的几个非跟踪对象进行训练,进一步减少了跟踪对象与非跟踪对象的训练样本,加剧了样本不均衡。
- 针对上述出现的跟踪对象和非跟踪对象的训练样本过少的情况,添加其样本,也就是添加语义否定对。
- 添加语义否定对的本质是添加非跟踪对象的种类,分为添加非跟踪对象的相同种类和非跟踪对象的不同种类。
- 相同种类:添加相同种类,与跟踪目标组成多对语义否定对,增强跟踪器判别能力和泛化能力,更加精确。
- 不同种类:添加不同种类,是为了防止在跟踪过程中漂移到其他对象,如遮挡。
- 语义否定对的含义:顾名思义,就是一对由非跟踪目标的物体组成的训练图片对。
-
自定义有效的数据增强以进行视觉跟踪
- 作者提出了一种新的增强技术,称为运动模糊。
- 作者观察到运动模式可以通过网络中的浅层轻松建模,于是在数据扩充中明确引入了运动模糊。
对于数据集的修改是我认为这篇论文最主要的东西,剩下的搜索策略就是我上述提到的意思,至于新的选取跟踪候选框的方法作者其实没有用到,说明这种方法还不成熟,不建议大家去学。当然对自己高要求的同学,可以自己亲自去查看一下论文。