对于数据分析师来说,数据获取通常有两种方式,一种是直接从系统本地获取数据,另一种是爬取网页上的数据,爬虫从网页爬取数据需要几步?总结下来,Python爬取网页数据需要发起请求、获取响应内容、解析数据、保存数据共计4步。
本文使用Python爬取去哪儿网景点评论数据共计100条数据,数据爬取后使用Tableau Public软件进行可视化分析,从数据获取,到数据清洗,最后数据可视化进行全流程数据分析,下面一起来学习。
示例工具:anconda3.7
本文讲解内容:数据获取、数据可视化
适用范围:网页数据获取及评论分析
网页数据爬取
Python爬取网页数据需要发起请求、获取响应内容、解析数据、保存数据共计4步,懂的数据爬取的原理后,进行数据爬取。

1、发起请求
以去哪儿旅行网站为例,爬取网页数据,首先发送请求。
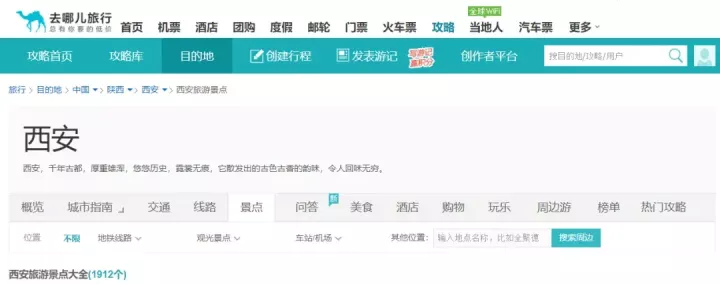
import requests
u='https://travel.qunar.com/p-cs300100-xian-jingdian'#爬取网址
response=requests.get(u)
print('状态码:{}'.format(response.status_code))
if response.status_code != 200:pass
else:print("服务器连接正常")
这里返回状态码为200,说明服务器连接正常,可以进行数据爬取。
2、获取响应内容
服务器连接正常后,直接打印返回内容,这里返回整个网页html。
print(response.text)
3、解析数据
网页结构由复杂的html语言构成,这里借助BeautifulSoup库进行解析。

from bs4 import BeautifulSoupri = requests.get(url=u)
soupi=BeautifulSoup(ri.text,'lxml')#解析网址
ul=soupi.find('ul',class_='list_item clrfix')
lis = ul.find_all('li')
lis
对于特定的标签进行定位,输出text。
print(soupi.h1.text)#标签定位,输出text
lis=ul.find_all('li')
print(lis[0].text)
建立一个字典,解析目标标签内容。
li1=lis[0]
dic={}
dic['景点名称']=li1.find('span',class_="cn_tit").text
dic['攻略提到数量']=li1.find('div',class_="strategy_sum").text
dic['评论数量']=li1.find('div',class_="comment_sum").text
dic['lng']=li['data-lng']
dic['lat']=li['data-lat']
dic
使用for循环解析标签内容。
import requests
from bs4 import BeautifulSoup
u1='https://travel.qunar.com/p-cs300100-xian-jingdian'
ri=requests.get(url= u1)soupi=BeautifulSoup(ri.text,'lxml')#解析网址
ul=soupi.find('ul',class_='list_item clrfix')
lis=ul.find_all('li')
for li in lis:dic={}dic['景点名称']=li.find('span',class_="cn_tit").textdic['攻略提到数量']=li.find('div',class_="strategy_sum").textdic['评论数量']=li.find('div',class_="comment_sum").textdic['lng']=li['data-lng']dic['lat']=li['data-lat']
print(dic)
根据翻页规律设置翻页数,这里设置一个列表,用来循环爬取前十页数据。
#根据翻页规律,设置翻页数
urllst=[]
for i in range(11):urllst.append('https://travel.qunar.com/p-cs300100-xian-jingdian'+str('-1-')+str(i))urllst=urllst[2:11]urllst.append('https://travel.qunar.com/p-cs300100-xian-jingdian')
urllst
4、保存数据
新建一个空的数据框,用于保存数据。
import pandas as pd
dic = pd.DataFrame(columns=["景点名称", "攻略提到数量", "评论数量", "lng", "lat"])
dic
在空的数据框中保存第一条数据,并且使用for循环,依次爬取其余页面的数据。
n=0
dic.loc[n, '景点名称'] = li.find('span', class_="cn_tit").text
dic.loc[n, '攻略提到数量'] = li.find('div', class_="strategy_sum").text
dic.loc[n, '评论数量'] = li.find('div', class_="comment_sum").text
dic.loc[n, 'lng'] = li['data-lng']
dic.loc[n, 'lat'] = li['data-lat']
dic
最后
如果对Python感兴趣的话,可以试试我的学习方法以及相关的学习资料
Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、精品Python学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、Python练习题
检查学习结果。

七、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


大家拿到脑图后,根据脑图对应的学习路线,做好学习计划制定。根据学习计划的路线来逐步学习,正常情况下2个月以内,再结合文章中资料,就能够很好地掌握Python并实现一些实践功能。