本系列为慕课网《深度学习之神经网络(CNN/RNN/GAN)算法原理+实战》视频笔记,希望自己能通过分享笔记的形式更好的掌握该部分内容。
往期回顾:
神经网络(一)—— 机器学习、深度学习简介
神经网络(二)—— 神经元、Logistic回归模型
多分类的Logistic回归模型
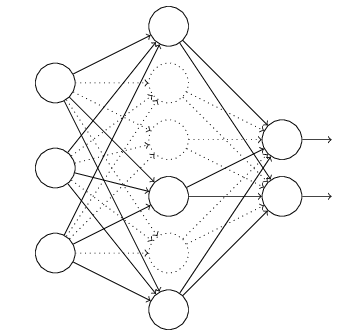
多个神经元就可以得到多个输出!由此,我们可以得到多分类的Logistic回归模型。
- W W W从向量扩展为矩阵
- 输出 W ∗ x W*x W∗x则变成向量
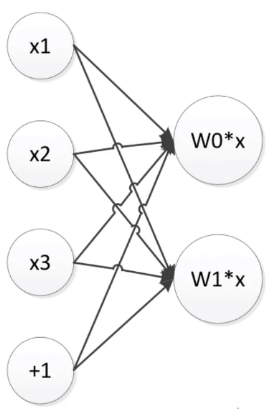
上图为两个神经元组成的三分类模型,每个神经元有不同的权重 W W W。
Example:
X = [ 3 , 1 , 2 ] X=[3,1,2] X=[3,1,2], W = [ [ 0.4 , 0.6 , 0.5 ] , [ 0.3 , 0.2 , 0.1 ] ] W=[[0.4,0.6,0.5],[0.3,0.2,0.1]] W=[[0.4,0.6,0.5],[0.3,0.2,0.1]],
then, Y = [ y 0 , y 1 ] = [ W [ 0 ] ∗ x , W [ 1 ] ∗ x ] = [ 2.8 , 1.3 ] Y=[y_0,y_1]=[W[0]*x,W[1]*x]=[2.8,1.3] Y=[y0,y1]=[W[0]∗x,W[1]∗x]=[2.8,1.3]
多输出神经元 → \rightarrow →softmax → \rightarrow →多分类Logistic回归模型
前一节(神经元、Logistic回归模型)我们已经学过了二分类Logistic回归模型通过sigmoid函数给出分类概率。但我们还可以换一个角度,把它看成将 1 1 1和 e − w T x e^{-w^Tx} e−wTx做归一化。

对于 K K K个分类的分类问题,如下图所示, W W W为一个 K − 1 K-1 K−1行的矩阵,将 K − 1 K-1 K−1个值和 1 1 1一起做归一化,给出 K K K个类别的分类概率。
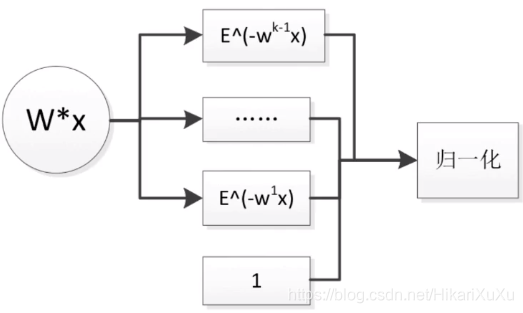
具体地分类概率:
P ( Y = k ∣ x ) = h w ( x ) = e − w k T x 1 + Σ 1 k − 1 e − w k T x , k = 1 , 2 , . . . , K − 1 P(Y=k|x)=h_w(x)=\frac{e^{-w^T_kx}}{1+\Sigma_1^{k-1} e^{-w^T_kx}}, \ k=1,2,...,K-1 P(Y=k∣x)=hw(x)=1+Σ1k−1e−wkTxe−wkTx, k=1,2,...,K−1
P ( Y = k ∣ x ) = 1 − h w ( x ) = 1 1 + Σ 1 k − 1 e − w k T x , k = K P(Y=k|x)=1-h_w(x)=\frac{1}{1+\Sigma_1^{k-1} e^{-w^T_kx}}, \ k=K P(Y=k∣x)=1−hw(x)=1+Σ1k−1e−wkTx1, k=K
Example:
Y = [ y 0 , y 1 ] = [ 2.8 , 1.3 ] Y=[y_0,y_1]=[2.8,1.3] Y=[y0,y1]=[2.8,1.3]
e − Y = [ e − 2.8 , e − 1.3 ] = [ 0.06 , 0.27 ] e^{-Y}=[e^{-2.8},e^{-1.3}]=[0.06,0.27] e−Y=[e−2.8,e−1.3]=[0.06,0.27]
S u m = 1 + 0.06 + 0.27 = 1.33 Sum=1+0.06+0.27=1.33 Sum=1+0.06+0.27=1.33
P ( Y = 0 ∣ x ) = 0.06 / 1.33 = 0.045 P(Y=0|x)=0.06/1.33=0.045 P(Y=0∣x)=0.06/1.33=0.045
P ( Y = 1 ∣ x ) = 0.27 / 1.33 = 0.203 P(Y=1|x)=0.27/1.33=0.203 P(Y=1∣x)=0.27/1.33=0.203
P ( Y = 2 ∣ x ) = 1.00 / 1.33 = 0.752 P(Y=2|x)=1.00/1.33=0.752 P(Y=2∣x)=1.00/1.33=0.752
从Logistic回归模型的介绍,我们可以看出其实我们也可以把Logistic回归模型看成神经网络,多分类的Logistic回归模型已经有多个神经元了。
目标函数(损失函数)
- 衡量对数据的拟合程度。
Example:
( x 1 , y 1 ) = ( [ 10 , 3 , 9 , 20 , . . . , 4 ] , 1 ) (x_1,y_1)=([10,3,9,20,...,4],1) (x1,y1)=([10,3,9,20,...,4],1)
y 1 ′ = M o d e l ( x 1 ) = 0.8 y_1'=Model(x_1)=0.8 y1′=Model(x1)=0.8
L o s s = ∣ y 1 − y 1 ′ ∣ = 0.2 Loss=|y_1-y_1'|=0.2 Loss=∣y1−y1′∣=0.2
One More Example:
( x 1 , y 1 ) = ( [ 10 , 3 , 9 , 20 , . . . , 4 ] , 3 ) (x_1,y_1)=([10,3,9,20,...,4],3) (x1,y1)=([10,3,9,20,...,4],3)
y 1 ′ = M o d e l ( x 1 ) = [ 0.1 , 0.2 , 0.25 , 0.4 , 0.05 ] y_1'=Model(x_1)=[0.1,0.2,0.25,0.4,0.05] y1′=Model(x1)=[0.1,0.2,0.25,0.4,0.05]
L o s s = ∣ y 1 − y 1 ′ ∣ = a b s ( [ 0 , 0 , 0 , 1 , 0 ] − y 1 ′ ) = [ 0.1 , 0.2 , 0.25 , 0.6 , 0.05 ] = 1.2 Loss=|y_1-y_1'|=abs([0,0,0,1,0]-y_1')=[0.1,0.2,0.25,0.6,0.05]=1.2 Loss=∣y1−y1′∣=abs([0,0,0,1,0]−y1′)=[0.1,0.2,0.25,0.6,0.05]=1.2
常用目标函数
- 平方差函数
1 n Σ 1 2 ( y − M o d e l ( x ) ) 2 \frac{1}{n}\Sigma\frac{1}{2}(y-Model(x))^2 n1Σ21(y−Model(x))2 - 交叉熵函数
1 n Σ y l n ( M o d e l ( x ) ) \frac{1}{n}\Sigma yln(Model(x)) n1Σyln(Model(x))
神经网络训练
- 调整参数使模型在训练集上的损失函数最小