目录
摘要
介绍
相关工作
数据
特征
模型
结果
结论
https://arxiv.org/pdf/1703.04009.pdf
发布时间:2017 年 3 月 11 日
(Google翻译)
摘要
社交媒体上自动仇恨言论检测的一个关键挑战是将仇恨言论与其他攻击性语言实例分开。词汇检测方法的精度往往较低,因为它们将所有包含特定术语的消息归类为仇恨言论,而之前使用监督学习的工作未能区分这两个类别。我们使用众包仇恨言论词典来收集包含仇恨言论关键词的推文。我们使用众包将这些推文的样本标记为三类:包含仇恨言论、仅包含冒犯性语言以及两者均不包含的那些。我们训练一个多类分类器来区分这些不同的类别。对预测和错误的仔细分析表明,我们何时可以可靠地将仇恨言论与其他冒犯性语言区分开来,以及何时更难区分。我们发现种族主义和恐同推文更有可能被归类为仇恨言论,而性别歧视推文通常被归类为冒犯性言论。没有明确仇恨关键词的推文也更难分类
(数据集地址: GitHub - t-davidson/hate-speech-and-offensive-language: Repository for the paper "Automated Hate Speech Detection and the Problem of Offensive Language", ICWSM 2017)
ella笔记:
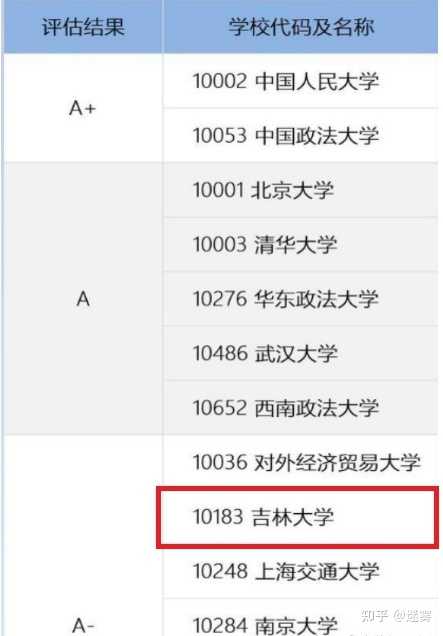
本文数据集特点
- 24,802 tweets from Hatebase
- Contain a large number of ethnicity content
- Collection on offensive keywords
- Highly imbalanced
- Hate / Offensive / Normal
- 整体精度为 0.91,召回率为 0.90,F1 分数为 0.90
====================================
介绍
- 仇恨言论没有正式的定义,但有一个共识,即以可能对弱势社会群体有害的方式针对弱势社会群体的言论(Jacobs 和 Potter 2000;Walker 1994)。
- Facebook 和 Twitter 都对批评没有采取足够措施来防止其网站上的仇恨言论做出回应,制定政策禁止使用其平台基于种族、民族、性别和性取向等特征对人进行攻击,或威胁对他人的暴力[1]
- 我们将仇恨言论定义为用于表达对目标群体的仇恨或意在贬损、羞辱或侮辱该群体成员的语言。在极端情况下,这也可能是威胁或煽动暴力的语言,但将我们的定义仅限于此类情况会排除大部分仇恨言论。重要的是,我们的定义不包括冒犯性语言的所有实例,因为人们经常使用对某些群体具有高度冒犯性但性质不同的术语。
- 许多研究仍然倾向于将仇恨言论和冒犯性语言混为一谈。
- 我们训练一个模型来区分Hate/Offensive/Normal,然后分析结果以更好地理解我们如何区分它们。
- 我们的结果表明,细粒度标签可以帮助完成仇恨言论检测任务,并突出了准确分类的一些关键挑战。我们的结论是,未来的工作必须更好地考虑仇恨言论使用的背景和异质性。
--------------------------------------------------------------
[1]Facebook 的政策可在此处找到:www.facebook.com/communitystandards#hate-speech. 可以在此处找到 Twitter 的政策:support.twitter.com/articles/20175050.
====================================
相关工作
- 词袋方法往往具有较高的召回率,但会导致较高的误报率,因为攻击性词语的存在会导致将推文错误分类为仇恨言论(Kwok 和 Wang 2013;Burnap 和 Williams 2015)。
- 专注于反黑人种族主义,Kwok 和 Wang 发现,86% 的推文被归类为种族主义的原因是因为它包含冒犯性的词语。
- 鉴于攻击性语言和“脏话”在社交媒体上的流行率相对较高,这使得仇恨言论检测变得特别具有挑战性(Wang 等人,2014 年)。
- 仇恨言论和其他冒犯性语言之间的区别通常基于细微的语言差异,例如包含单词 n***er 的推文比 n***a 更可能被标记为仇恨言论(Kwok 和 Wang 2013)。
- 许多可能是模棱两可的,例如同性恋这个词既可以用于贬义,也可以在与仇恨言论无关的其他语境中使用(Wang 等人,2014 年)。
- 句法特征已被用来更好地识别仇恨言论的目标和强度,例如出现相关名词和动词的句子(例如 kill 和 Jews)(Gitari 等人,2015 年)
- 词性三元组“DT jewish NN”(Warner和 Hirschberg 2012),句法结构 I <intensity > <user intent > <hate target >(Silva 等人,2016 年)。
- 其他仇恨言论分类的监督方法将仇恨言论与攻击性语言混为一谈,因此很难确定它们真正识别仇恨言论的程度(Burnap 和 Williams 2015;Waseem 和 Hovy 2016)。
- 神经语言模型在任务中显示出前景,但现有工作使用的训练数据对仇恨言论有类似广泛的定义(Djuric 等人,2015 年)。
- 作者的性别或种族等非语言特征有助于改善仇恨言论分类,但这些信息在社交媒体上通常不可用或不可靠(Waseem 和 Hovy 2016)。
====================================
数据
- Hatebase.org 编制的字典,该字典包含被互联网用户识别为仇恨言论的单词和短语
- 我们使用 Twitter API 搜索了包含词典中术语的推文,结果得到了来自 33,458 位 Twitter 用户的推文样本。
- 我们提取了每个用户的时间线,产生了一组 8540 万条推文。然后,我们从这个语料库中随机抽取了 25,000 条包含词典中术语的推文样本,并让 CrowdFlower (CF) 工作人员对它们进行手动编码。
- 工作人员被要求将每条推文标记为三类之一:仇恨言论、冒犯性但不仇恨的言论,或者既不冒犯也不仇恨的言论。他们收到了我们的定义以及一段对其进行更详细解释的段落。要求用户不仅要考虑给定推文中出现的词,还要考虑使用这些词的上下文。他们被告知,一个特定词的存在,无论多么令人反感,并不一定表明推文是仇恨言论。
- 每条推文都由三个或更多人编码。 CF 提供的编码器间一致性分数为 92%。我们使用多数决定为每条推文分配标签。一些推文没有分配标签,因为没有多数类别。这会产生 24,802 条带标签的推文样本。
- 只有 5% 的推文被大多数编码员编码为仇恨言论。
- 只有 1.3% 的推文被一致编码,这表明 Hatebase 词典的不精确性。 这远低于使用 Twitter 进行的比较研究,其中 11.6% 的推文被标记为仇恨言论(Burnap 和 Williams 2015),这可能是因为我们对仇恨言论使用了更严格的标准。
- 大多数推文被认为是攻击性语言(76% 为 2/3,53% 为 3/3)和其余被认为是非攻击性的(16.6% 为 2/3,11.8% 为 3/3)。
- 我们从这些推文中构建特征,并使用它们来训练分类器。
====================================
特征
- 我们将每条推文小写化并使用 Porter 词干分析器[3] 对其进行词干提取,然后创建二元组、一元组和三元组特征,每个特征都由其 TF-IDF 加权。
- 为了捕获有关句法结构的信息,我们使用 NLTK(Bird、Loper 和 Klein 2009)来构建 Penn 词性 (POS) 标记一元组、二元组和三元组。
- 为了捕捉每条推文的质量,我们使用修改后的 Flesch-Kincaid Grade Level 和 Flesch Reading Ease 分数,其中句子的数量固定为一个。
- 我们使用专为社交媒体设计的情感词典来为每条推文分配情感分数(Hutto 和 Gilbert 2014)。
- 我们还包括主题标签、提及、转发和 URL 的二进制和计数指标,以及每条推文中字符、单词和音节数量的特征。
--------------------------------------------------------------
[3] 我们验证了词干分析器没有通过将关键术语减少到相同的词干来删除重要信息
====================================
模型
- 首先使用具有 L1 正则化的逻辑回归来降低数据的维度。
- 测试了之前工作中使用的各种模型:逻辑回归、朴素贝叶斯、决策树、随机森林和线性 SVM。我们使用 5 折交叉验证来测试每个模型,保留 10% 的样本进行评估以帮助防止过度拟合。在使用网格搜索对模型和参数进行迭代后,我们发现逻辑回归和线性 SVM 往往比其他模型表现得更好。
- 对最终模型使用具有 L2 正则化的逻辑回归,因为它更容易让我们检查类成员的预测概率,并且在以前的论文中表现良好(Burnap 和 Williams 2015;Waseem 和 Hovy 2016)。
- 我们使用整个数据集训练了最终模型,并用它来预测每条推文的标签。我们使用一对一框架,其中为每个类训练一个单独的分类器,并将所有分类器中预测概率最高的类标签分配给每条推文。所有建模均使用 scikit-learn 执行(Pedregosa 等 2011)。
====================================
结果
- 表现最好的模型的整体精度为 0.91,召回率为 0.90,F1 分数为 0.90。
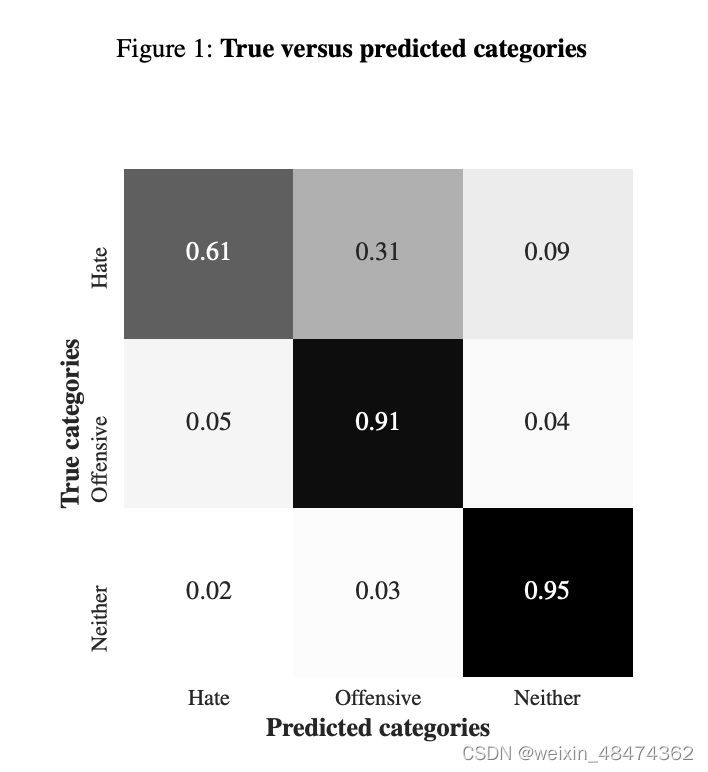
- 然而,查看图 1,我们发现近 40% 的仇恨言论被错误分类:仇恨类的准确率和召回率分别为 0.44 和 0.61。
- 大多数错误分类发生在该矩阵的上三角,这表明该模型偏向于将推文分类为比人类编码员更不仇恨或冒犯。
- 大约 5% 的冒犯性推文和 2% 的无伤大雅的推文被错误地归类为仇恨言论。
- 具有最高预测仇恨言论概率的推文往往包含多种种族或恐同诽谤
- 其他推文在包含强烈的种族主义或恐同词语时往往会被正确识别为仇恨。
- 发现人们使用仇恨言论来回应其他仇恨言论者的案例
- 看起来具有最高预测冒犯性可能性的推文实际上不那么仇恨并且可能被错误标记
- 包含诽谤但实际上是反对种族主义。编码人员很可能过快地浏览了这些推文,在没有考虑上下文的情况下挑选出看起来令人讨厌的单词或短语。
- 推文符合我们对仇恨言论的定义,但很可能被错误分类,因为它们不包含任何与仇恨言论最密切相关的术语。
- 那些被错误地标记为两者都不是的仇恨推文往往不包含仇恨或诅咒词。
- 我们还看到了罕见类型的仇恨言论分类不正确。
- 虽然分类器在仇恨言论的普遍形式上表现良好,尤其是反黑人种族主义和恐同症,但在检测不常发生的仇恨言论类型方面不太可靠,这是 Nobata 等人指出的一个问题。 (2016)。
- 我们发现许多推文包含多种诽谤,虽然这些推文包含可被视为种族主义和性别歧视的术语,但显然许多 Twitter 用户在日常交流中使用此类语言。 当他们确实包含种族主义语言时,他们倾向于包含术语 n***a 而不是 n****r,这与 Kwok 和 Wang(2013 年)的发现一致。
- 我们还发现了一些重复出现的短语,它们实际上是用户引用的说唱歌曲中的歌词。
- 此类别中被错误归类为仇恨或冒犯的推文往往会提到仇恨言论者针对的种族、性取向和其他社会类别。
- 大多数似乎是错误分类似乎是由存在潜在冒犯性语言引起的,例如他是一个该死的好演员,其中包含潜在的冒犯性术语同性恋和酷儿,但在积极的意义上使用它们。这个问题在之前的研究中遇到过(Warner 和 Hirschberg 2012),说明了考虑上下文的重要性。
- 我们还发现少数情况下,编码人员似乎错过了我们的模型正确识别的仇恨言论。这一发现与之前的工作一致,该工作发现业余编码人员在识别滥用内容方面通常不可靠(Nobata 等人 2016 年;Waseem 2016 年)。
结论
- 如果我们将仇恨言论和冒犯性语言混为一谈,那么我们就会错误地认为很多人都是仇恨言论者(图 1 下三角中的错误),并且无法区分常见的冒犯性语言和严重的仇恨言论(图 1 上三角中的错误)。
- 词汇方法是识别潜在攻击性术语的有效方法,但在识别仇恨言论方面并不准确;只有一小部分被 Hatebase 词典标记的推文被人类编码员认为是仇恨言论[4]。
- 虽然自动分类方法在区分这些不同类别时可以达到相对较高的准确性,但对结果的仔细分析表明,是否存在特定的攻击性言论或仇恨术语既可以帮助也可以阻碍准确分类。
- 我们发现某些术语对于区分仇恨言论和冒犯性语言特别有用。
- 如果仇恨言论不包含任何诅咒词或冒犯性词语,我们更有可能将其错误分类。为了更准确地对此类案例进行分类,我们应该找到仇恨的训练数据源,而不必使用特定的关键字或攻击性语言。
- 未来的工作应该区分这些不同的用途,并更仔细地研究仇恨言论发生的社会背景和对话。
- 我们还必须更仔细地研究使用仇恨言论的人,既关注他们的个人特征和动机,又关注他们所处的社会结构。
- 未来的工作应该旨在识别并纠正这些偏见。
--------------------------------------------------------------
[4] 如果必须使用词典,我们建议具有更高精确度的较小词典优于具有更高召回率的较大词典。我们在此处提供了更受限制的 Hatebase 词典版本:https://github.com/t-davidson/hate-speech-and-offensive-language。
====================================
References
Bird, S.; Loper, E.; and Klein, E. 2009. Natural Language Processing with Python. O’Reilly Media Inc.
Burnap, P., and Williams, M. L. 2015. Cyber hate speech on twitter: An application of machine classification and statistical modeling for policy and decision making. Policy & Internet 7(2):223– 242.
Djuric, N.; Zhou, J.; Morris, R.; Grbovic, M.; Radosavljevic, V.; and Bhamidipati, N. 2015. Hate speech detection with comment embeddings. In WWW, 29–30.
Gitari, N. D.; Zuping, Z.; Damien, H.; and Long, J. 2015. A lexicon-based approach for hate speech detection. International Journal of Multimedia and Ubiquitous Engineering 10:215–230.
Hutto, C. J., and Gilbert, E. 2014. VADER: A parsimonious rulebased model for sentiment analysis of social media text. In ICWSM.
Jacobs, J. B., and Potter, K. 2000. Hate crimes: Criminal Law and Identity Politics. Oxford University Press.
Kwok, I., and Wang, Y. 2013. Locate the hate: Detecting tweets against blacks. In AAAI.
Nobata, C.; Tetreault, J.; Thomas, A.; Mehdad, Y.; and Chang, Y. 2016. Abusive language detection in online user content. In WWW, 145–153.
Pedregosa, F., et al. 2011. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research 12:2825–2830.
Silva, L. A.; Mondal, M.; Correa, D.; Benevenuto, F.; and Weber, I. 2016. Analyzing the targets of hate in online social media. In ICWSM, 687–690.
Walker, S. 1994. Hate Speech: The History of an American Controversy. U of Nebraska Press.
Wang, W.; Chen, L.; Thirunarayan, K.; and Sheth, A. P. 2014. Cursing in english on twitter. In CSCW, 415–425.
Warner, W., and Hirschberg, J. 2012. Detecting hate speech on the world wide web. In LSM, 19–26.
Waseem, Z., and Hovy, D. 2016. Hateful symbols or hateful people? predictive features for hate speech detection on twitter. In SRW@HLT-NAACL, 88–93.
Waseem, Z. 2016. Are you a racist or am i seeing things? annotator influence on hate speech detection on twitter. In Proceedings of the First Workshop on NLP and CSS, 138–142.