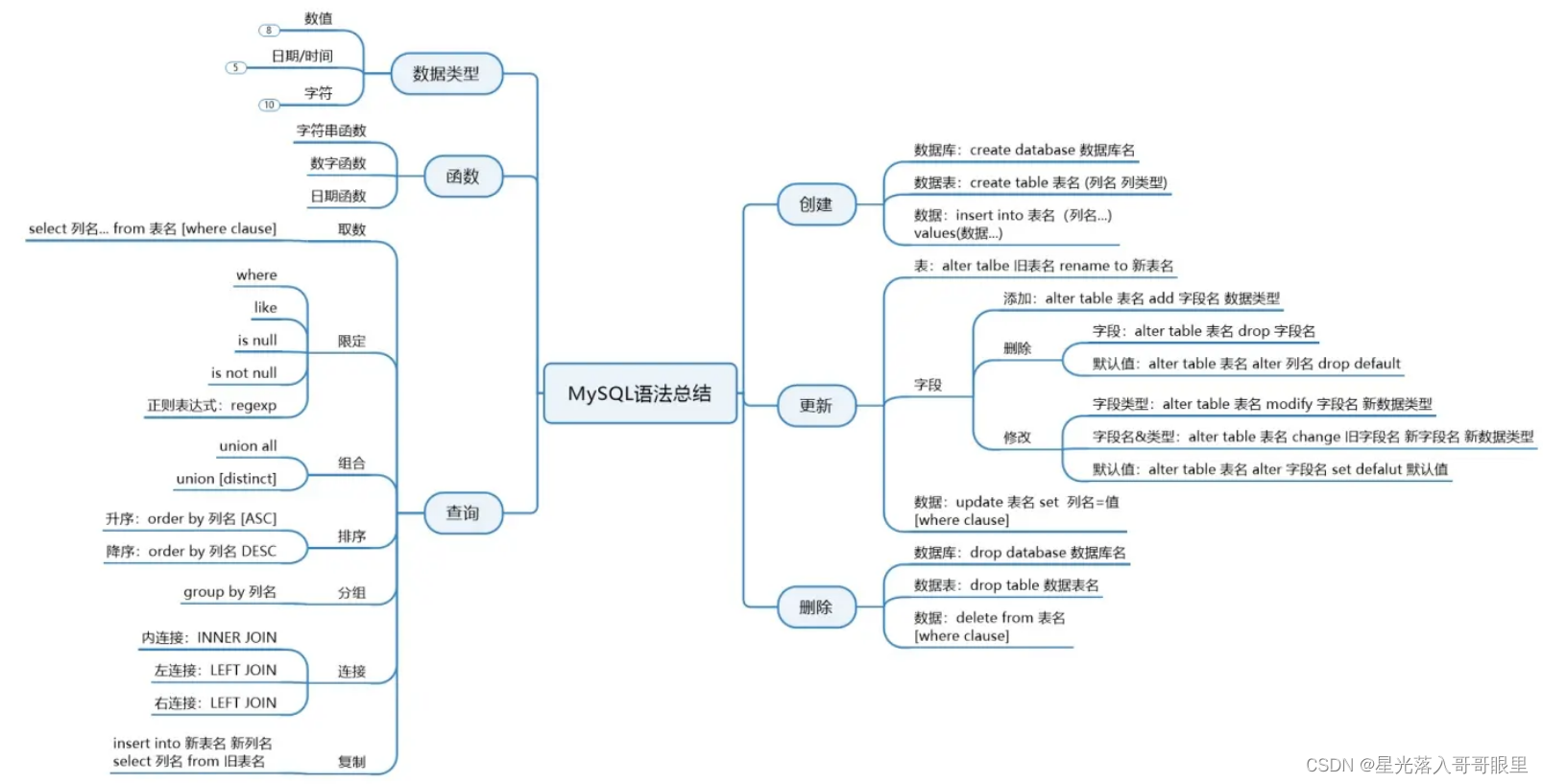
每周一期,纵览音视频技术领域的干货。
新闻投稿:contribute@livevideostack.com。

TCSVT 2022 | 基于环路多帧预测的深度视频压缩
本文基于端到端深度视频压缩框架,提出了一种环路多帧预测模块(in-loop frame prediction module),在不额外消耗码率的情况下,对当前帧实现基于多个参考帧的高效预测。
汇聚音视频新能量 探索行业新蓝海
作者从视频行业趋势和痛点出发,结合快手自身的探索、演进历程,分享技术变革和突破的思路,寻求行业新增长点。
英伟达Optical Flow SDK 为 Vulkan 带来加速运动处理
NVOFA是新型 NVIDIA GPU 上的专用硬件单元,用于以高性能计算一对图像之间的光流。NVIDIA Optical Flow SDK 公开了开发人员 API,使用户能够在应用程序中利用 NVOFA 硬件的强大功能。
https://developer.nvidia.com/blog/accelerated-motion-processing-brought-to-vulkan-with-optical-flow-sdk/

什么是语音识别?
介绍了语音识别技术的基本概念、工作原理和应用场景。此外,作者还提到了一些开源和商业语音识别解决方案,如Google Cloud Speech-to-Text和Twilio Autopilot等。
https://www.twilio.com/blog/what-is-speech-recognition
为什么我们能判断声音的远近
本文探讨了双耳听觉在距离感知方面的重要性。并详细介绍了四个关键参数——声压级、直达声与混响声能量之比、频谱和双耳差异对距离感知的影响。
王博聊声学 | 音频主观评价方法 – MUSHRA
本文从音频感知的主观属性、评价方法、客观参数测量等方面与大家共同探讨技术挑战以及HBK的解决方案。

RedPajama 模型发布,万亿级数据且开源
Together 发布 RedPajama 项目,旨在创建一套领先的全开源模型。目前,该项目已完成了第一步,成功复制了 LLaMA 训练数据集超过 1.2 万亿个数据 token。
https://www.together.xyz/blog/redpajama
ICLR 2023杰出论文奖得主独家分享:适配任意密集预测任务的通用小样本学习器
当计算机视觉模型学会了“举一反三”
对话Peter Lee:大模型在医疗健康领域应用的机遇与挑战
近期在微软研究院最新的 AI 前沿系列播客节目中,Peter Lee 与微软研究院副总裁、微软杰出首席科学家 Ashley Llorens 进行了一次深度对话,表达了他对于大模型在医疗健康领域应用潜力和挑战的看法,以及在大模型潮流的引领下,微软研究院对未来计算的研究规划。
10万月薪,大模型疯狂抢人
有业内人士预计:“国内能够进行相关技术研发的人才应该不超过1000人,保守一点来说仅有两三百号人。”但粗略计算下来,目前市场上已经存在几十个大模型项目了。抢人大战,燃起来了。
梁建章:人工智能如何影响经济和各行各业
未来的问题,不是人工智能能够干什么,而是人类选择会让人工智能干什么。
如何与孩子聊ChatGPT:AI大时代的完整版家长指南
供每一位关心时代变革与孩子成长的家长备查。
迈向「大」和「统一」的视觉神经网络架构设计新思路
基础模型创新是视觉发展的核心源动力
大语言模型综述
中国人民大学高瓴人工智能学院教师和学生调研了大语言模型的最新研究进展和主要技术路径,形成本领域的综述文章一篇,引用或介绍了相关论文420余篇,期望能为各位研究人员和工程人员提供一定的技术参考。
钉钉接入千问大模型,称未来将全面智能化
在千问大模型面世一周后,钉钉确认接入千问。目前,钉钉与大模型融合场景正在测试中,将在相关安全评估完成后上线。
解决深度学习中遇到的各种问题——自动微分方法——JAX(Just Another XLA)
相比于目前广泛使用的自动微分方法,JAX有更高的灵活性和可扩展性,并且可以在多个平台上运行,包括CPU、GPU和TPU等。JAX的另一个优势是能够支持一些基于源代码生成的编程语言,例如Python、NumPy和SciPy等。
https://ai.googleblog.com/2023/04/beyond-automatic-differentiation.html
DeepSpeed使用指南(简略版)
本文旨在简要地介绍Deepspeed进行大规模模型训练的核心理念,以及最基本的使用方法。
http://e.betheme.net/article/show-1318637.aspx?action=onClick
AI研究知识小组
AI主流工具合集,包含chatgpt、Midjourney和AI绘画和视频等。
https://zl49so8lbq.feishu.cn/wiki/wikcnLrLDTYCm2uxYKqzCVnCr1c
全球最大的 ChatGPT 开源替代品来了,支持 35 种语言
不用费心买 ChatGPT Plus了。
Google组建“Magi”项目组,将发布全新AI驱动的搜索引擎
新的搜索引擎将为用户提供比Google现有搜索服务更加个性化的体验,并试图预测用户的需求。目前,Google公司已经组建了一支由设计师、工程师和高管组成的团队,负责打造这个全新的搜索引擎。
拥有“意识”的AI:如何让大语言模型具备自我意识?
为了更好地探究意识与人工智能的关系,张江老师梳理了人类意识研究、意识理论与建模、自指与意识机器、以及自模拟意识机器等话题。
OpenAI的CEO表示,巨型AI模型的时代已经结束
他认为,由于大规模预训练的模型需要消耗大量的计算资源和能源,并且存在数据隐私和环境可持续性等问题,因此未来的AI技术发展将会转向小型、更具可解释性和更加环保的模型。
https://www.wired.com/story/openai-ceo-sam-altman-the-age-of-giant-ai-models-is-already-over/
梯度视角下的LoRA:简介、分析、猜测及推广
DINOv2:在没有监督的情况下学习强健的视觉特征
https://github.com/facebookresearch/dinov2
什么是涌现?

麻省理工学院专家探讨生成式AI,应该谦虚对待模型的潜能并还需要继续学习
AIGC如何用于推荐?中科大最新《生成式推荐: 迈向下一代推荐系统新范式》论文
这篇论文提出了一种新的生成式推荐系统范式GeneRec,它通过结合content generation和instruction guidance来服务用户的个性化信息需求。此外,作者还强调了多种fidelity checks的重要性,以确保生成内容的可信度。
揭秘 Auto-GPT 喧嚣背后的残酷真相!
Auto-GPT 究竟是一个开创性的项目,还是一个被过度炒作的 AI 实验?本文为我们揭开了喧嚣背后的真相,并揭示了 Auto-GPT 不适合实际应用的生产局限性。
AdobeFirefly也开始支持视频了
Adobe将生成式AI带入视频编辑,让算法辅助用户生成想要的视频效果
英伟达发布音频转视频模型LDMs
https://research.nvidia.com/labs/toronto-ai/VideoLDM/
微软开源“傻瓜式”类ChatGPT模型训练工具,成本大大降低,速度提升15倍
Deep Speed Chat 是基于微软 Deep Speed 深度学习优化库开发而成,具备训练、强化推理等功能,还使用了 RLHF(基于人类反馈的强化学习)技术,可将训练速度提升 15 倍以上,而成本却大大降低。

Amazon EC2 Inf2 已经正式上线,提供低成本、高性能的生成式 AI 推理服务。
详细地介绍了 Inf2 实例的特点和优势,为使用者提供了有用的指导和建议,使其更好地利用 Inf2 实例来进行生成式 AI 推理。
https://aws.amazon.com/cn/blogs/aws/amazon-ec2-inf2-instances-for-low-cost-high-performance-generative-ai-inference-are-now-generally-available/
英特尔的 Core i5 处理器是目前最具性价比的 CPU 之一,但哪一个是更适合你的?
作者提到,Core i5 处理器在价格和性能之间找到了很好的平衡点,可以满足大多数用户的需要。然而,不同型号的 Core i5 处理器有着不同的规格和特点,例如核心数量、时钟频率、缓存容量等,需要根据自己的使用需求和预算做出选择。
https://arstechnica.com/gadgets/2023/04/intels-core-i5-is-the-best-bargain-in-cpus-right-now-but-which-should-you-get/
全球首款3nm芯片,正式发布
据Marvell介绍,公司在该节点中的业界首创硅构建模块包括 112G XSR SerDes(串行器/解串行器)、Long Reach SerDes、PCIe Gen 6 / CXL 3.0 SerDes 和 240 Tbps 并行芯片到芯片互连。

亚马逊 CEO 表示 AWS 员工现在将“大部分时间”花在优化客户的云上
贝佐斯表示AWS正在构建一个更加安全、可靠、高效、环保的云计算基础设施,同时也在扩展新的产品和服务以满足客户需求。
https://www.theregister.com/2023/04/17/amazon_annual_shareholder_letter_aws/

PAG 4.2 版本正式发布:新增 3D 图层与视频替换能力,大幅优化 UI 播放性能
PAG 4.2 版本新增支持了大家需求比较强烈的 3D 图层,针对需要同时播放多个 PAG 动效的 UI 及列表场景进行了优化,同时在视频后编辑和素材加密等垂直领域进行了封装,满足特定场景的用户需求。
使用Flux.jl进行图像分类
AI模型技术国家标准正式发布 全球标准体系布局基本成型

BP-EVD:一种实时性视频去噪方法
本文基于深度学习的视频去噪方法,巧妙安排了时域上数据的利用方式,实现了高质量的实时视频去噪。

如何系统的学习机器视觉技术?
文章是部分机器视觉方面知识汇总,建议想学习的同学收藏。

元宇宙场景下的实时互动RTI技术能力构建
LiveVideoStack 2022北京站邀请到了 ZEGO 即构科技的解决方案专家许明龙,为我们介绍 ZEGO 在元宇宙场景中的底层技术能力构建。

Edison如何帮助我们在网络上构建更快、更强大的Dropbox
Dropbox为未来十年重写了其核心网络服务堆栈:停用在过去13年中累积的技术债务,并将高流量表面迁移到一个经过未来化改进的平台,以便适应公司的多产品演进。
https://dropbox.tech/frontend/edison-webserver-a-faster-more-powerful-dropbox-on-the-web

NAB展区详解
介绍了NAB的展位和新技术,有兴趣的可以观看。
https://www.sportsvideo.org/2023/04/19/sportstechbuzz-at-nab-2023-wednesdays-latest-from-vegas/
2023春季火山引擎“FORCE·原动力”大会
4月18日,由火山引擎主办的2023春季火山引擎“FORCE·原动力”大会在上海召开。本次大会全方位地展示火山引擎在云技术、云服务和云场景方面的最新探索、应用与实践,呈现创新发展的战略蓝图。

BlikVM的开源KVM-over-IP解决方案
它可以让你在使用Raspberry Pi CM4或Allwinner H616处理器的设备上,通过网络远程控制和管理其他计算机。BlikVM由一款基于树莓派HAT设计的PCIe板卡驱动,这个板卡提供了将视频信号和USB输入/输出通过网络传输的功能。
https://www.cnx-software.com/2023/04/18/blikvm-open-source-kvm-over-ip-raspberry-pi-cm4-raspberry-pi-hat-pcie-board-allwinner-h616/
CNCF 模糊测试开源项目的安全性和可靠性
CNCF项目的介绍、结果以及两个目标:1. 扩展现有设置以包含更多模糊器并将更多项目集成到 OSS-Fuzz 中;2. 通过增加维护者的参与和教育来提高模糊测试工作的可持续性。
https://www.cncf.io/blog/2023/04/18/cncf-fuzzing-open-source-projects-for-security-and-reliability/

2023视频编解码现状
虽然HEVC是高效的编解码器,但因为其使用费用和专利限制等原因,AV1正在成为一个更加流行的选择。
https://www.streamingmedia.com/Articles/Editorial/Featured-Articles/The-State-of-Video-Codecs-2023-158116.aspx
CVPR 2019 | 实用的全分辨率学习无损图像压缩
本文提出了第一个实用的学习无损图像压缩系统 L3C,并表明它优于流行的工程编解码器 PNG、WebP 和 JPEG2000。
非线性矢量变换编码-全新编码框架的探索
提出了一种VQ码本初始化策略,解决了多级VQ难以联合优化的问题。

英伟达悄然垄断算力:人工智能背后的新帝国
算力的扩张与通用、技术的开发与布局,是英伟达成功的因由。
日本如何利用AI来解决老人出行问题
东京羽田机场推出自动行驶的轮椅,用来给年老和行动不便的乘客使用,实现从安检口到乘机口之间自动驾驶。
活动推荐

LiveVideoStackCon 2023上海站 讲师招募中
LiveVideoStackCon是每个人的舞台,如果你在团队、公司中独当一面,在某一领域或技术拥有多年实践,并热衷于技术交流,欢迎申请成为LiveVideoStackCon的讲师。请提交演讲内容至邮箱:speaker@livevideostack.com。
https://sh2023.livevideostack.cn/

【公开课】开放XCDN直播方案设计与实践
4月25日 19:00,我们邀请到了百度智能云视频云技术架构师 柯于刚老师为大家介绍一种基于HTTP/3协议的直播方案,并详细解析如何采用统一协议协同使用云、边、端各级资源,采用开放式架构实现多厂商服务互通,以及如何高效利用复杂的边缘资源,实现视频的快速加载、稳定播放。
时间: 2023年4月25日 19:00
2023年4月25日 19:00
报名: 扫描图中二维码或点击【阅读原文】预约报名,观看直播!
扫描图中二维码或点击【阅读原文】预约报名,观看直播!