Mutual Information-Based Temporal Difference Learning for Human Pose Estimation in Video
- 前言
- 1. Background & Motivation
- 2, Methodology (Temporal Difference Learning based on Mutual Information, TDMI)
- 2.1 Feature Extractor
- 2.2 Multi-Stage Temporal Difference Encoder (TDE)
- 2.3 Representation Disentanglement Module(RDM)
- 2.4 Mutual Information Objective
- 3. Experiments
- 3.1 Compare with the State-of-the-art Methods
- 3.2 Ablation Studies
前言
今天跟大家分享一篇收录于CVPR2023,有关视频2D人体姿态估计的工作《Mutual Information-Based Temporal Difference Learning for Human Pose Estimation in Video》,拜读了本文,受益匪浅,现简要记录读后感。
本文的创新在于作者提出利用互信息表征学习方式,引导模型学习task-relevant的特征。众所周知,现阶段性能优越的深度模型是数据驱动,尤其近来ChatGPT等大预言模型相继问世,更是体现了数据对深度模型的重要性。但是,通常所用到的数据并不是理想的“干净”数据,其包含大量的噪声(无关信息)。因此,如何从冗余的无关信息中提取task-relevant特征,对于下游任务来讲尤为重要。 那么,如何实现上述目标?本文给出了一个可行的解决方案。下面我们具体来看。
文章简介:
出处: CVPR 2023
题目: 《Mutual Information-Based Temporal Difference Learning for Human Pose Estimation in Video》
作者: R u n y a n g F e n g Runyang Feng RunyangFeng, Y i x i n g G a o Yixing Gao YixingGao, X u e q i n g M a Xueqing Ma XueqingMa, T z e H o E l d e n T s e Tze Ho Elden Tse TzeHoEldenTse, and H y u n g J i n C h a n g Hyung Jin Chang HyungJinChang
单位: S c h o o l o f A r t i f i c i a l I n t e l l i g e n c e , J i l i n U n i v e r s i t y School of Artificial Intelligence, Jilin University SchoolofArtificialIntelligence,JilinUniversity; E n g i n e e r i n g R e s e a r c h C e n t e r o f K n o w l e d g e − D r i v e n H u m a n − M a c h i n e I n t e l l i g e n c e , M i n i s t r y o f E d u c a t i o n , C h i n a Engineering Research Center of Knowledge-Driven Human-Machine Intelligence, Ministry of Education, China EngineeringResearchCenterofKnowledge−DrivenHuman−MachineIntelligence,MinistryofEducation,China, and S c h o o l o f C o m p u t e r S c i e n c e , U n i v e r s i t y o f B i r m i n g h a m School of Computer Science, University of Birmingham SchoolofComputerScience,UniversityofBirmingham
文章地址: https://arxiv.org/pdf/2303.08475.pdf
项目地址:https://github.com/Pose-Group/TDMI 【开源ing…】
1. Background & Motivation
从文章的题目可以看出,本文提出了一个基于互信息的时间差学习方法用于解决视频中的人体姿态估计(Video-based Human Pose Estimation, V-HPE)问题。V-HPE任务的本质实则还是对人体姿态的时空建模问题。相比于图像数据,video数据提供了丰富的时序信息。基于图像的HPE方法近年来已经取得重大突破,那么对于V-HPE任务,如何有效建模视频中姿态的时序特征显得尤为重要。
现阶段V-HPE相关工作根据时序建模方式的不同,可以大致分为四类:LSTM(RNN)-based, Optical flow-based, 2D CNN-based以及3D CNN-based,如下图所示。哎?貌似常用的时序建模方法都用到V-HPE任务了。但是细想一下会发现,还有一种常用的运动信息建模方法没包括在这里面。那就是帧差法。 帧差法在其他任务中,如动作识别、超分等任务,取得了很显著的效果,但确实在V-HPE任务中很少人用帧差来建模姿态的动态信息。

与其他时序建模方法相比,帧差法能够保留目标的细节信息(如轮廓、纹理等)和一些attention的信息等,如下图。因此,帧差也能够为运动目标提供有效的动态信息,且提供了任务相关的特征区域。比如第2幅图,假设做HPE任务,帧差为我们提供了人体的一个区域,该区域是task-relevant的。

(这里可能有人会说,光流也可以起到同样的作用呀,甚至光流可以屏蔽背景等无用信息。对,确实时这样的。但是提取的光流信息不一定是perfect,尤其对于一些运动模糊、遮挡的区域,提到的光流是很模糊的,甚至是提取不到的。如下图(a)所示,对于运动模糊和被遮挡的右腿,光流信息直接丢失,导致最终模型定位出错。反观图(c)中的帧差特征,能够帮助模型关注于有效特征区域。)

上述时序建模方式各有千秋。但是呢,其存在一个共性的drawback,即在建模动态信息时会引入大量的任务不相关的信息(如相邻的人、背景信息等)。 下面对上述提到的方法进行稍微详细的解释,为什么会引入无关信息。
(1)对于LSTM-based方法,通常利用一个backbone提取每一帧的spatial features,然后将提取到的特征输入LSTM进行时序特征建模。在提取spatial feature时,是不区分前景、背景的,故整个输入图像的信息均被编码到一个feature中。因此,该过程会引入一些task-irrelevant信息。(2)对于Optical flow的方法,因为提取到的光流并不能跟目标区域完全match,同样会引入一些无关信息。(3)对于CNN-based方法,卷积具有权重共享以及平移不变性,对于同一个kernel,每次覆盖的区域权重是相同的。这就会导致,同一个kernel不同位置的像素被同等看待。但事实却非如此,我们更希望前景信息能得到更多的关注,而背景等无关信息被抑制。(4)对于帧差的方法,同样也会包含大量无关信息,如果仅通过简单的特征融合策略(如卷积模块融合),还是会不可避免的引入过多的无关信息。
因此,针对上述系列问题,本文从如何引导模型学习更多的task-relevant特征角度出发,提出了一种基于互信息的时间差学习方法来提高视频的人体姿态估计性能。具体来说,本文的主要Contribution如下:
- 提出了一个新的人体姿态估计框架——基于互信息的时间差学习模型(Temporal Difference Learning based on Mutual Infromation, TDMI)。TDMI主要包括两个关键模块:(1)多阶段时间差编码器(Multi-stage Temporal Difference Encoder, TDE)用于建模不同阶段特征的运动信息(PS:主要用于提取不同level特征的运动信息);(2)特征结构模块(Representation Disentanglement module, RDM)用于提取task-relevant的特征。
- 提出了一种特征解耦的学习策略,结合RDM模块与互信息表征学习方式,能够引导模型提取具有代表性的任务相关的运动信息。
- 在常用数据集PoseTrack2017, PoseTrack2018, PoseTrack2021以及HiEve上取得了最先进的结果。
2, Methodology (Temporal Difference Learning based on Mutual Information, TDMI)
本文的整体框架采用Top-dwon的处理方式,包括三部分:Feature Extraction, Multi-stage Temporal Difference Encoder 以及 Representation Disentanglement Module,如下图所示。下面将详细介绍每个component的操作。
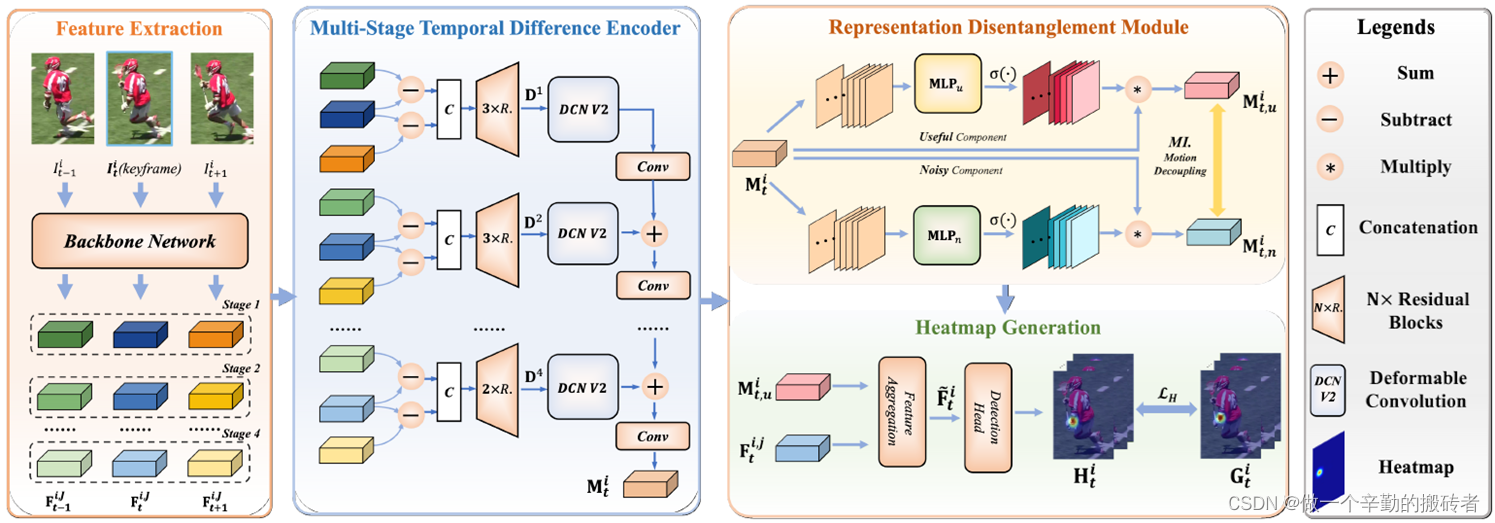
2.1 Feature Extractor
给定一段包含(2δ+1)帧的视频片段 X t = { I t − δ , ⋯ , I t , ⋯ , I t + δ } \mathcal{X}_t=\{I_{t-\delta},\cdots,I_{t},\cdots,I_{t+\delta}\} Xt={It−δ,⋯,It,⋯,It+δ},采用预训练目标检测模型从每一帧图像中crop出每个人,即 X t i = { I t − δ i , ⋯ , I t i , ⋯ , I t + δ i } \mathcal{X}_t^i=\{I_{t-\delta}^i,\cdots,I_{t}^i,\cdots,I_{t+\delta}^i\} Xti={It−δi,⋯,Iti,⋯,It+δi},其中, i i i表示第 i i i个人。【后续为了方便叙述,采用3帧为例进行说明】
直接对输入图像做帧差操作,会引入过多无用的信息,且得到的帧差质量较差。故本文首先采用预训练的backbone提取每帧图像的空间特征,基于空间特征构造帧差。作者采用预训练的backbone网络(文中采用的HRNet)来提取每个人的空间表征 { F t − 1 i , J , F t i , J , F t + 1 i , J } \{F_{t-1}^{i,J}, F_{t}^{i,J}, F_{t+1}^{i,J}\} {Ft−1i,J,Fti,J,Ft+1i,J},其中, J = { 1 , 2 , 3 , 4 } J=\{1,2,3,4\} J={1,2,3,4}表示HRNet 4个不同的stage。

2.2 Multi-Stage Temporal Difference Encoder (TDE)
基于Feature Extractor提取的空间特征,构造帧差特征。需要注意的是,对于backbone不同阶段提取的特征,包含的信息是不同的。比如,比较浅层的网络提取到的细节信息(轮廓、纹理等)比较丰富,而较深层的网络提取到的高级语义信息较为丰富。因此,为了获取更丰富的运动信息,作者对HRNet 3个stage提取到的空间特征均做了帧差操作。并对多stage的运动信息做了progressive融合,得到图像最终的运动特征 M t i M_{t}^i Mti(PS:因为这里的 M t i M_{t}^i Mti同时包含task-relevant和irrelevant的信息,故我理解其为图像的运动特征)。TDE模块主要包含4个步骤:feature difference sequence generation, intra-stage feature fusion, inter-stage feature fusion, 以及multi-stage feature fusion。
1. Feature Difference Sequence ( S t i , J = { S 1 , S 2 , S 3 , S 4 } \mathcal{S}_t^{i,J}=\{S^1, S^2, S^3, S^4\} Sti,J={S1,S2,S3,S4}) Generation(图中灰色框)
初始特征帧差的生成比较简单,直接对HRNet每个stage得到的空间特征做相邻帧的减法即可得到每个stage的特征帧差特征 S j S^j Sj,即
S j = { F t i , j − F t − 1 i , j , F t + 1 i , j − F t i , j } , j = { 1 , 2 , 3 , 4 } S^j = \{F_{t}^{i,j} - F_{t-1}^{i,j}, F_{t+1}^{i,j} - F_{t}^{i,j}\}, j = \{1, 2, 3, 4\} Sj={Fti,j−Ft−1i,j,Ft+1i,j−Fti,j},j={1,2,3,4}
2. Intra-stage Feature Fusion ( D t i , J = { D 1 , D 2 , D 3 , D 4 } \mathcal{D}_t^{i,J}=\{D^1, D^2, D^3, D^4\} Dti,J={D1,D2,D3,D4})(图中红色框)
基于提取到相邻帧的短时帧差特征 S t i , J \mathcal{S}_t^{i,J} Sti,J,做进一步的相对长时的动态信息提取。具体操作为将相邻两帧的帧差特征进行concate操作,然后通过一组Residual Block提取相对长时的运动特征,即
D j = C o n v [ ( F t i , j − F t − 1 i , j ) ⊕ ( F t + 1 i , j − F t i , j ) ] D^j = Conv[(F_{t}^{i,j} - F_{t-1}^{i,j}) \oplus(F_{t+1}^{i,j} - F_{t}^{i,j})] Dj=Conv[(Fti,j−Ft−1i,j)⊕(Ft+1i,j−Fti,j)]
其中, D j D^j Dj包含了连续3帧的运动信息。可以注意到,每个stage的帧差融合用到了不同数量的Residual Block(图中"3×R."的R表示Residual Block,3表示block的数量),因为对前几个stage来讲,底层的信息比较丰富,而后面的stage语义信息比较丰富,故在前几个stage多用几个残差模块提取相对高语义的特征信息有利于后续多阶段的运动信息融合(这里可以理解为将不同stage的运动信息映射到相对一致的特征空间中)。

3. Inter-stage Feature Fusion(图中绿色框)
得到每个stage的运动特征 D t i , J D_t^{i,J} Dti,J之后,需要考虑将不同stage的运动特征融合。由于不同stage提取的特征存在一定的gap,即包含的信息不同或者说特征空间不同。浅层网络提取的特征对应于浅层特征空间,相反深层网络对应于高语义特征空间。即使在步骤2采用了不同的Residual block进行统一的特征映射,但是不同stage的特征之间仍存在特征信息空间不对齐的问题。这个问题可以理解为:如何将深层特征的高级语义信息与底层特征提取到的纹理等信息一一对应起来。 该问题对于特征融合是比较关键的。
为了应对上述问题,作者在融合特征之前,采用了Deformable Convolution V2 (DCN V2)对不同stage的特征做了modulation。DCN V2包含两个关键参数 offset O \mathcal{O} O 和 scalar W \mathcal{W} W(这里不做过多介绍啦,大家感兴趣的话可以去看DCV V2的paper)。因此,作者采用两个convolution操作来回归 offset O \mathcal{O} O 和 scalar W \mathcal{W} W,如下

经过Deformable操作之后,网络能够注意到其他特征位置。用作者的话讲就是"output the spatially calibrated motion features of each stage"。
4. Multi-stage Feature Fusion(图中紫色框)
得到每个阶段calibrated特征之后,就要做多阶段的特征融合了。这里作者并没有将3个stage的运动特征直接concate或相加,而是采用一种渐进式的特征融合策略,即当前stage在和下一个stage融合之前,先经过一个卷积层,即

为什么采用渐进式的融合策略呢?这里我认为是保证不同stage在融合之前处于相同的特征空间(相同可能有点不确切,应该说比较类似的或相对统一的特征空间)。因为归根结底,不同stage出的特征还是存在一定gap的,缩小特征间的gap再进行融合是有必要的。(作者的消融实验也证实了这一点)
经过融合之后,最终得到了图像的运动信息 M t i M_t^i Mti(图中红色实线框)。上文也提到了,因为 M t i M_t^i Mti中包含了有用和无用的信息,所以这里我暂称它为图像的运动信息。
2.3 Representation Disentanglement Module(RDM)
为了促使网络学习更多的task-relevant特征,作者结合互信息(Mutual Information)提出了一个特征解耦模块(RDM),如下图所示,其主要包含两步操作:Representation factorization 和 Heatmap generation。
1. Representation Factorization
该操作主要是将图像运动特征 M t i M_t^i Mti中包含的有用信息 M t , u i M_{t,u}^i Mt,ui和噪声信息 M t , n i M_{t,n}^i Mt,ni分离开,并利用有用信息来引导模型学习task-relevant特征。因为要提取特征图中的有用/噪声信息,故需要一步操作做一个特征初始化。在这里,作者采用全局池化(GAP)和MLP来做通道注意力,利用通道注意力来突出重要的特征(注意这里是重要的特征,而不是有用特征),即

这里也就是采用了两个SE Block来对原特征做了两次通道注意力,分别获得有用特征 M t , u i M_{t,u}^i Mt,ui和噪声特征 M t , n i M_{t,n}^i Mt,ni。但是需要注意的是,这里若不配合互信息学习方式(图中红色框),只用SE Block是提取不到desired信息的,因为通过SE得到的特征依然会同时包括有用和无用信息。

2. Heatmap Generation
结合RDM学习到的task-relevant特征 M t , u i M_{t,u}^i Mt,ui和目标person的空间特征 F t i , j F_t^{i,j} Fti,j即可得到最终的关节点热图,即

这里 F t i , j F_t^{i,j} Fti,j作者采用的是HRNet第4个stage的输出特征。并且,在后续的实验中,作者分别采用了Keyframe,连续3帧的spatial特征进行融合。
2.4 Mutual Information Objective
互信息可以用来衡量一个随机变量 x 1 x_1 x1包含另一个随机变量 x 2 x_2 x2的信息量。其可以定义为以下形式:

其中, p ( x 1 , x 2 ) p(x_1, x_2) p(x1,x2)表示随机变量 x 1 x_1 x1和 x 2 x_2 x2的联合概率; p ( x 1 ) p(x_1) p(x1)和 p ( x 2 ) p(x_2) p(x2)是它们的边缘概率。因此,可以通过最小化有用特征和噪声特征之间的互信息来将两者分离开,即
m i n I ( M t , u i ; M t , n i ) min\ \mathcal{I}(M_{t,u}^i; M_{t,n}^i) min I(Mt,ui;Mt,ni)
上述公式可以衡量有用特征 M t , u i M_{t,u}^i Mt,ui中包含噪声特征 M t , n i M_{t,n}^i Mt,ni的信息量。理所应当,有用特征中包含的噪声信息越少越好。故通过上述最小化 M t , u i M_{t,u}^i Mt,ui和 M t , n i M_{t,n}^i Mt,ni的互信息可以将有用特征分离(如下图绿色框)。
实际应用中,我们希望useful特征 M t , u i M_{t,u}^i Mt,ui越多越好,相反,噪声信息越少越好。useful特征 M t , u i M_{t,u}^i Mt,ui来自于图像的运动特征 M t i M_{t}^i Mti。因此,若要 M t , u i M_{t,u}^i Mt,ui越多,需要让特征 M t i M_{t}^i Mti中包含的useful特征越多。为实现该目标,作者设计了如下的目标函数:
m a x I ( M t i ; M t , u i ) max\ \mathcal{I}(M_{t}^i; M_{t,u}^i) max I(Mti;Mt,ui)
通过最大化图像运动特征 M t i M_{t}^i Mti中useful特征的信息量,即可引导模型学习更多的useful信息(图中红色框)。

值得注意的是,上述两目标函数促使模型学习到更多的useful特征。但具体如何判定所学习到的特征是useful呢?这需要跟具体的任务建立联系。 换句话说,有利于定位关节点位置的特征可以视为useful特征,如人体区域。为了实现上述目标,作者提出了最小化task-irrelevant信息的目标函数:
m i n [ I ( M t , u i ; y t i ∣ F ~ t i ) + I ( F t i , j ; y t i ∣ F ~ t i ) ] min\ [\mathcal{I}(M_{t,u}^i; y_t^i|\tilde{F}_{t}^i) + \mathcal{I}(F_{t}^{i,j}; y_t^i|\tilde{F}_{t}^i)] min [I(Mt,ui;yti∣F~ti)+I(Fti,j;yti∣F~ti)]
其中, y t i y_t^i yti表示ground truth,也就是人体姿态label;“|”表示非操作; ( y t i ∣ F ~ t i ) (y_t^i|\tilde{F}_{t}^i) (yti∣F~ti)表示增强特征 F ~ t i \tilde{F}_{t}^i F~ti不含有label信息的特征区域,也就是task-irrelevant特征。因此, I ( M t , u i ; y t i ∣ F ~ t i ) \mathcal{I}(M_{t,u}^i; y_t^i|\tilde{F}_{t}^i) I(Mt,ui;yti∣F~ti) 和 I ( F t i , j ; y t i ∣ F ~ t i ) \mathcal{I}(F_{t}^{i,j}; y_t^i|\tilde{F}_{t}^i) I(Fti,j;yti∣F~ti)分别表示 M t , u i M_{t,u}^i Mt,ui和 F t i , j F_{t}^{i,j} Fti,j中含有的task-irrelevant信息量。通过最小化该两项objective,即可使useful运动特征 M t , u i M_{t,u}^i Mt,ui和空间表征 F t i , j F_{t}^{i,j} Fti,j学习更多的task-relevant特征(图中蓝色和紫色框)。
但是,作者提到,直接计算conditional MI是比较困难的(具体原因还未去看,大家感兴趣可以去参考文献一查究竟),因此,需要换一种近似的方式来逼近上述objective,如下:
I ( M t , u i ; y t i ∣ F ~ t i ) → I ( M t , u i ; y t i ) − I ( M t , u i ; F ~ t i ) I ( F t i , j ; y t i ∣ F ~ t i ) → I ( F t i , j ; y t i ) − I ( F t i , j ; F ~ t i ) \mathcal{I}(M_{t,u}^i; y_t^i|\tilde{F}_{t}^i) \rightarrow \mathcal{I}(M_{t,u}^i; y_t^i) - \mathcal{I}(M_{t,u}^i; \tilde{F}_{t}^i) \\ \mathcal{I}(F_{t}^{i,j}; y_t^i|\tilde{F}_{t}^i) \rightarrow \mathcal{I}(F_{t}^{i,j}; y_t^i) - \mathcal{I}(F_{t}^{i,j}; \tilde{F}_{t}^i) I(Mt,ui;yti∣F~ti)→I(Mt,ui;yti)−I(Mt,ui;F~ti)I(Fti,j;yti∣F~ti)→I(Fti,j;yti)−I(Fti,j;F~ti)
I ( M t , u i ; y t i ) \mathcal{I}(M_{t,u}^i; y_t^i) I(Mt,ui;yti)和 I ( F t i , j ; y t i ) \mathcal{I}(F_{t}^{i,j}; y_t^i) I(Fti,j;yti)表示useful运动特征 M t , u i M_{t,u}^i Mt,ui和空间特征 F t i , j F_t^{i,j} Fti,j中包含task-relevant的特征; I ( M t , u i ; F ~ t i ) \mathcal{I}(M_{t,u}^i; \tilde{F}_{t}^i) I(Mt,ui;F~ti)和 I ( F t i , j ; F ~ t i ) \mathcal{I}(F_{t}^{i,j}; \tilde{F}_{t}^i) I(Fti,j;F~ti)表示 M t , u i M_{t,u}^i Mt,ui和 F t i , j F_t^{i,j} Fti,j中包含的增强特征 F ~ t i \tilde{F}_{t}^i F~ti的信息量。两项相减之后,得到的即为 M t , u i M_{t,u}^i Mt,ui和 F t i , j F_t^{i,j} Fti,j包含的task-irrelevant的信息量。
综上所述,本文的MI Objective可以表示为上述思想objective的加和,即:

结合整体结构图来看,其中绿色框部分引导模型RDM模块提取图像运动特征 M t i M_t^i Mti的useful特征;红色部分引导模型TDE模块学到的运动特征 M t i M_t^i Mti中包含越多的有用信息;蓝色部分引导模型学到的useful特征 M t , u i M_{t,u}^i Mt,ui中包含更多的task-relevant信息;而紫色部分引导模型backbone学到的空间表征 F t i , j F_{t}^{i,j} Fti,j中包含更多的task-relevant信息。因此,通过 L M I \mathcal{L}_{MI} LMI分别对backbone、TDE和RDM模块进行了约束与引导,最终能够提取到desired task-relevant特征。

最后,模型的训练Loss采用关节点热图的MSE Loss和MI Loss,即:
L t o t a l = L H + α L M I L H = ∣ ∣ H t i − G t i ∣ ∣ 2 2 \mathcal{L}_{total} = \mathcal{L}_{H} + \alpha\mathcal{L}_{MI}\\ \mathcal{L}_{H} = ||H_t^i - G_t^i||_2^2 Ltotal=LH+αLMILH=∣∣Hti−Gti∣∣22
3. Experiments
3.1 Compare with the State-of-the-art Methods
作者分别在PoseTrack2017/2018/2021以及HiEve数据集上做了评估。实验结果如下:



其中,TDMI表示空间特征 F t i , j F_{t}^{i,j} Fti,j表示仅用Keyframe的空间表征;而TDMI-ST表示空间表征 F t i , j F_{t}^{i,j} Fti,j采用连续N帧的空间特征。从实验结果可以看出,采用连续N帧的空间表征相对于Keyframe的空间表征性能提升幅度不大。这可能是因为视频的语义一致性,相邻帧之间的appearance特征十分相似,用关键帧足以表征video clip的空间信息。

3.2 Ablation Studies
作者分别验证了TDMI的两个关键模块的有效性、TDE模块结构的有效性以及RDM模块结构的有效性。其中,比较有趣的是对TDE模块多阶段特征对齐的验证(即Table 6红色框),特征对齐操作给模型性能的提升最大。可以说明不同层、stage的特征间确实存在一定的gap,通过一定的操作减少这种gap再融合效果会更好。

以上内容纯粹是跟人的一己之见,如有不到之处,烦请指出,大家一起交流~ 另外,码字不易,转载请注明!
(PS:本人关注评论或私信不及时,如没有及时反馈大家,请大家谅解~可以多给我发几条私信。平时也比较忙,看到后会第一时间回复!谢谢)