作者:Naresh Ram翻译:王闯(Chuck)
校对:zrx本文约6600字,建议阅读10+分钟
本文通过实例展示了大语言模型(LLM)在数据清洗中的惊艳之处。文章详细介绍了如何利用提示、API调用和自动化代码,以低成本实现数据清洗,并展示了其在提升数据质量和发掘洞察方面的巨大潜力。标签:数据科学、数据清洗、大语言模型、LLM
使用OpenAI的GPT模型清理调查问卷反馈。完整代码已上传至Github链接(https://github.com/aaxis-nram/data-cleanser-llm-node)。

图片由Dall-E 2生成并由作者修改
在数字时代,准确可靠的数据对企业来说至关重要。这些数据为企业提供个性化的体验,并帮助他们做出明智的决策[1]。然而,由于庞大的数据量和复杂度,处理数据常常面临重大挑战,需要进行大量枯燥且手动的工作。在这种情况下,大语言模型(LLM)应运而生,这项变革性技术具备了自然语言处理和模式识别的能力,有望彻底改变数据清洗的过程,使数据更具可用性。
在数据科学家的工具箱中,LLM就像是扳手和螺丝刀,能够重塑活动并发挥作用,以提升数据质量。就像谚语中说的一锤定音,LLM将揭示出可行的洞见,最终为创造更好的客户体验铺平道路。
现在,让我们直接进入今天的案例。

图片由Scott Graham上传至Unsplash
案例
当对学生进行调查问卷时,将事实字段设为自由形式的文本是最糟糕的选择!你可以想象我们收到的一些回答。
开个玩笑,我们的客户之一是Study Fetch(https://www.studyfetch.com/),这是一个AI驱动的平台,利用课程材料为学生创建个性化的全方位学习套件。他们在大学生中进行了一项调查,收到了超过10,000个反馈。然而,他们的首席执行官兼联合创始人Esan Durrani遇到了一个小问题。原来,在调查中,"主修"字段是一个自由形式的文本框,这意味着回答者可以输入任何内容。作为数据科学家,我们知道这对于进行统计计算来说绝对不是一个明智的选择。所以,从调查中获得的原始数据看起来像这样...

天了噜,让你的Excel准备好吧!准备好花上一个小时,甚至三个小时的冒险来对付这些数据异类。
但是,别担心,我们有一把大语言模型(LLM)的锤子。
正如一位长者所言,假如你只有一把锤子,那么所有的问题都会像是钉子。而数据清洗工作难道不正是最适合这把锤子的任务吗?
我们只需要简单地使用我们友好的大语言模型将它们归类到已知的类别中。特别是,OpenAI的生成式预训练Transformer(GPT)模型,正是当下流行的聊天机器人应用ChatGPT背后的LLM。GPT模型使用了高达1750亿个参数,并且已经通过对来自公开数据集Common Crawl的26亿个存储网页进行训练。此外,通过一种称为从人类反馈中的强化学习(RLHF)的技术,训练者可以推动并激励模型提供更准确和有用的回答[2]。
对于我们的目标来说,我相信超过1750亿个参数应该足够了,只要我们能给出正确的提示(prompt)。

图片由Kelly Sikkema上传至Unsplash
关键在于提示语
来自某AI公司的Ryan和Esan,他们的主要业务是编写出色的提示语。他们提供了我们的提示语的第一个版本。这个版本很棒,使用语言推断[3]效果非常好,但有两个可以改进的地方:
首先,它仅适用于单个记录。
其次,它使用了达芬奇模型的'Completion'方法(一提到它,我的银行账户就开始恐慌)。
这导致了过高的成本,这是我们无法接受的。因此,Ryan和我分别使用'gpt-3.5-turbo'重新编写了提示语,以便进行批量操作。对我来说,OpenAI的提示语最佳实践(https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-openai-api)和ChatGPT Prompt Engineering for Developers课程(https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/)非常有帮助。经过一系列思考、实施、分析和改进的迭代,我们最终获得了一个出色的工作版本。
现在,让我们马上展示经过第二次修订后的提示语:

对这个提示语,LLM给的回应是:

这个方法或多或少会有些效果。但我并不太喜欢那些重复的、长篇大论的项目名称。在LLM中,文本就是tokens,tokens就是真金白银啊。你知道,我的编程技能是在互联网泡沫破裂的火热深渊中锻炼出来的。让我告诉你,我从不放过任何一次节省成本的机会。
因此,我在“期望的格式”部分略微修改了提示语。我要求模型只输出调查反馈的序数(例如,上面的戏剧为1)和项目的序数(例如,文学为1)。然后Ryan建议我应该要求输出JSON格式而不是CSV,以便更简单地解析。他还建议我添加一个“示例输出”部分,这是一个极好的建议。
最终的提示语如下(为清晰起见,已简化):

我们使用的完整提示语可以在这里的GitHub链接(https://github.com/aaxis-nram/data-cleanser-llm-node)上查看。
模型的输出结果是:
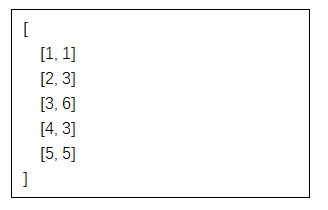
所以,正如我们之前讨论的,模型的输出是我们定义的类别与调查响应的序数之间的映射。以第一行为例:1,1。这意味着1是响应编号,1是相应的映射程序编号。调查响应1是“戏剧”,映射的程序1是“文学与人文”。这看起来很正确!戏剧在它应有的#1位置,成为了所有人的焦点。
虽然输出结果乍看之下像是嵌入的输出(用于聚类和降维),但它们只是相同的映射信息,只不过是序数位置。除了在token使用上提供一些成本优势外,这些数字还更容易解析。
我们现在可以把原始的调查反馈文件转换为有意义的专业,做聚合,获得有价值的可操作的洞察。
但等等,我不打算坐在电脑前,把每一块调查反馈输入浏览器并计算映射。这除了令人头脑麻木,错误率也是无法接受的。
我们需要的是一些好的自动化工具。让我们来看看API...

图片由Laura Ockel上传至Unsplash
API救世主
可能你已经知道,应用程序接口(API)使我们的程序能够高效地与第三方服务进行交互。尽管许多人通过使用ChatGPT实现了令人印象深刻的成果,但语言模型的真正潜力在于利用API将自然语言能力无缝地集成到应用程序中,使用户感觉不到它的存在。就像你正在用来阅读这篇文章的手机或电脑背后的令人难以置信的科学技术。
如果你还没有API权限,你可以在这里申请,https://openai.com/blog/openai-api [4]。一旦你注册并获得你的API密钥,规格可以在这里(https://platform.openai.com/docs/api-reference/chat)找到。一些非常有帮助的例子和代码样本可以在这里(https://platform.openai.com/examples)找到。在你实际应用前,playground(API测试平台,https://platform.openai.com/playground)是一个很好的功能,用来在各种设置下测试提示语 [5]。
我们将使用REST来调用chat completion API。调用的示例如下:

我们快速看一下参数及其效果。
模型
到目前为止,对公众开放的聊天完成模型只有gpt-3.5-turbo。Esan可以使用GPT 4模型,我对此非常嫉妒。虽然gpt-4更准确,且出现错误的可能性更小[2],但它的成本大约是gpt-3.5-turbo的20倍,对于我们的需求来说,gpt-3.5-turbo完全足够了,谢谢。
温度(temperature)
temperature是我们可以传递给模型的最重要的设置之一,仅次于提示。根据API文档,它可以设置在0和2之间的值。它有着显著的影响[6],因为它控制输出中的随机性,有点像你开始写作前体内的咖啡因含量。你可以在这里找到一个对于每个应用可以使用的值的指南[7]。
对于我们的用例,我们只想要没有变化的输出。我们希望引擎给我们原封不动的映射,每次都是相同的。所以,我们使用了0的值。
N值
生成多少个聊天完成选择?如果我们是为了创造性写作并希望有多个选择,我们可以使用2或者3。对于我们的情况,n=1(默认)会很好。
角色
角色可以是system(系统)、user(用户)或assistant(助手)。系统角色提供指令和设定环境。用户角色代表来自最终用户的提示。助手角色是基于对话历史的响应。这些角色帮助构造对话,并使用户和AI助手能够有效地互动。
模型最大Token
这不一定是我们在请求中传递的参数,尽管另一个参数max_tokens限制了从聊天中获取的响应的总长度。
首先,token可以被认为是一个词的一部分。一个token大约是英语中的4个字符。例如,被归于亚伯拉罕·林肯(Abraham Lincoln)和其他人的引语“The best way to predict the future is to create it”包含了11个token。

图片来自Open AI Tokenizer,由作者生成
如果你认为一个token就是一个词,那么这里有一个64个token的例子,可以显示它并非那么简单。

图片来自Open AI Tokenizer,由作者生成
做好准备,因为现在要揭示一个令人震惊的事实:每个你在消息中使用的表情符号都会额外增加高达6个重要令牌的成本。没错,你喜爱的笑脸和眨眼都是偷偷摸摸的小令牌窃贼!😉💸
模型的最大token窗口是一种技术限制。你的提示(包括其中的任何额外数据)和答案必须适应模型的最大限制。在对话完成的情况下,内容、角色和之前的所有消息都会占用token。如果你从输入或输出(助手消息)中删除一条消息,模型将完全失去对它的了解[8]。就像多丽在寻找奇科时,没有法比奥,没有宾果,没有哈波,没有艾尔莫?... 尼莫!
对于gpt-3.5-turbo,模型的最大限制是4096个token,或大约16000个字符。对于我们的示例来说,提示大约占用2000个字符,每个调查反馈平均约20个字符,映射反馈约为7个字符。因此,如果我们在每个提示中放入N个调查反馈,最大字符数应为:
2000 + 20N + 7N应小于16000。
解这个等式后,我们得到一个小于518或大约500的N值。从技术角度来说,我们可以在每个请求中放入500个调查反馈,并处理我们的数据20次。然而,我们选择在每个反馈中放入50个反馈,并进行200次处理,因为如果我们在单个请求中放入超过50个调查反馈,我们会偶尔收到异常响应。有时候,服务可能会出现问题!我们不确定这是一个系统的长期问题,还是我们碰巧遇到了不幸的情况。
那么,我们该如何使用我们拥有的API呢?让我们进入精彩部分,代码。

图片由Markus Spiske上传至Unsplash
代码的方法
Node.js是一个JavaScript运行环境[9]。我们将编写一个Node.js/JavaScript程序,它将按照这个流程图所描述的动作执行操作:
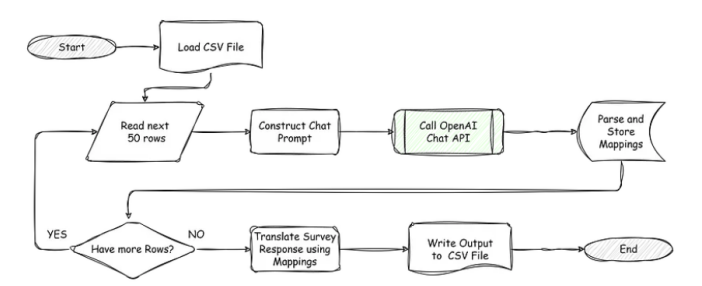
程序的流程图,由作者绘制
我的Javascript技能并不是那么出色。我可以写更好的Java,PHP,Julia,Go,C#,甚至Python。但是Esan坚持使用Node,所以就用Javascript吧。
完整的代码,提示和样本输入可以在这个GitHub链接(https://github.com/aaxis-nram/data-cleanser-llm-node)中找到。然而,让我们先看一下最吸引人的部分:
首先,让我们看看我们如何使用“csv-parser” Node库来读取CSV文件。

接下来,我们调用分类器来生成映射。

然后,我们从类别、主提示文本以及CSV中的数据构造出提示。接着,我们使用他们的 OpenAI Node 库将提示发送给服务。

最后,当所有迭代都完成后,我们可以将 srcCol 文本(即调查反馈)转换为 targetCol(即标准化的项目名称),并写出CSV。

这点 JavaScript 并没有我预期的那么复杂,而且在2到3小时内就完成了。我想,任何事情在你开始做之前总是看起来令人生畏的。
所以,现在我们已经准备好了代码,是时候进行最终的执行了…

图片由Alexander Grey上传至Unsplash
执行过程
现在,我们需要一个地方来运行这个代码。在争论是否应该在云实例上运行负载之后,我做了一些快速的计算,意识到我可以在我的笔记本电脑上在不到一个小时内跑完。这还不算太糟糕。
我们开始进行一轮测试,并注意到该服务在10次请求中有1次会返回提供给它的数据,而不是映射数据。因此,我们只会收到调查反馈的列表。由于没有找到映射,CSV文件中的这些反馈将被映射为空字符串。
为了避免在代码中检测并重试,我决定重新运行脚本,但只处理目标列为空的记录。
脚本会先将所有行的目标列设为空,并填入规范化的程序名称。由于响应中的错误,一些行的目标列不会被映射,保持为空。当脚本第二次运行时,它只会为第一次运行中未处理的响应构建提示。我们运行了几次程序,并将所有内容都映射出来。
多次运行大约花费了30分钟左右,并且不需要太多监督。以下是模型中一些更有趣的映射的精选:
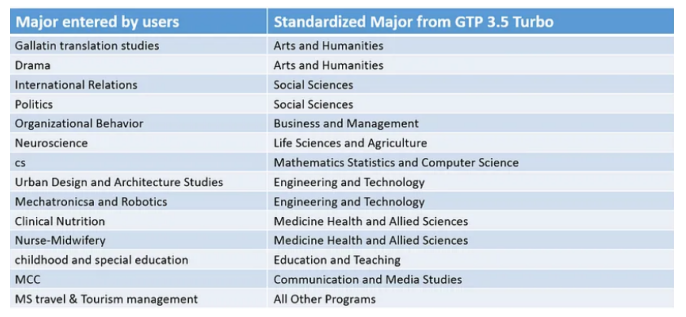
输入与程序名称之间的样例映射,图表由作者绘制
大多数看起来都对。不确定组织行为(Organizational Behavior)是否属于社会科学(Social Sciences)或商业(Business)?我想任何一个都可以。
每个大约50条记录的请求总共需要大约800个token。整个练习的成本是40美分。我们可能在测试、重新运行等方面花费了10美分。所以,总成本大约是50美分,大约2.5小时的编码/测试时间,半小时的运行时间,我们完成了任务。
总成本:大约不到1美元
总时间:大约3小时
或许手动使用Excel进行转换,排序,正则表达式,和拖拽复制,我们可能在相同的时间内完成它,并节省了一点小钱。但是,这样做更有趣,我们学到了东西,我们有了可以重复的脚本/流程,并且还产出了一篇文章。而且,我觉得StudyFetch可以负担得起50美分。
这是我们以高效率,高收益的方式实现的一个很好的应用,但LLM还可以用于哪些其他用途呢?

图片由Marcel Strauß上传至Unsplash
探索更多的用例
将语言功能添加到你的应用程序中可能有比我上面所示更多的用例。以下是与我们刚刚查看的评论数据相关的更多用例:
数据解析和标准化:LLM可以通过识别和提取非结构化或半结构化数据源(如我们刚刚看到的数据源)中的相关信息,帮助解析和标准化数据。
数据去重:LLM可以通过比较各种数据点来帮助识别重复记录。例如,我们可以在评论数据中比较姓名、专业和大学,以标记潜在的重复记录。
数据摘要:LLM可以对不同的记录进行摘要,以了解回答的概况。例如,对于问题“在学习过程中你面临的最大挑战是什么?”,一个大语言模型可以对来自同一专业和大学的多个回答进行摘要,以查看是否存在任何模式。然后,我们可以将所有的摘要放入一个请求中,得到一个整体的列表。但我猜每个客户细分的摘要可能会更有用。
情感分析:LLM可以分析评论以确定情感,并提取有价值的见解。对于问题“你愿意为帮助你学习的服务付费吗?”,LLM可以将情感分类为0(非常负面)到5(非常正面)。然后,我们可以利用这一点通过细分分析学生对付费服务的兴趣。
尽管学生评论只是一个微小的示例,但这项技术在更广泛的领域中有着多种应用。在我所在的AAXIS公司,我们专注于企业和消费者数字商务解决方案。我们的工作包括将大量数据从现有的旧系统迁移到具有不同数据结构的新系统。为了确保数据的一致性,我们使用各种数据工具对源数据进行分析。这篇文章中介绍的技术对于这个目标非常有帮助。
其他数字商务用例包括检查产品目录中的错误、编写产品说明、扫描评论回复和生成产品评论摘要等等。相比询问学生的专业,编写这些用例的代码要简单得多。
然而,需要注意的是,尽管LLM在数据清洗方面是强大的工具,但它们应与其他技术和人工监督相结合使用。数据清洗过程通常需要领域专业知识、上下文理解和人工审核,以做出明智的决策并保持数据的完整性。LLM并不是推理引擎[10],它们只是下一个词的预测器。它们往往以极大的自信和说服力提供错误的信息(幻觉)[2][11]。在我们的测试中,由于我们主要涉及分类,我们没有遇到任何幻觉的情况。
如果您谨慎行事并了解其中的陷阱,LLM可以成为您工具箱中强大的工具。

图片由Paul Szewczyk上传至Unsplash
尾声
在这篇文章中,我们首先研究了数据清洗的一个具体应用案例:将调查问卷反馈规范化为一组特定的值。这样做可以将反馈进行分组并获得有价值的见解。为了对这些反馈进行分类,我们使用了OpenAI的GPT 3.5 Turbo,一个强大的LLM。我们详细介绍了使用的提示、如何利用API调用来处理提示以及实现自动化的代码。最终,我们成功地将所有组件整合在一起,以不到一美元的成本完成了任务。
我们是不是像拿着一把传说中的LLM锤子,找到了在自由文本形式的调查反馈中那颗完美闪亮的钉子?也许吧。更可能的是,我们拿出了一把瑞士军刀,用它剥皮并享用了一些美味的鱼肉。虽然LLM不是专门为此而设计的工具,但仍然非常实用。而且,Esan真的非常喜欢寿司。
那么,你有什么LLM的用例呢?我们非常乐意听听你的想法!
鸣谢
本文的主要工作由我、Esan Durrani和Ryan Trattner完成,我们是StudyFetch的联合创始人。StudyFetch是一个基于人工智能的平台,利用课程资料为学生创建个性化的一站式学习集。
我要感谢AAXIS Digital的同事Prashant Mishra、Rajeev Hans、Israel Moura和Andy Wagner对本文的审查和建议。
我还要感谢我30年的朋友、TRM Labs的工程副总裁Kiran Bondalapati,感谢他在生成式人工智能领域的初期引导以及对本文的审阅。
同时,我要特别感谢我的编辑Megan Polstra,她一如既往地为文章增添了专业和精致的风格。
参考资料
1. Temu Raitaluoto, “The importance of personalized marketing in the digital age”, MaketTailor Blog, May 2023,https://www.markettailor.io/blog/importance-of-personalized-marketing-in-digital-age
2. Ankur A. Patel, Bryant Linton and Dina Sostarec, GPT-4, GPT-3, and GPT-3.5 Turbo: A Review Of OpenAI’s Large Language Models, Apr 2023, Ankur’s Newsletter,https://www.ankursnewsletter.com/p/gpt-4-gpt-3-and-gpt-35-turbo-a-review
3. Alexandra Mendes, Ultimate ChatGPT prompt engineering guide for general users and developers, Jun 2023, Imaginary Cloud Blog,https://www.imaginarycloud.com/blog/chatgpt-prompt-engineering/
4. Sebastian, How to Use OpenAI’s ChatGPT API in Node.js, Mar 2023, Medium — Coding the Smart Way,https://medium.com/codingthesmartway-com-blog/how-to-use-openais-chatgpt-api-in-node-js-3f01c1f8d473
5. Tristan Wolff, Liberate Your Prompts From ChatGPT Restrictions With The OpenAI API Playground, Feb 2023, Medium — Tales of Tomorrow,https://medium.com/tales-of-tomorrow/liberate-your-prompts-from-chatgpt-restrictions-with-the-openai-api-playground-a0ac92644c6f
6. AlgoWriting, A simple guide to setting the GPT-3 temperature, Nov 2020, Medium,https://algowriting.medium.com/gpt-3-temperature-setting-101-41200ff0d0be
7. Kane Hooper, Mastering the GPT-3 Temperature Parameter with Ruby, Jan 2023, Plain English,https://plainenglish.io/blog/mastering-the-gpt-3-temperature-parameter-with-ruby
8. OpenAI Authors, GPT Guide — Managing tokens, 2023, OpenAI Documentation,https://platform.openai.com/docs/guides/gpt/managing-tokens
9. Priyesh Patel, What exactly is Node.js?, Apr 2018, Medium — Free Code Camp,https://medium.com/free-code-camp/what-exactly-is-node-js-ae36e97449f5
10. Ben Dickson, Large language models have a reasoning problem, June 2022, Tech Talks Blog,https://bdtechtalks.com/2022/06/27/large-language-models-logical-reasoning/
11. Frank Neugebauer, Understanding LLM Hallucinations, May 2023, Towards Data Science,https://towardsdatascience.com/llm-hallucinations-ec831dcd7786
原文标题:From Chaos to Clarity: Streamlining Data Cleansing Using Large Language Models
原文链接:https://towardsdatascience.com/from-chaos-to-clarity-streamlining-data-cleansing-using-large-language-models-a539fa0b2d90
编辑:黄继彦
译者简介

王闯(Chuck),台湾清华大学资讯工程硕士。曾任奥浦诺管理咨询公司数据分析主管,现任尼尔森市场研究公司数据科学经理。很荣幸有机会通过数据派THU微信公众平台和各位老师、同学以及同行前辈们交流学习。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织