文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 Yolov5算法
- 4 数据处理和训练
- 5 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 **深度学习卫星遥感图像检测与识别 **
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:5分

1 课题背景
近年来,世界各国大力发展航空航天事业,卫星图像的目标检测在各行各业的应用得到了快速的发展,特别是军事侦查、海洋船舶和渔业管理等领域。由于卫星图像中有价值的信息极少,卫星图像数据规模巨大,这迫切需要智能辅助工具帮助相关从业人员从卫星图像中高效获取精确直观的信息。
本文利用深度学习技术,基于Yolov5算法框架实现卫星图像目标检测问题。
2 实现效果
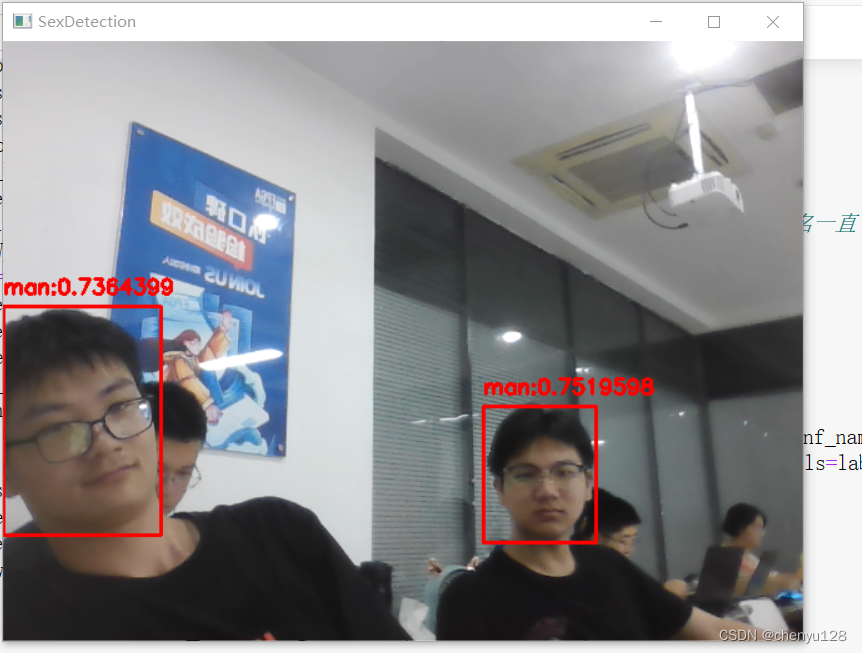
实现效果如下:可以看出对船只、飞机等识别效果还是很好的。



3 Yolov5算法
简介
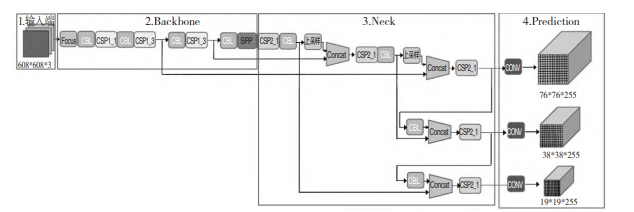
下图所示为 YOLOv5 的网络结构图,分为输入端,Backbone,Neck 和 Prediction 四个部分。其中,
输入端包括 Mosaic 数据增强、自适应图片缩放、自适应锚框计算,Backbone 包括 Focus 结构、CSP
结 构,Neck 包 括 FPN+PAN 结 构,Prediction 包 括GIOU_Loss 结构。
相关代码
class Yolo(object):def __init__(self, weights_file, verbose=True):self.verbose = verbose# detection paramsself.S = 7 # cell sizeself.B = 2 # boxes_per_cellself.classes = ["aeroplane", "bicycle", "bird", "boat", "bottle","bus", "car", "cat", "chair", "cow", "diningtable","dog", "horse", "motorbike", "person", "pottedplant","sheep", "sofa", "train","tvmonitor"]self.C = len(self.classes) # number of classes# offset for box center (top left point of each cell)self.x_offset = np.transpose(np.reshape(np.array([np.arange(self.S)]*self.S*self.B),[self.B, self.S, self.S]), [1, 2, 0])self.y_offset = np.transpose(self.x_offset, [1, 0, 2])self.threshold = 0.2 # confidence scores threholdself.iou_threshold = 0.4# the maximum number of boxes to be selected by non max suppressionself.max_output_size = 10self.sess = tf.Session()self._build_net()self._build_detector()self._load_weights(weights_file)
4 数据处理和训练
数据集
本项目使用 DOTA 数据集,原数据集中待检测的目标如下

原数据集中的标签如下

图像分割和尺寸调整
YOLO 模型的图像输入尺寸是固定的,由于原数据集中的图像尺寸不一,我们将原数据集中的图像按目标分布的位置分割成一个个包含目标的子图,并将每个子图尺寸调整为 1024×1024。分割前后的图像如所示。
分割前

分割后

模型训练
在 yolov5/ 目录,运行 train.py 文件开始训练:
python train.py --weight weights/yolov5s.pt --batch 16 --epochs 100 --cache
其中的参数说明:
- weight:使用的预训练权重,这里示范使用的是 yolov5s 模型的预训练权重
- batch:mini-batch 的大小,这里使用 16
- epochs:训练的迭代次数,这里我们训练 100 个 epoch
- cache:使用数据缓存,加速训练进程
相关代码
#部分代码
def train(hyp, opt, device, tb_writer=None):logger.info(f'Hyperparameters {hyp}')log_dir = Path(tb_writer.log_dir) if tb_writer else Path(opt.logdir) / 'evolve' # logging directorywdir = log_dir / 'weights' # weights directoryos.makedirs(wdir, exist_ok=True)last = wdir / 'last.pt'best = wdir / 'best.pt'results_file = str(log_dir / 'results.txt')epochs, batch_size, total_batch_size, weights, rank = \opt.epochs, opt.batch_size, opt.total_batch_size, opt.weights, opt.global_rank# Save run settingswith open(log_dir / 'hyp.yaml', 'w') as f:yaml.dump(hyp, f, sort_keys=False)with open(log_dir / 'opt.yaml', 'w') as f:yaml.dump(vars(opt), f, sort_keys=False)# Configurecuda = device.type != 'cpu'init_seeds(2 + rank)with open(opt.data) as f:data_dict = yaml.load(f, Loader=yaml.FullLoader) # data dictwith torch_distributed_zero_first(rank):check_dataset(data_dict) # checktrain_path = data_dict['train']test_path = data_dict['val']nc, names = (1, ['item']) if opt.single_cls else (int(data_dict['nc']), data_dict['names']) # number classes, namesassert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, opt.data) # check# Modelpretrained = weights.endswith('.pt')if pretrained:with torch_distributed_zero_first(rank):attempt_download(weights) # download if not found locallyckpt = torch.load(weights, map_location=device) # load checkpointif 'anchors' in hyp and hyp['anchors']:ckpt['model'].yaml['anchors'] = round(hyp['anchors']) # force autoanchormodel = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc).to(device) # createexclude = ['anchor'] if opt.cfg else [] # exclude keysstate_dict = ckpt['model'].float().state_dict() # to FP32state_dict = intersect_dicts(state_dict, model.state_dict(), exclude=exclude) # intersectmodel.load_state_dict(state_dict, strict=False) # loadlogger.info('Transferred %g/%g items from %s' % (len(state_dict), len(model.state_dict()), weights)) # reportelse:model = Model(opt.cfg, ch=3, nc=nc).to(device) # create# Freezefreeze = ['', ] # parameter names to freeze (full or partial)if any(freeze):for k, v in model.named_parameters():if any(x in k for x in freeze):print('freezing %s' % k)v.requires_grad = False# Optimizernbs = 64 # nominal batch sizeaccumulate = max(round(nbs / total_batch_size), 1) # accumulate loss before optimizinghyp['weight_decay'] *= total_batch_size * accumulate / nbs # scale weight_decaypg0, pg1, pg2 = [], [], [] # optimizer parameter groupsfor k, v in model.named_parameters():v.requires_grad = Trueif '.bias' in k:pg2.append(v) # biaseselif '.weight' in k and '.bn' not in k:pg1.append(v) # apply weight decayelse:pg0.append(v) # all else训练开始时的日志信息