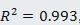学一门知识,充实自我 掌握一项工具,让生活更美好~今天flare老师教大家AI选股,轻松搭建一个年化收益40%的机器学习选股策略
—by flare zhao,转载请注明出处,原创不易,谢谢支持
话不多说,先看策略的最终表现:
2017年12月到2019年12月期间
为了让大家有个更直观的感受,我们来看看K线图及策略的净值曲线:
接下来,我们再来看看策略的具体交易情况:
考虑到文章篇幅限制,flare老师没有把所有的交易都列举出,我们可以看到,本策略并不是买了一只股票就不变化,而是会根据模型预测进行买入、卖出调仓。
看到这个结果是不是有些小激动,期待自己也能亲手跑一遍
Let’s start!
通常来说,搭建AI选股模型的核心有三点
- 确定基本逻辑,思考一个理智的投资者会从哪些方面去选择股票
- 逻辑代码化,基于实际数据建立并训练模型,进行预测
- 回测模型表现,表现好那就可以应用到实际交易中了
Wow,so easy对不对!
1、理清思路,确定假设条件
以我们今天的策略来举栗子:
- 投资者会根这里是斜体文字据股票公司的基本面信息(比如营业收入、基本每股收益 、净利润 、净资产收益率等等)来判断这个公司好不好,值不值得买!
- 除了基本面,中短期交易还会考虑公司最近的技术因子(比如相对强弱指数RSI、换手率、威廉指标等等),以此分析公司最近的市场追捧度,适不适合最近下手!
- 投资者对股票的选股方式会维持一段时间,比如说今天以某种策略买了A股并持有了一段日期,那明天我的选股策略不会有大的改变
这里,flare老师说到的因子数据我们都可以去网上获取到,大家如有需要可以在文章最后链接处下载。
数据有了,我们就来说说第三个假设,说白了,不就是建立一个模型把这个态度信息提取出来嘛!然后再利用这个态度信息去选择买/卖股票就可以了,是不是很简单!
到这里,你已经掌握了机器学习量化交易的核心。知识有了,接下来就是利用工具去检验知识。
我们先把代码的思路再理一理:
现实生活:今天我想买股票,想从沪深300的股票池中选一些好的标的,那我先看看上个月所有股票的表现,并且把股票表现和股票上个月的基本面、技术信息建立一个关系。当然了,信息那么多,让我自己去找怕是不行,那就交给计算机。
有了这个关系,我再看看股票池股票现在的基本面信息,然后预测下个月涨跌表现,买入会涨的,卖出会跌的,然后躺着赚钱??
思路清晰化:
1、读取沪深300所有股票20个交易日之前的信息X、前20个交易日区间的涨跌幅Y
2、数据预处理:对X、Y进行预处理,让其更适合于模型训练
3、建立并训练模型,再进行模型训练
光动脑子还不够,接下来我们一起动手实操一下:
1、载入数据
import pandas as pd
import numpy as np
data_train = pd.read_csv('data_train.csv')
data_train.head()
我们看看部分数据(股票代码、营业收入、每股收益等等,部分0数据通常是数据没有获取到导致的)
数据中,date表明了因子在当前日期的数据,y则是一个月后对应标的的涨跌幅。
我们以2017年12月7日的数据为例,对模型进行讲解
#分析日期
date = 20171207
data_train_temp = data_train[data_train['date'] == date]
#以股票代码进行数据索引
data_train_temp = data_train_temp.set_index(['stock_code'])
x_train = data_train_temp.drop(['date','y'],axis=1)
y_temp = data_train_temp.loc[:,'y']
y_temp.head()
2、数据预处理(为了防止模型过拟合,我们需要对输入因子进行降维处理;对y,我们根据涨跌幅是否大于4%,将数据分类两类,大于4%的标签为1,小于的为0.
如果不理解过拟合、降维、数据分类标签化处理,大家可以点击链接。
#引入依赖库
from sklearn.decomposition import PCA
from sklearn.preprocessing import MinMaxScaler
from sklearn.svm import SVC
y_temp = y_train.dropna()#缺省值去掉
y_temp_win = y_temp[y_temp>0.04] #筛选出收益率大于0.04的股票
y_temp_loss= y_temp[y_temp<=0.04]#筛选出收益率小于0.04的股票
#训练数据的y赋值,收益率大于4%的股票标签为1,否则为0
y_train = [1] * len(y_temp_win) + [0] * len(y_temp_loss)
#获取有正常数据的股票代码
code_train = list(y_temp_win.index)+list(y_temp_loss.index)
code_train = code_train
#提取股票的因子信息
x_train = x_train.loc[code_train].values
# 使用主成分分析,对数据作降维处理,提取四个关键的特征
nm_scaler= MinMaxScaler()
x_train = nm_scaler.fit_transform(x_train)
pca = PCA(n_components=4)
x_train = pca.fit_transform(x_train)
3、建立模型并训练、评估模型表现(这里我们使用在金融市场应用广泛的支持向量机SVM模型,flare老师会在以后的文章据具体介绍该模型)
# 构建模型,对模型进行训练
model=SVC(C=20000,kernel='rbf',gamma=1)
model.fit(x_train, y_train)
y_train_predict = model.predict(x_train)
#评估表现
from sklearn.metrics import accuracy_score,confusion_matrix
acc=accuracy_score(y_train,y_train_predict)
#cm = confusion_matrix(y_train,y_train_predict)
#print(cm)
print(acc)
模型准确率accuracy=85%,感觉效果还不错!当然,我们还可以通过一些其他指标来判断这个模型的表现,这里不做过于详细的陈述。
模型有了,意味着判断投资者对个股的情绪信息能够提取出来了,我们再利用这个模型去提取投资者现对于不同股票的投资情绪与意向,然后操作!
基本方法还是一样的,那就是读取当前日期的股票基本信息,然后预测未来一个月的标签是1还是0,1则表示预测该股票未来一个月涨幅超过4%,0则不会超过。
data_test = pd.read_csv('data_test.csv')
#分析日期
date = 20171227
data_test_temp = data_test[data_test['date'] == date]
#以股票代码进行数据索引
data_test_temp = data_test_temp.set_index(['stock_code'])
x_test = data_test_temp.drop(['date'],axis=1)
x_test = x_test.fillna(0)
x_test = x_test.values
# 使用主成分分析,对数据作降维处理,提取四个关键的特征
x_test = nm_scaler.transform(x_test)
x_test = pca.transform(x_test)
#预测
y_test_predict = model.predict(x_test)
#预测收益率大于0.04的股票
stock_selected = data_test_temp.index.values[y_test_predict==1]
print(stock_selected)
此时,模型帮我们从沪深300的300只股票池中,找出了超过40只未来一个与可能涨幅会超过4%的股票。
接下来,我们可以进一步思考
How if we get so many stocks???
资金有限,我们很难做到去购买所有的股票,可以进一步细化策略:
比如:
- 如果选用的模型会输出预测的概率,可以根据概率进行排序筛选;
- 事先约定,如果模型推荐的数量不多于m只(比如10只),那我们才进行操作
- 或者,我们还可以想想其他的筛选准则
到这里,我们只分析了一个日期的数据,为了帮助我们进一步优化策略,我们把之后每20个交易日进行一次分析
flare老师提醒大家一点,每一次分析,最好重新训练模型,因为随着时间推移,一年前的投资者偏好可能和一年后不同
我们来看看模型的分析与推荐结果(列举部分结果,数据在文章最后提供下载链接):
有了每个日期的结果,我们可以根据个人意愿优化策略,比如在这里,flare老师的计划是,如果当期推荐股票数量少于十只,那就进行操作:对推荐股票进行买入、调仓操作,不在推荐列表的股票进行卖出操作。
日期从前往后依次为2018年6月28日买入000063.SZ,2018年11月23、12月21
最后,我们再一次来看看策略的回测收益曲线:
看上去还是很nice的!
我们可以再细看模型推荐的标的:中兴通讯、中国平安、大族激光、五粮液、隆基股份,的确都是大家很熟悉业绩很不错的股票,买了就算短期回调,我们都还是很有信心的,看来推荐的标的还是很良心的。
除此之外,两年时间,总共只进行了16次操作,标的数量不超过10只,意味着:1、空仓期间,可以结合其他策略,产生更高收益;2、不必花费太多精力在调仓上,很省心。
做个小总结:
- 数据证明,AI选股是有价值的,能够帮助我们在大池子中找到优质标的
- AI金融没有想象中那么难,核心是思路的构建与工具的使用
flare老师再给几个小建议:
- 无论何时,投资有风险一定要记住,没有完美的模型,试想如果明天突然发生黑天鹅事件,股市短期下跌不可避免,我们要随时有所准备,做好资金管理;
- 大家市场说A股市场比不过美股,但认真去想,任何一个市场都有优质和垃圾标的,在A股,基本面好的股票最终总会在股价上有所反应,长期来看有效市场终归是有效市场。我们要做的,就是通过预先的数据去发现优质标的,接下来就交给时间吧。
文章收尾前,感谢国信证券iquant平台给予的免费试用机会,平台还有很多值得优化的地方,但已经是个很不错的工具了,有兴趣的小伙伴可以尝试一下。
附上感兴趣的小伙伴需要的数据链接: https://pan.baidu.com/s/1YQYAyo3A_jsIWC9WSW7Ntg
提取码: 8qz3
点赞转发,还可获得最后部分的程序源码~?
Finally:flare老师的实战课程“Python人工智能套餐课”已经上线,新课上线希望大家多多支持,和flare老师一起学习AI,掌握AI工具,解决实际问题。
「CSDN好物推荐」
技术转型,这两年一直是程序员圈子里的热门话题。对于大部分基层程序员来说,基础岗位上薪资的涨幅很难跟上年龄的增长。而近些年,AI技术发展势头迅猛,优秀人才短缺。在这种情况下,无疑是谁先转型成功,谁就占得职场先机。
而如何高效掌握人工智能则是目前大家最关注的。 本课程专为准备入门人工智能的小白打造,并结合初级AI工程师的能力模型以及学习路径设计的课程内容。
在课程中,老师将带你全面掌握:Python语法编程、人工智能核心数学理论、机器学习八大算法、深度学习与神经网络、计算机视觉,为你求职人工智能打下夯实的基础。
通过 6 大课程,5 大阶段,355 节视频课程的学习,带你系统掌握初级AI工程师的核心能力。
读后有收获可以扫码(不是加好友噢)请作者喝咖啡:
扫码有惊喜
还可以分享给朋友。