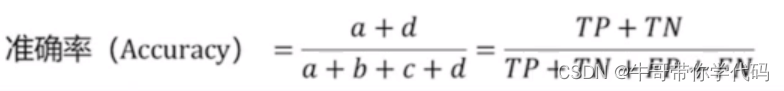1.1sklearn转换器和估计器
转换器和预估器(estimator)
1.1.1转换器
- 实例化一个转换器类 Transformer
- 调用fit_transform()
转换器调用有以下几种形式:
- fit_transform
- fit
- transform
1.1.2估计器
在sklearn中,估计器是一个重要的角色,是一类实现了算法的API
1、用于分类的估计器:
1)sklearn.neighbors k近邻算法
2)sklearn.native_bayes 贝叶斯
3)sklearn.linear_model.LogisticRegression 逻辑回归
4)sklearn.tree 决策树与随机森林
2、用于回归的估计器
1)sklearn.linear_model.LinearRegression 线性回归
2)sklearn.linear_model.Ridge 岭回归
3、用于无监督学习的估计器
1)sklearn.cluster.KMeans 聚类
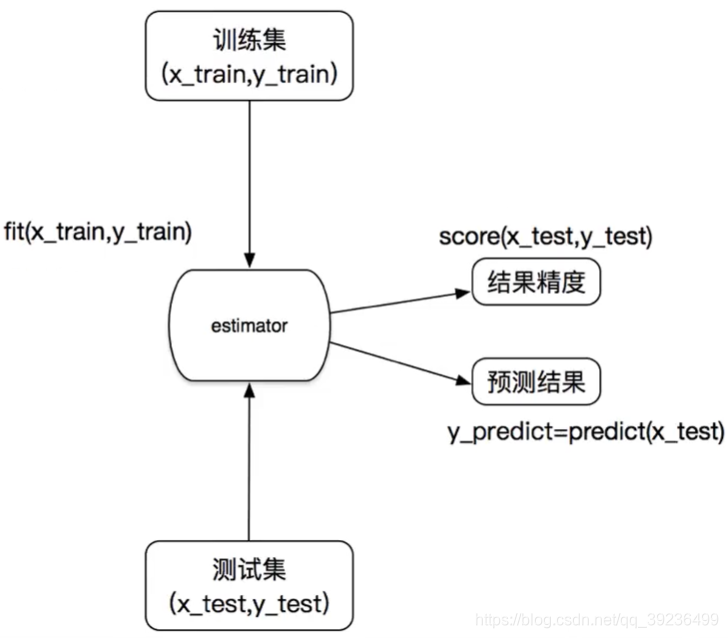
估计器工作流程
1.实例化一个estimator
2.estimator_fit(x_train,y_train) 计算 --调用完毕,模型生成
3.模型评估:
1)直接比对真实值和预测值 y_predict = estimator.predict(x_test)
y_test == y_predict
2)计算准确率
accuacy = estimator.score(x_test,y_test)
2.2knn算法
学习目标:
- 说明K-近邻算法的距离公式
- 说明K-近邻算法的超参数K值以及取值问题
- 说明K-近邻算法的优缺点
- 应用K-近邻实现分类
2.2.1 什么是K-近邻算法
1.原理
定义:如果一个样本在特征空间总的K个最相近的特征空间中最邻近的样本中的大多数属于某一个类别,则该样本也属于这个类别
1)欧式距离:

2)曼哈顿距离:绝对值距离
3)明可夫斯基距离
2.电影类型分析
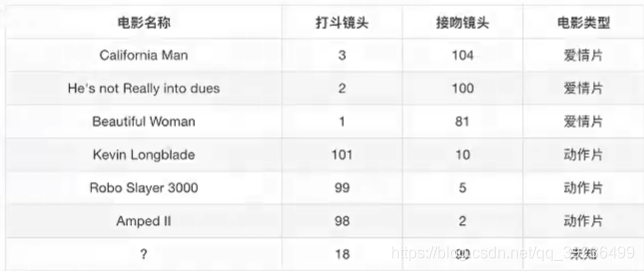
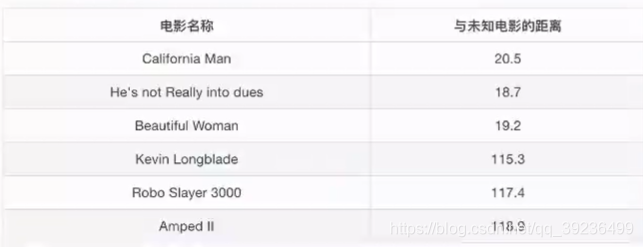
K=1时,离第二个电影近,属于爱情片
K=2时,离第二、三部电影近,属于爱情片
K=6时,无法确定
K值过大,容易受到样本不均衡的影响
K值过小,容易受到异常值影响
无量纲化处理 : 标准化
2.2.2 K-近邻算法API
sklearn.neighbor.KNeighborsClassifier(n_neighbors=5, algorithm='auto')
- n_neighbors:k值 int型,k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’}之一
2.2.3 案例:鸢尾花种类预测

流程:
1)获取数据
2)数据集划分
3)特征工程:标准化
4)KNN预估器流程
5)模型评估
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifierdef knn_iris():"""knn算法对鸢尾花进行分类:return:"""# 1)获取数据iris = load_iris()# 2)数据集划分x_train, x_test, y_train,y_test = train_test_split(iris.data, iris.target, random_state=6)# 3)特征工程:标准化tranfer = StandardScaler()x_train = tranfer.fit_transform(x_train)x_test = tranfer.transform(x_test)# 4)KNN预估器流程estimator = KNeighborsClassifier(n_neighbors=3)estimator.fit(x_train, y_train)# 5)模型评估#方法1:直接比对真实值和预测值y_predict = estimator.predict(x_test)print("y_predict:\n", y_predict)print("直接对比真实值和预测值:\n", y_test == y_predict)#方法2:计算准确率score = estimator.score(x_test, y_test)print("准确率为:\n", score)return Noneif __name__ == "__main__":knn_iris()
2.2.4 K-近邻总结
优点:简单,易于实现,无需训练
缺点:懒惰算法,对测试样本分类时的计算量大,内存开销大;必须指定K值,K值选择不当则分类精度不能保证
使用场景:小数据场景,几千~几万样本
2.3模型选择与调优
学习目标:
- 说明交叉验证过程
- 说明超参数搜索过程
- 应用GridSearchCV实现算法参数的调优
应用: - 鸢尾花数据集预测
- Facebook签到位置预测调优
2.3.1什么是交叉验证
交叉验证:将拿到的训练集数据,分为训练和验证集。以下图为例:将数据分成4份,其中一份作为验证集。然后经过4次的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果,又称4折交叉验证。
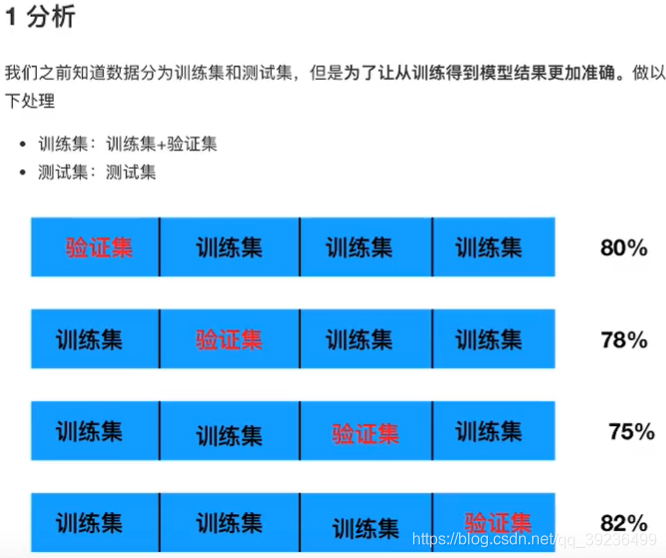
为什么需要交叉验证
交叉验证的目的:为了让被评估的模型更加准确可信
2.3.2超参数搜索-网格搜索
通常情况下,很多参数是需要手动指定的(如K-近邻算法中的K值),这种叫超参数。
但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型

sklearn.model_selection.GridSearchCV(estimator, param_grid=None, cv=None)
- 对估计器的指定参数进行详尽搜索
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
- fit():输入训练数据
- score():准确率
-
结果分析:
- 最佳参数:
best_params_ - 最佳结果:
best_score_ - 最佳估计器:
best_estimator_ - 交叉验证结果:
cv_results_
- 最佳参数:
2.3.3 鸢尾花案例增加K值调优
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCVdef knn_iris():"""knn算法对鸢尾花进行分类:return:"""# 1)获取数据iris = load_iris()# 2)数据集划分x_train, x_test, y_train,y_test = train_test_split(iris.data, iris.target, random_state=6)# 3)特征工程:标准化tranfer = StandardScaler()x_train = tranfer.fit_transform(x_train)x_test = tranfer.transform(x_test)# 4)KNN预估器流程estimator = KNeighborsClassifier()#加入网格搜索和交叉验证#参数准备param_dict = {"n_neighbors":[1, 3, 5, 7, 9, 11]}estimator = GridSearchCV(estimator,param_grid=param_dict, cv=10)estimator.fit(x_train, y_train)# 5)模型评估#方法1:直接比对真实值和预测值y_predict = estimator.predict(x_test)print("y_predict:\n", y_predict)print("直接对比真实值和预测值:\n", y_test == y_predict)#方法2:计算准确率score = estimator.score(x_test, y_test)print("准确率为:\n", score)print("最佳参数:\n", estimator.best_params_)print("最佳结果:\n", estimator.best_score_)print("最佳估计器:\n", estimator.best_estimator_)print("交叉验证结果:\n", estimator.cv_results_)return Noneif __name__ == "__main__":knn_iris()结果
y_predict:[0 2 0 0 2 1 2 0 2 1 2 1 2 2 1 1 2 1 1 0 0 2 0 0 1 1 1 2 0 1 0 1 0 0 1 2 12]
直接对比真实值和预测值:[ True True True True True True True True True True True TrueTrue True True False True True True True True True True TrueTrue True True True True True True True True True False TrueTrue True]
准确率为:0.9473684210526315
最佳参数:{'n_neighbors': 11}
最佳结果:0.9734848484848484
最佳估计器:KNeighborsClassifier(n_neighbors=11)
交叉验证结果:{'mean_fit_time': array([0.0015615 , 0.00156202, 0.00156248, 0. , 0. ,0. ]), 'std_fit_time': array([0.0046845 , 0.00468607, 0.00468743, 0. , 0. ,0. ]), 'mean_score_time': array([0., 0., 0., 0., 0., 0.]), 'std_score_time': array([0., 0., 0., 0., 0., 0.]), 'param_n_neighbors': masked_array(data=[1, 3, 5, 7, 9, 11],mask=[False, False, False, False, False, False],fill_value='?',dtype=object), 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}, {'n_neighbors': 7}, {'n_neighbors': 9}, {'n_neighbors': 11}], 'split0_test_score': array([1., 1., 1., 1., 1., 1.]), 'split1_test_score': array([0.91666667, 0.91666667, 1. , 0.91666667, 0.91666667,0.91666667]), 'split2_test_score': array([1., 1., 1., 1., 1., 1.]), 'split3_test_score': array([1. , 1. , 1. , 1. , 0.90909091,1. ]), 'split4_test_score': array([1., 1., 1., 1., 1., 1.]), 'split5_test_score': array([0.90909091, 0.90909091, 1. , 1. , 1. ,1. ]), 'split6_test_score': array([1., 1., 1., 1., 1., 1.]), 'split7_test_score': array([0.90909091, 0.90909091, 0.90909091, 0.90909091, 1. ,1. ]), 'split8_test_score': array([1., 1., 1., 1., 1., 1.]), 'split9_test_score': array([0.90909091, 0.81818182, 0.81818182, 0.81818182, 0.81818182,0.81818182]), 'mean_test_score': array([0.96439394, 0.95530303, 0.97272727, 0.96439394, 0.96439394,0.97348485]), 'std_test_score': array([0.04365767, 0.0604591 , 0.05821022, 0.05965639, 0.05965639,0.05742104]), 'rank_test_score': array([5, 6, 2, 3, 3, 1])}进程已结束,退出代码0
2.3.4案例,预测facebook签到位置

流程分析:
1)获取数据
2)数据处理
目的:
- 特征值 x:2<x<2.5
- 目标值y:1.0<y<1.5
- time -> 年与日时分秒
- 过滤签到次数少的地点
3)特征工程:标准化
4)KNN算法预估流程
5)模型选择与调优
6)模型评估
import pandas as pd
# 1、获取数据
data = pd.read_csv("./FBlocation/train.csv") #29118021 rows × 6 columns# 2、基本的数据处理
# 1)缩小数据范围
data = data.query("x<2.5 & x>2 & y<1.5 & y>1.0") #83197 rows × 6 columns
# 2)处理时间特征
time_value = pd.to_datetime(data["time"], unit="s") #Name: time, Length: 83197
date = pd.DatetimeIndex(time_value)
data["day"] = date.day
data["weekday"] = date.weekday
data["hour"] = date.hour
data.head() #83197 rows × 9 columns
# 3)过滤签到次数少的地点
place_count = data.groupby("place_id").count()["row_id"] #2514 rows × 8 columns
place_count[place_count > 3].head()
data_final = data[data["place_id"].isin(place_count[place_count>3].index.values)]
data_final.head() #80910 rows × 9 columns# 筛选特征值和目标值
x = data_final[["x", "y", "accuracy", "day", "weekday", "hour"]]
y = data_final["place_id"]# 数据集划分
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y)from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train) # 训练集标准化
x_test = transfer.transform(x_test) # 测试集标准化# 4、KNN算法预估器
estimator = KNeighborsClassifier()
# 加入网格搜索与交叉验证
# 参数准备
param_dict = {"n_neighbors": [3,5,7,9]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=5) # 10折,数据量不大,可以多折estimator.fit(x_train, y_train)# 5、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接必读真实值和预测值:\n", y_test == y_predict) # 直接比对# 方法2:计算准确率
score = estimator.score(x_test, y_test) # 测试集的特征值,测试集的目标值
print("准确率:", score)# 查看最佳参数:best_params_
print("最佳参数:", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:", estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:", estimator.cv_results_)
2.4朴素贝叶斯算法
2.4.1什么是朴素贝叶斯分类方法
2.4.2概率基础
女神是否喜欢计算案例
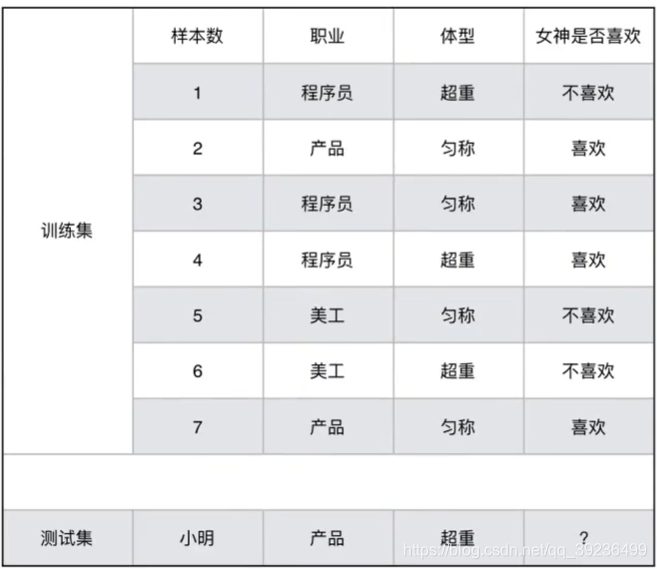

2.4.3联合概率,条件概率和相互独立

2.4.4贝叶斯公式

朴素?
假设:特征与特征之间相互独立
朴素贝叶斯算法?
朴素+贝叶斯
应用场景:文本分类,单词作为特征
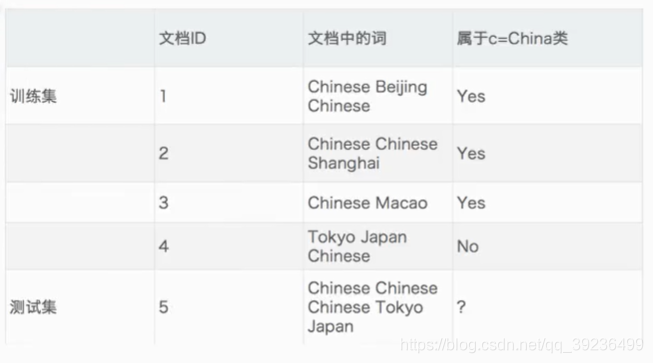
拉普拉斯平滑系数

2.4.5API
sklearn.naive_bayes.MultinomialNB(alpha=1.0)
- 朴素贝叶斯分类
- alpha:拉普拉斯平滑系数
2.4.6案例:20类新闻分类
1.获取数据
2.划分数据集
3.特征工程 文本特征抽取
4.朴素贝叶斯预估器流程
5、模型评估
from sklearn.model_selection import train_test_split # 划分数据集
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer # 文本特征抽取
from sklearn.naive_bayes import MultinomialNB # 朴素贝叶斯def nb_news():"""用朴素贝叶斯算法对新闻进行分类:return:"""# 1)获取数据news = fetch_20newsgroups(subset='all')# 2)划分数据集x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)# 3)特征工程:文本特征抽取transfer = TfidfVectorizer()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 4)朴素贝叶斯算法预估器流程estimator = MultinomialNB()estimator.fit(x_train, y_train)# 5)模型评估y_predict = estimator.predict(x_test)print("y_predict:\n", y_predict)print("直接必读真实值和预测值:\n", y_test == y_predict) # 直接比对# 方法2:计算准确率score = estimator.score(x_test, y_test) # 测试集的特征值,测试集的目标值print("准确率:", score)return Noneif __name__ == "__main__":nb_news()
2.4.7朴素贝叶斯算法总结
优点:
- 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类
- 分类准确度高,速度快
缺点: - 由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好
2.4.8总结
2.5决策树
2.5.1认识决策树
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-else结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法
2.5.2决策树分类原理详解
1 原理
信息熵、信息增益等
2 信息熵的定义
信息的衡量-信息量-信息熵

3 决策树的划分依据之一-----信息增益


2.5.3决策树API
sklearn.tree.DecisionTreeClassifier(criterion='gini', max_depth=None, random_state=None)
- 决策树分类器
- criterion:默认是“gini”系数,也可以选择信息增益的熵‘entropy’
- max_depth:树的深度大小
- random_state:随机数种子
2.5.4决策树用于鸢尾花数据集
from sklearn.datasets import load_iris # 获取数据集
from sklearn.model_selection import train_test_split # 划分数据集
from sklearn.naive_bayes import MultinomialNB # 朴素贝叶斯
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphvizdef decision_iris():"""决策树对鸢尾花进行分类:return:"""# 1)获取数据集iris = load_iris()# 2)划分数据集x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22) # 随机数种子# 不用做特征工程:标准化# 3)决策树预估器estimator = DecisionTreeClassifier(criterion='entropy')estimator.fit(x_train, y_train)# 4)模型评估y_predict = estimator.predict(x_test)print("y_predict:\n", y_predict)print("直接必读真实值和预测值:\n", y_test == y_predict) # 直接比对# 方法2:计算准确率score = estimator.score(x_test, y_test) # 测试集的特征值,测试集的目标值print("准确率:", score)# 可视化决策树export_graphviz(estimator, out_file='iris_tree.dot', feature_names=iris.feature_names)return Noneif __name__ == "__main__":decision_iris()

2.5.5决策树可视化
sklearn.tree.export_graphviz() # 该函数能够导入dot文件
tree.export.graphviz(estimator, out_file='tree.dot', feature_names=[","])
网站Webgraphviz
2.5.6决策树总结
优点:简单的理解和解释,树木可视化
缺点:决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合
改进:
- 剪枝cart算法(决策树API当中已经实现,随机森林参数调优有相关介绍)
- 随机森林
2.5.7案例,泰坦尼克号
流程分析:特征值、目标值
1)获取数据
2)数据处理:缺失值处理,特征值->字典类型,
3)准备好特征值、目标值
4)划分数据集
5)特征工程:字典特征处理
6)决策树预估器流程
7)模型评估
import pandas as pd# 1、获取数据
path = "C:/Users/zdb/Desktop/machine_learning/DataSets/titanic.csv"
titanic = pd.read_csv(path) #1313 rows × 11 columns# 筛选特征值和目标值
x = titanic[["pclass", "age", "sex"]]
y = titanic["survived"]# 2、数据处理
# 1)缺失值处理
x["age"].fillna(x["age"].mean(), inplace=True)# 2)转换成字典
x = x.to_dict(orient="records")from sklearn.model_selection import train_test_split
# 3、数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)# 4、字典特征抽取
from sklearn.feature_extraction import DictVectorizer
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)from sklearn.tree import DecisionTreeClassifier, export_graphviz# 3)决策树预估器
estimator = DecisionTreeClassifier(criterion='entropy')
estimator.fit(x_train, y_train)# 4)模型评估
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接必读真实值和预测值:\n", y_test == y_predict) # 直接比对# 方法2:计算准确率
score = estimator.score(x_test, y_test) # 测试集的特征值,测试集的目标值
print("准确率:", score)# 可视化决策树
export_graphviz(estimator, out_file='titanic_tree.dot', feature_names=transfer.get_feature_names())import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plot_tree(decision_tree=estimator)
plt.show()
2.6集成学习方法之随机森林
2.6.1什么是集成学习方法
集成学习方法通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各种独立地学习和做出预测。这些预测最后结合成组合预测,因此优于任何一个单分类做出的预测
2.6.2什么是随机森林
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别数输出的类别的众数而定
例如,如果训练了5棵树,5棵树的结果是True ,1棵树的结果是False,那么最终结果为True
2.6.3随机森林原理过程
两个随机:
- 训练集随机:BoostStrap,N个样本中随机有放回抽样
- 特征值随机:从M个特征中随机抽取m个特征,M>>m
训练集:特征值、目标值
2.6.4API
sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None, /
bootstrap=True, random_state=None, min_samples_split=2)
n_estimators:integer,optional(default=10)森林里的树木数量,可以用网格搜索
criteria:string,可选(default=‘gini’),分割特征的测量方法
max_depth:integer或None,可选(默认无),树的最大深度5,8,15,25,30 可以用网格搜索
max_teatures=‘auto’,每个决策树的最大特征数量
if ‘auto’ ,then max_features = sqrt(n_features)
if ‘sqrt’ ,then max_features = sqrt(n_features)
if ‘log2’ ,then max_features = log2(n_features)
if None,then max_features = n_features
booststrap:boolean,optional(default=True)是否在构建树时使用放回抽样
min_samples_split:节点划分最少样本数
min_samples_leaf:叶子节点的最小样本数
超参数:n_estimator,max_depth,min_samples_split,min_samples_leaf
2.6.5随机森林案例预测
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
estimator = RandomForestClassifier()# 加入网格搜索与交叉验证
# 参数准备
param_dict = {"n_estimators":[120,200,300,500,800,1200], "max_depth":[5,8,15,25,30]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3) # 10折,数据量不大,可以多折estimator.fit(x_train, y_train)# 5、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接必读真实值和预测值:\n", y_test == y_predict) # 直接比对# 方法2:计算准确率
score = estimator.score(x_test, y_test) # 测试集的特征值,测试集的目标值
print("准确率:", score)# 查看最佳参数:best_params_
print("最佳参数:", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:", estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:", estimator.cv_results_)
2.6.6总结
- 在当前所有算法中,具有极好的准确率
- 能够有效地运行在大数据集上,处理具有高维特征的输入样本,而且不需要降维
- 能够评估各个特征在分类问题上的重要性

![[excel]vlookup函数对相同的ip进行关联](https://img-blog.csdnimg.cn/18ac618a941446619fbdaa543bbdcb34.png)