一、数据分区
数据是以分区目录的形式组织的,每个分区独立分开存储.这种形式,查询数据时,可以有效的跳过无用的数据文件。
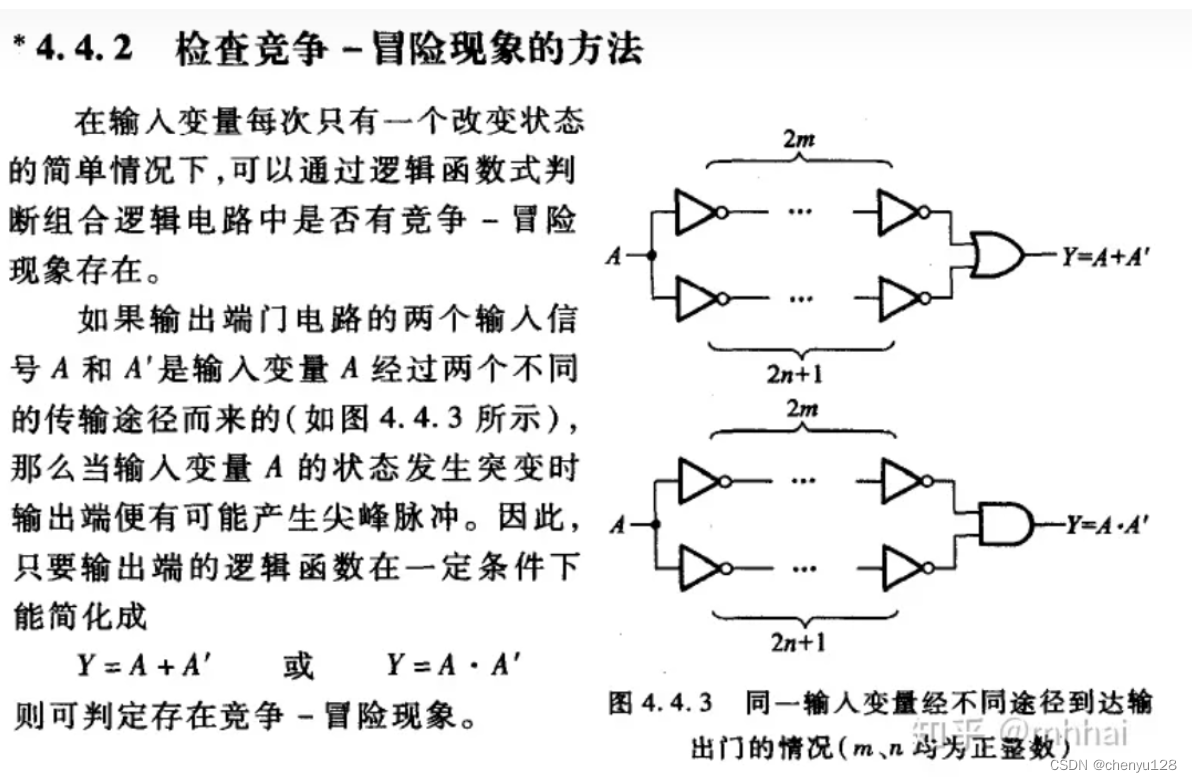
1.1 数据分区的规则
分区键的取值,生成分区ID,分区根据ID决定。根据分区键的数据类型不同,分区ID的生成目前有四种规则:
(1)不指定分区键
(2)整形
(3)日期类型(主要根据日期进行分区)
(4)其他类型
数据在写入时,会对照分区ID落入对应的分区
1.2分区目录的生成规则
partitionID_MinBlockNum_MaxBlockNum_Level
BlockNum是一个全局整型,从1开始,每当新创建一个分区目录,此数字就累加1。
MinBlockNum:最小数据块编号。
MaxBlockNum:最大数据块编号。
对于一个新的分区,MinBlockNum和MaxBlockNum的值相同: 2020_03_1_1_0,2020_03_2_2_0
*Level:合并的层级,即某个分区被合并过得次数。不是全局的,而是针对某一个分区。
1.3分区目录的合并过程
MergeTree的分区目录在数据写入过程中被创建。
不同的批次写入数据属于同一分区,也会生成不同的目录,在之后的某个时刻再合并(写入后的10-15分钟),合并后的旧分区目录默认8分钟后删除。
同一个分区的多个目录合并以后的命名规则:
。MinBlockNum:取同一分区中MinBlockNum值最小的
。MaxBlockNum:取同一分区中MaxBlockNum值最大的
·Level:取同一分区最大的Level值加1
二、索引文件
2.1 稀疏索引
primary.idx文件的一级索引采用稀疏索引。
稠密索引: 每一行索引标记对应一行具体的数据记录。
稀疏索引:每一行索引标记对应一段数据记录(默认索引粒度为8192)。

稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存,取用速度快!
2.2 一级索引
文件:primary.idx
MergeTree的主键使用Primary Key定义,主键定义之后,MergeTree会根据index granularity间隔(默认8192)为数据生成一级索引并保存至primaryidx文件中。这种方式是稀疏索引
**简化形式:通过order by指代主键**
2.3索引生成规则

三、 索引如何执行查询操作
索引的查询过程
索引是如何工作的?对primaryidx文件的查询过程**MarkRange:一小段数据区间**按照index granularity的间隔粒度,将一段完整的数据划分成多个小的数据段,小的数据段就是MarkRangeMarkRange与索引编号对应
案例
共200行数据
indexgranularity大小为5
主键ID为Int,取值从0开始
根据索引生成规则,primary.idx文件内容为:

执行过程


.bin 原始数据 .mark 索引映射

形成一个压缩块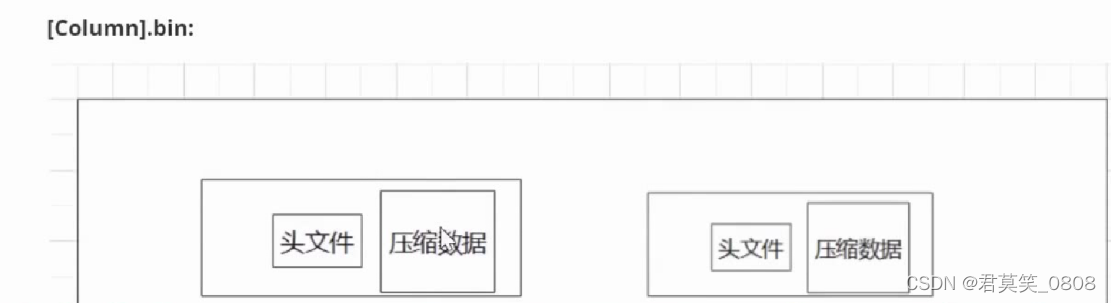
整体数据查询过程
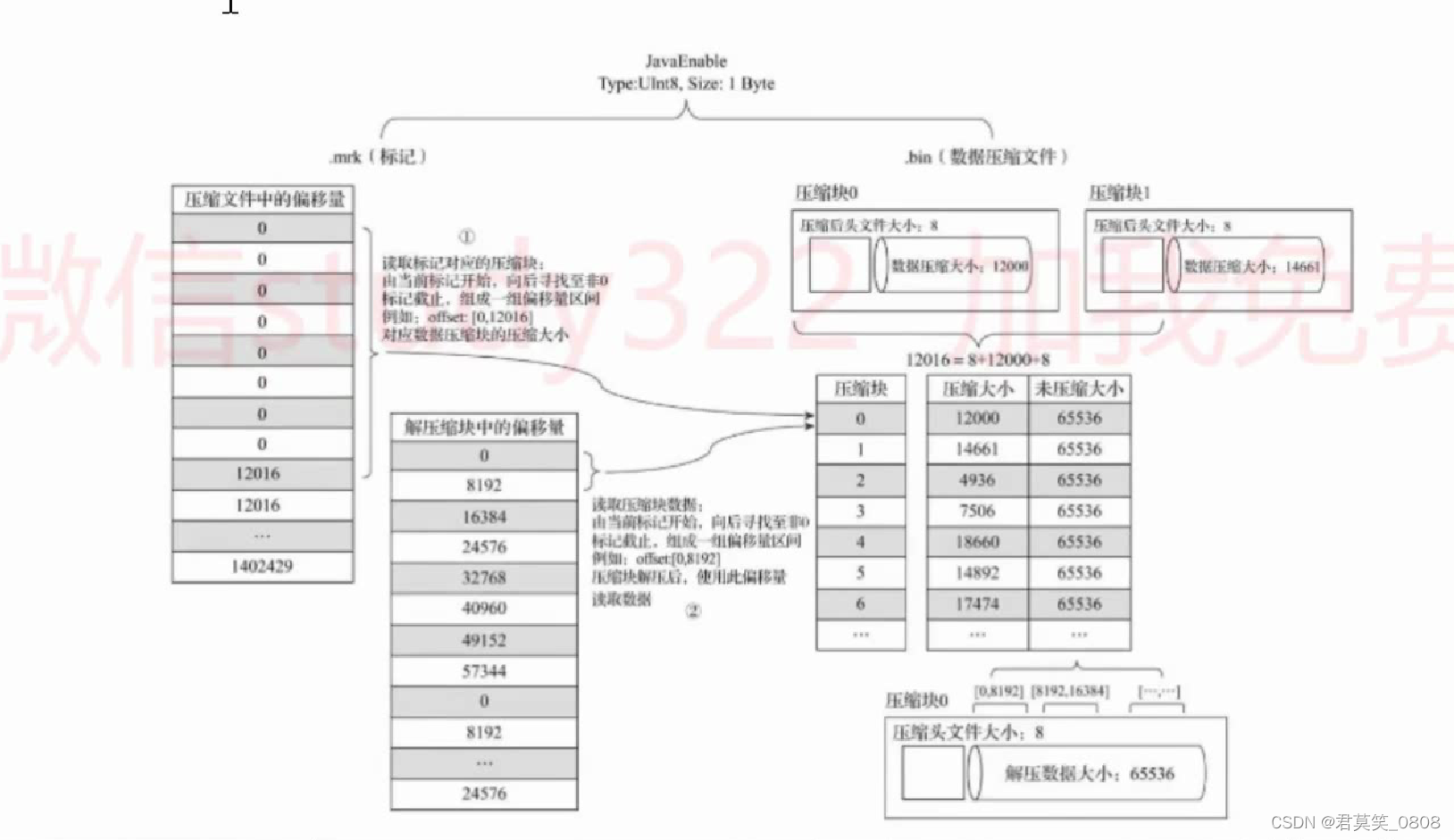

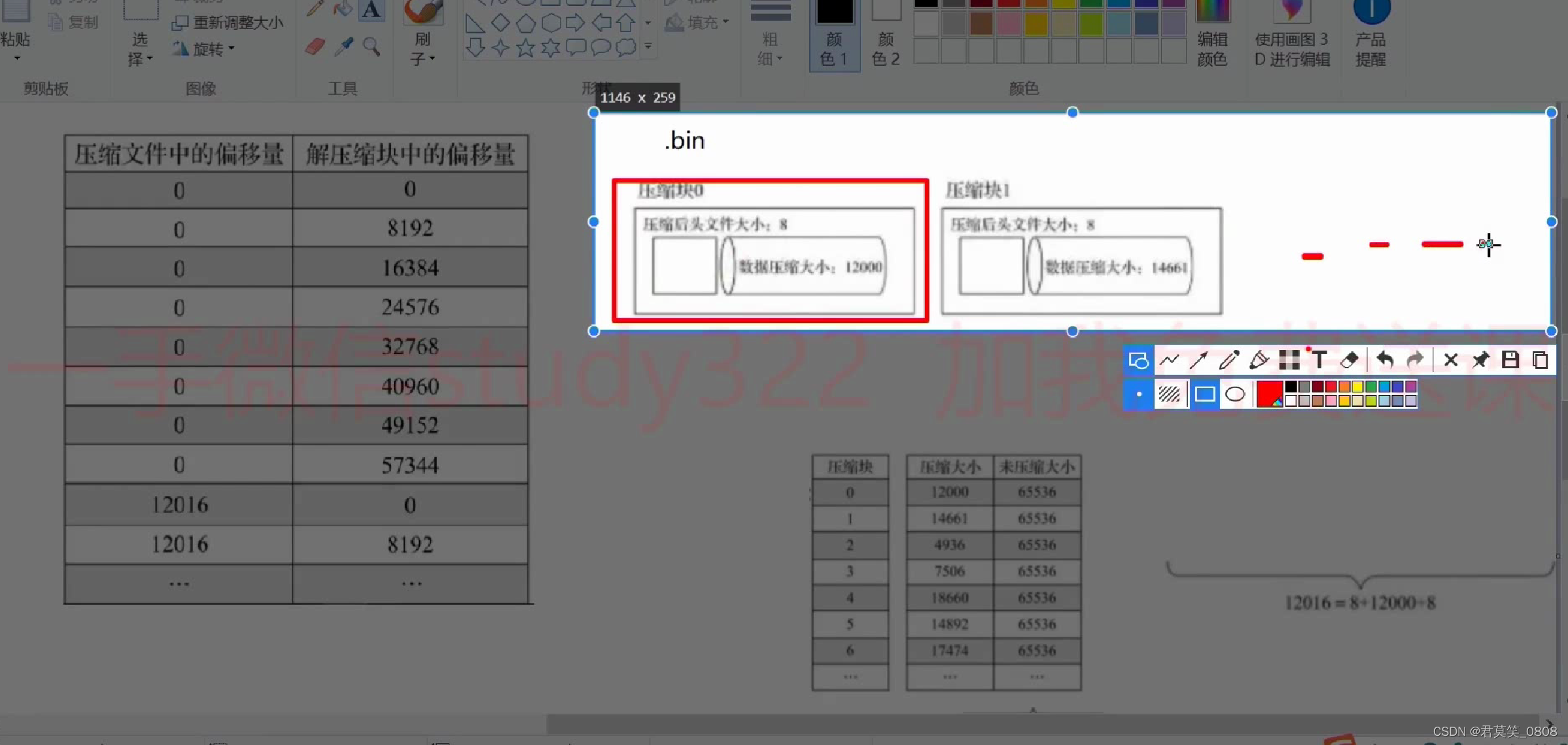
.bin文件形成多个压缩块->.mark文件找到压缩块 ->索引块->解压->再找数据

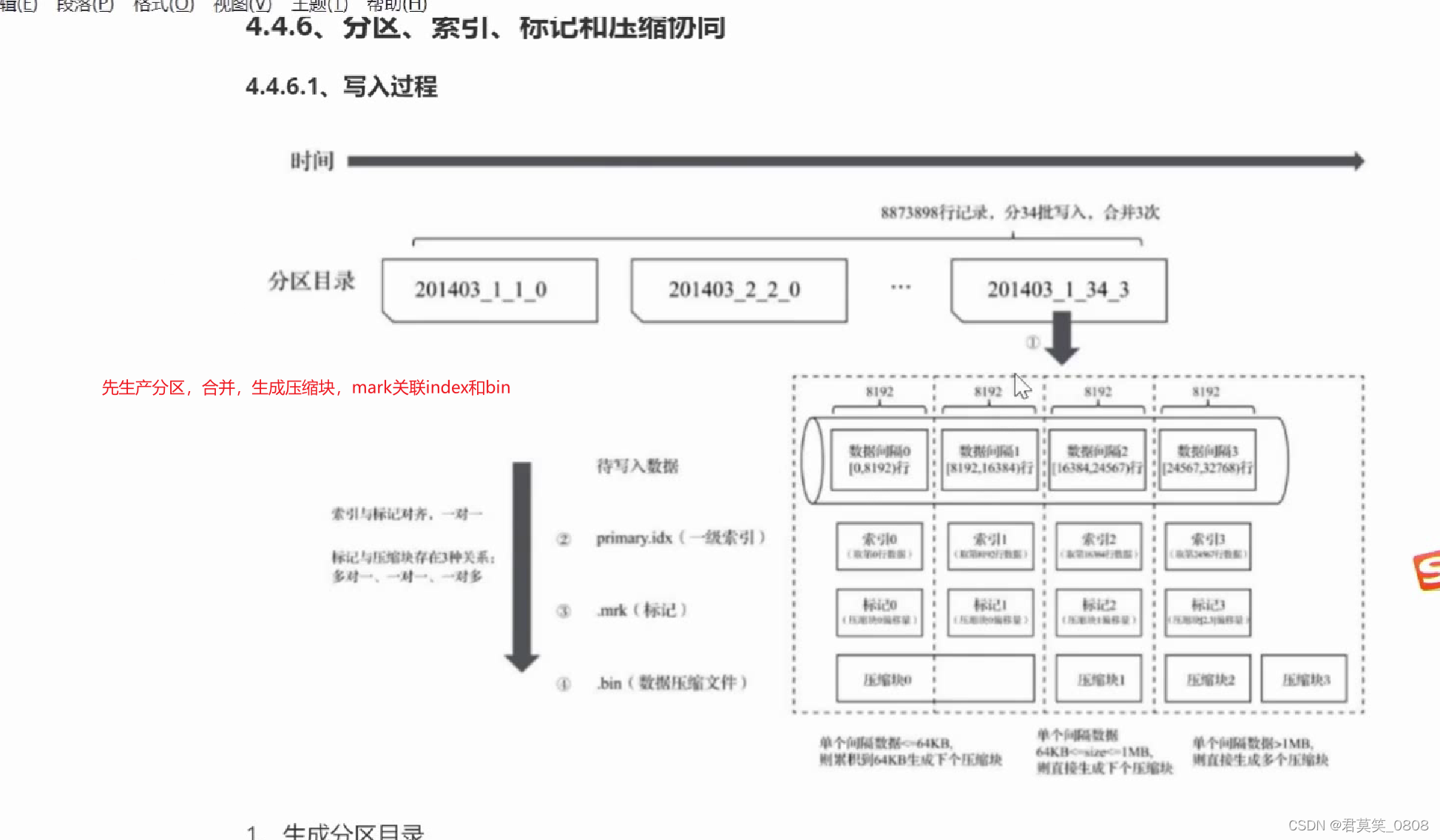
数据写入过程
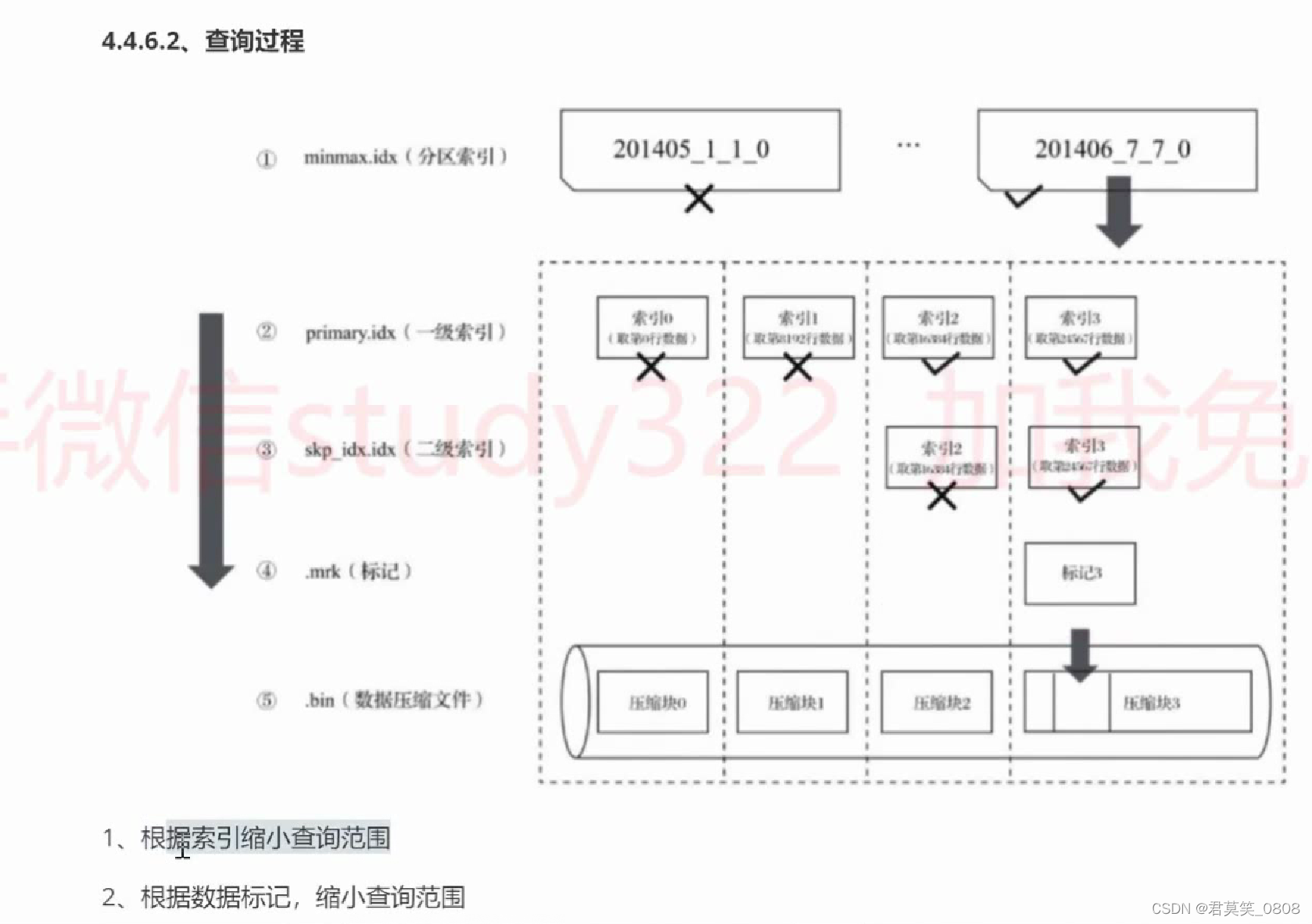
查询过程







![[excel]vlookup函数对相同的ip进行关联](https://img-blog.csdnimg.cn/18ac618a941446619fbdaa543bbdcb34.png)