基于线性回归预测波士顿房价
摘要:分类和回归属于机器学习领域有监督学习算法的两种方法,有监督学习是通过已有的训练样本去训练得到一个模型,再使用这个模型将所有的输入映射到相应的输出,若输出结果是离散型称为分类,若输出结果是连续型则称为回归。本项目将利用著名的 boston 房价数据集来介绍简单的回归算法,建立回归模型并通过不断训练提高准确率。
一、问题介绍:
波士顿房屋数据集于1978年开始统计,涵盖了麻省波士顿不同郊区房屋14种特征的信息。本数据集共有506个样本,每个样本有13个特征及标签MEDV
特征信息:
CRIM 城镇人均犯罪率
ZN 占地面积超过2.5万平方英尺的住宅用地比例
INDUS 城镇非零售业务地区的比例
CHAS 查尔斯河虚拟变量 (= 1 如果土地在河边;否则是0)
NOX 一氧化氮浓度(每1000万份)
RM 平均每居民房数
AGE 在1940年之前建成的所有者占用单位的比例
DIS 与五个波士顿就业中心的加权距离
RAD 辐射状公路的可达性指数
TAX 每10,000美元的全额物业税率
PTRATIO 城镇师生比例
B 1000(Bk - 0.63)^2 其中 Bk 是城镇的黑人比例
LSTAT 人口中地位较低人群的百分数
MEDV 以1000美元计算的自有住房的中位数
请解决以下问题:
请用seaborn库绘制所有特征间的相关系数热力图
并对所有特征关于MEDV标签的相关性进行排序
尝试使用相关性最高的3个特征量重建模型,并与原模型进行比较
尝试使用其它多种算法分别建立模型,并比较模型
二、解决思路:
1.导入项目所需要的包:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
2.绘制散点图矩阵:
使用sns库的pairplot()方法绘制的散点图矩阵可以查看数据集内部特征之间的关系,例如可以观察到特征间分布关系以及离群样本。查看特征间的关系,主要是变量两两之间的关系(线性或非线性,有无明显较为相关关系)
features_np = np.array([x[:13] for x in housing_data], np.float32)
labels_np = np.array([x[-1] for x in housing_data], np.float32)
df = pd.DataFrame(housing_data, columns=feature_names)
sns.pairplot(df.dropna(), y_vars=feature_names[-1], x_vars=feature_names[::-1], diag_kind='kde')
plt.show()
散点图如下:

3.特征之间的相关分析:
fig, ax = plt.subplots(figsize=(15, 1))
corr_data = df.corr().iloc[-1]
corr_data = np.asarray(corr_data).reshape(1, 14)
ax = sns.heatmap(corr_data, cbar=True, annot=True)
plt.show()
特征关系如图:

4.查看特征值的数据分布区间:
sns.boxplot(data=df.iloc[:, 0:13])
plt.show()

通过上图分析得出一些结论:
(1)波士顿房价数据中的各特征之间的相关系不大
(2)各特征的取值范围差异太大,甚至不能够在一个画布上充分的展示各属性具体的最大、最小值以及异常值等,需要做归一化处理。
做归一化有以下理由:
(1)过大或过小的数值范围会导致计算时的浮点上溢或下溢。
(2)不同的数值范围会导致不同属性对模型的重要性不同,而这个隐含的假设常常是不合理的。这会对优化的过程造成困难,使训练时间大大的加长。
5.归一化处理:
features_max = housing_data.max(axis=0)
features_min = housing_data.min(axis=0)
features_avg = housing_data.sum(axis=0) / housing_data.shape[0]BATCH_SIZE = 20
def feature_norm(input):f_size = input.shapeoutput_features = np.zeros(f_size, np.float32)for batch_id in range(f_size[0]):for index in range(13):output_features[batch_id][index] = (input[batch_id][index] - features_avg[index]) / (features_max[index] - features_min[index])return output_features#只对属性进行归一化
housing_features = feature_norm(housing_data[:, :13])
#print(feature_trian.shape)
housing_data = np.c_[housing_features, housing_data[:, -1]].astype(np.float32)
#print(training_data[0])#归一化后的train_data,我们看下各属性的情况
features_np = np.array([x[:13] for x in housing_data],np.float32)
labels_np = np.array([x[-1] for x in housing_data],np.float32)
data_np = np.c_[features_np, labels_np]
df = pd.DataFrame(data_np, columns=feature_names)
sns.boxplot(data=df.iloc[:, 0:13])
plt.show()
归一化后得到图像:

6.利用线性回归模型预测波士顿房价:
# 线性回归模型
lf = LinearRegression()
lf.fit(x_train, y_train) # 训练数据,学习模型参数
y_predict = lf.predict(x_test) # 预测# 与验证值作比较
error = mean_squared_error(y_test, y_predict).round(5) # 平方差
score = r2_score(y_test, y_predict).round(5) # 相关系数# 绘制真实值和预测值的对比图
fig = plt.figure(figsize=(13, 7))
plt.rcParams['font.family'] = "sans-serif"
plt.rcParams['font.sans-serif'] = "SimHei"
plt.rcParams['axes.unicode_minus'] = False # 绘图
plt.plot(range(y_test.shape[0]), y_test, color='red', linewidth=1, linestyle='-')
plt.plot(range(y_test.shape[0]), y_predict, color='green', linewidth=1, linestyle='dashdot')
plt.legend(['真实值', '预测值'])error = "标准差d=" + str(error)+"\n"+"相关指数R^2="+str(score)
plt.xlabel(error, size=18, color="black")
plt.grid()
plt.show()plt2.rcParams['font.family'] = "sans-serif"
plt2.rcParams['font.sans-serif'] = "SimHei"xx = np.arange(0, 40)
yy = xx
plt.xlabel('ground truth', fontsize=14)
plt.ylabel('infer result', fontsize=14)
plt2.plot(xx, yy)
plt2.scatter(y_test, y_predict, color='green')
plt2.grid()
plt2.show()
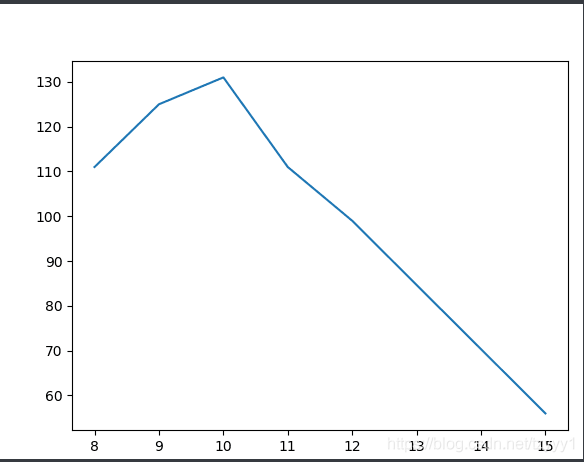
所得图像如下:


根据预测值和真实值的对比图,其中线性回归模型的决定系数为0.62907,说明线性关系可以解释房价的62.907%。
7.其他模型预测波士顿房价:
岭回归
岭回归是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。
from sklearn.linear_model import RidgeCV
rr = RidgeCV(alphas=np.array([.1, .2, .3, .4]))
rr.fit(X_train,y_train)
rr_y_predict = rr.predict(X_test)score_rr = r2_score(y_test,rr_y_predict)
score_rr

lasso回归:
LASSO是由1996年Robert Tibshirani首次提出,全称Least absolute shrinkage and selection operator。该方法是一种压缩估计。它通过构造一个惩罚函数得到一个较为精炼的模型,使得它压缩一些回归系数,即强制系数绝对值之和小于某个固定值;同时设定一些回归系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。
lassr = linear_model.Lasso(alpha=.0001)
lassr.fit(X_train,y_train)
lassr_y_predict=lassr.predict(X_test)score_lassr = r2_score(y_test,lassr_y_predict)
print(score_lassr)

SVR回归
from sklearn.svm import SVR
svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=.1) #高斯核
svr_lin = SVR(kernel='linear', C=100, gamma='auto') #线性核
svr_poly = SVR(kernel='poly', C=100, gamma='auto', degree=3, epsilon=.1,coef0=1) #径向基核函数
svr_rbf_y_predict=svr_rbf.fit(X_train, y_train).predict(X_test)
score_svr_rbf = r2_score(y_test,svr_rbf_y_predict)
svr_lin_y_predict=svr_lin.fit(X_train, y_train).predict(X_test)
score_svr_lin = r2_score(y_test,svr_lin_y_predict)
svr_poly_y_predict=svr_poly.fit(X_train, y_train).predict(X_test)
score_svr_poly = r2_score(y_test,svr_poly_y_predict)
8.模型可视化:
#绘制真实值和预测值对比图
def draw_infer_result(groud_truths,infer_results):title='Boston'plt.title(title, fontsize=24)x = np.arange(-0.2,2)y = xplt.plot(x, y)plt.xlabel('ground truth', fontsize=14)plt.ylabel('infer result', fontsize=14)plt.scatter(groud_truths, infer_results,color='green',label='training cost')plt.grid()plt.show()draw_infer_result(y_test,lr_y_predict)
draw_infer_result(y_test,rr_y_predict)
draw_infer_result(y_test,lassr_y_predict)
draw_infer_result(y_test,svr_rbf_y_predict)
draw_infer_result(y_test,svr_lin_y_predict)
draw_infer_result(y_test,svr_poly_y_predict)
print("score of lr:",score_lr)
print("score of rr:",score_rr)
print("score of lassr:",score_lassr)
print("score of svr_rbf:",score_svr_rbf)
print("score of svr_lin:",score_svr_lin)
print("score of svr_poly:",score_svr_poly)波士顿房价预测数据集和相关文档可通过本页面下载:
https://download.csdn.net/download/weixin_47686861/40769250